C++哈希
一.哈希概念
哈希又叫做散列。本质就是通过哈希函数把关键字key和存储位置建立映射关系,查找时通过这个哈希函数计算出key存储的位置,进行快速查找。
上述概念可能不那么好懂,下面的例子可以辅助我们理解。
无论是数组还是链表,查找一个数都需要通过遍历的方式,假设用单向查找最坏的情况就是查找n次,假设双向查找最坏的情况是查找n/2次,在数据量很大的情况下查找一个数就变得比较困难。最好的情况就是希望一下子就可以找到目标数字,由此出现了哈希表。
什么是映射关系?
映射关系分为两种:一对一和一对多
一对一:假设有2 3 90 100这四个数据,那我就开100个空间,将每一个数存在对应下标的位置,这样查找数据的时候一下子就找到了。
一对一的弊端十分明显,就是当数据较为分散,例如存储1和1001,那就要开辟1001个空间,十分浪费。那么一对多的存储就会比较好。
一对多:就是一个空间对应着多个数据。按照概念存储数据的时候肯定会产生冲突,这就是哈希冲突。
二.除法散列法
针对冲突的情况可以用除法散列法来解决。顾名思义,假设哈希表大小为M,那么通过Key除以M的余数作为映射位置下标,也就是哈希函数为:h(key)=key%M
例如:假设数字为12,哈希表大小为10
12/10的余数是2,那么就将12映射到2的位置,但是如果还要存储32这个数据,不难发现32/10的余数仍然是2于是就产生了冲突,那该怎么解决呢?
2.1线性探测
从发生冲突的位置开始,依次线性向后探测,直到寻找到下一个没有存储数据的位置为止,如果走到哈希表尾,则绕回到哈希表头的位置。
就像上面的例子,12已经映射到2的位置,那么32就需要向后线性探测,假如下标为3的位置没有数据存储 那么就将32存储到下标为3的位置。
我们最初的目标就是避免遍历,那如果数据一直冲突的话也就无法解决这个问题了,很简单通过扩容就可以解决这个问题。
2.1.1哈希因子
说到扩容就不得不提到哈希因子了,哈希因子就是有效数据个数/哈希表大小。
例如数据个数为2,哈希表大小为10,那么哈希因子就是0.2,一般来说当哈希因子到0.7时就需要开始扩容了。
2.1.2哈希桶
有时候扩容仍然无法解决冲突的问题,那么哈希桶就很好解决了这个问题。
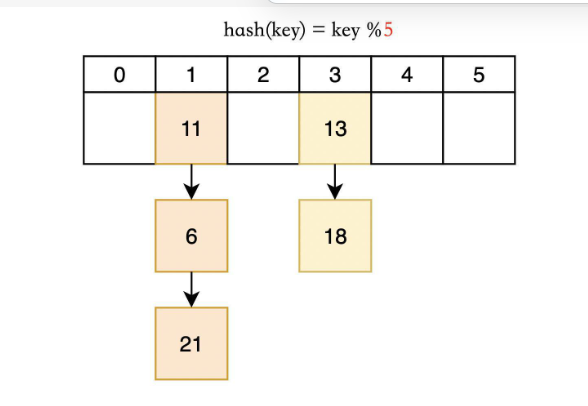
哈希桶概念:哈希表中存储一个指针,当没有数据映射到这个位置时,这个指针为空;有多个数据映射到这个位置时,把冲突的数据连接成一个链表,挂在哈希表这个位置下面。
哈希桶的扩容:
// 扩容函数void Resize() {size_t newSize = _tables.size() * 2;vector<Node*> newTables(newSize, nullptr);KeyOfT kot;Hash hs;// 重新哈希所有元素for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];while (cur) {Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newSize;cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}}_tables.swap(newTables);}
代码中出现KeyOfT是因为set和map取出key方式不一样,set可以直接取出key而map需要从pair中取出。
三.key不是整数的情况
在计算位置的时候需要用到key来除以哈希表大小,当key不为整数时分两种情况:
- double等可以直接强制类型转换为int
- string不能强制类型转换成int
template<class K>
struct HashFunc {size_t operator()(const K& key) {return (size_t)key; // 默认实现:适用于整数类型}
};// 字符串类型特化
template<>
struct HashFunc<string> {size_t operator()(const string& key) {size_t hash = 0;for (char c : key) {hash = hash * 131 + c; // 使用BKDR哈希算法处理字符串}return hash;}
};完整代码:
#pragma once
#include<vector>
#include<iostream>
using namespace std;
// 通用哈希函数模板(默认使用类型转换)
template<class K>
struct HashFunc {size_t operator()(const K& key) {return (size_t)key; // 默认实现:适用于整数类型}
};// 字符串类型特化
template<>
struct HashFunc<string> {size_t operator()(const string& key) {size_t hash = 0;for (char c : key) {hash = hash * 131 + c; // 使用BKDR哈希算法处理字符串}return hash;}
};
namespace hash_bucket {template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>class HashTable {typedef HashNode<T> Node;public:// 构造函数HashTable() {_tables.resize(10, nullptr);}// 析构函数:释放所有节点内存~HashTable() {for (auto& bucket : _tables) {Node* cur = bucket;while (cur) {Node* next = cur->_next;delete cur;cur = next;}bucket = nullptr;}_n = 0;}// 插入元素bool Insert(const T& data) {KeyOfT kot;Hash hs;const K& key = kot(data); // 提取键// 检查键是否已存在if (Find(key)) return false;// 负载因子超过1时扩容if (_n >= _tables.size()) {Resize();}// 计算哈希值并插入size_t hashi = hs(key) % _tables.size();Node* newNode = new Node(data);newNode->_next = _tables[hashi];_tables[hashi] = newNode;++_n;return true;}// 查找元素bool Find(const K& key) {Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {return true;}cur = cur->_next;}return false;}// 删除元素bool Erase(const K& key) {Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {_tables[hashi] = cur->_next;}else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:// 扩容函数void Resize() {size_t newSize = _tables.size() * 2;vector<Node*> newTables(newSize, nullptr);KeyOfT kot;Hash hs;// 重新哈希所有元素for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];while (cur) {Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newSize;cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}}_tables.swap(newTables);}private:vector<Node*> _tables;size_t _n = 0;};} // namespace hash_bucket四.unordered_set和unordered_map的封装
1.unordered_set
#define _CRT_SECURE_NO_WARNINGS
#include"hashi.h"
namespace happy
{template<class K>class unorder_set{struct SetKeyOfT{ const K& operator()(const K& key) {return key;}};public://取类模板的内嵌类型需要typenametypedef typename hash_bucket::HashTable<K, const K, SetKeyOfT>::Iterator iterator;typedef typename hash_bucket::HashTable<K, const K, SetKeyOfT>::const_Iterator Citerator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}Citerator begin()const{return _ht.begin();}Citerator end()const{return _ht.end();}pair<iterator,bool> insert(const K& key){return _ht.Insert(key);}private:hash_bucket::HashTable<K, const K,SetKeyOfT> _ht;};void print(const unorder_set<int>& s){unorder_set<int>::Citerator it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;}
}2.unordered_map
#pragma once
#include"hashi.h"
#include <utility> // pair
#include <iostream>
using namespace std;
namespace happy
{template<class K, class V, class Hash = HashFunc<K>>class unorder_map{struct MapKeyOfT{const K& operator() (const pair<const K, V>& kv){return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::Iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash>::const_Iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}pair<iterator, bool> insert(const pair<const K, V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = insert({ key, V() });return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT, Hash> _ht;};void test_unordered_map(){unorder_map<string, string> dict;dict.insert({ "string", "字符串" });dict.insert({ "left", "左边" });unorder_map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;// 测试 operator[]dict["right"] = "右边";cout << "dict[\"right\"]: " << dict["right"] << endl;}
}3.hashi
#pragma once
#include<vector>
#include<iostream>
using namespace std;
// 通用哈希函数模板(默认使用类型转换)
template<class K>
struct HashFunc {size_t operator()(const K& key) {return (size_t)key; // 默认实现:适用于整数类型}
};// 字符串类型特化
template<>
struct HashFunc<string> {size_t operator()(const string& key) {size_t hash = 0;for (char c : key) {hash = hash * 131 + c; // 使用BKDR哈希算法处理字符串}return hash;}
};
