Sentieon项目文章 | 社区努力识别和纠正蛋白质基因组研究中标签错误的样本

关键词:多组学;蛋白质;错误标记;
引言
在日常生活中,会经常遇到物品与标签错误的问题,比如超市商品标价错误、图书馆书籍分类错误等。都会造成一些后果。在生物医学研究领域中,蛋白质样本标记错误同样是一个普遍存在的问题。特别是在现代高通量组学研究中,由于实验流程复杂、样本数量庞大,标记错误的情况更为常见。这些错误不仅会浪费昂贵的实验资源,更可能导致研究结论的错误,影响后续的临床决策。
以下的文章,主要为大家介绍一个样本错误标记自动检测与纠正工具COSMO,以及它在多组学研究中的应用价值。
文献介绍
- 标题(英文):A community effort to identify and correct mislabeled samples in proteogenomic studies
- 标题(中文):社区努力识别和纠正蛋白质基因组研究中标签错误的样本
- 发表期刊:Patterns
- 作者单位:西奈山伊坎医学院、Sentieon 公司等
- 发表年份:2021
- 文章地址:https://doi.org/10.1016/j.patter.2021.100245

图1 文献介绍
随着TCGA和CPTAC等大型项目推动多组学研究的深入开展,数据量和复杂度显著提升,但人为错误导致的样本标记问题也随之凸显。虽然在遗传和基因组数据方面已有多种检测方法,但这些方法难以直接应用于特性不同的蛋白质组数据。
