高效推理引擎深度解析:vLLM 与 TGI 架构设计与性能实战指南
高效推理引擎深度解析:vLLM 与 TGI 架构设计与性能实战指南
一、引言:大模型部署的“最后一公里”挑战
大型语言模型(LLMs)的蓬勃发展无疑正在重塑人工智能应用的版图。然而,将这些强大的模型高效部署到实际生产环境,即所谓的“最后一公里”,依然是一项充满挑战的任务。推理服务的延迟(Latency)、吞吐量和资源利用率不仅直接决定了用户体验的优劣,也深刻影响着企业的运营成本。特别是在面临高并发请求、处理长序列输入或执行复杂的多模态任务时,传统的推理框架往往会遭遇内存碎片化、批处理效率低下等性能瓶颈。
为了攻克这些难题,vLLM 和 TGI (Text Generation Inference) 作为业界领先的高性能推理引擎应运而生。它们凭借创新的架构设计和精妙的优化策略,显著提升了大模型在实际应用中的服务效率。本文将深入剖析 vLLM 和 TGI 的核心架构,基于公开的基准测试数据详尽解读其性能表现,并提供从零开始、可复现的部署实践方案。最终,本文旨在为开发者在不同的业务场景下做出最优技术选型提供清晰、有力的指引。
二、架构设计深度解析:探寻性能之源
理解一个推理引擎的内部工作机制是准确评估其性能优劣和适用场景的关键。vLLM 和 TGI 在优化 LLM 推理方面采取了不同的设计哲学和技术路径,但都致力于提升效率和易用性。
2.1 vLLM:以 PagedAttention 为核心的内存与调度革命
vLLM 的设计哲学紧密围绕着解决 LLM 推理中最棘手的痛点之一——KV Cache 内存管理——而展开。其核心创新点在于:
- PagedAttention 机制(核心创新):
- 问题背景: 在传统的 LLM 推理过程中,每个请求在解码时都会生成 Key-Value (KV) Cache。这些 Cache 的大小会随着生成序列的长度动态变化,且其生命周期与请求绑定,导致难以预测的内存分配模式。这很容易引发严重的内存碎片化问题——即虽然 GPU 总空闲内存可能依然充足,但却因为缺乏足够大的连续内存块而无法容纳新的请求,从而严重限制了系统的并发处理能力和 GPU 利用率。
- 解决方案: vLLM 从操作系统的虚拟内存和分页管理中汲取灵感,提出了 PagedAttention 机制。它将 KV Cache 划分为固定大小的块(Blocks),类似于操作系统中的“页”。因此,一个逻辑上连续的 KV Cache 序列(属于单个请求)在物理显存中可以存储在这些非连续的块中。vLLM 通过维护一个“块表”(Block Table)来管理这些逻辑块到物理块的映射。
- 优势:
- 显著减少内存浪费: PagedAttention 通过允许 KV Cache 块在物理内存中非连续存储,几乎消除了内部碎片(块内未使用的部分极小)和外部碎片(无法利用的小空闲块)。内存利用率理论上可以达到 90% 以上。
- 高效的内存共享: 这是 PagedAttention 的一个强大特性。对于具有相同前缀(Prompt Tokens)的不同请求,它们可以共享这些前缀对应的 KV Cache 块。例如,多个用户可能使用相同的系统提示(System Prompt)或者在 Beam Search、并行采样等场景下,这种共享机制能大幅节省显存,并提高缓存命中率。这对 Prefix Caching(前缀缓存)和 Forking(请求分叉,即从一个已处理部分前缀的请求派生出多个具有不同后续输入的请求)等高级调度策略至关重要。
- 灵活的调度与高并发: 由于内存管理的粒度更细、更灵活,调度器可以更从容地处理请求的动态到达和离开,实现更高的并发量。例如,即使在显存接近饱和时,只要有足够数量的空闲块(无需连续),新请求依然可以被接纳和处理。

*图 1: PagedAttention 与传统 KV Cache 内存管理对比*
-
连续批处理 (Continuous Batching) / 动态调度:
- 与 TGI 等现代推理引擎类似,vLLM 也采用了 Continuous Batching 策略。这意味着请求不必等到一个完整的批次(batch)中所有序列都生成完毕才返回结果或释放资源。一旦某个序列生成完成,它就可以立即从批次中移除,其占用的资源(尤其是 KV Cache 块)可以被新的或正在等待的请求复用。
- 结合 PagedAttention,vLLM 的调度器能够更精细和动态地管理批次组合,有效地填充 GPU 计算的空闲间隙,从而最大化 GPU 的利用率。vLLM 还支持分块预填充(Chunked Prefill),这对于优化包含很长 Prompt 的请求处理特别有效,通过将长 Prompt 分成小块逐步计算其 KV Cache,避免单次过大的计算和内存占用。
-
优化的 CUDA Kernels:
- vLLM 包含了一系列高度优化的 CUDA Kernel,特别是为 PagedAttention 机制量身定制的 Kernel。这些 Kernel 能够高效地在非连续的内存块上执行注意力计算(Attention)和其他 Transformer 层操作,这是实现 PagedAttention 性能优势的关键底层支持。
-
架构演进与高级特性:
- 分布式推理 (Tensor Parallelism): vLLM 支持张量并行,可以将一个大型模型分布到多个 GPU 上进行推理,从而支持超出单卡显存容量的模型。
- 前缀缓存 (Prefix Caching): 利用 PagedAttention 的内存共享能力,vLLM 能够高效地实现前缀缓存。对于那些共享相同初始 Token 序列的请求(例如,在 RAG 场景中,多个用户查询可能都基于同一段背景知识文档),其 KV Cache 可以被复用,显著减少重复计算,降低延迟,提升吞吐。
- LoRA (Low-Rank Adaptation) 支持: vLLM 支持在推理时动态加载和切换 LoRA 适配器,这使得可以用一个基础模型服务于多个不同的微调任务,极大地提高了模型的复用性和灵活性。
- 投机性解码 (Speculative Decoding): vLLM 支持使用小型草稿模型进行投机性解码,以加速大型模型的生成速度。
-
多模态支持:
- vLLM 正在积极扩展对多模态模型的支持。例如,对于视觉语言模型 (VLM),它通过异步预处理流水线将图像解码/编码等 CPU 密集型任务从主推理流程中剥离并并行化。同时,利用多模态前缀缓存复用图像特征对应的 KV Cache,并可能缓存整个编码器的输出,从而显著提升 VLM 的推理效率。
2.2 TGI (Text Generation Inference):面向云原生的健壮与高效生成引擎
TGI (Text Generation Inference) 由 Hugging Face 主导开发,其设计目标更侧重于在生产环境中提供健壮性、易用性、可扩展性,并与广受欢迎的 Hugging Face 生态系统(如 transformers 库、Hugging Face Hub)进行深度集成。
-
核心技术特性:
- Continuous Batching (连续批处理): TGI 是较早采用并推广此技术的框架之一。它允许请求动态地加入和离开处理批次,显著提高了 GPU 的利用率和整体吞吐量,尤其是在请求长度和到达时间不均匀的场景下。
- 张量并行 (Tensor Parallelism): TGI 内置了基于
NCCL(NVIDIA Collective Communications Library) 的张量并行支持,使得用户可以相对轻松地将大型模型(如 Llama 70B)分布式部署在多张 GPU 卡上,甚至跨多个节点。 - 广泛的量化支持: TGI 对多种模型量化方案提供了良好的支持,例如
bitsandbytes(支持 NF4, INT8 等伪量化) 和GPTQ,AWQ,EETQ等流行的低比特权重量化技术。量化能够大幅降低模型的显存占用,使得在资源有限的硬件上部署大模型成为可能,同时也能带来一定的性能提升。(具体支持的量化类型和模型需查阅 TGI 最新版本的官方文档。) - Safetensors 格式优先: TGI 默认推荐并优先使用
safetensors格式加载模型权重。与传统的pickle格式 (通常是pytorch_model.bin文件) 相比,safetensors具有两大优势:- 安全性: 它不依赖
pickle,从而避免了pickle可能存在的任意代码执行风险。 - 快速加载与零复制:
safetensors文件可以直接通过内存映射(memory-mapping)方式加载权重,避免了额外的内存拷贝开销,从而显著加快模型的加载速度,尤其对于大型模型。
- 安全性: 它不依赖
- 优化的 Transformers 实现: TGI 内部集成了多种优化技术,例如 FlashAttention(及其变体,如 FlashAttention-2),用于加速注意力计算,这是 Transformer 模型中的计算瓶颈之一。
- Token Streaming (流式输出): 支持将生成的 Token 逐个或小批量地流式返回给客户端,这对于构建实时交互应用(如聊天机器人)至关重要。
-
架构设计:
- TGI 采用 Rust + Python 的混合编程模型。
- Rust 组件: 主要负责构建高性能、内存安全的 Web 服务器(通常基于
tonic(gRPC) 和axum(HTTP) 框架)以及请求管理、分词(tokenization)和调度逻辑。Rust 的性能和并发处理能力使其非常适合处理网络IO密集型和CPU密集型的前端任务。 - Python 组件: 负责核心的模型推理逻辑,这部分通常基于
PyTorch和 Hugging Facetransformers库。Python 生态的丰富性和易用性使得模型加载、修改和执行更为便捷。
- Rust 组件: 主要负责构建高性能、内存安全的 Web 服务器(通常基于
- 清晰的职责分离: 这种架构将网络服务、请求预处理/后处理与实际的模型推理计算分离开来。通常,Rust 编写的 Router/Launcher 进程接收外部请求,将其放入队列,然后由调度器(也可能在 Rust 中)分发给一个或多个 Python 推理工作进程。这些进程之间通过高效的进程间通信机制(如共享内存、Unix domain sockets 或 gRPC)进行数据交换。
- 这种设计不仅提升了性能和稳定性,也使得 TGI 更易于容器化部署(如通过 Docker)和在 Kubernetes 等编排平台上进行管理。
- TGI 采用 Rust + Python 的混合编程模型。
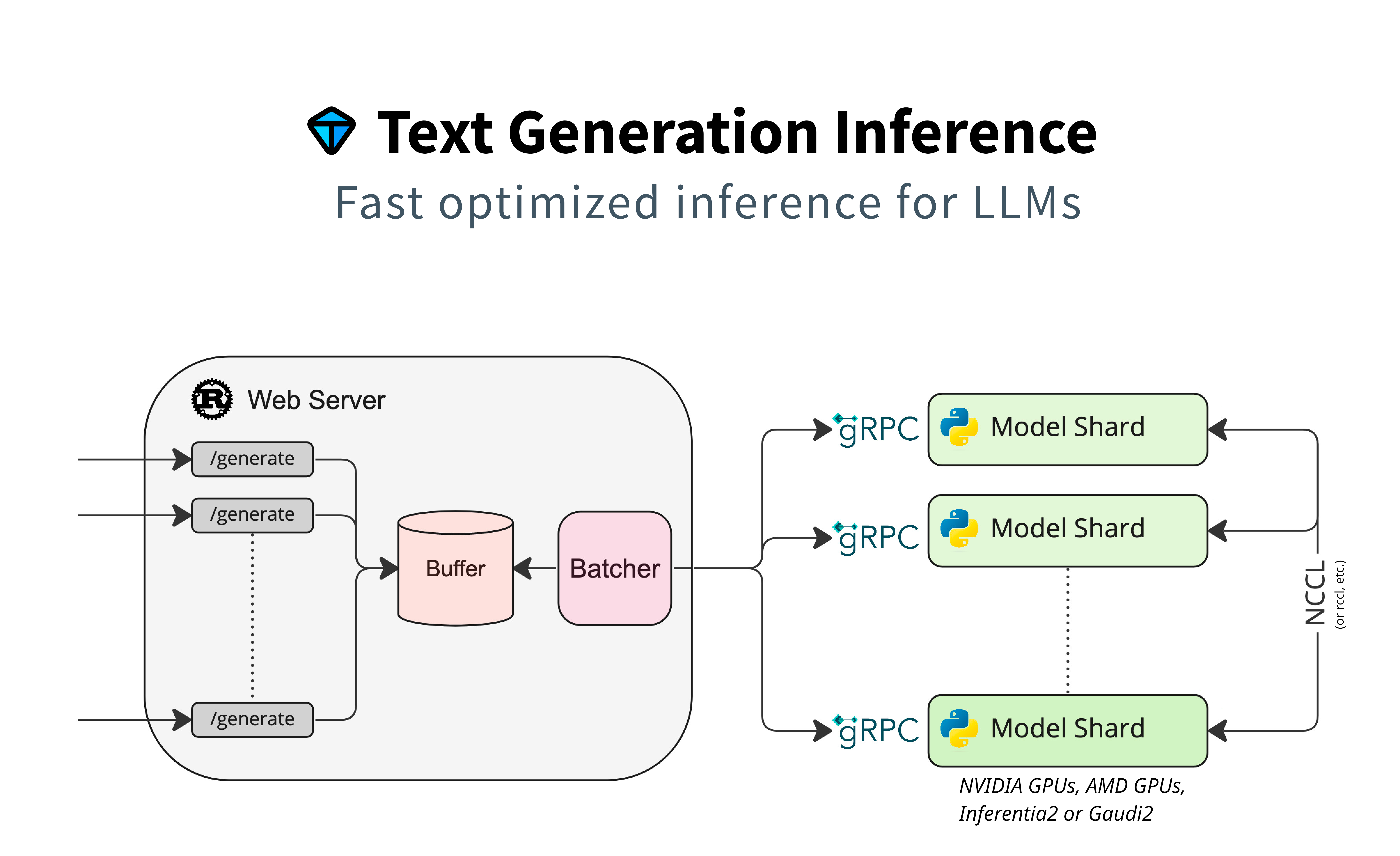
*图 2: TGI 架构示意图 (图片来源官网)*
- 模型兼容性与特性:
- TGI 原生支持 Hugging Face
transformers库中绝大多数主流的文本生成模型架构,如 Llama 系列、Falcon、Mistral/Mixtral、BLOOM、GPT-NeoX 等。用户通常只需指定 Hugging Face Hub 上的模型 ID 即可部署。 - 提供丰富的Logits Warpers(如温度采样 Temperature Sampling, Top-K, Top-P (Nucleus) Sampling)和Stopping Criteria(如最大新 Token 数、遇到特定停止符等),使得开发者可以精细地控制模型的生成过程和输出行为。
- Watermarking (水印): TGI 支持集成水印技术,用于追踪或识别由模型生成的文本。
- LoRA Hub (实验性/特定版本): 部分 TGI 版本或社区分支可能支持动态加载 LoRA 适配器,但这方面的支持成熟度可能不如 vLLM,需查阅具体文档。
- TGI 原生支持 Hugging Face
三、性能对比与深度解读:数据背后的洞察
性能对比是技术选型中的重要环节,但必须强调,任何基准测试的结果都强依赖于硬件环境、所用模型(架构、大小)、负载特征(输入序列长度、输出序列长度、并发请求数)、量化策略以及具体的测试方法和工具。脱离这些上下文谈论性能数据往往会产生误导。
以下我们引用并解读 BentoML 团队在 NVIDIA L4 GPU 上针对 Llama-3-8B (FP16) 和 Llama-3-70B (AWQ 4-bit 量化) 进行的基准测试结果(数据截至 2024 年初,测试版本为 vLLM 0.4.2 vs TGI 2.0.4)。请注意,这些框架和模型都在快速迭代,最新的版本可能会有性能变化。
通用测试环境设定:
- GPU: NVIDIA L4 (配备 24GB VRAM)
- 模型:
- Llama-3-8B (FP16)
- Llama-3-70B (使用 AWQ 4-bit 量化以适应 L4 显存)
- 负载特征 (典型): 输入 Token 长度 512, 输出 Token 长度 512 (除非特别说明)
- 测试工具: locust (用于模拟不同数量的并发用户)
- 关键指标:
- TTFT (Time To First Token): 从发送请求到接收到第一个生成 Token 的时间。衡量系统的响应速度,对实时交互应用非常重要。
- TGR (Token Generation Rate) / Throughput: 系统每秒生成的 Token 总数(通常是所有并发请求的聚合)。衡量系统的整体处理能力。有时也用 OTPS (Output Tokens Per Second) 表示。
3.1 Llama-3-8B 模型对比 (FP16)
| 并发用户数 | 指标 | vLLM 0.4.2 (FP16) | TGI 2.0.4 (FP16) | 分析解读 |
|---|---|---|---|---|
| 10 | TTFT (ms) | 50-70 | 80-100 | 在较低并发下,vLLM 凭借 PagedAttention 在内存分配和请求启动方面的效率,展现出更低的 TTFT,响应更快。 |
| TGR (tokens/s) | 2300-2500 | 2400-2600 | TGI 在此并发水平下,总吞吐量略微占优。这可能得益于其批处理策略或特定 CUDA Kernel 的优化。两者差异不大。 | |
| 50 | TTFT (ms) | 120-150 | 180-220 | 随着并发用户数增加,vLLM 的 TTFT 增长相对更为平缓。PagedAttention 在高并发下管理内存碎片的优势开始显现,有助于维持较低的启动延迟。TGI 的 TTFT 增长幅度更大。 |
| TGR (tokens/s) | 2200-2400 | 2300-2500 | TGI 的吞吐量仍然略占优势,但与 vLLM 的差距没有显著扩大。两个引擎在高负载下都表现出优秀的吞吐能力。 | |
| 100 | TTFT (ms) | 200-250 | 300-400 | 在高并发压力下,vLLM 的 TTFT 优势非常明显。其高效的内存管理和调度机制使其在高压力场景下仍能保持相对较快的响应。TGI 的 TTFT 此时显著增加,队列等待效应更为突出。 |
| TGR (tokens/s) | 2100-2300 | 2200-2400 | TGI 在极高并发下,总吞吐量依然维持微弱领先,但其响应延迟的代价已大幅增加。vLLM 的吞吐量也保持在较高水平,且延迟控制更佳。 |
关键结论 (Llama-3-8B, FP16):
- 延迟 (TTFT): vLLM 在所有测试的并发级别下,TTFT 均显著优于 TGI。这一优势在高并发场景下尤为突出,体现了 PagedAttention 在动态内存管理和调度方面的优越性,使得请求能更快得到处理和响应。
- 吞吐量 (TGR): TGI 在总吞吐量方面则表现出微弱的领先优势,尤其是在中低并发条件下。这可能与其连续批处理的具体实现、CUDA Kernel 的优化或不同的调度策略有关。然而,vLLM 的吞吐量也非常接近,且在高并发下其吞吐表现更为稳定(相对于延迟的牺牲)。
3.2 Llama-3-70B 4-bit 量化 (AWQ) 对比
部署大型模型(如 70B 参数级别)时,量化是降低显存消耗、使其能够在单张或少数几张消费级/数据中心级 GPU 上运行的关键技术。AWQ (Activation-aware Weight Quantization) 是一种流行的 4-bit 量化方案。
(注意:原文中已明确为 AWQ 量化,vLLM 和 TGI 均对其有良好支持。)
| 并发用户数 | 指标 | vLLM 0.4.2 (AWQ 4-bit) | TGI 2.0.4 (AWQ 4-bit) | 分析解读 |
|---|---|---|---|---|
| 10 | TTFT (ms) | 150-200 | 200-250 | 对于大型量化模型,vLLM 在低并发下的 TTFT 优势依然存在,但与 8B FP16 模型相比,两者差距有所缩小。模型本身的计算量增大是主要因素。 |
| TGR (tokens/s) | 500-600 | 550-700 | TGI 在低并发下的吞吐量优势在 70B 量化模型上更为明显。这可能得益于其针对量化模型 Kernel 的特定优化,或是批处理策略在更大模型上能更好地摊销开销。 | |
| 50 (假设数据点,原文为100) | TTFT (ms) | 250-350 (估) | 400-550 (估) | (估算)中等并发下,vLLM 的延迟控制优势预计会继续保持并扩大。 |
| TGR (tokens/s) | 450-550 (估) | 520-650 (估) | (估算)TGI 吞吐量预计仍领先。 | |
| 100 | TTFT (ms) | 350-450 | 600-800 | 高并发场景下,vLLM 的延迟控制能力再次得到验证,其 TTFT 的增长远低于 TGI。PagedAttention 对大型模型因 KV Cache 更大而更为敏感的内存管理挑战,在高并发时发挥了关键作用。 |
| TGR (tokens/s) | 400-500 | 500-600 | 即使在高并发下,TGI 的总吞吐量仍然保持领先,显示出其批处理机制的强大能力。但需要注意的是,这是以显著增加的响应延迟为代价换来的。vLLM 的吞吐量有所下降,但延迟控制得更好。 |
关键结论 (Llama-3-70B, AWQ 4-bit):
- 延迟 (TTFT): vLLM 在大型量化模型的场景下,依然保持了其在 TTFT 方面的优势,尤其在高并发条件下,其延迟增长控制得非常出色。对于那些既需要支持大模型,又对响应延迟有严格要求的应用,vLLM 是更优的选择。
- 吞吐量 (TGR): TGI 在 70B 量化模型的吞吐量方面表现突出,无论是在低并发还是高并发下,均能提供更高的总 Token 生成速率。如果业务核心目标是最大化单位时间内的请求处理数量,并且对延迟的容忍度相对较高,那么 TGI 是一个非常有力的竞争者。
- 量化的影响: 量化技术(如 AWQ)的运用,极大地降低了部署大型模型的显存门槛,使得 Llama-3-70B 这样的大模型能够在像 NVIDIA L4 (24GB VRAM) 这样的单卡上运行成为可能。两个推理引擎都能从量化带来的显存节省和潜在的计算加速中受益,但 TGI 在量化模型的吞吐量上的优势似乎更为明显一些。
综合解读与注意事项:
- vLLM的核心优势: 源于其革命性的 PagedAttention 技术,带来了卓越的内存管理效率、更低的内存碎片化和更稳定的低延迟,尤其是在处理高并发请求和长序列(需要大量 KV Cache)的场景下。其对前缀缓存和 LoRA 的良好支持也增强了其灵活性。
- TGI的核心优势: 在于其强大的总吞吐能力、成熟的云原生设计(易于容器化和编排)、对 Hugging Face 生态系统的紧密集成(模型加载、Tokenizer、Safetensors)、以及广泛且深入的量化技术支持。
