Dolphin文档解析从理论到实践——保姆级教程
论文:https://arxiv.org/abs/2505.14059
代码:github.com/bytedance/Dolphin
2025年5月,字节开源了文档解析Dolphin,让文档解析效率提升83%。本文将深入解析字节跳动最新开源的Dolphin模型,先看理论再实战体验。
现实世界中约80%的有价值信息都被"囚禁"在非结构化文档中——PDF学术论文、企业报告、技术文档、医疗记录。这些"沉睡的数据资产"如同被锁在保险柜中的黄金,等待着被解放的钥匙。
一. 理论
1. 文档解析面临的挑战
文档解析表面上看似直观——将图像转换为可编辑文本。但深入分析后发现,这是一个涉及计算机视觉、自然语言处理、布局分析、结构理解的多维度挑战:
- 视觉复杂性:从手写笔记到精美排版,从单栏文本到多栏布局
- 内容异构性:文本、表格、公式、图表、化学结构式的混合出现
- 结构层次性:标题、段落、列表、脚注的层次关系
- 语言多样性:多语言混排、专业术语、数学符号
- 质量差异性:扫描质量、拍照角度、光照条件的不一致
2. 目前的解决方案
传统路径:集成式专家系统——通过不同的算法模块组合和逻辑策略实现文档解析(例如Paddle OCR),技术框架如下图所示。
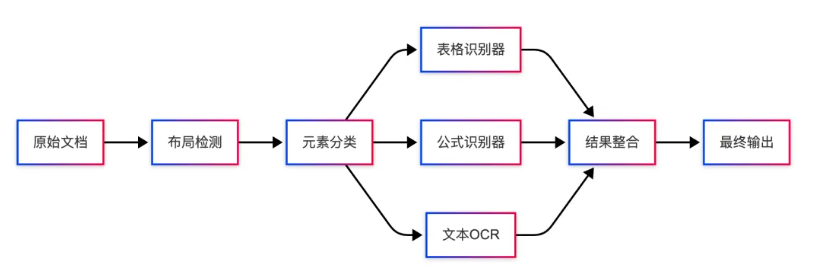
优势:每个专家模型在特定任务上精度较高
缺点如下:
- 错误累积效应:前一阶段的错误会被放大传递
- 系统复杂度高:需要维护多个模型和复杂的协调机制
- 结构丢失风险:在模型间传递过程中容易丢失全局结构信息
- 效率瓶颈:串行处理导致延迟累积
多模态视觉-语言大模型解决方案,以Qwen2.5 VL、GPT-4V为代表,采取一步到位的策略,实现路径如下图所示。

优势:架构简洁,能够利用大模型的泛化能力
缺点如下:
- 效率困境:自回归解码的串行特性导致处理速度慢
- 结构丢失:长序列生成过程中容易丢失布局信息
- 资源消耗:需要大规模模型才能达到可用精度
- 控制困难:难以精确控制输出格式和结构
3. Dolphin是如何实现的?

- Dolphin模型以322M的轻量级参数量,在所有评测指标上都取得了最优性能
- 处理效率方面,Dolphin达到0.1729 FPS,比第二名Mathpix(0.0944 FPS)快近2倍
- 相比动辄数千亿参数的通用VLM和复杂的集成式方案,Dolphin在保持轻量化的同时实现了专业文档解析的最佳效果
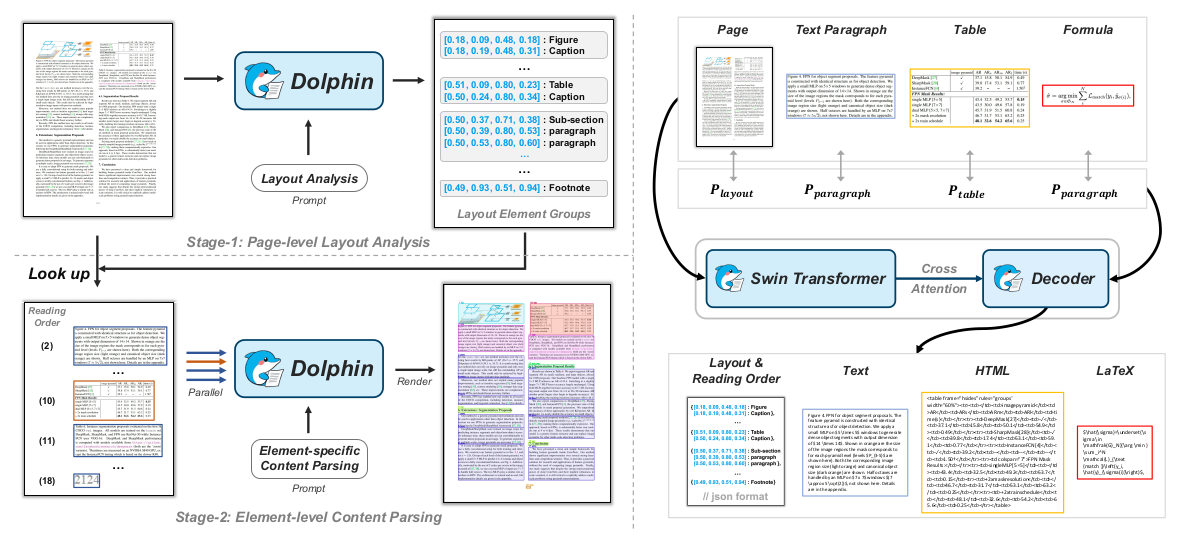
那么Dolphin是如何实现的呢?下图展示了Dolphin的算法架构:
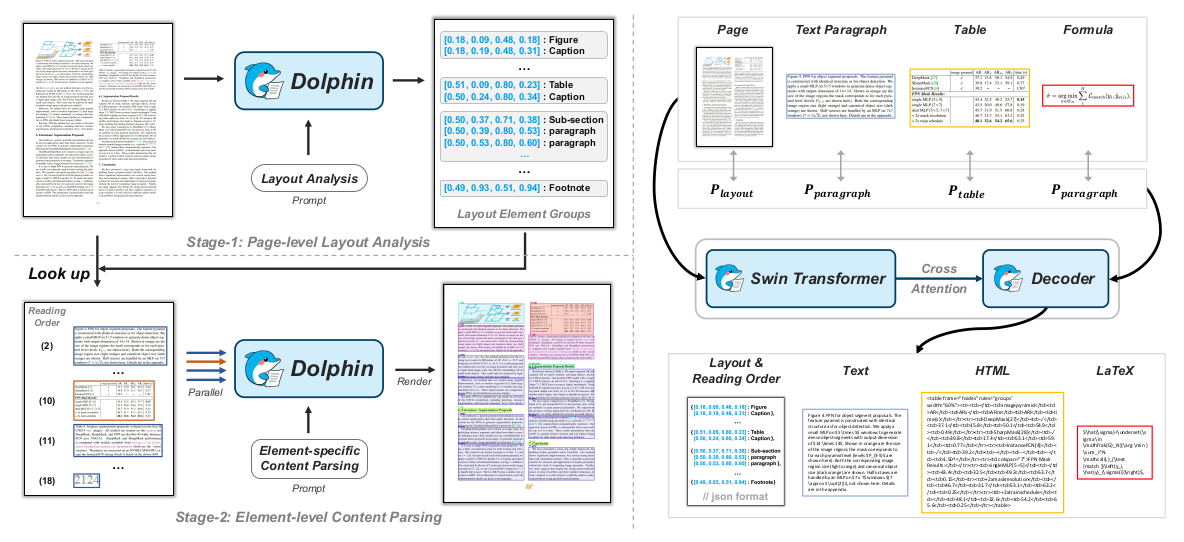
布局分析模块:确定自然阅读顺序、识别元素块类别、检测元素块的bbox,元素块包括:段落、表格、图片、公式等。
# 伪代码示例
def stage1_layout_analysis(document_image):visual_features = swin_transformer(document_image)layout_prompt = "Parse the reading order of this document."layout_sequence = mbart_decoder(visual_features, layout_prompt)return structured_elements # [(type, bbox, reading_order), ...]