为解决这一问题,precisionFDA和NCI-CPTAC发起了"多组学样本错误标记纠正挑战赛",旨在开发自动化工具来检测和纠正蛋白质基因组数据集中的错误标记。
本次挑战赛基于181个结直肠癌肿瘤样本的RNA测序、蛋白质组学和临床数据展开。通过随机抽样创建训练和测试数据集,并在数据集中故意引入错误标记,用于测试参与者的检测和纠正能力。
挑战赛分为两个子挑战:第一个子挑战要求参与者基于临床和蛋白质组数据检测不匹配样本;第二个子挑战增加RNA-seq数据,要求参与者检测问题样本、识别错误数据类型并进行纠正。
测序流程
来自15个国家的52个团队参与比赛。结果显示,处理蛋白质组数据的缺失值时,使用0替换的策略表现最佳。在模型构建方面,子挑战1表现较好的团队都结合了逻辑回归(LR)、随机森林(RF)和KNN等方法。
子挑战2的结果证明,多组学数据整合能提供更准确的错误检测。前三名团队均采用基于Pearson或Spearman的相关性分析进行数据匹配,并使用热图可视化辅助标签纠正。其中,来自隆德大学、莱特州立大学和Sentieon公司的团队表现最佳。
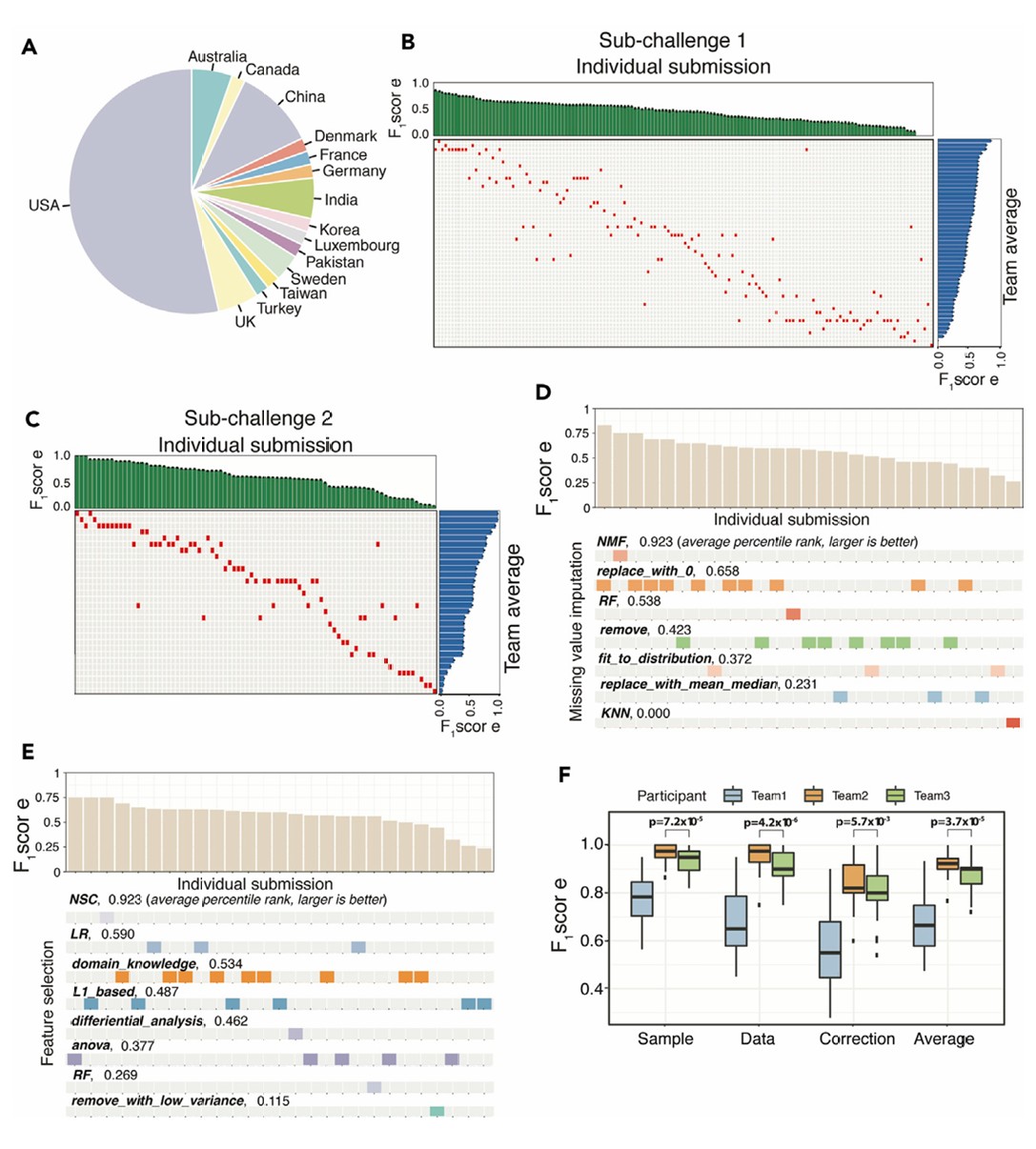
图2 挑战赛结果总结
(A) 全球参与者情况显示对挑战问题的高度关注。
(B) 对子挑战1中52个独特提交者的149份提交作品进行性能评估。对每份提交作品评估了具有95%置信区间的F1分数,并对独特提交者取平均值。
(C) 子挑战2的评估。共评估了31个独特提交者的57份提交作品的平均F1分数。观察到两个子挑战的提交性能都呈现广泛分布。即使在同一团队内,性能也有很大差异,表明标准化方法的重要性。 (D和E) 团队在子挑战1中的表现与缺失数据插补方法(C)和特征选择方法(D)之间的关联。使用平均百分位排名作为度量标准。
(F) 使用50个结肠癌模拟数据集(具有固定类型和错误数量)评估子挑战2中前三名方法的稳健性。P值使用双侧配对Student's t检验计算。
挑战赛结束后,表现最佳的三个团队进行后续合作。通过对原始50个训练/测试数据集的评估,莱特州立大学和Sentieon公司展现出优异的表现,平均F1分数为0.9,明显优于基线方法的0.68。而隆德大学团队由于难以将人工检查转化为自动流程,整体表现相对较弱。
为模拟真实场景,研究人员基于结肠数据创建了50个具有不同错误标记率和模式的新数据集。只有莱特州立大学的方法成功适应,F1分数为0.92。通过整合莱特州立大学和Sentieon公司的方法,检测和纠正错误的准确性得到进一步提升。
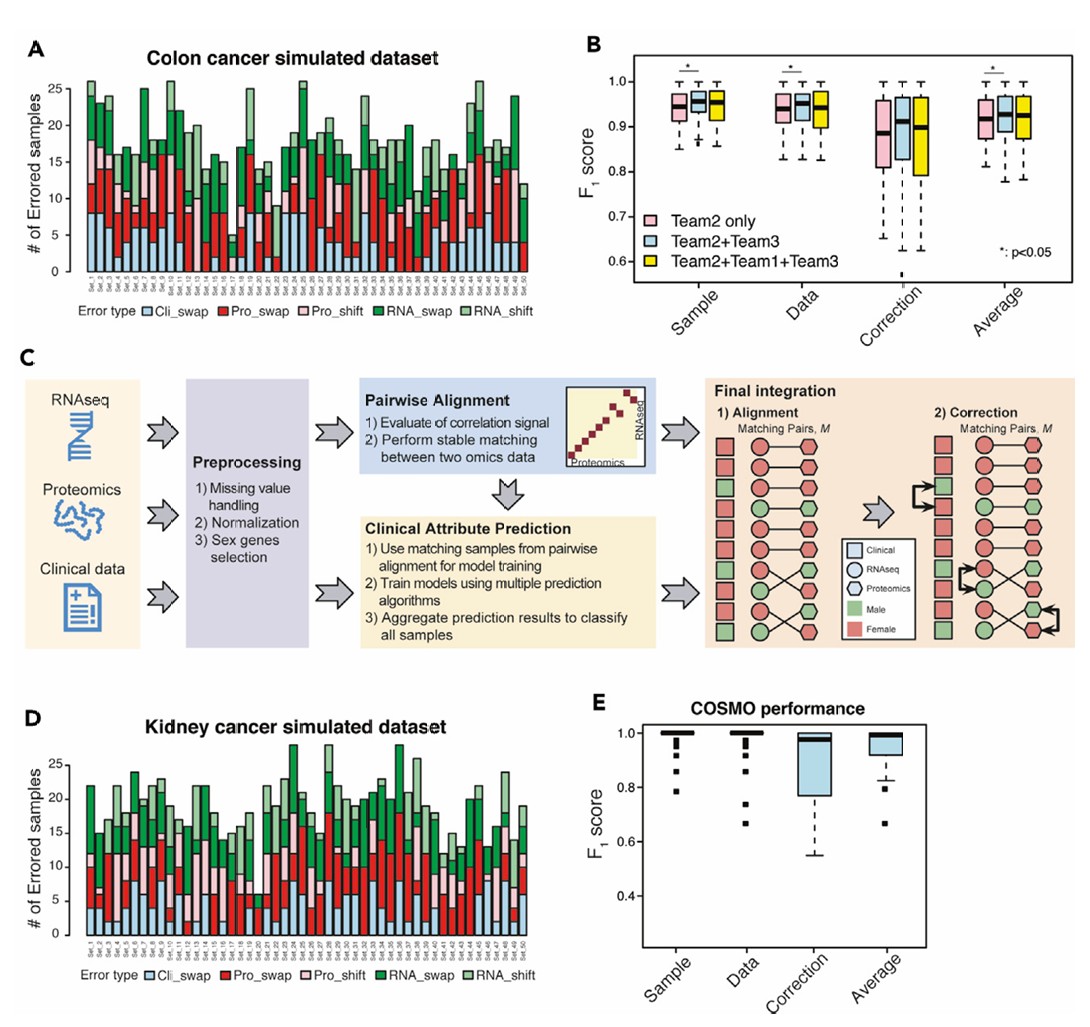
图3 COSMO及其在独立测试数据集上的表现