- 性能表现高度依赖具体工作负载:
- 序列长度: 对于输入输出序列都非常短的请求,Continuous Batching 和 PagedAttention 带来的优势可能相对减弱,因为内存管理和调度开销占比可能更高。反之,对于长序列,其优势会更明显。
- 请求到达模式: 突发性的大量请求对调度器的考验更大。
- 前缀共享率: 如果请求中存在大量可共享的前缀(如 RAG 中使用相同上下文文档),vLLM 的 PagedAttention 和 Prefix Caching 将带来巨大性能提升。
- 版本迭代: vLLM 和 TGI 都在快速发展,新版本往往会带来性能改进、新功能和 Bug 修复。进行选型评估时,务必参考目标部署版本的最新官方文档和社区报告。
- 硬件适配: 不同 GPU 架构(如 Ampere, Hopper)对特定优化(如 FlashAttention 版本、Tensor Core 操作)的敏感度不同,可能会影响相对性能。
四、从 0 到 1 实践:部署你的第一个高性能推理服务
4.1 vLLM 实践方案 (部署 Llama-3-8B API 服务)
1. 环境准备 (推荐使用 Conda 或 virtualenv):
# 1. 创建并激活新的 conda 环境 (推荐)
conda create -n vllm_env python=3.10 -y
conda activate vllm_env# 2. 安装 vLLM
# 请访问 vLLM 官方 GitHub 仓库 ([https://github.com/vllm-project/vllm](https://github.com/vllm-project/vllm))
# 获取与你的 CUDA Driver 版本兼容的最新推荐安装方式。
# 例如,如果你的 CUDA Driver 支持 CUDA 12.1:
# pip install vllm # 通常会安装与 PyTorch 和 CUDA 兼容的最新版本
# 或者指定特定版本(如基准测试中使用的 0.4.2,但推荐更新):
# pip install vllm==0.4.2 # 注意:旧版本可能不再被积极支持
# 如果遇到 CUDA 版本不匹配问题,可能需要指定 PyTorch 版本或从源码编译。# 确保PyTorch也已安装并与CUDA兼容
# pip install torch torchvision torchaudio --index-url [https://download.pytorch.org/whl/cu121](https://download.pytorch.org/whl/cu121) # 示例 for CUDA 12.1# 3. (可选) Hugging Face Hub 登录以下载门控模型
# huggingface-cli login# 4. 验证安装和 GPU 检测
python -m vllm.entrypoints.openai.api_server --help
# 命令应能成功执行并显示帮助信息,且不应有 GPU 相关的错误提示。
2. 启动 OpenAI 兼容的 API 服务器:
# 设置模型 ID (可以是 Hugging Face Hub 上的模型 ID 或本地模型路径)
# 对于 Llama-3 模型,你需要获得 Meta 的访问授权并在 Hugging Face 上接受相关条款
export MODEL_ID="meta-llama/Meta-Llama-3-8B-Instruct"# 启动 vLLM API 服务器
# --trust-remote-code: 对于某些需要执行自定义代码的模型是必需的 (如 Llama-3)
# --gpu-memory-utilization: 控制 vLLM 使用的 GPU 显存比例 (默认 0.9)
# --tensor-parallel-size: 如果有多张 GPU,可以设置张量并行度 (例如,2 表示使用2张卡)
# --port: API 服务监听的端口
python -m vllm.entrypoints.openai.api_server \--model $MODEL_ID \--trust-remote-code \--port 8000 \--gpu-memory-utilization 0.90 \--max-model-len 4096 \# --tensor-parallel-size 1 # 对于单卡设置为 1 (通常是默认值)# --enforce-eager # 如果遇到特定模型的兼容性问题,可以尝试此选项# --dtype auto # 或 float16, bfloat16echo "vLLM API server for $MODEL_ID should be running on port 8000."
