Triton推理服务器部署YOLOv8(onnxruntime后端和TensorRT后端)
文章目录
- 一、Trition推理服务器基础知识
- 1)推理服务器设计概述
- 2)Trition推理服务器quickstart
- (1)创建模型仓库(Create a model Repository)
- (2)启动Triton (launching triton)并验证是否正常运行
- (3)发送推理请求(send a inference request)
- 3)Trition推理服务器架构
- 4)Trition推理服务器模型配置(最小、最大模型配置,最大批处理次数,模型维度形状,数据类型)
- 二、YOLOv8安装
- 1)安装网络环境
- 2)安装pytorch
- 3)安装和克隆YOLOv8
- 三、TensorRT补充
- 1)简介
- 2)TRT引擎构建
- 3)TRT API基本用法
- 4)plugin加速推理
- 四、onnx补充
- 1)onnx概述+模型网络结构+数据结构
- 2)onnx模型搭建+dump信息+推理
- 3)onnx_graphsurgeon
- 4)onnx_Simplifier
- 五、Trion推理服务器部署(onnxruntime后端)
- 1)安装docker和NVIDIA Container toolkit
- (1)安装docker
- (2)安装NVIDIA Container toolkit
- 2)导出onnx模型
- 3)组织模型仓库布局文件
- 4)构建Triton推理docker容器
- 5)运行和测试Triton服务器
- 六、Trion推理服务器部署(TensorRT后端)
- 1)构建TensorRT引擎
- 2)组织模型仓库布局
- 3)构建Triton推理的docker容器
- 4)运行和测试Triton服务器
- 5)前处理说明
一、Trition推理服务器基础知识
1)推理服务器设计概述
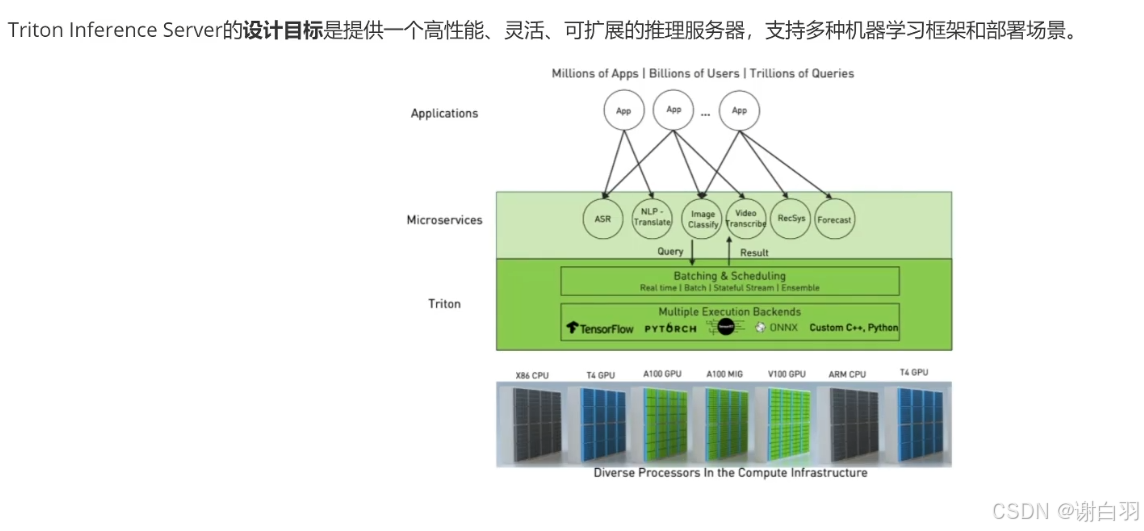
- 设计思想和特点
1、支持多种机器学习框架