(A) 通过从结肠癌数据集生成具有不同类型和数量的样本标记错误的模拟数据集来模拟样本错误标记的真实情况。
(B) 不同临床属性预测来源的性能。P值使用双侧配对Student's t检验计算。
(C) COSMO检测和纠正临床或组学数据中错误标记样本的整体示意图。
(D) 使用CPTAC肾癌数据集生成具有不同类型和数量的样本标记错误的模拟数据集来模拟样本错误标记的真实情况。
(E) COSMO在(D)中50个模拟数据集上的性能。
基于这些发现,研究团队开发了自动化工具COSMO,结合了莱特州立大学的整体流程和Sentieon公司的临床属性预测算法,COSMO在肾癌研究数据集的验证中展现出极高的准确性,F1分数中位数达0.99。即使错误率>20%的情况下仍能保持出色表现,F1分数大于0.9。
COSMO在六个独立的多组学数据集中进行了实际应用验证。在已知存在错误标记的三个人类肿瘤数据集中,COSMO成功识别出CPTAC肺癌数据集(preQC CPTAC LUAD)中四对互换样本、CPTAC肾癌数据集(preQC CPTAC CCRCC)中三个错误标记样本,以及TCGA乳腺癌数据集(TCGA BRCA)中八对互换样本。
在此前未报告错误的三个数据集中,COSMO的应用也取得了重要发现。虽然CCLE细胞系数据显示完全对齐,但在人类淋巴母细胞系研究中发现了RNA-seq数据的两个样本互换和蛋白质组的一个重复样本。在外繁小鼠肝脏研究中,COSMO检测到了九对互换样本。