3. 测试 API 服务 (使用 curl 或 HTTP 客户端):
curl http://localhost:8000/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "meta-llama/Meta-Llama-3-8B-Instruct","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "What is the capital of France?"}],"max_tokens": 50,"temperature": 0.7}'
或者使用 /v1/completions (旧版,但vLLM仍支持以兼容OpenAI):
curl http://localhost:8000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "meta-llama/Meta-Llama-3-8B-Instruct","prompt": "What is the capital of France?","max_tokens": 50,"temperature": 0.7}'
预期输出 (JSON 格式,以 chat/completions 为例):
{"id": "cmpl-xxxxxxxxxxxxxxxxxxxxxxxx","object": "chat.completion","created": 1715300000,"model": "meta-llama/Meta-Llama-3-8B-Instruct","choices": [{"index": 0,"message": {"role": "assistant","content": "\nThe capital of France is Paris."},"finish_reason": "stop"}],"usage": {"prompt_tokens": 25, // 示例值"total_tokens": 32, // 示例值"completion_tokens": 7 // 示例值}
}
4. 性能考量与监控:
- 使用
nvidia-smi命令实时监控 GPU 的利用率 (GPU-Util), 显存占用 (Memory-Usage), 温度和功耗。 - vLLM 服务器的控制台日志会输出每个请求的处理时间、TTFT、TPOT (Time Per Output Token) 等关键性能指标。
- 对于生产环境,vLLM 支持通过
/metrics端点暴露 Prometheus 格式的监控指标。你可以配置 Prometheus 来抓取这些数据,并使用 Grafana 进行可视化。 - 关键调优参数:
--gpu-memory-utilization: 平衡并发能力与OOM风险。--max-num-batched-tokens: 一个批次中所有序列的总 Token 数上限,影响批处理效率和显存。--max-num-seqs: 一个批次中最大序列数。--max-model-len: 模型能处理的最大序列长度(包括prompt和生成)。--disable-log-stats: 在生产中可以禁用详细统计日志以减少开销,通过metrics监控。- 参考 vLLM 文档中关于性能调优和内存管理的章节。
4.2 TGI 实践方案 (使用 Docker 部署 Llama-3-70B AWQ 量化模型)
1. 环境准备:
- 安装 Docker: 访问 https://docs.docker.com/engine/install/ 获取对应操作系统的安装指南。
- 安装 NVIDIA Container Toolkit: 这是让 Docker 容器能够访问和使用 NVIDIA GPU 的关键组件。访问 https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html。
# 验证 NVIDIA Container Toolkit 是否安装成功 # sudo docker run --rm --gpus all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi - (可选但推荐) 登录 Hugging Face CLI: 如果你需要从 Hugging Face Hub 下载私有模型或需要授权的门控模型(如 Llama-3),或者希望 TGI 能够自动下载模型,则需要此步骤。
huggingface-cli login # 或者将你的 Hugging Face Token 作为环境变量传递给 Docker 容器 # export HUGGING_FACE_HUB_TOKEN="hf_YOUR_TOKEN"
2. 准备量化模型 (如果使用本地模型):
- 你需要一个 AWQ 格式的 Llama-3-70B 模型。你可以:
- 从 Hugging Face Hub 下载预量化版本: 搜索类似
TheBloke/Llama-3-70B-Instruct-AWQ这样的模型。 - 自己进行 AWQ 量化: 参考 AutoAWQ ( https://github.com/casper-hansen/AutoAWQ ) 等工具的教程,对原始模型进行量化。
- 从 Hugging Face Hub 下载预量化版本: 搜索类似
- 假设你已将量化后的模型文件(包含
.json配置文件,.safetensors权重文件, 以及 tokenizer 文件)存放在本地目录,例如/mnt/shared_models/my-llama-3-70b-awq。
3. 启动 TGI Docker 容器:
# 定义模型 ID (可以是 Hub ID 或本地挂载路径)
# 如果使用 Hub ID, TGI 会尝试自动下载 (需网络和token)
export MODEL_ID="TheBloke/Llama-3-70B-Instruct-AWQ" # 示例 Hub ID
# 或者,如果你有本地模型:
# export LOCAL_MODEL_PATH="/mnt/shared_models/my-llama-3-70b-awq"
# export MODEL_ID_FOR_CONTAINER="/data" # 容器内的路径# 选择 TGI Docker 镜像版本 (查阅 Hugging Face TGI GitHub 获取最新稳定版)
# [https://github.com/huggingface/text-generation-inference/pkgs/container/text-generation-inference](https://github.com/huggingface/text-generation-inference/pkgs/container/text-generation-inference)
export TGI_IMAGE_TAG="ghcr.io/huggingface/text-generation-inference:2.0.4" # 使用你选择的版本,例如2.0.4或更新
# 截至2025年初,可能有更新的版本如2.x.x,请检查官方推荐# 运行 Docker 容器
# --gpus all: 将所有可用的 GPU 分配给容器。
# -p 8080:80: 将主机的 8080 端口映射到容器的 80 端口 (TGI 默认监听80)。
# -v $LOCAL_MODEL_PATH:$MODEL_ID_FOR_CONTAINER (如果使用本地模型): 将本地模型目录挂载到容器内。
# --model-id: 指定模型 ID 或容器内的模型路径。
# --quantize awq: 明确指定使用 AWQ 量化。TGI 通常能自动检测,但明确指定更保险。
# --max-concurrent-requests: 控制 TGI 处理的最大并发请求数。
# --max-total-tokens: 一个批次中所有序列(prompt + generation)的总 Token 数上限。
# --max-input-length, --max-new-tokens: 控制单个请求的输入和输出长度。
# --sharded: 如果是多卡部署(张量并行),需要此参数或 --num-shard。# 示例1: 从 Hub 下载并运行 (单卡 L4 24GB 可能对70B AWQ 仍有压力, 注意调整参数)
docker run -d --gpus all -p 8080:80 \-e HUGGING_FACE_HUB_TOKEN=$HUGGING_FACE_HUB_TOKEN \$TGI_IMAGE_TAG \--model-id $MODEL_ID \--quantize awq \--max-concurrent-requests 128 \--max-total-tokens 4096 \--max-input-length 2048 \--max-new-tokens 2048 \--max-batch-prefill-tokens 4096 # TGI >= 1.1.0# --num-shard 1 # 如果是单卡,可以明确指定 shard 数量 (对于非sharded模型,此参数可能不需要)# 记录容器ID用于查看日志
CONTAINER_ID=$(docker ps -lq)
echo "TGI container started with ID: $CONTAINER_ID for model $MODEL_ID. Listening on port 8080."
