Denoising Autoencoders 视频截图 DAEs简单实现 kaggle 去噪编码器
https://www.bilibili.com/video/BV1syzrYaEtw

Denoising Autoencoders (DAEs) 是一种无监督学习模型,属于自动编码器(Autoencoder)的一种扩展形式。它们的目标是通过训练神经网络来学习数据的鲁棒表示(robust representation),同时具备从被噪声污染的数据中恢复原始输入的能力。
一、什么是 Denoising Autoencoder?
一个 Denoising Autoencoder 的基本思想是:
- 给定一个输入样本 $ x $,我们人为地向它添加一些噪声,得到一个“损坏”版本 $ \tilde{x} $。
- 然后训练一个神经网络模型,让它从这个被损坏的输入 $ \tilde{x} $ 中尽可能还原出原始的、干净的输入 $ x $。
结构图示意:
x → [加噪] → ˜x → [Encoder] → z → [Decoder] → x̂
其中:
- $ x $:原始输入(如图像、文本等)
- $ \tilde{x} $:加入噪声后的输入
- $ z $:隐藏层表示(latent representation)
- $ \hat{x} $:重构输出
二、为什么使用 Denoising Autoencoder?
传统的自编码器(Vanilla Autoencoder)直接学习恒等映射(identity mapping),即让网络学会将输入复制到输出。这可能导致模型只是“记住”了输入,而不是学到有用的特征表示。
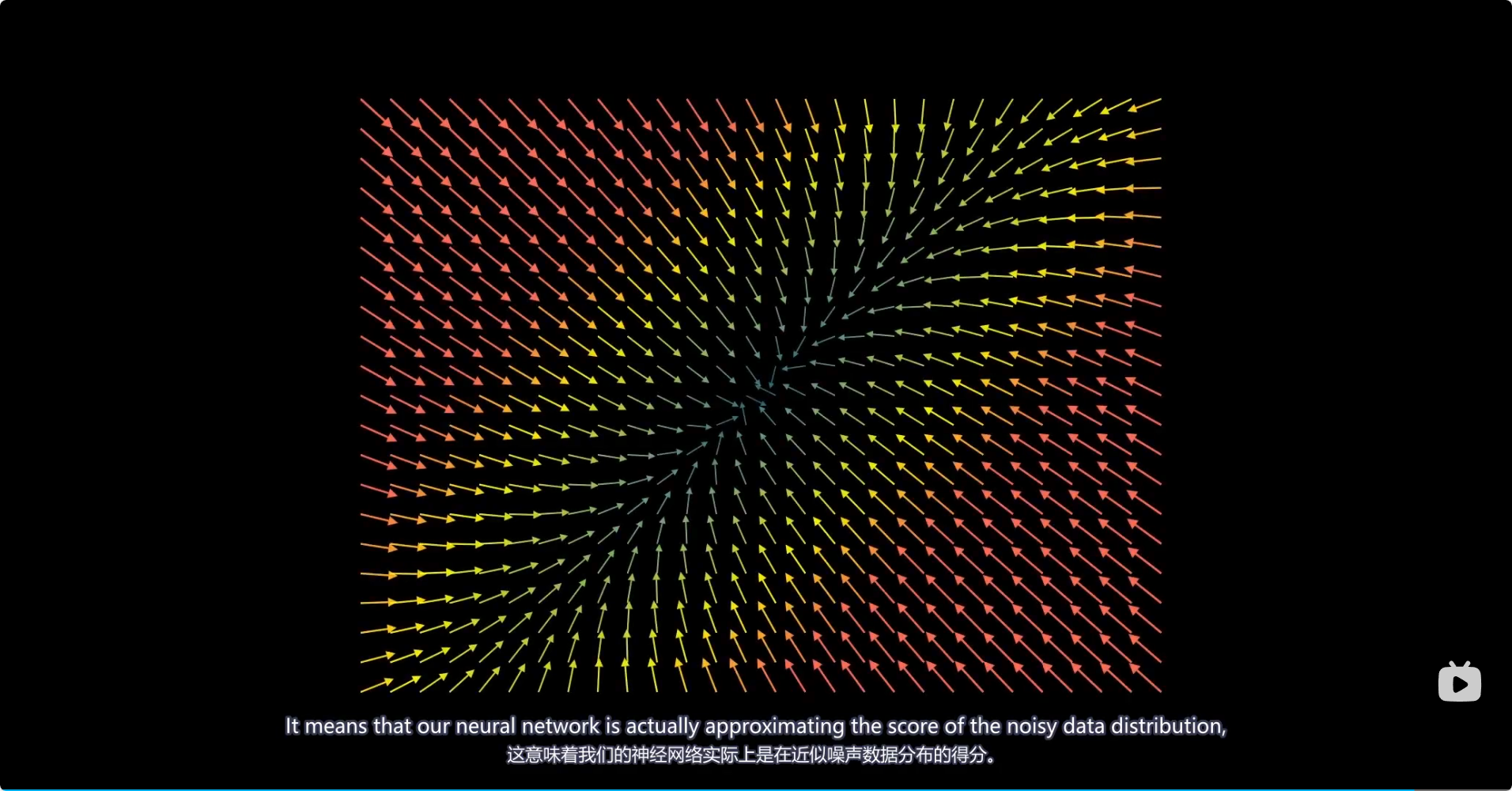
而 DAEs 强迫网络去理解输入数据的结构和分布,从而学到更鲁棒、更有意义的特征表示。
主要优点:
- 防止过拟合:通过引入噪声,增加模型泛化能力。
- 学习高阶特征:迫使模型提取输入的本质特征,以完成去噪任务。
- 用于预训练:DAE 可作为深度网络的预训练方法,提升后续监督学习任务的性能。
- 可用于异常检测:如果某个输入经过 DAE 后重构误差很大,可能意味着该输入是异常点。
三、常见的噪声类型
在训练 DAE 时,通常会使用以下几种方式对输入进行“损坏”:
| 噪声类型 | 描述 |
|---|---|
| 高斯噪声(Gaussian Noise) | 在每个输入维度上加上服从正态分布的随机数 |
| 随机遮蔽(Masking Noise) | 将部分输入值设置为0或均值(如随机屏蔽图像像素) |
| Salt-and-Pepper 噪声 | 将部分输入值随机置为最大值或最小值 |
| 输入缺失 | 模拟真实场景中的缺失数据 |
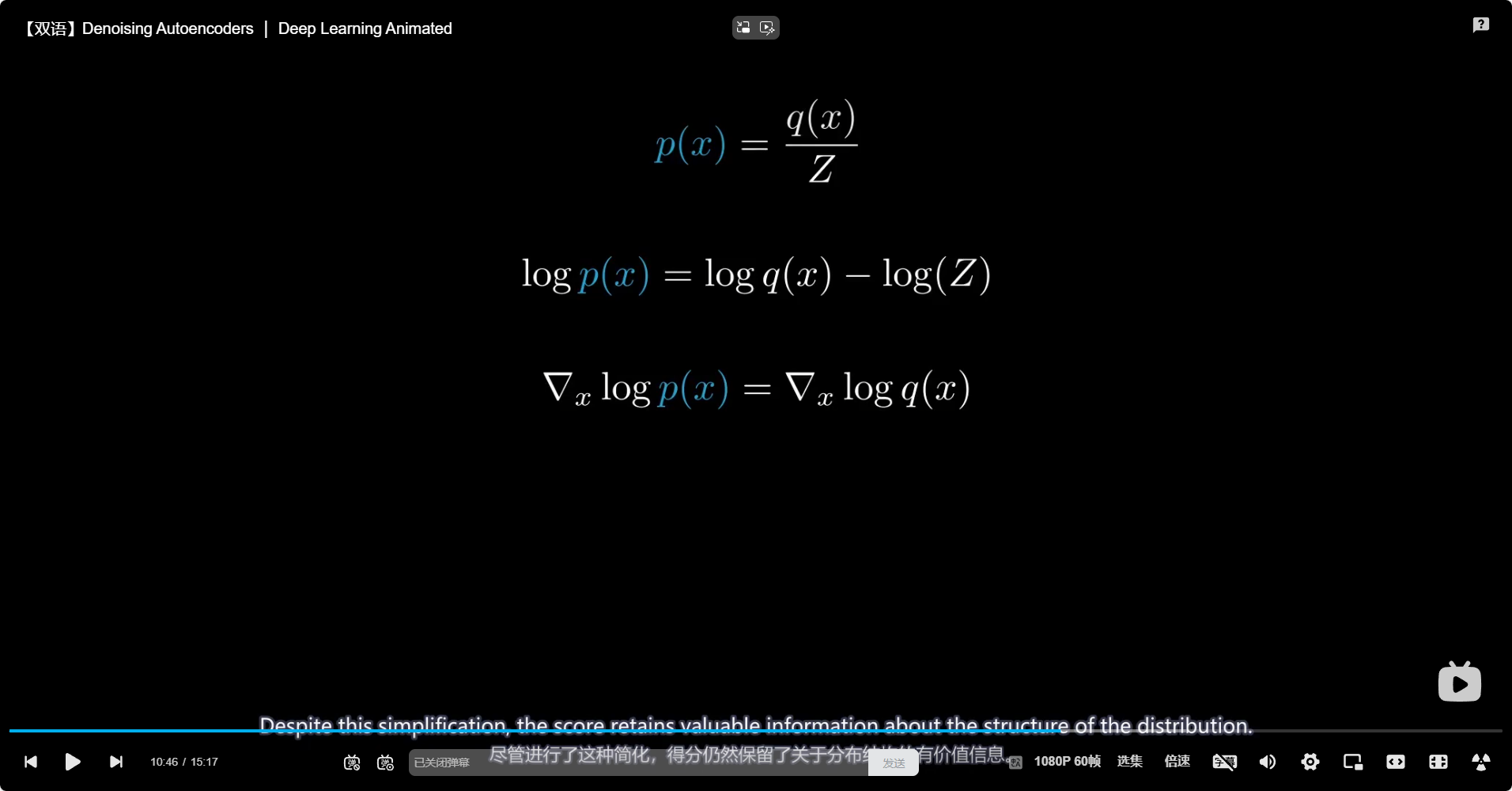
四、损失函数
DAE 的目标是最小化原始输入 $ x $ 和重构输出 $ \hat{x} $ 之间的差异,常用的损失函数包括:
-
均方误差(MSE):
L ( x , x ^ ) = 1 n ∑ i = 1 n ( x i − x ^ i ) 2 L(x, \hat{x}) = \frac{1}{n} \sum_{i=1}^{n} (x_i - \hat{x}_i)^2 L(x,x^)=n1i=1∑n(xi−x^i)2 -
