新版LangChain向量数据库VectorStore设计详解
导读:在大型语言模型与知识库集成的实践中,向量数据库的选择和架构设计往往成为项目成败的关键因素。本文深入剖析了LangChain框架中VectorStore的核心设计理念,为开发者提供了系统性的技术指导和实践方案。
文章揭示了LangChain如何通过抽象类设计实现向量数据库的统一接口规范,使开发者能够在Milvus、Pinecone、Chroma等不同存储引擎间灵活切换,而无需修改上层业务逻辑。通过详细解析from_documents()与add_documents()方法的设计差异,文章阐明了批量初始化与增量更新的最佳实践策略。
简介
本文深入探讨新版LangChain中向量数据库VectorStore的设计理念和核心架构,为开发者提供全面的技术指导。
本文继上一篇文章进一步讲述:MMR搜索和LangChain整合Milvus实战
LangChain向量存储体系架构
RAG系统核心设计模式
LangChain采用了标准化的RAG(Retrieval-Augmented Generation)处理流程:
Document↓
Text Splitter↓
Embedding Model↓
VectorStore ↔ [Milvus | Chroma | Pinecone ...]
LangChain通过设计抽象类VectorStore来统一接口规范,具体的实现则由各个向量数据库厂商负责。这种设计模式确保了系统的可扩展性和互操作性。
环境配置
在使用向量存储功能前,需要安装相应的依赖包:
pip install langchain-milvus
核心导入语句:
from langchain_core.vectorstores import VectorStore
注意:官方文档链接 https://python.langchain.com/docs/integrations/vectorstores/ (如果过期请忽略)
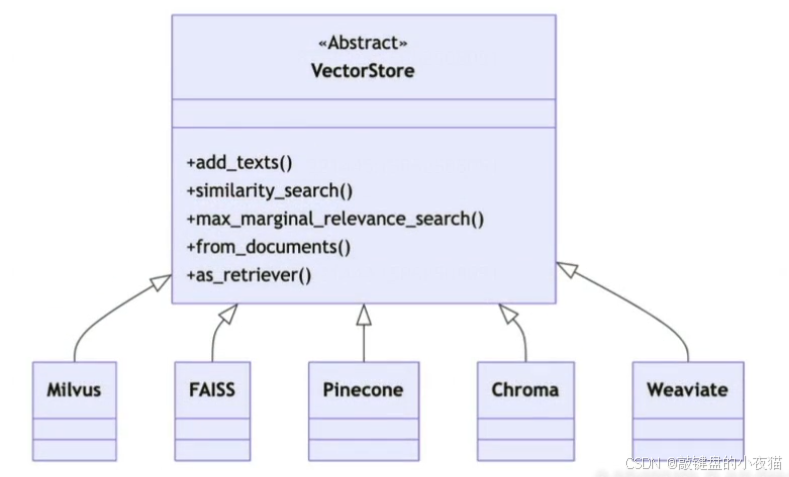
VectorStore核心方法详解
通用方法概览
| 方法名 | 作用描述 | 常用参数示例 |
|---|---|---|
| from_documents() | 从文档创建向量库 | documents, embedding, **kwargs |
| add_documents() | 追加文档到已有库 | documents |
| similarity_search() | 相似度查询 | query, k=4 |
| similarity_search_with_score() | 带相似度得分的查询 | query, k=4 |
| max_marginal_relevance_search() | MMR最大边界搜索 | query, k=4 |
| as_retriever() | 转换为检索器供链式调用 | search_kwargs={} |
初始化方法详解
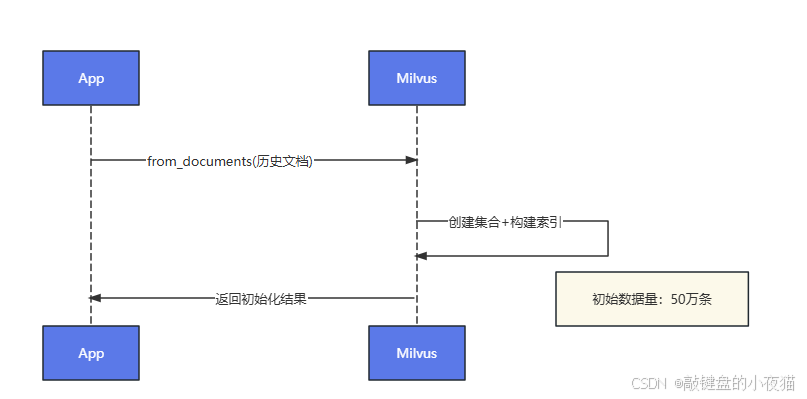
from_documents() 方法
@classmethod
def from_documents(cls,documents: List[Document],embedding: Embeddings,**kwargs
) -> VectorStore:"""文档自动转换存储:param documents: LangChain Document对象列表:param embedding: 文本向量化模型:param kwargs: 向量库特有参数:return: 初始化的VectorStore实例"""
参数详细说明
- @classmethod:这是一个类方法,可以通过类名直接调用,无需先实例化类
- cls:类方法的第一个参数,表示类本身
- documents:类型为
List[Document],表示输入的文档列表,这些文档是LangChain中的Document对象 - embedding:类型为
Embeddings,表示用于将文本转换为向量的模型 - kwargs:关键字参数,用于传递向量库特有的参数
- 返回值:返回一个初始化的VectorStore实例
实际应用示例
from langchain.document_loaders import UnstructuredFileLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma# 加载文档
loader = UnstructuredFileLoader("path/to/your/documents")
documents = loader.load()# 初始化向量存储
vectorstore = Chroma.from_documents(documents,OpenAIEmbeddings(),persist_directory="./my_chroma_db"
)
在这个示例中,我们首先使用UnstructuredFileLoader加载文档,然后使用Chroma.from_documents方法将这些文档转换为向量并存储在本地数据库中。
from_documents() 与 add_documents() 方法对比
| 特性 | from_documents() | add_documents() |
|---|---|---|
| 方法类型 | 类方法(静态方法) | 实例方法 |
| 主要用途 | 初始化集合并批量插入文档 | 向已存在的集合追加文档 |
| 集合创建 | 自动创建新集合 | 要求集合已存在 |
| 性能消耗 | 高(需建索引+数据迁移) | 低(仅数据插入) |
| 典型场景 | 首次数据入库 | 增量数据更新 |
| 连接参数 | 需要完整连接配置 | 复用已有实例的配置 |
数据插入方法
def add_texts(self,texts: Iterable[str],metadatas: Optional[List[dict]] = None,**kwargs
) -> List[str]:"""插入文本数据到向量库:param texts: 文本内容列表:param metadatas: 对应的元数据列表:return: 插入文档的ID列表"""
相似性搜索方法
def similarity_search(self,query: str,k: int = 4,filter: Optional[dict] = None,**kwargs
) -> List[Document]:"""执行相似性搜索:param query: 查询文本:param k: 返回结果数量:param filter: 元数据过滤条件:return: 匹配的Document列表"""
最大边界相关算法(MMR)
def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,lambda_mult: float = 0.5
) -> List[Document]:"""多样性增强搜索:param query: 查询文本:param k: 最终返回数量:param fetch_k: 初始获取数量:param lambda_mult: 多样性权重 (0-1)"""
不同向量数据库特性对比
需要注意的是,不同向量数据库在功能支持方面存在差异:
| 特性 | Milvus | FAISS | Pinecone | Chroma |
|---|---|---|---|---|
| 分布式支持 | ✓ | × | ✓ | × |
| 元数据过滤 | ✓ | × | ✓ | ✓ |
| 自动索引管理 | ✓ | × | ✓ | ✓ |
| 本地运行 | ✓ | ✓ | × | ✓ |
| 相似度算法 | 8种 | 4种 | 3种 | 2种 |
总结
LangChain的VectorStore设计通过统一的抽象层提供了灵活而强大的向量存储解决方案。开发者可以根据具体需求选择合适的向量数据库实现,同时享受统一的API接口带来的便利性。在实际应用中,建议根据项目的规模、性能要求和部署环境来选择最适合的向量数据库。