2、支持多种部署场景

3、高性能推理

4、灵活的模型管理

5、可扩展性

6、强大的客户端支持

2)Trition推理服务器quickstart
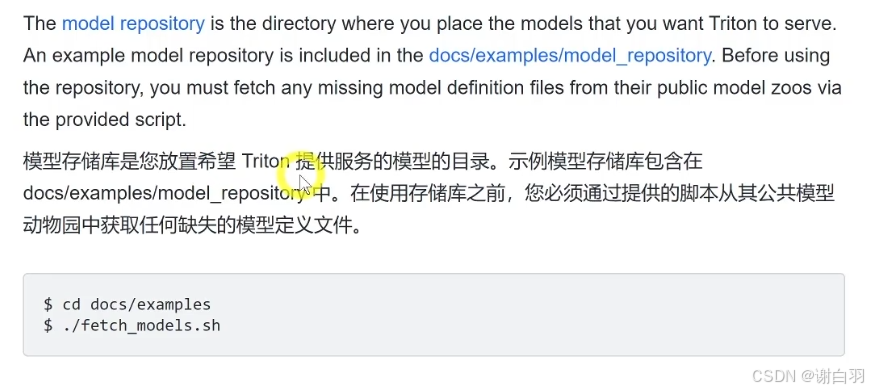
(1)创建模型仓库(Create a model Repository)
(2)启动Triton (launching triton)并验证是否正常运行
cpu运行
$ docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models

GPU运行
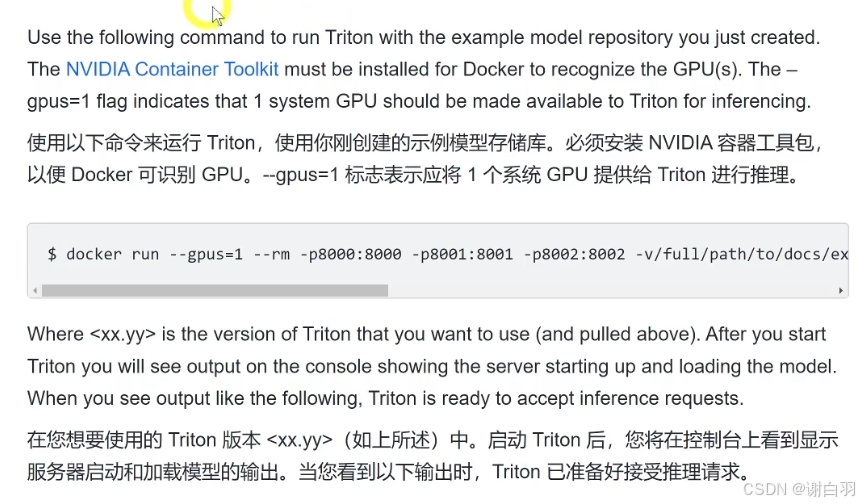
命令
$ docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
输出
+----------------------+---------+--------+
| Model | Version | Status |
+----------------------+---------+--------+
| <model_name> | <v> | READY |
| .. | . | .. |
| .. | . | .. |
+----------------------+---------+--------+
...
...
...
I1002 21:58:57.891440 62 grpc_server.cc:3914] Started GRPCInferenceService at 0.0.0.0:8001
I1002 21:58:57.893177 62 http_server.cc:2717] Started HTTPService at 0.0.0.0:8000
I1002 21:58:57.935518 62 http_server.cc:2736] Started Metrics Service at 0.0.0.0:8002

- 验证是否正常运行
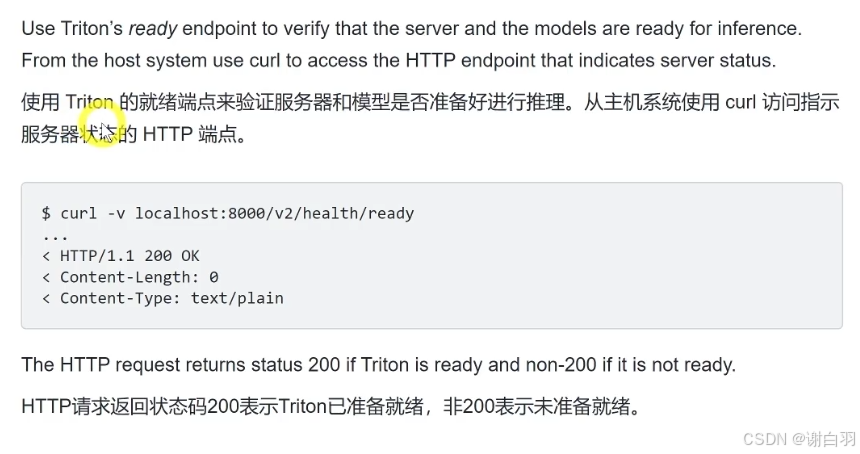
$ curl -v localhost:8000/v2/health/ready
...
< HTTP/1.1 200 OK
< Content-Length: