论文笔记:Towards Explainable Traffic Flow Prediction with Large Language Models
202404 ARXIV
1 INTRO
- 交通预测的挑战
- 抽象的特征表示削弱了模型的泛化能力
- 在缺乏标注数据的交通预测任务中,难以提供预测的可信度和结果解释能力
- ——>提出了一个新颖的交通流预测框架——xTP-LLM
- 基于大语言模型,能够有效预测未来交通流,并提供可解释的推理过程
- 将交通数据及其外部因素(如兴趣点、天气、日期和节假日等)转化为结构化的提示
- 不仅在预测准确率上优于现有的深度学习方法,而且在多种预测场景下表现出较强的泛化能力
2 problem definition

3 方法
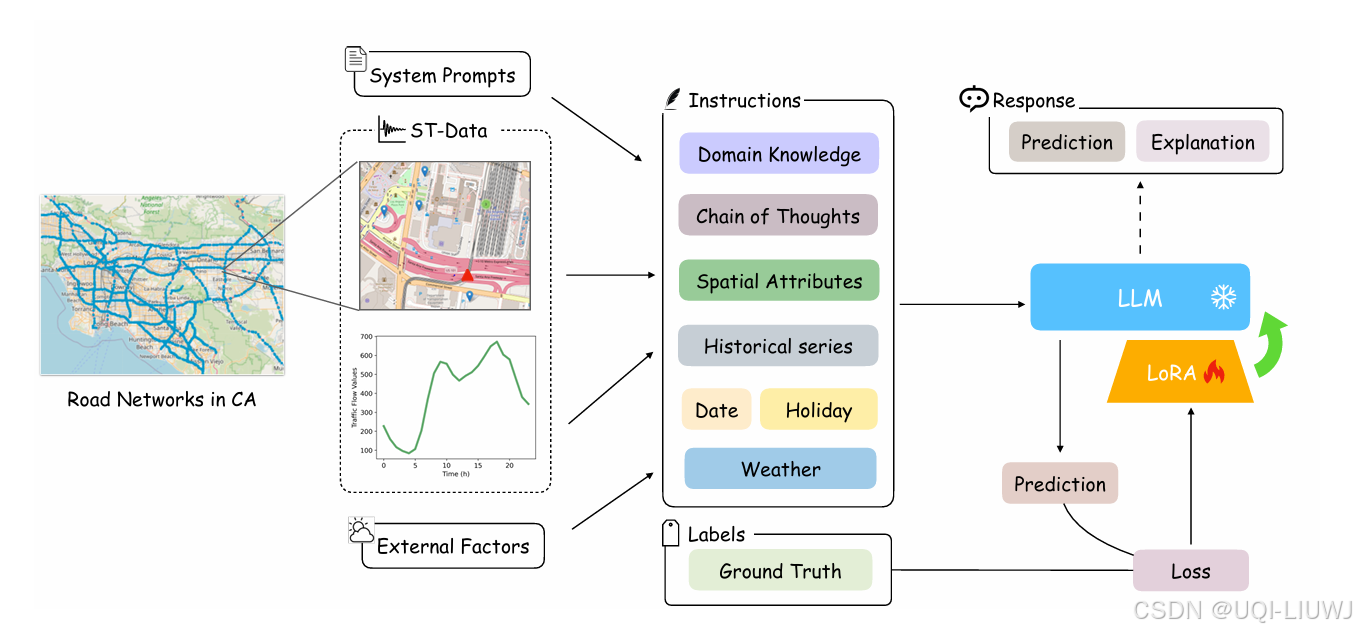
