HTML应用指南:利用GET请求获取全国罗森门店位置信息
罗森作为全球知名的便利店连锁品牌,自1939年创立以来,始终致力于为消费者提供高品质、便捷的购物与服务体验。在中国市场,罗森凭借其丰富的商品种类、灵活的营业时间和高效的配送服务,逐渐赢得了广大消费者的青睐。品牌通过不断拓展门店网络、优化线上服务体系,以及推出符合本土消费需求的新品商品,成功在竞争激烈的零售市场中占据了一席之地。
本文将探讨如何利用GET请求从罗森中国官方网站获取门店分布信息,并展示使用Python的requests库发送GET请求的方法,以提取详细的门店地址、营业时间、联系方式等关键信息。这些数据覆盖全国范围内的所有罗森门店,并通过解析API返回的JSON格式响应数据进行处理,最终整理出结构化的门店列表。通过对这些门店数据的分析,不仅可以全面了解罗森在国内市场的扩张趋势与区域布局特点,还能为消费者提供便捷的门店查询服务,提升整体用户体验。此外,结合各城市的门店密度、选址特征及周边消费环境,还可以深入洞察不同地区的消费偏好差异,从而为罗森未来的产品开发策略、营销活动策划以及新店选址提供有力的数据支持与决策依据。
罗森门店位置查询:店铺地址 - 上海罗森
我们第一步先找到门店数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
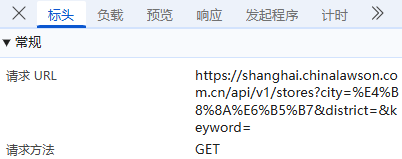
负载:对于GET请求:负载通常包含了传递的参数,这里我们可以看到它的传参包括,城市名,还是明文,没有进行加密;
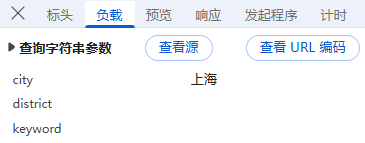
预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;
接下来就是数据获取部分,先讲一下方法思路,一共三个步骤;
方法思路
- 找到对应数据存储位置,获取所有店铺列表的相关标签数据;
- 根据不同城市的链接了解网站规律,接下来改变查询关键字,来遍历全国门店数据;
- 坐标转换,通过coord-convert库实现GCJ-02转WGS84;
因为罗森不是所有城市都有门店,我们可以通过网站自带的城市列表,进行遍历里面的城市关系列表作为查询的城市字典结构进行后续的遍历;
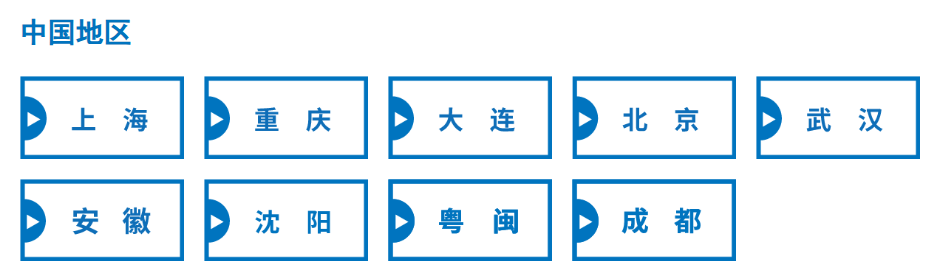
第一步:我们先找到对应数据存储位置,获取所有门店列表,经过测试,每次查询一个城市关键词会对应一个html,我们通过修改关键词来进行数据获取,以上海为例,只要修改URL里面的cities对应的关键词即可,即江苏,浙江共用同一个URL,只有city关键词需要变动;
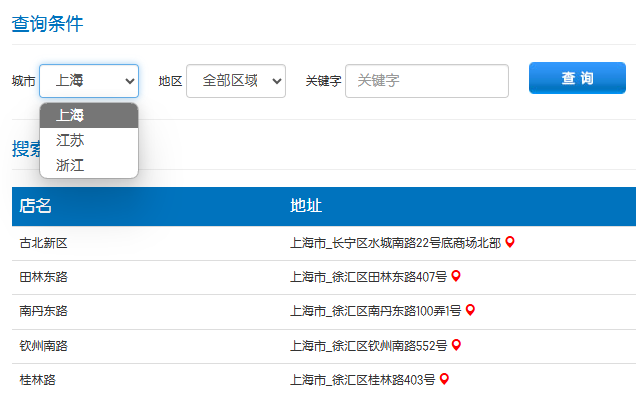
但是换到其他对应城市的链接,就需要同时修改城市的网址拼音和,city对应的关键词,这里以大连为例,需要修改连接的拼音和city二个部分才可以执行查询,但是其同等行政区级别的丹东市就只需要修改city对应的关键词即可;
![]()
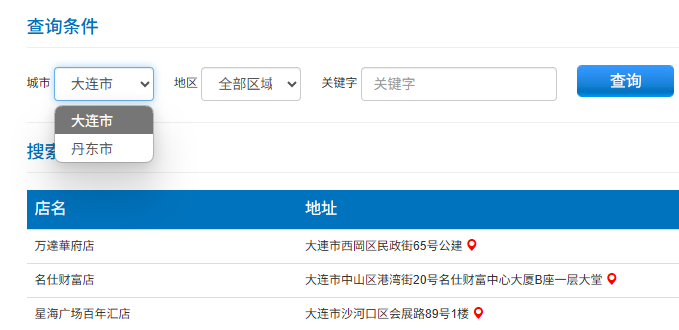
第二步:利用GET请求获取所有店铺列表,并根据标签进行保存,另存为csv,这里以上海、江苏、浙江为例;
完整代码#运行环境 Python 3.11
import requests
import csv# 定义要遍历的城市
cities = ["上海", "江苏", "浙江"]def fetch_store_data(city_name):"""获取指定城市的门店数据"""url = "https://shanghai.chinalawson.com.cn/api/v1/stores"# 使用字典管理请求参数request_params = {"city": city_name,"district": "","keyword": ""}headers = {"User-Agent": "Mozilla/5.0"}response = requests.get(url, params=request_params, headers=headers)if response.status_code == 200:try:return response.json()except Exception as e:print(f"解析 {city_name} 数据失败: {e}")return []else:print(f"请求 {city_name} 失败,状态码:{response.status_code}")return []def save_to_csv(stores, filename):"""将门店数据保存到CSV文件"""with open(filename, mode='w', newline='', encoding='utf-8-sig') as file:writer = csv.DictWriter(file, fieldnames=['id', 'name', 'city', 'district', 'address', 'tel','latitude', 'longitude'])writer.writeheader()for store in stores:store_id = store.get("id")name = store.get("name")city = store.get("city")district = store.get("district")address = store.get("address")coords = store.get("coords")tel = store.get("tel") or "无"# 拆分坐标if coords and ',' in coords:latitude, longitude = coords.split(',')else:latitude, longitude = "", ""writer.writerow({'id': store_id,'name': name,'city': city,'district': district,'address': address,'tel': tel,'latitude': latitude.strip(),'longitude': longitude.strip()})# 存储所有城市的门店数据
all_stores = []for city_name in cities:print(f"正在获取 {city_name} 的门店数据...")stores = fetch_store_data(city_name)all_stores.extend(stores)# 将所有门店数据保存为 CSV 文件
save_to_csv(all_stores, 'luosen_stores.csv')print("所有城市的门店数据已成功保存到文件:luosen_stores.csv")获取数据标签如下,id(店铺编码)、name(店铺名称)、city(城市)、distinct(行政区)、address(详细地址)、tel(电话)、coords(坐标)坐标这里通过脚本拆成了两列,其他一些非关键标签,这里省略;
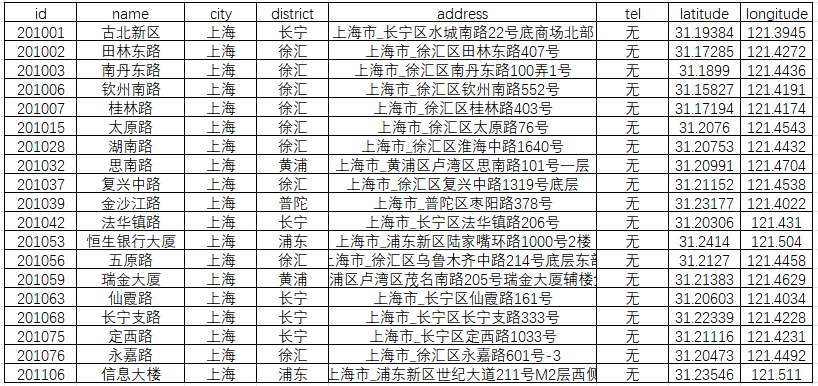
第三步:坐标系转换,由于罗森门店数据使用的是高德坐标系(GCJ-02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ-02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地图坐标系批量转换 - 免费在线工具;
对CSV文件中的门店坐标列进行转换。完成坐标转换后,再将数据导入ArcGIS进行可视化;
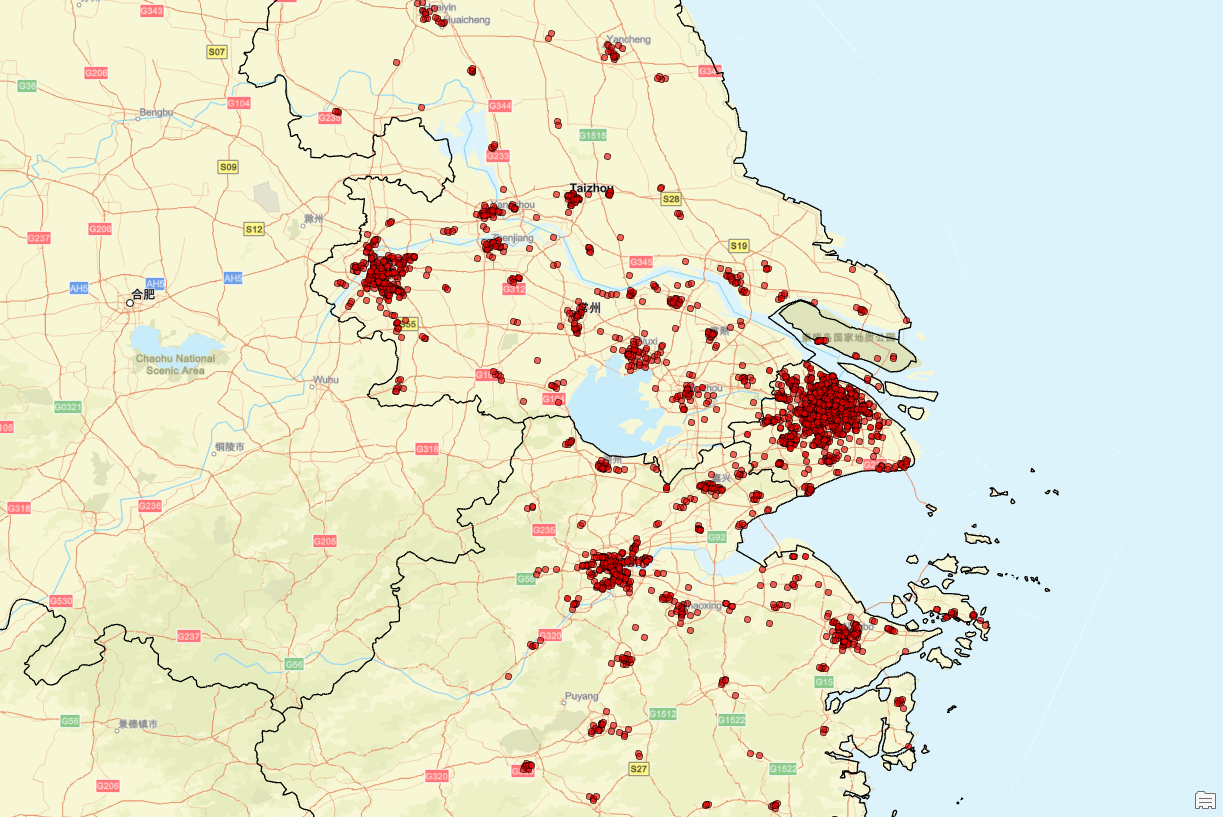
接下来,我们进行看图说话:
罗森在上海、江苏和浙江的分布情况显示出其在这些地区具有广泛的布局,特别是在经济发达的城市和人口密集区。具体来说,在上海,罗森门店几乎遍布整个市区,尤其是在浦东新区、徐汇区等核心区域,门店密度非常高,这表明了罗森在上海市场上的强势地位以及对本地消费者的高度覆盖。
对于江苏省而言,罗森门店主要集中在南部城市,如苏州、无锡、常州等地,其中南京市也有不少门店,但总体来看,北部城市的门店数量较少,分布较为稀疏。这种布局反映了罗森倾向于选择经济发展水平较高、消费能力较强的区域进行重点发展。
浙江省内,罗森的门店则更多地集中于北部和东部沿海地区,比如杭州、宁波和温州等城市。特别是杭州市,作为浙江省的政治经济中心,拥有较高的门店密度,显示了罗森对这一重要市场的重视。而在西部山区,由于地理条件限制,门店数量相对较少且分布分散。
整体来看,罗森门店的分布与各地区的经济发展水平、人口密度及交通便利性密切相关,体现出其以经济发达地区为优先考虑的选址策略。此外,通过地图分析可以直观地看出罗森在长三角地区内的战略布局,以及如何根据不同的市场需求进行门店分布调整。这种分布模式不仅有助于品牌提高市场份额,还能更好地服务于当地居民,满足他们的日常需求。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。