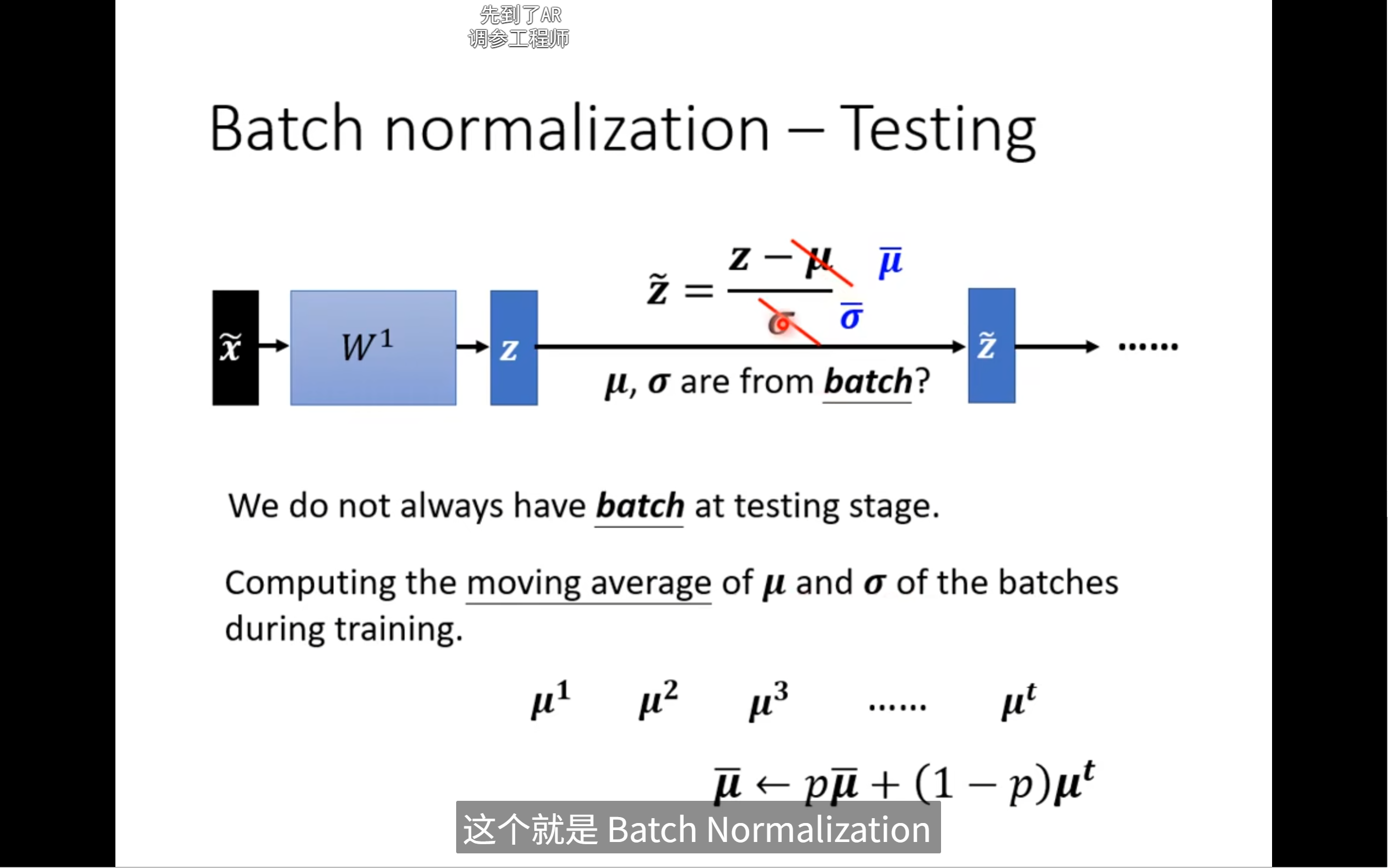
Batch Normalization[[
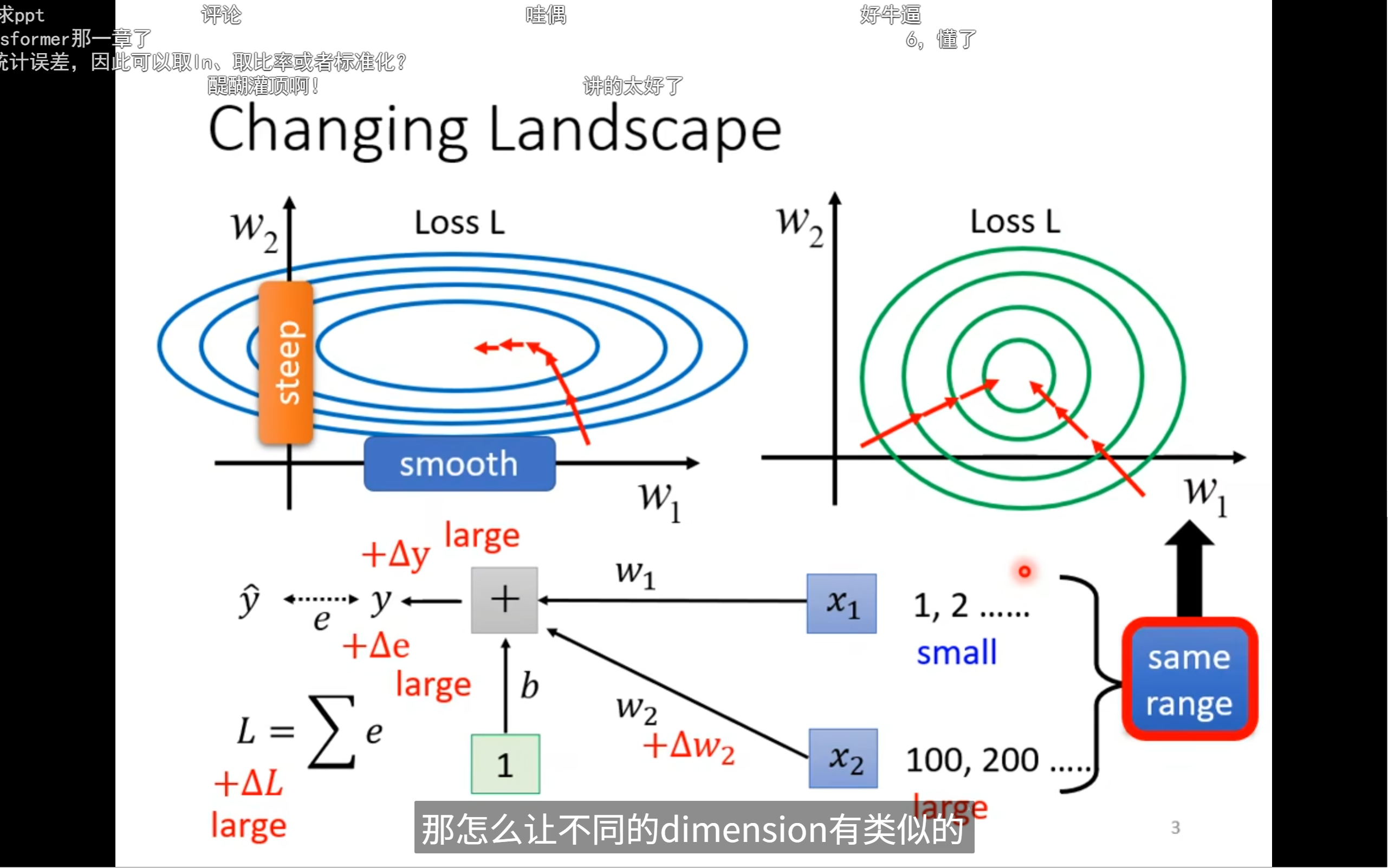
error surface如果很崎岖,那么就代表比较难train,我们有没有办法去改变这个landscape呢
可以用batch normalization.
- 如果 ( x_1 ) 的取值范围很小(如 1, 2),而 ( x_2 ) 的取值范围很大(如 100, 200),那么 ( w_2 ) 的变化会对输出 ( \hat{y} ) 产生更大的影响,进而导致损失 ( L ) 的变化也很大(+ΔL large)。
- 这会导致梯度更新时,某些方向变化很大,某些方向变化很小,优化过程不平衡。
- 如果特征的尺度差异很大,损失函数的地形会很“陡峭”或“扁平”,导致梯度下降时路径弯曲,优化困难。
- 经过特征归一化后,损失函数的地形变得“圆滑”,各个方向变化一致,优化路径更直接,收敛更快。
我们想要这个loss landscape变得平滑,就要进行特征归一化
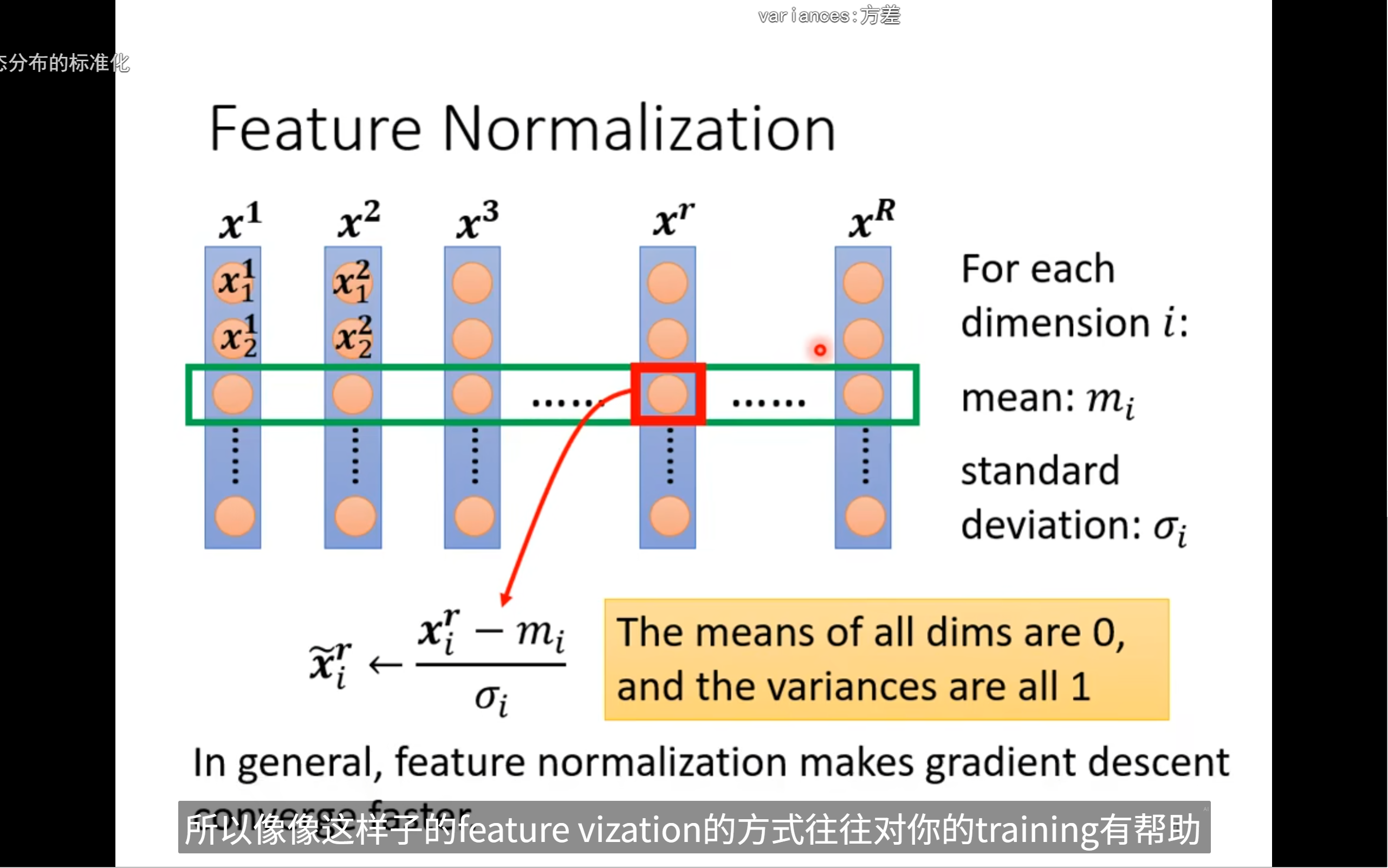
feature normalization
将每一维的数值特征归一化,使他们平均为0,方差为1
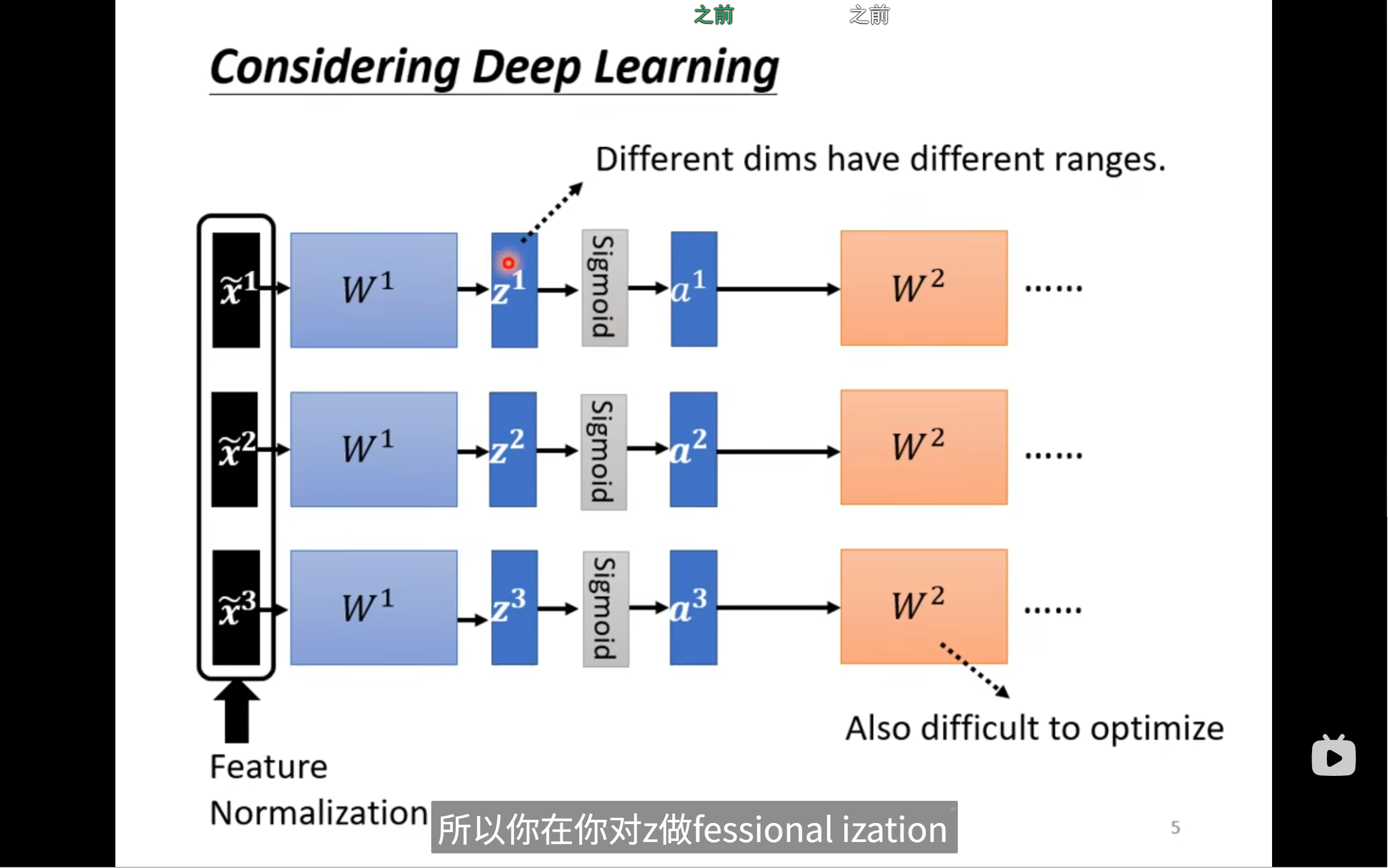
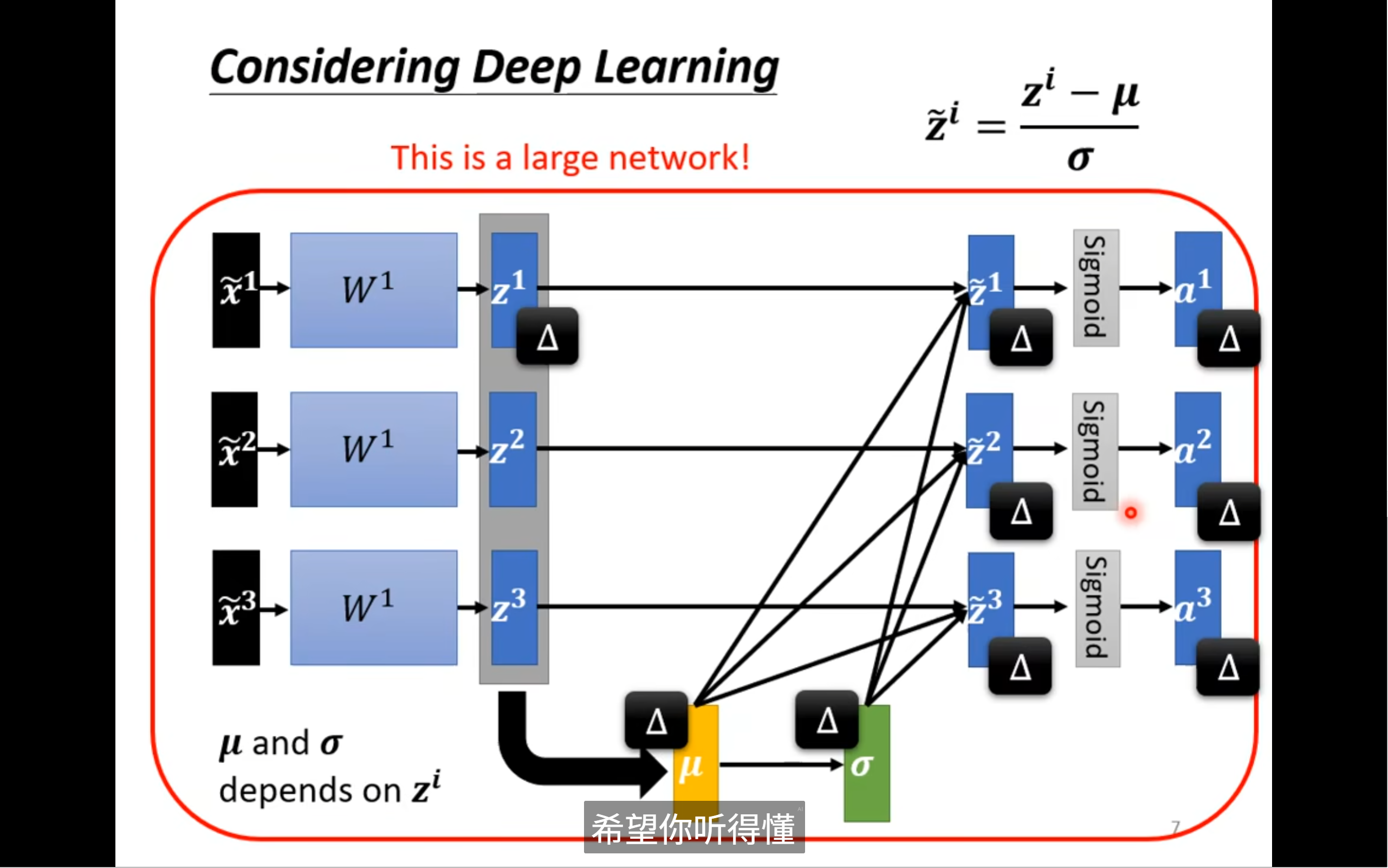
我们经过一层normalization后的x经过w得到z再经过activate function得到a,那么a和z实际上对w2是input,那么就有可能特征差异大,所以要在z或者a再做一次normalization,在哪里做其实差异不大
z是向量/矩阵,但是经过normalization后,每一个z的小改变就会引起后面三个a的改变,相比input时候是单独改变
为什么说这个network是一个large的network?
归一化操作本身就把原本“每个样本独立”的网络,变成了“所有样本互相关联”的大网络
因为我们没办法把所有的这个data都进行normalization,改为在一个batch做normalization
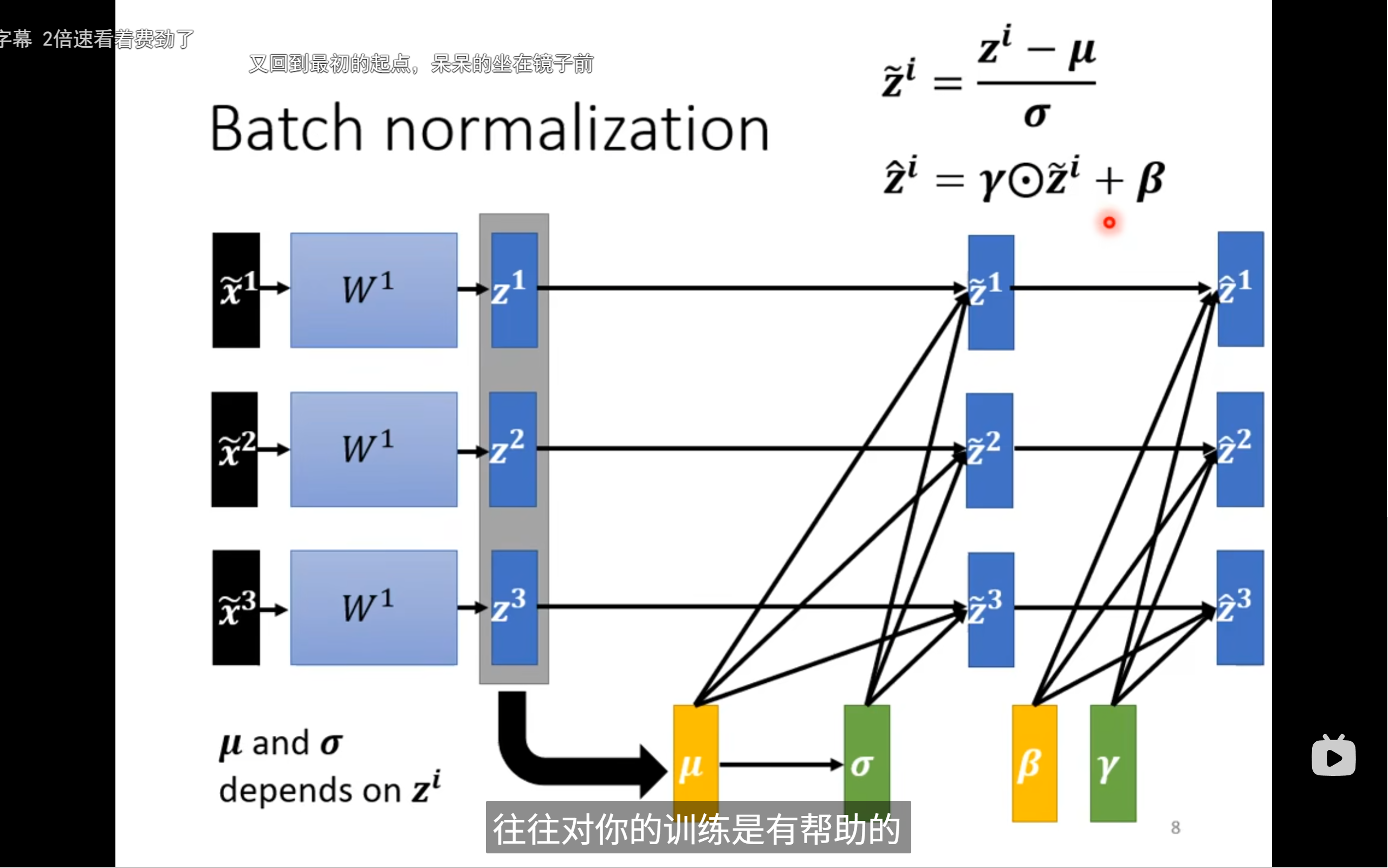
我们再归一化之后还要让机器learn出来γ和β干什么呢?这样子不就会导致我们每一个dimension的分布不接近了吗?
我们一开始会设置两个参数向量分别为1和0,让训练初期的dimension分布比较接近,找到一个好的error surface后再慢慢加进去
如果我们真正在做application的时候,资料不是一个batch的传进来,我们无法累计到一个batch再计算,我们就得用滑动平均来计算