namespace hash_bucket {template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};template<class K, class T, class KeyOfT, class Hash >class HashTable;template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hash = HashFunc<K>>struct HTIterator{typedef HashNode<T> Node;typedef HashTable<K, T, KeyOfT, Hash> HT;typedef HTIterator<K, T,Ref,Ptr, KeyOfT, Hash> iterator;Node* _node;//结点指针const HT* _ht;//哈希表指针HTIterator(Node*node,const HT*ht):_node(node),_ht(ht){}Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}bool operator!=(const iterator& s){return _node != s._node;}bool operator==(const iterator& s){return _node == s._node;}iterator& operator++(){if (_node->_next){_node = _node->_next;}else{KeyOfT kot;Hash hs;size_t hashi = hs(kot(_node->_data)) % _ht->_tables.size();++hashi;while (hashi < _ht->_tables.size()){if (_ht->_tables[hashi]){_node = _ht->_tables[hashi];break;}else{++hashi;}}//所有桶走完if (hashi == _ht->_tables.size()){_node = nullptr;}}return *this;}};template<class K, class T, class KeyOfT, class Hash = HashFunc<K>>class HashTable {typedef HashNode<T> Node;//友元声明template<class K, class T,class Ref,class Ptr, class KeyOfT, class Hash >friend struct HTIterator;public:typedef HTIterator<K, T,T&,T*, KeyOfT, Hash> Iterator;typedef HTIterator<K, T,const T&,const T*, KeyOfT, Hash> const_Iterator;Iterator begin(){for (size_t hashi = 0; hashi < _tables.size(); hashi++){if (_tables[hashi]){return Iterator(_tables[hashi],this);}}return end();}Iterator end(){return Iterator(nullptr, this);}const_Iterator begin()const{for (size_t hashi = 0; hashi < _tables.size(); hashi++){if (_tables[hashi]){return const_Iterator(_tables[hashi], this);}}return end();}const_Iterator end()const{return const_Iterator(nullptr, this);}// 构造函数HashTable() {_tables.resize(10, nullptr);}// 析构函数:释放所有节点内存~HashTable() {for (auto& bucket : _tables) {Node* cur = bucket;while (cur) {Node* next = cur->_next;delete cur;cur = next;}bucket = nullptr;}_n = 0;}// 插入元素pair<Iterator,bool> Insert(const T& data) {KeyOfT kot;Hash hs;Iterator it = Find(kot(data));const K& key = kot(data); // 提取键// 检查键是否已存在if (it != end()) return { it,false };// 负载因子超过1时扩容if (_n >= _tables.size()) {Resize();}// 计算哈希值并插入size_t hashi = hs(key) % _tables.size();Node* newNode = new Node(data);newNode->_next = _tables[hashi];_tables[hashi] = newNode;++_n;return { {newNode,this},true };}// 查找元素Iterator Find(const K& key) {Hash hs;KeyOfT kot;size_t hashi = hs(key) % _tables.size();Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {return Iterator(cur, nullptr);}cur = cur->_next;}return end();}// 删除元素bool Erase(const K& key) {Hash hs;size_t hashi = hs(key) % _tables.size();Node* prev = nullptr;Node* cur = _tables[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {_tables[hashi] = cur->_next;}else {prev->_next = cur->_next;}delete cur;--_n;return true;}prev = cur;cur = cur->_next;}return false;}private:// 扩容函数void Resize() {size_t newSize = _tables.size() * 2;vector<Node*> newTables(newSize, nullptr);KeyOfT kot;Hash hs;// 重新哈希所有元素for (size_t i = 0; i < _tables.size(); ++i) {Node* cur = _tables[i];while (cur) {Node* next = cur->_next;size_t hashi = hs(kot(cur->_data)) % newSize;cur->_next = newTables[hashi];newTables[hashi] = cur;cur = next;}}_tables.swap(newTables);}private:vector<Node*> _tables;size_t _n = 0;};} // namespace hash_bucket