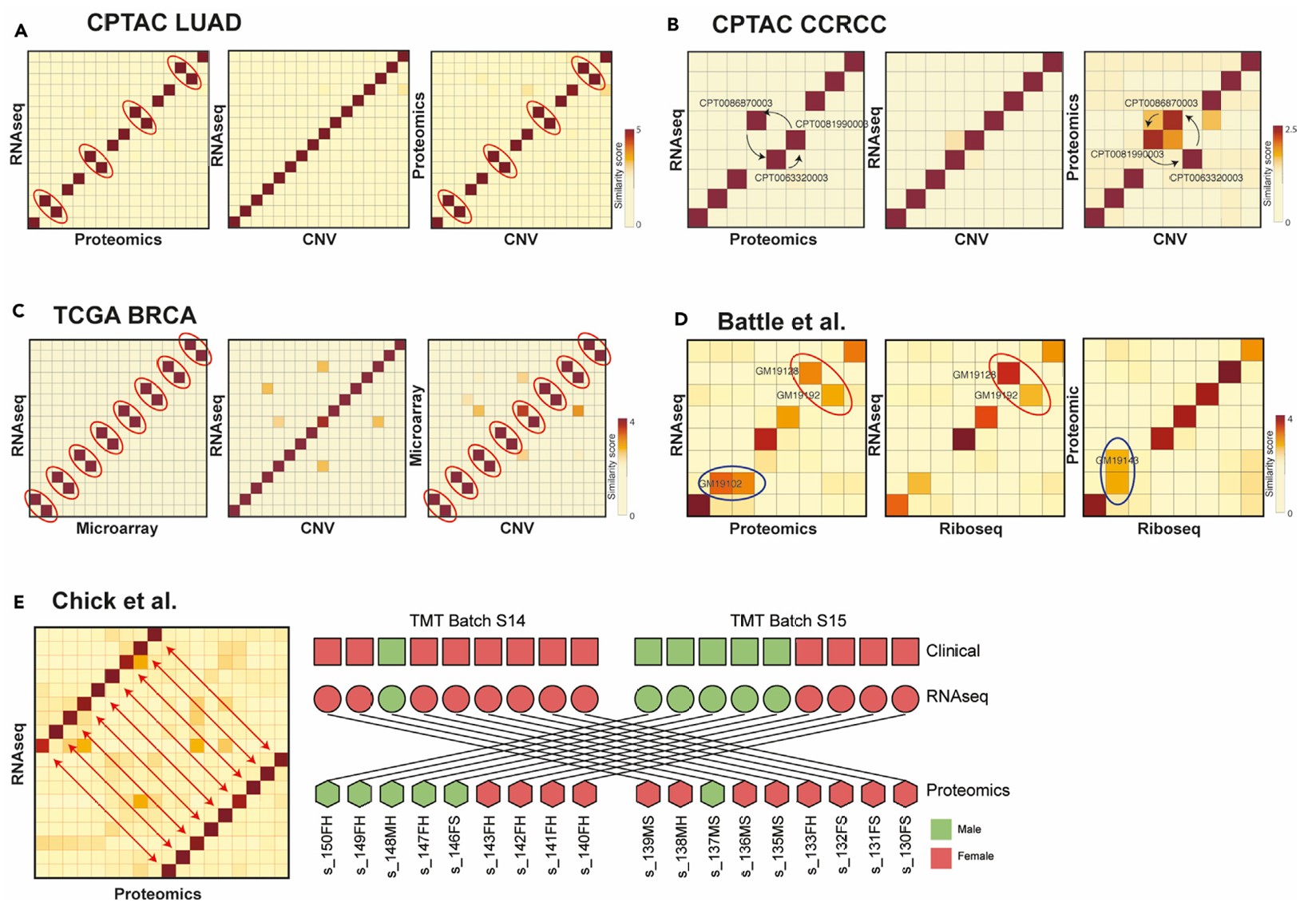
图4 COSMO在真实数据集中的应用
(A) CPTAC LUAD:四对蛋白质组学样本在RNA-seq-蛋白质组学和蛋白质组学-CNV之间相互匹配,但在RNA-seq-CNV中未观察到标记交换。
(B) CPTAC CCRCC:蛋白质组学中的三个样本在RNA-seq-蛋白质组学和蛋白质组学-CNV匹配中发生偏移,而RNA-seq和CNV之间的样本匹配良好。
(C) TCGA BRCA:八对微阵列样本在RNA-seq-微阵列和微阵列-CNV匹配中发生交换。
(D) Battle等人的研究:基于RNA-seq、蛋白质组学和Riboseq数据的比对,发现两个RNA-seq样本发生交换。观察到潜在的重复蛋白质样本。 (E) Chick等人的研究:RNA-seq和蛋白质数据之间有九对样本发生交换。与样本性别的临床注释合并表明蛋白质组学数据中存在交换。
研究表明样本错误标记的纠正对生物学结论有重要影响。以CPTAC肺癌研究为例,纠正样本标记后,差异表达蛋白的数量从160个增加到584个。并提高了检测性别相关通路的能力。
在免疫热/冷肿瘤分析中,错误纠正后不仅识别出比纠错前多20%的差异表达蛋白,还揭示了其他与免疫反应相关的重要通路。