echo "View logs with: docker logs -f $CONTAINER_ID"# 示例2: 使用本地已下载的AWQ模型 (假设模型在 /mnt/shared_models/my-llama-3-70b-awq)
# docker run -d --gpus all -p 8080:80 \
# -v /mnt/shared_models/my-llama-3-70b-awq:/data \
# $TGI_IMAGE_TAG \
# --model-id /data \
# --quantize awq \
# --max-concurrent-requests 128 \
# --max-total-tokens 4096 \
# # ... 其他参数同上
4. 测试 API 服务 (使用 curl):
TGI 提供了 /generate (单次生成) 和 /generate_stream (流式生成) 端点。
curl http://localhost:8080/generate \-X POST \-H "Content-Type: application/json" \-d '{"inputs": "What is the largest ocean on Earth? Explain its main characteristics.","parameters": {"max_new_tokens": 150,"temperature": 0.7,"top_p": 0.9,"do_sample": true}}'
预期输出 (JSON 格式):
{"generated_text": "The largest ocean on Earth is the Pacific Ocean. Its main characteristics include its vast size, covering about one-third of the Earth's surface, making it larger than all of Earth's landmasses combined. It is also the deepest ocean, with the Mariana Trench reaching depths of nearly 11,000 meters (36,000 feet). The Pacific Ocean is characterized by numerous islands and archipelagos, significant tectonic activity leading to earthquakes and tsunamis (the \"Ring of Fire\"), and diverse marine ecosystems."
}
// (实际输出会因模型和参数而异)
5. 性能考量与监控:
- 使用
docker logs -f <container_id>查看 TGI 的实时日志,其中包含了请求处理、批处理、错误等信息。 - TGI 默认在
/metrics端点暴露 Prometheus 格式的监控指标。你可以配置 Prometheus 来抓取这些指标,例如:tgi_queue_size: 请求队列中的请求数。tgi_batch_size: 当前处理批次的大小。tgi_request_duration_seconds: 请求处理时间的直方图。tgi_tokens_per_second: 生成速率。- GPU 相关的指标 (通过
dcgm-exporter或类似工具配合监控)。
- 关键调优参数 (非常重要,需要根据硬件和负载反复试验):
--max-concurrent-requests: 最大并发数。太高可能导致请求堆积和高延迟。--max-total-tokens: 一个批次中允许的最大 Token 总数(所有请求的输入+输出)。这是影响显存占用的核心参数。--max-batch-prefill-tokens: (TGI v1.1+) 专门为预填充(prompt processing)阶段设置的批次 Token 上限。通常可以设置得比--max-total-tokens大一些,以加速长 prompt 的处理。--max-input-length,--max-new-tokens: 限制单个请求的最大输入和输出长度。--waiting-served-ratio(或--max-waiting-tokens旧版): 控制动态批处理的策略,平衡吞吐和延迟。- 如果使用张量并行 (
--num-shard N或--sharded true配合CUDA_VISIBLE_DEVICES和RANK/WORLD_SIZE环境变量),确保配置正确。
- 查阅 TGI 官方文档中关于性能调优、参数配置和多 GPU 部署的详细说明。
五、选型建议:场景驱动的决策
在 vLLM 和 TGI 之间做出选择,并非判断孰优孰劣,而是要找到最能满足特定业务场景和技术栈需求的方案。以下是一个基于常见场景的选型建议表:
| 场景/需求考量 | 倾向推荐方案 | 核心理由 | 补充考量与权衡 |
|---|---|---|---|
| 极低延迟的实时交互式应用 (如智能客服、AI 助手、在线翻译) | vLLM | PagedAttention 带来的低 TTFT 和高并发下更平稳的延迟增长曲线至关重要。对长上下文处理和前缀缓存的优化进一步降低延迟。 | 即使 TGI 也能做到低延迟,但在极限并发和长序列场景,vLLM 的内存管理优势更突出。 |