交叉熵损失(Cross-Entropy Loss)(适用于归一化到 [0,1] 的图像数据)
五、代码示例(PyTorch)
下面是一个简单的 Denoising Autoencoder 示例,使用 PyTorch 实现:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 定义 Autoencoder 模型
class DenoisingAutoencoder(nn.Module):def __init__(self):super(DenoisingAutoencoder, self).__init__()self.encoder = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(True))self.decoder = nn.Sequential(nn.Linear(512, 28*28),nn.Sigmoid())def forward(self, x):x = self.encoder(x)x = self.decoder(x)return x# 加载 MNIST 数据集
transform = transforms.Compose([transforms.ToTensor()])
dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
loader = DataLoader(dataset, batch_size=64, shuffle=True)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DenoisingAutoencoder().to(device)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)# 训练循环
for epoch in range(10):for data, _ in loader:# 添加高斯噪声noisy_data = data + 0.2 * torch.randn(data.shape)noisy_data = torch.clamp(noisy_data, 0., 1.)data = data.view(-1, 28*28).to(device)noisy_data = noisy_data.view(-1, 28*28).to(device)output = model(noisy_data)loss = criterion(output, data)optimizer.zero_grad()loss.backward()optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')
六、应用领域
- 图像去噪
- 特征提取与降维
- 异常检测
- 半监督学习
- 深度生成模型的基础组件(如VAE、GAN)
七、变体与其他相关模型
| 模型名称 | 说明 |
|---|---|