元素内容解析模块:根据元素的类别对应不同的提示词,并对元素块进行并行解析,从而实现元素级别的内容识别。
# 伪代码示例
def stage2_content_parsing(document_image, layout_elements):results = []for element in layout_elements:cropped_region = crop_image(document_image, element.bbox)task_prompt = get_prompt_by_type(element.type)content = mbart_decoder(cropped_region, task_prompt)results.append((element, content))return parallel_process(results) # 并行处理
4. Dolphin设计亮点
共享编解码器,同一个模型实现布局分析模块和元素内容解析模块。仅通过提示词差异化实现功能分化,如下表所示:
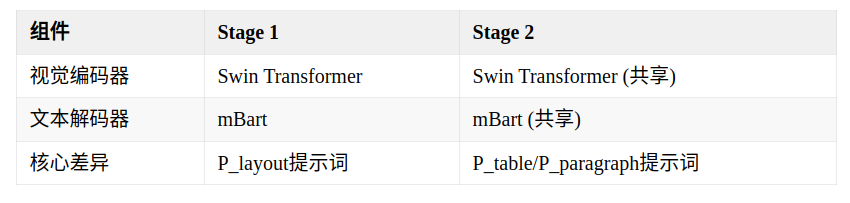
PROMPTS = {"layout": "Parse the reading order of this document.","table": "Extract table structure and content in HTML format.","paragraph": "Extract text content preserving structure.","formula": "Convert mathematical formula to LaTeX format."
}
元素块并行解析,实现效率的提升
二. 实践
1. 获取代码并配置环境
# 获取代码
git clone https://github.com/ByteDance/Dolphin.git
cd Dolphin# 配置环境
pip install -r requirements.txt
2. 下载模型并测试
模型下载地址:https://drive.google.com/drive/folders/1PQJ3UutepXvunizZEw-uGaQ0BCzf-mie
下载的模型放在./checkpoints目录下
测试代码脚本:
python demo_page.py --config ./config/Dolphin.yaml --input_path ./demo/page_imgs/page_1.jpeg --save_dir ./results
3. 结果可视化
# 更多精彩,请关注微信公众号:AIWorkshopLab
import json
from PIL import Image, ImageDraw, ImageFont
import osdef draw_layout_on_image(img_path, layout_json_path, output_path):"""在图片上绘制layout信息Args:img_path: 图片路径layout_json_path: layout.json文件路径output_path: 输出图片路径"""# 1. 用PIL读取图片img = Image.open(img_path)draw = ImageDraw.Draw(img)# 2. 读取layout.json数据with open(layout_json_path, 'r', encoding='utf-8') as f:layout_data = json.load(f)# 定义不同label的颜色label_colors = {'tab': '#FF0000', # 红色 - 表格'cap': '#00FF00', # 绿色 - 标题'sec': '#0000FF', # 蓝色 - 章节'para': '#FF00FF', # 紫色 - 段落'pic': '#FFFF00', # 黄色 - 图片'fig': '#FFFF00', # 黄色 - 图片'list': '#00FFFF', # 青色 - 列表'formula': '#FFA500', # 橙色 - 公式'footnote': '#800080', # 紫红色 - 脚注'header': '#008000', # 深绿色 - 页眉'footer': '#800000' # 深红色 - 页脚}# 尝试加载支持中文的字体font_large = Nonefont_small = None# 常见的中文字体路径列表chinese_font_paths = ["/usr/share/fonts/truetype/wqy/wqy-microhei.ttc","/usr/share/fonts/truetype/wqy/wqy-zenhei.ttc", "/usr/share/fonts/truetype/arphic/ukai.ttc","/usr/share/fonts/truetype/arphic/uming.ttc"]# 尝试加载中文字体for font_path in chinese_font_paths:try:if os.path.exists(font_path):font_large = ImageFont.truetype(font_path, 16)font_small = ImageFont.truetype(font_path, 12)print(f"成功加载字体: {font_path}")breakexcept Exception as e:continue# 如果没有找到中文字体,尝试使用英文字体if font_large is None:try:font_large = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf", 16)font_small = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 12)print("使用英文字体")except:print("警告: 无法加载任何字体,将使用基本绘制方式")def safe_text_length(text, font):"""安全地计算文本长度,处理编码错误"""try:if font:return draw.textlength(text, font=font)else:# 简单估算:中文字符按2个字符宽度,英文按1个字符宽度chinese_chars = sum(1 for char in text if ord(char) > 127)english_chars = len(text) - chinese_charsreturn chinese_chars * 12 + english_chars * 6 # 估算宽度except UnicodeEncodeError:# 如果遇到编码错误,使用简单估算chinese_chars = sum(1 for char in text if ord(char) > 127)english_chars = len(text) - chinese_charsreturn chinese_chars * 12 + english_chars * 6def safe_draw_text(x, y, text, fill, font=None):"""安全地绘制文本,处理编码错误"""try:if font:draw.text((x, y), text, fill=fill, font=font)else:draw.text((x, y), text, fill=fill)except UnicodeEncodeError:# 如果遇到编码错误,尝试只绘制ASCII字符ascii_text = ''.join(char if ord(char) < 128 else '?' for char in text)draw.text((x, y), ascii_text, fill=fill, font=font if font else None)# 3. 遍历layout数据并绘制for item in layout_data:label = item['label']bbox = item['bbox'] # [x1, y1, x2, y2]reading_order = item['reading_order']text = item.get('text', '')# 获取颜色,如果没有定义则使用默认颜色color = label_colors.get(label, '#808080')# 绘制边界框draw.rectangle(bbox, outline=color, width=3)# 绘制label和reading_orderlabel_text = f"{label}({reading_order})"# 计算文本位置(在框的左上角)text_x = bbox[0]text_y = bbox[1] - 20 if bbox[1] > 20 else bbox[1] + 5# 绘制背景矩形使文字更清晰try:if font_large:text_bbox = draw.textbbox((text_x, text_y), label_text, font=font_large)draw.rectangle(text_bbox, fill='white', outline=color)safe_draw_text(text_x, text_y, label_text, color, font_large)except:# 如果出错,使用简单方式绘制safe_draw_text(text_x, text_y, label_text, color)# 如果文本内容不为空且不是表格HTML,显示部分文本内容if text and not text.startswith('<table>'):# 截取前30个字符避免文本过长(中文字符较宽)display_text = text[:30] + "..." if len(text) > 30 else textdisplay_text = display_text.replace('\n', ' ') # 替换换行符# 在框内显示文本内容content_x = bbox[0] + 5content_y = bbox[1] + 25# 简化文本处理,避免复杂的换行逻辑导致编码错误if font_small:# 计算可用宽度available_width = bbox[2] - bbox[0] - 10# 简单的文本截断,避免复杂的分词逻辑max_chars = max(1, available_width // 8) # 估算每个字符8像素宽度if len(display_text) > max_chars:display_text = display_text[:max_chars] + "..."# 绘制文本if content_y < bbox[3] - 15: # 确保不超出框的底部safe_draw_text(content_x, content_y, display_text, 'black', font_small)else:safe_draw_text(content_x, content_y, display_text, 'black')# 4. 保存结果img.save(output_path)print(f"结果已保存到: {output_path}")def main():# 设置文件路径img_path = "./test.png"layout_json_path = "./results/recognition_json/test.json"output_path = "./test_visualization.png"# 检查文件是否存在if not os.path.exists(img_path):print(f"图片文件不存在: {img_path}")returnif not os.path.exists(layout_json_path):print(f"JSON文件不存在: {layout_json_path}")return# 创建输出目录(如果输出路径包含目录)output_dir = os.path.dirname(output_path)if output_dir:os.makedirs(output_dir, exist_ok=True)# 执行绘制draw_layout_on_image(img_path, layout_json_path, output_path)if __name__ == "__main__":main()
测试结果如下,左图是输入图片,右图是可视化结果。
博主思考:Dolphin在文档解析精度和解析效率达到了SOTA,代码架构简单,是未来的发展趋势。虽然在复杂板式和竖排文字识别上还有些问题,但是通过添加数据并适当加大模型应该是可以解决的。
感谢关注,喜欢记得给博主点赞~