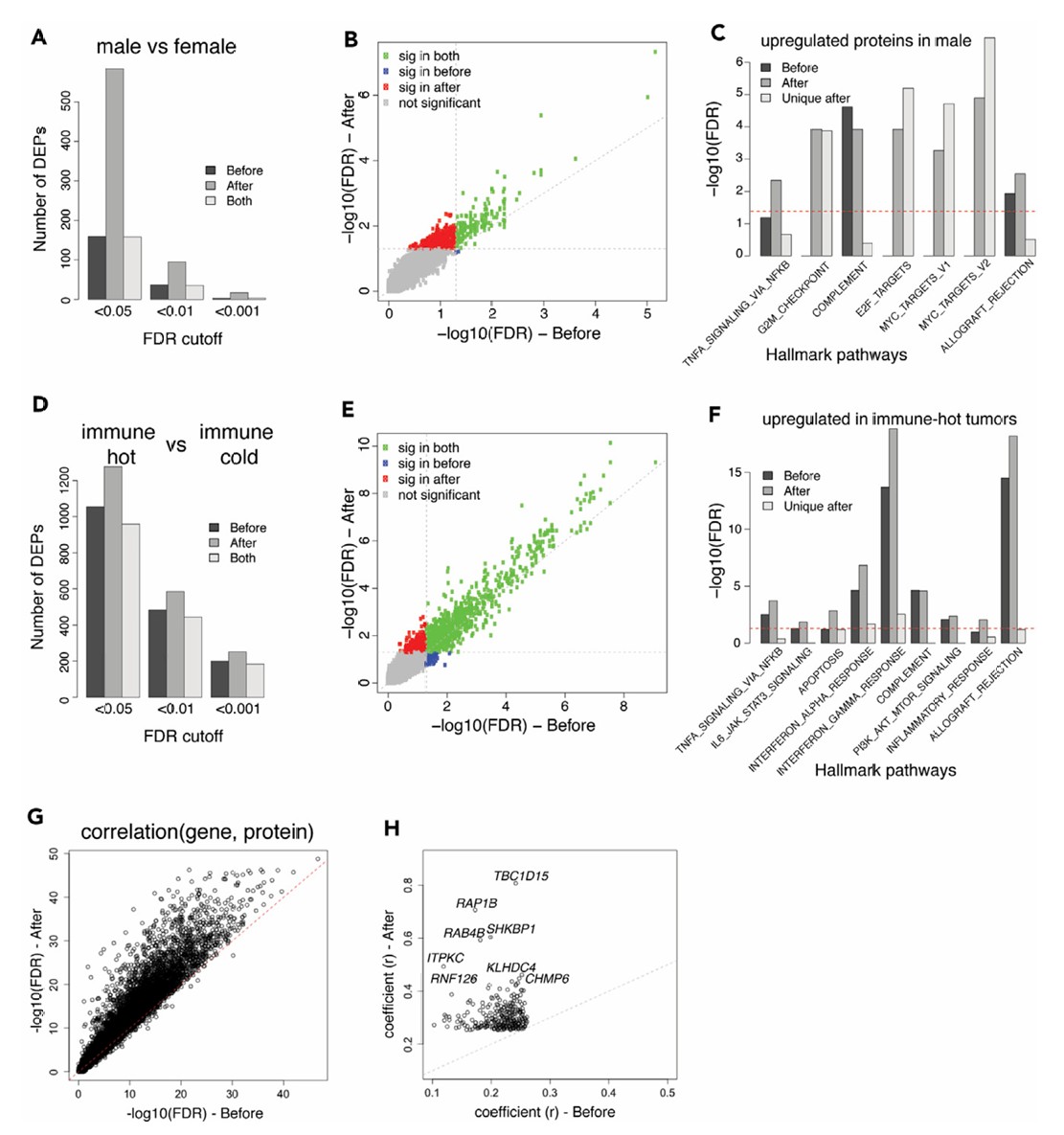
图5 COSMO错误纠正在CPTAC LUAD数据集中的生物学影响
(A) 错误纠正前后男性和女性肿瘤之间DEPs的数量。
(B) 比较8,528个蛋白质在男性和女性肿瘤之间的t检验FDR(-log10)。
(C) 错误纠正前后与性别DEPs显著相关的HALLMARK通路(FET FDR < 0.05)。COSMO后的独特DEPs也用于功能富集测试。
(D) 免疫热和免疫冷肿瘤中DEPs的数量。
(E) 比较8,528个蛋白质在免疫热和免疫冷肿瘤之间的t检验FDR。
(F) 与免疫热亚型肿瘤中上调蛋白质显著相关的HALLMARK通路。
(G) 纠正前后8,366个基因-蛋白质对的相关强度。Pearson相关p值经Benjamini-Hochberg调整为FDR,然后进行-log10转换。
(H) 仅在错误纠正后显著的269个基因-蛋白质对的相关强度差异。
在多组学分析方面,COSMO的纠正同样带来显著的改善效果。在CPTAC肺癌研究中,修复了7.5%的错误标记就使85%基因的mRNA-蛋白质相关性得到提升,还发现267个新增的显著相关基因,包括多个重要的癌症相关基因。即使在错误率为3.5%的CPTAC肾癌数据集中,纠正后也观察到了62%基因的相关性提升。
在外繁小鼠研究中,基于COSMO纠正后的数据重新进行pQTL分析,发现遗传变异对蛋白质组的影响更强烈,新分析多识别出了497个局部pQTL。
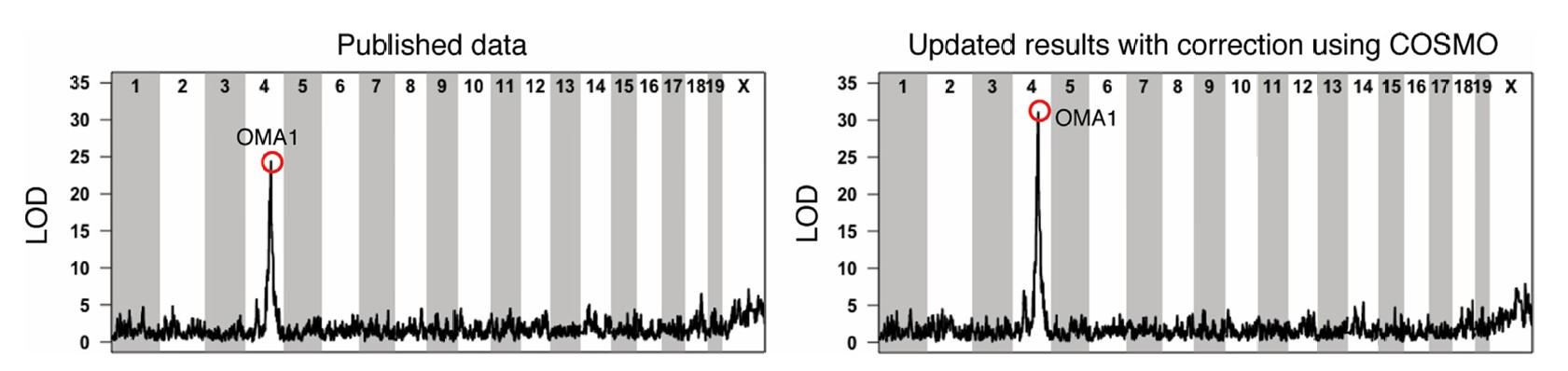
图6 错误纠正影响的pQTL分析 OMA1局部pQTL的对数优势比(LOD)得分在错误纠正后从24(左)增加到31(右)。
Sentieon 软件团队拥有丰富的软件开发及算法优化工程经验,致力于解决生物数据分析中的速度与准确度瓶颈,为来自于分子诊断、药物研发、临床医疗、人群队列、动植物等多个领域的合作伙伴提供高效精准的软件解决方案,共同推动基因技术的发展。截至 2023 年 3 月份,Sentieon 已经在全球范围内为 1300+用户提供服务,被世界一级影响因子刊物如 NEJM、Cell、Nature 等广泛引用,引用次数超过 700 篇。此外,Sentieon 连续数年摘得了 Precision FDA、Dream Challenges 等多个权威评比的桂冠,在业内获得广泛认可。
总结
虽然研究仍存在着一些局限性,如:训练集和测试集不是完全独立的,因此不能保证获胜解决方案的泛化能力。使用单一的数据集来进行性能验证限制了评估结果的稳定性等。
但研究展示了COSMO在处理不同类型组学平台、不同生物体以及各类研究中的通用性和可靠性,证明了COSMO作为自动化解决方案的价值。也凸显了样本错误标记纠正对提高组学研究准确性的重要性。