| Sparse Autoencoder | 对隐藏层施加稀疏性约束 |
| Variational Autoencoder (VAE) | 引入概率建模,实现生成式建模 |
| Contractive Autoencoder | 对编码器的雅可比矩阵施加惩罚,增强鲁棒性 |
| Stacked Denoising Autoencoder | 多层堆叠的 DAE,用于构建深度网络 |
如果你需要我进一步讲解某一部分(比如具体数学推导、PyTorch Lightning 实现、如何可视化结果等),欢迎继续提问!
import matplotlib.pyplot as plt
def visualize_autoencoder(model, device, data_loader):model.eval()data_iter = iter(data_loader)images, _ = next(data_iter)# 添加噪声noisy_images = images + 0.2 * torch.randn(images.shape)noisy_images = torch.clamp(noisy_images, 0., 1.)# 展平 & 移动到设备images_flat = images.view(-1, 28*28).to(device)noisy_images_flat = noisy_images.view(-1, 28*28).to(device)with torch.no_grad():reconstructed = model(noisy_images_flat)# 恢复为图像格式reconstructed = reconstructed.view(-1, 1, 28, 28).cpu()# 可视化前 5 张图片fig, axes = plt.subplots(nrows=3, ncols=5, figsize=(10, 6))for i in range(5):# 原始图像axes[0, i].imshow(images[i].squeeze(), cmap='gray')axes[0, i].set_title('Original')axes[0, i].axis('off')# 加噪图像axes[1, i].imshow(noisy_images[i].squeeze(), cmap='gray')axes[1, i].set_title('Noisy')axes[1, i].axis('off')# 重构图像axes[2, i].imshow(reconstructed[i].squeeze(), cmap='gray')axes[2, i].set_title('Reconstructed')axes[2, i].axis('off')plt.tight_layout()plt.show()# 调用可视化函数
visualize_autoencoder(model, device, loader)
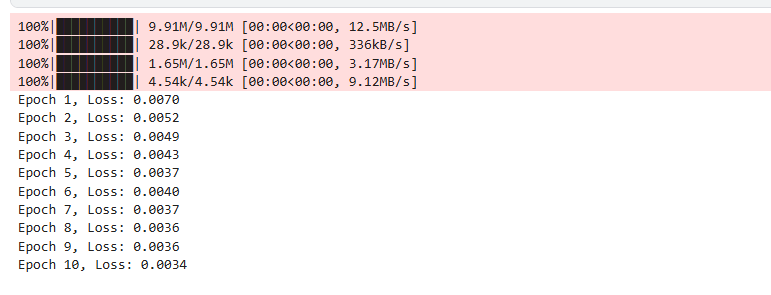
https://www.kaggle.com/code/alihhhjj/daes-easy