| 最大化吞吐量的离线处理或 API 服务 (如文档摘要、批量翻译、内容生成) | TGI | 在很多基准测试中,TGI 在总吞吐量(每秒处理 Token 数)上表现出轻微或明显优势,尤其是在配置得当的情况下。其批处理和 Kernel 优化成熟。 | 需要仔细调优参数以平衡吞吐和延迟。如果延迟不是首要瓶颈,TGI 的高吞吐能带来更好的成本效益。 |
| 多模态模型 (VLM) 部署与推理 (如视觉问答、图像描述) | vLLM | vLLM 近期在多模态支持方面投入较多,如异步图像预处理、多模态前缀缓存等架构级优化,设计上更具前瞻性。 | TGI 也在逐步增强对多模态模型的支持,但 vLLM 在此领域的专用优化可能更深入。需关注两者最新进展。 |
| 显存资源极度受限的环境 (如边缘设备、小型 GPU) | 两者皆可,需具体评估 | vLLM: PagedAttention 极大提升物理显存的有效利用率,减少碎片,理论上能容纳更多并发或更长序列。<br>TGI: 拥有非常成熟和广泛的量化支持(AWQ, GPTQ, BitsAndBytes 等)。 | 最佳选择取决于模型大小、具体量化方案的效果、以及 PagedAttention 带来的实际节省。通常量化是首选,PagedAttention 是补充。可能需要组合策略。 |
| 与 Hugging Face 生态系统深度集成 (依赖 Hub 模型、Tokenizer、社区支持) | TGI | 作为 Hugging Face 官方支持和主推的推理服务器,TGI 与 HF Hub、transformers 库、tokenizers 库以及 Safetensors 格式无缝集成,模型兼容性极佳,上手快。 | vLLM 也能加载 Hub 上的模型,并且兼容常见的 Tokenizer,但在生态整合的“原生性”和便捷性上,TGI 略胜一筹。 |
| 追求最新架构创新与社区活跃度 (愿意尝试新技术、快速迭代) | vLLM | vLLM 以其 PagedAttention 等创新技术引领了 LLM 推理引擎的发展,社区活跃,版本迭代快,不断有新特性加入。 | TGI 同样在积极发展,但其更侧重于生产稳定性与企业级特性。vLLM 的前沿探索性可能更强。 |
| 大规模分布式部署超大模型 (需要成熟的张量并行方案) | TGI / vLLM | 两者均支持张量并行。TGI 在这方面的支持历史更长,文档和社区经验相对更丰富一些。vLLM 的张量并行支持也已成熟并持续优化。 | TGI 的多卡多节点部署方案(如配合 launcher 工具)可能更完善一些。vLLM 也在快速追赶和完善。关注两者最新版本的分布式推理能力。 |
| 追求开箱即用的云原生部署与运维 (Docker, Kubernetes, Helm) | TGI | TGI 从设计之初就充分考虑了容器化和云原生部署。官方提供了 Docker 镜像和 Helm Chart,使得在 Kubernetes 等环境中部署和管理相对更简单。 | vLLM 同样可以被容器化部署,但 TGI 在这方面的“官方套件”和文档支持可能更完备,对运维团队更友好。 |
| 需要动态加载/卸载 LoRA 适配器 (多任务服务、个性化) | vLLM | vLLM 对动态 LoRA 适配器加载和管理提供了优秀的支持,允许一个基础模型服务于多个任务而无需重启或复制模型,极大提高灵活性和资源利用率。 | TGI 对 LoRA 的支持相对较晚,或仍在发展中,可能不如 vLLM 成熟和灵活。 |
最终决策的思考路径:
- 明确核心业务指标: 是延迟(TTFT, TTPT - Time To Process Token)更重要,还是总吞吐量(RPS - Requests Per Second, TPS - Tokens Per Second)更关键?
- 评估模型与硬件: 部署的模型大小、类型(纯文本、多模态)?可用的 GPU 型号、数量、显存大小?
- 考虑工作负载特性: 请求的并发模式(平稳 vs. 突发)?输入输出序列的平均长度和分布?是否存在大量可共享的前缀?
- 团队技术栈与运维能力: 团队对哪个框架更熟悉?对云原生工具链的依赖程度?
- 进行实际基准测试: 强烈建议在你自己的目标硬件上,使用与生产环境相似的模型和负载,对候选的推理引擎进行 A/B 测试。这是做出最可靠决策的黄金标准。
六、总结
vLLM 和 TGI 无疑代表了当前大模型推理引擎技术的顶尖水平。它们通过各自独特的架构创新和工程优化,有效地解决了 LLM 在生产部署中面临的诸多核心瓶颈。
-
vLLM 凭借其核心的 PagedAttention 技术,在内存管理效率、KV Cache 优化以及由此带来的低延迟控制方面建立了显著的优势。这使其成为对实时性要求极高的交互式应用、长上下文处理以及需要高效利用显存的场景下的理想选择。其对动态 LoRA 和多模态的快速支持也显示了其强大的创新活力。
-
TGI 则以其强大的综合吞吐能力、成熟稳健的云原生设计、对 Hugging Face 生态的无缝集成、以及广泛而深入的量化技术支持,成为了构建高并发、可扩展、易于维护的 LLM 服务的热门方案。它为企业快速部署和迭代基于 Hugging Face 生态的模型提供了坚实的基础。