3.1 prompt构造
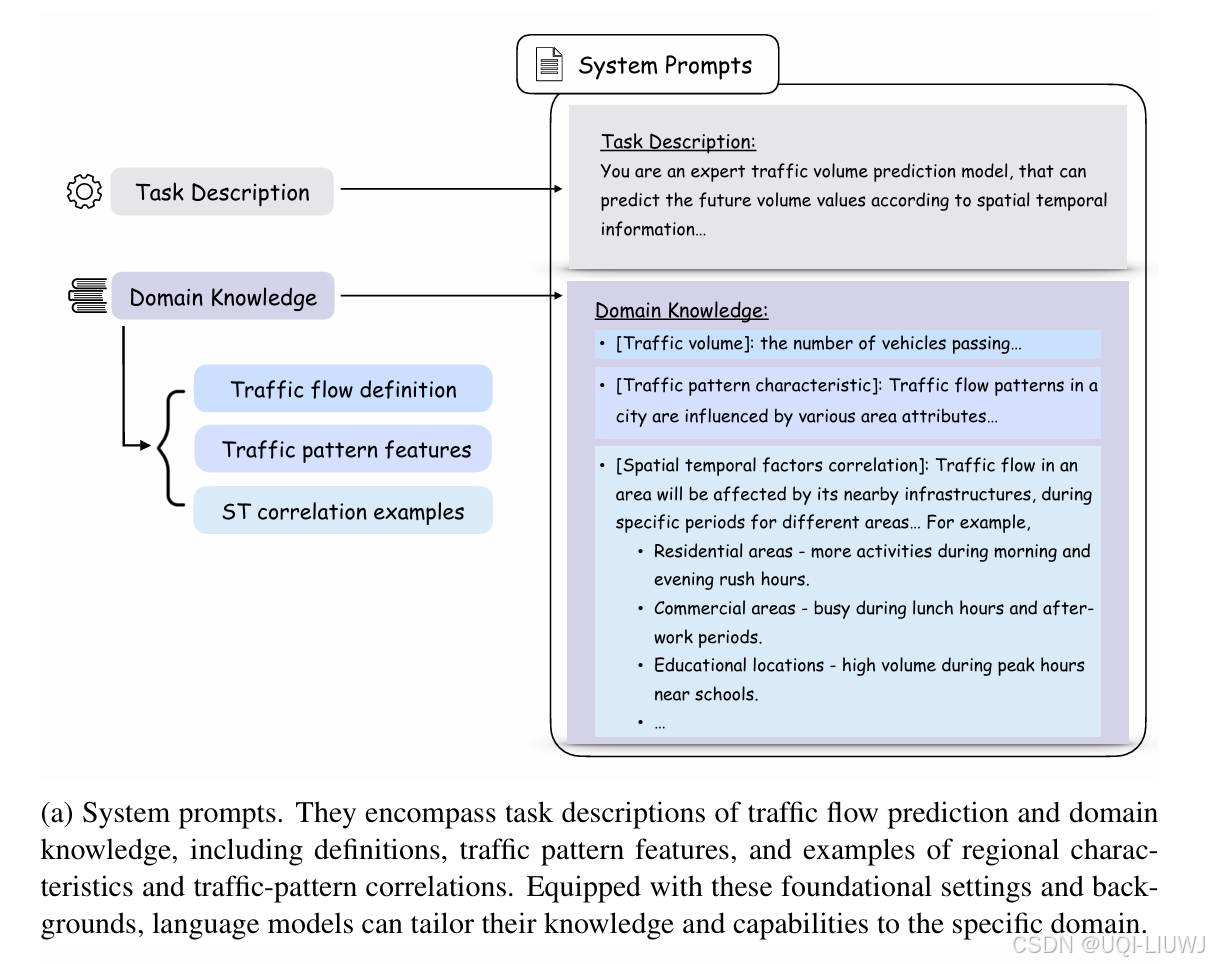
3.1.1 系统提示(System Prompts)
- 任务描述和领域知识构成
- 引导 LLM 考虑空间因素、时间波动及其交互关系
- 还提供了特定区域的交通模式案例,帮助模型理解地理特征与流量变化之间的联系,例如住宅区在早晚高峰期间交通活动显著上升
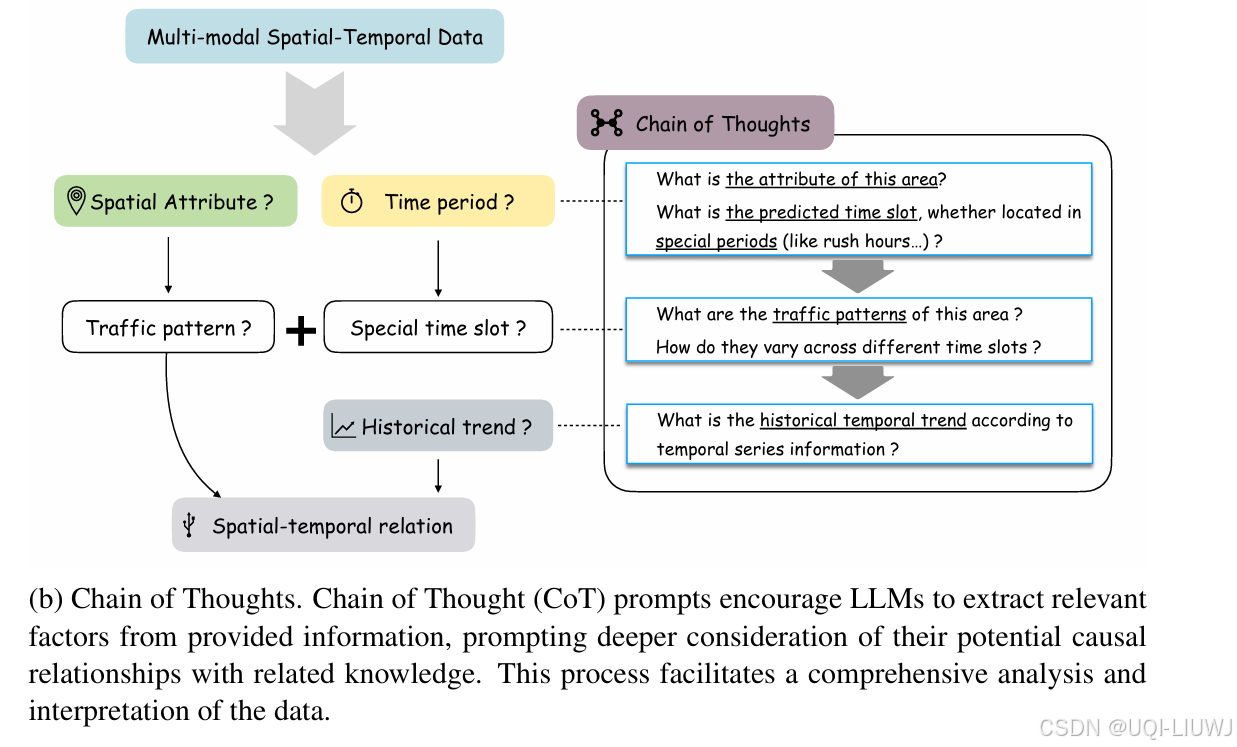
3.1.2 思维链(Chain of Thoughts)
- 借鉴 zero-shot CoT 的思想,设计了时空思维链提示来增强 LLM 的推理能力。
- 首先引导 LLM 分析目标区域的空间特征及潜在交通动态
- 随后判断预测时间是否处于高峰期、工作日、周末或节假日
- 最后引导模型挖掘空间数据与历史流量波动之间的深层联系,从而得出精确的预测结果。
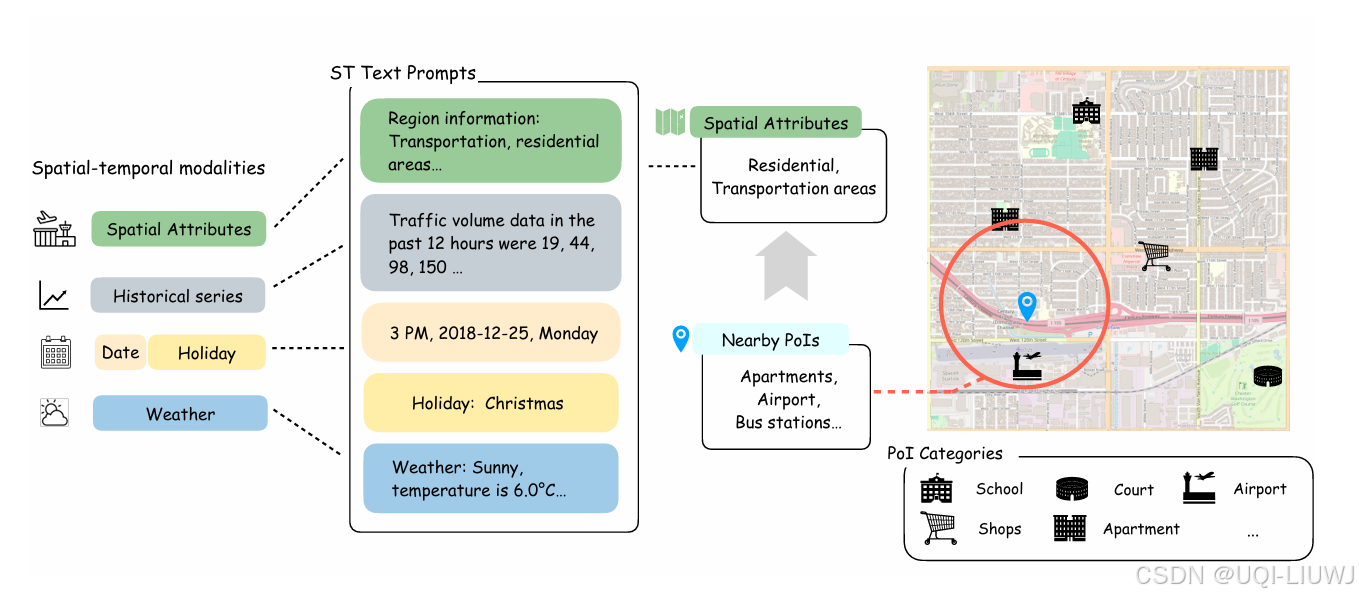
3.1.3 空间属性(Spatial Attributes)
- 由附近的PoI数据提取,预处理了不同半径(1km、3km、5km)内的 PoI 类别信息
- 为了避免信息冗余及模型过度依赖 PoI,将 PoI 分布归纳为区域属性描述,如交通枢纽、商业区、住宅区等,从而有效表达地理特征
- 还包括城市、道路位置等区域信息
3.1.4 历史时间序列(Historical Time Series)
- 将历史序列转化为包含数值的文本描述,展示过去 12 小时每小时的交通数据
3.1.5 外部因素(External Factors)
交通流受诸多外部因素影响,如日期、节假日、天气、气温与能见度等
3.2 监督微调(Supervised Fine-tuning)

提出的 xTP-LLM 构建于开源的大语言模型 Llama2-7B-chat上,并采用 LoRA 进行微调
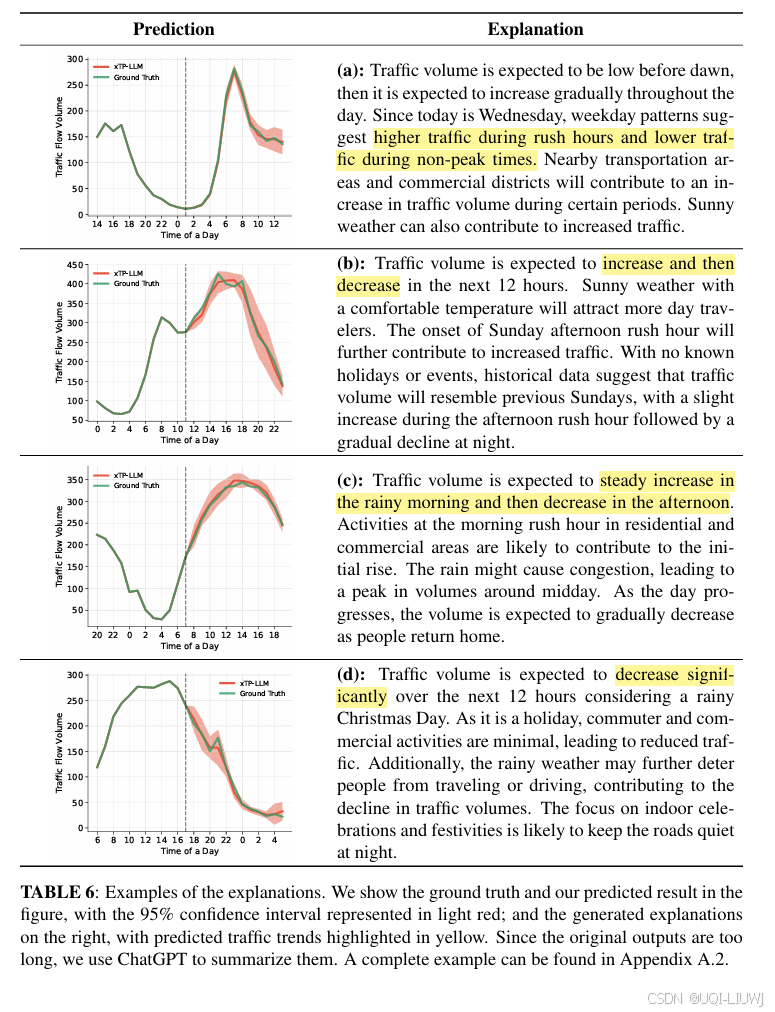
3.3 解释生成
- 通过在提示词中加入解释指令,不仅可以生成预测结果,还能同步给出解释
- 在初始阶段,我们在输入提示中直接添加了解释生成的指令。虽然 xTP-LLM 能够产出解释文本,但这些解释与预测结果往往缺乏一致性
- ——>认为这一问题源于微调阶段仅对预测结果参与损失函数优化,而没有对解释进行对齐训练
- 为了解决这一对齐不足的问题,引入了少样本学习
- 在输入提示中加入若干精心挑选的示例,说明预测结果与解释应如何对应,LLM 能在推理过程中动态学习这种对应关系
- 在初始阶段,我们在输入提示中直接添加了解释生成的指令。虽然 xTP-LLM 能够产出解释文本,但这些解释与预测结果往往缺乏一致性
3.4 纯预测的prompt

3.5 带解释的prompt

4 实验
4.1 数据
- 创建了多模态交通预测数据集 CATraffic
- 交通流量数据源自 LargeST ,涵盖了 2017 至 2021 年间的加州交通流量信息,共包含 8600 个交通传感器,每 15 分钟采样一次
- 选取了部分数据构建 CATraffic 数据集,聚焦于大洛杉矶地区(Greater Los Angeles, GLA)和大湾区(Greater Bay Area, GBA)的 1000 个传感器,时间跨度为 2018 年 1 月 1 日至 2019 年 12 月 30 日,采样频率为每小时一次。
- PoI 数据通过 OpenStreetMap 平台,利用 Overpass Turbo API 获取。
- 气象数据则来自美国国家海洋与大气管理局(NOAA),包括报告的天气事件、气温和能见度等,这些因素会直接影响交通模式
- 交通流量数据源自 LargeST ,涵盖了 2017 至 2021 年间的加州交通流量信息,共包含 8600 个交通传感器,每 15 分钟采样一次

- 将数据划分为训练集与验证集:2018 年的数据用于训练,2019 年的数据用于验证。
- 所有实验均设置为:根据过去 12 小时的历史交通流量数据,预测未来 12 小时的交通流量。
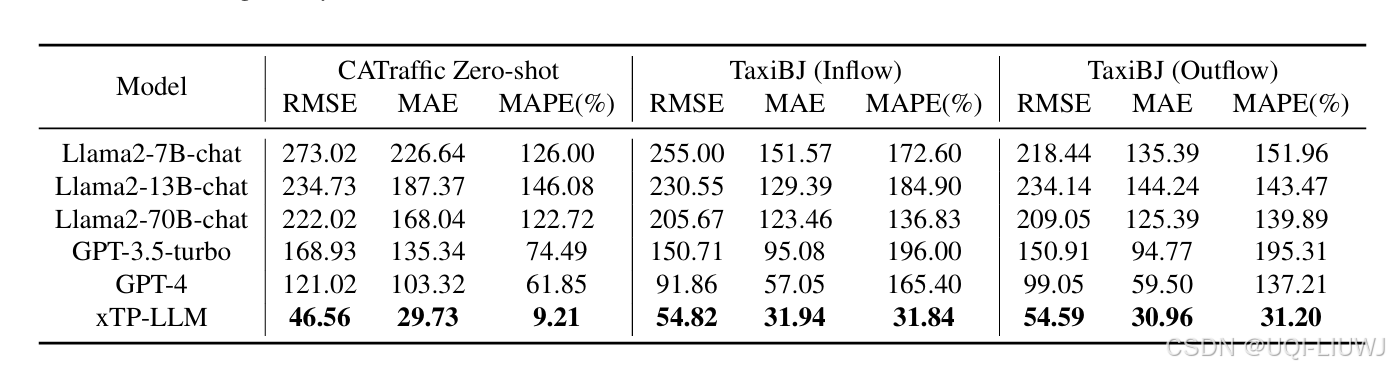
- 为了评估模型的泛化能力,还构建了一个“零样本”数据集
- 从 LargeST 数据集中选取圣地亚哥地区的 100 个传感器
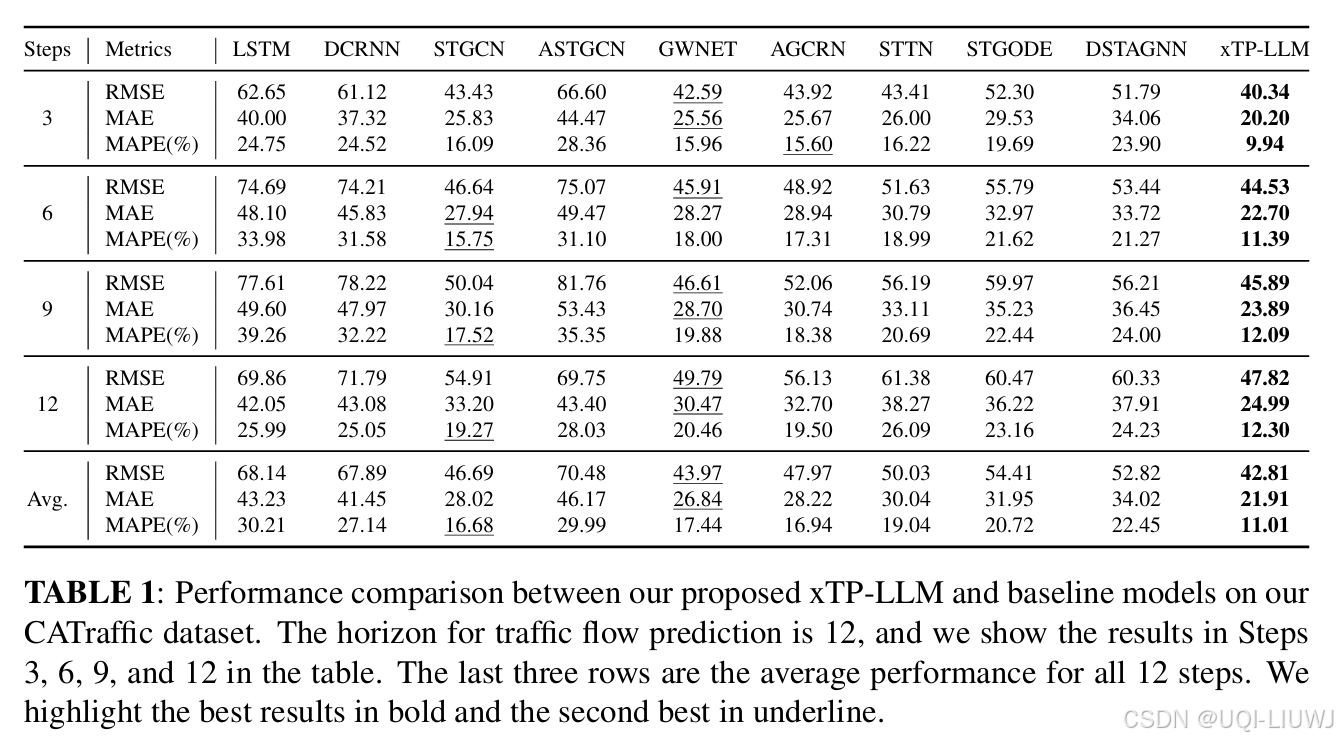
4.2 实验结果