【Redis】常用的数据类型 + 单线程模型
常用的数据类型 + 单线程模型
- 一. 数据类型
- 二. 编码方式
- 三. 单线程模型
- 1. 引出单线程模型
- 2. 为什么单线程还能这么快
一. 数据类型
Redis 的常见 5 种数据类型,它们分别是:string (字符串)、list (列表)、hash (哈希)、set (集合)、zset (有序集合),如下:
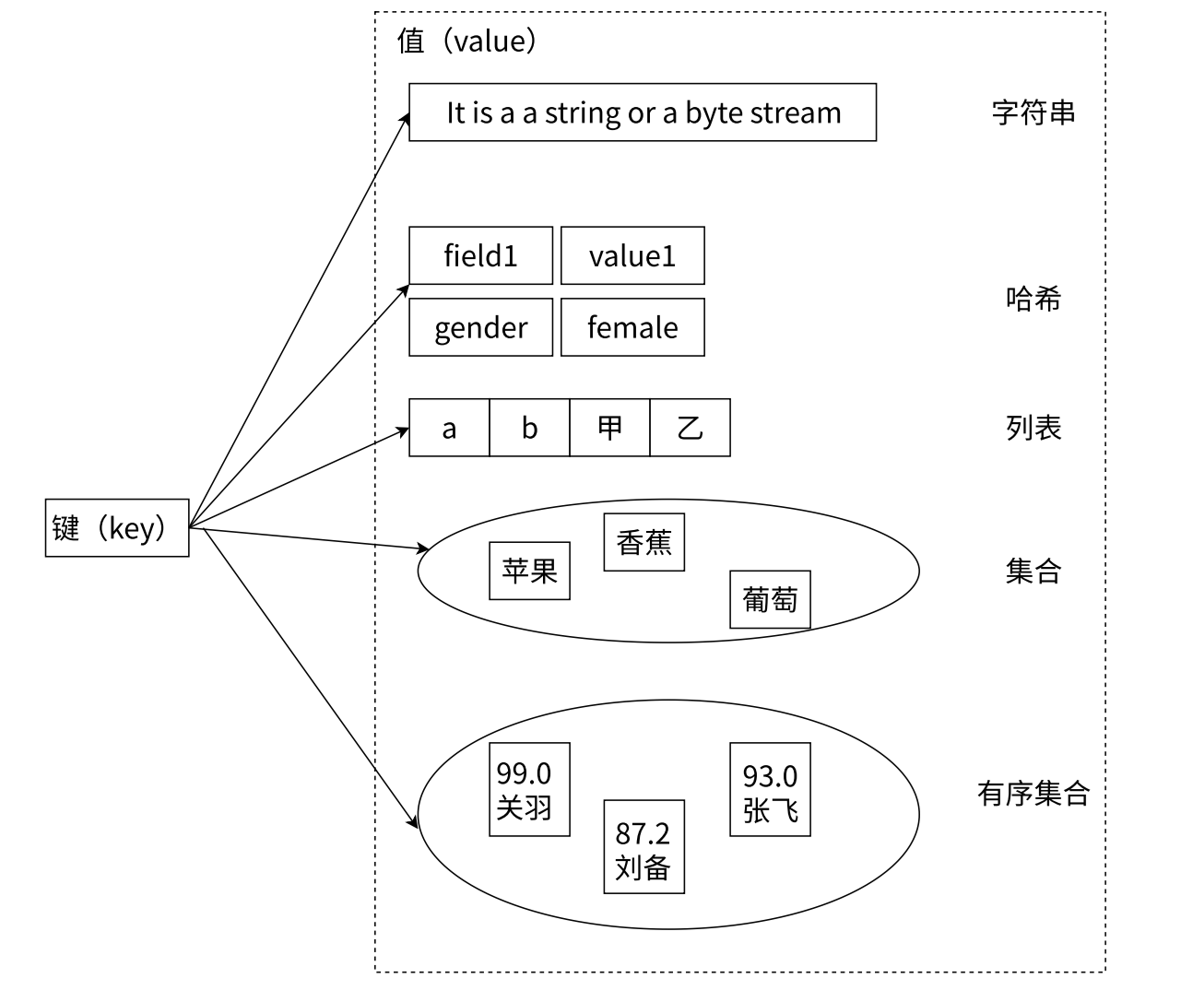
- Redis 低层在实现上述数据结构的时候,会在源码层面针对上述实现进行特定的优化,来达到节省时间/节省空间效果,内部的具体实现的编码方式还会有变数。
- Redis 承诺,现在我有这个 hash 表,进行查询、插入、删除操作,都保证时间复杂度是 O(1),但是这个背后的实现,不一定是一个标准的 hash 表,可能在特定的场景下,使用别的数据结构实现,但是仍然保证时间复杂度符合承诺。
二. 编码方式
- 数据结构:Redis 承诺给你的,也可以理解为数据类型。
- 编码方式:Redis 内部低层实现。
同一个数据类型的背后可能得编码实现方式是不同的,会根据特定场景优化。
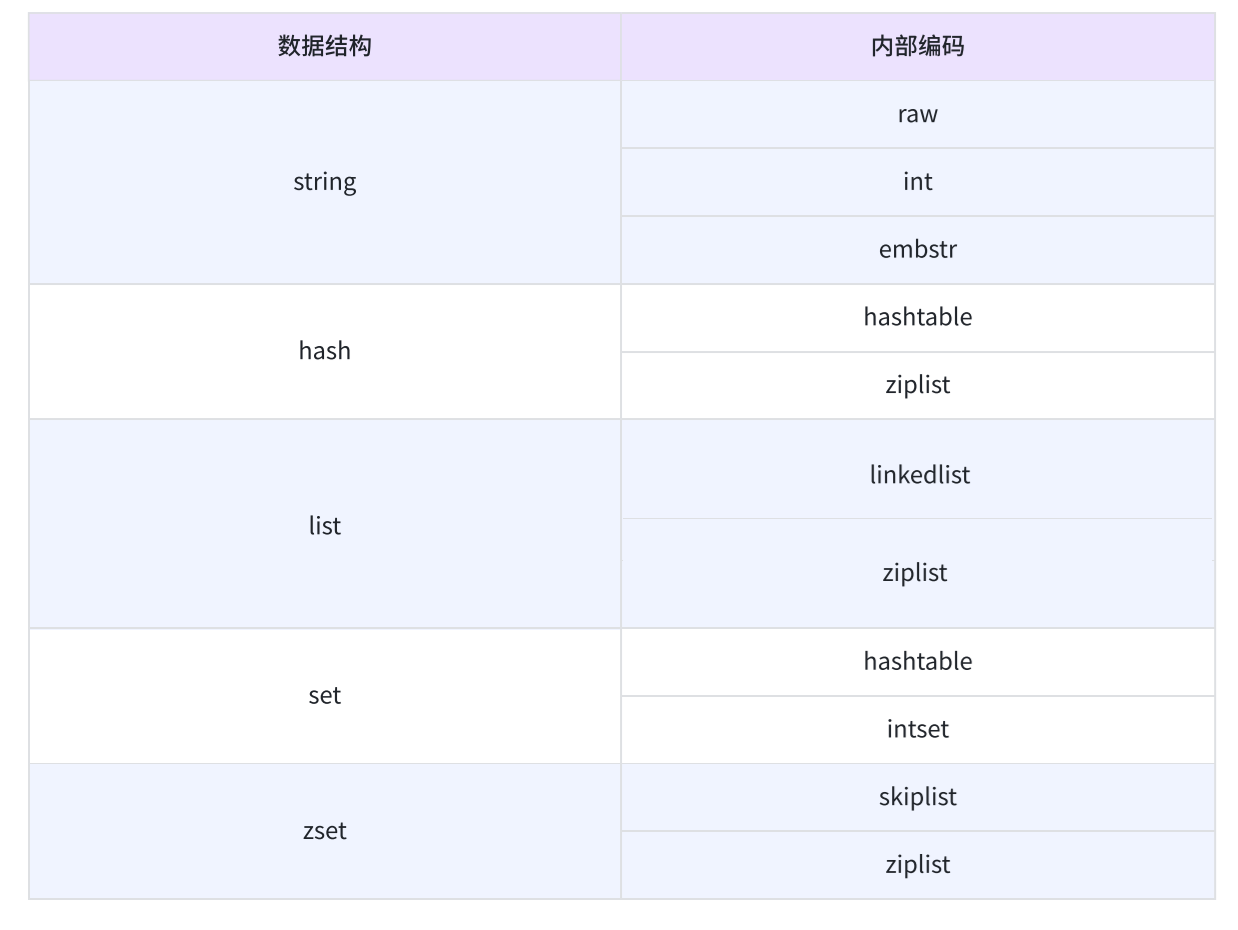
- string:字符串
- raw:最基本的字符串,低层就是一个 char 数组。
- int:当 value 就是一个整数的时候,此时可能会使用 int 来保存字符串。
- embstr:针对短字符串进行的特殊优化。
- hash:哈希表
- hashtable:最基本的哈希表,Redis 内部的哈希表的实现。
- ziplist:压缩链表,在哈希表里面的元素比较少的时候,可能进行的优化,能够节省空间。
- 为什么要压缩?Redis 上有很多的 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不大的情况下,就尽量去压缩,之后就可以让整体占用的内存空间更小了。
- list:列表
- linkedlist:链表。
- ziplist:压缩链表。
- 从 Redis 3.2 开始,引入了新的实现方式 quicklist,同时兼顾了 linkedlist 和 ziplist 的优点。quicklist 就是一个链表,每一个元素又是一个 ziplist,能够把空间和效率都兼顾到。quicklist 比较类似于 deque
- set:集合
- hashtable:哈希表。
- intset:集合中存储的是整数时的优化。
- zset:有序集合
- skiplist:跳表,不同于普通的链表,每个节点上有多个指针域,巧妙的搭配这些指针域的执行,就可以做到,从跳表上查询元素的时间复杂度是 O(logN)
- ziplist:压缩链表。
可以通过 object encoding 命令查询 key 对应 value 的编码方式:
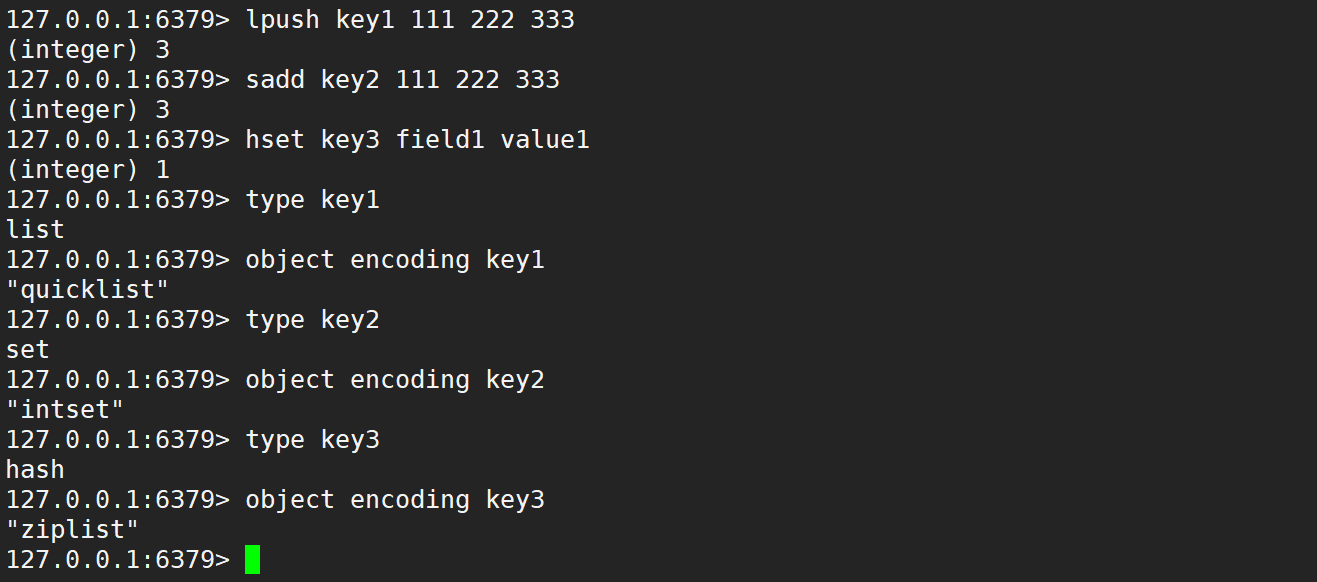
Redis 会自动根据当前的实际情况选择内部的编码方式,自动适应的。
三. 单线程模型
Redis 单线程模型:Redis 只使用一个线程,处理所有的请求命令,不是说一个 Redis 服务器进程内部就真的只有一个线程,其它也有多个线程,多线线程是在处理网络 IO
1. 引出单线程模型
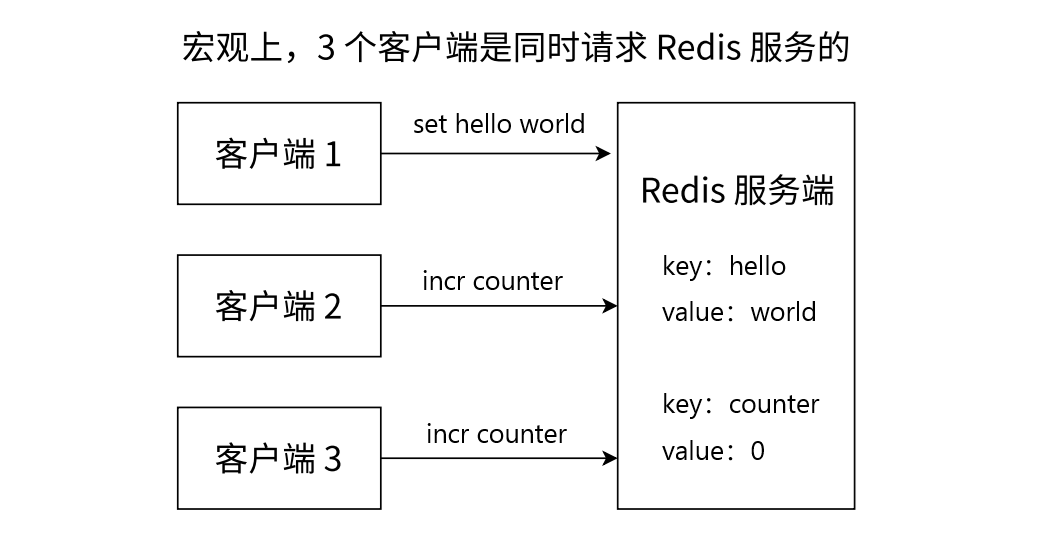
假设有三个 redis-cli 客户端同时执行命令,操作 Redis 服务器:
- 客户端 1 设置一个字符串键值对:set hello world
- 客户端 2 对 counter 做自增操作:incr counter
- 客户端 3 对 counter 做自增操作:incr counter
- incr 的作用是把 key 对应的 value 进行 + 1 操作,在多线程中,针对类似这样的场景,两个线程尝试同时对一个变量进行自增操作,表面上是自增两次,实际上可能是自增一次,存在线程安全问题。
- 当前这三个客户端,也相当与 “并发” 的发起了上述的请求,此时是否意味着服务器这边存在类似的线程安全问题?答案是并不会,因为 Redis 服务器实际上是单线程模型,保证了当前收到的这多个请求时串行执行的!
- 多个请求同时达到 Redis 服务器,也是要在先在队列中排队,再等待 Redis 服务器一个个的取出里面的命令再执行,微观上讲,Redis 服务器是串行/顺序执行这多个命令的。
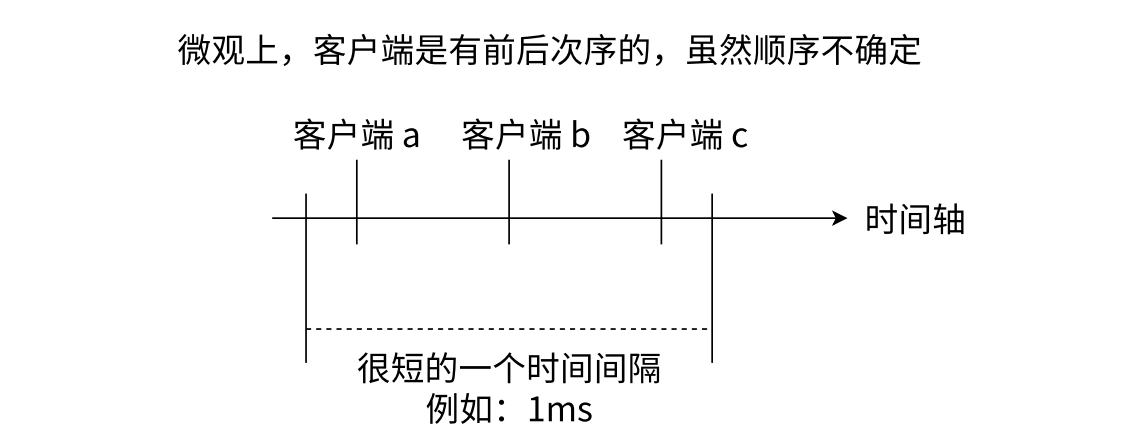
Redis 的单线程模型:
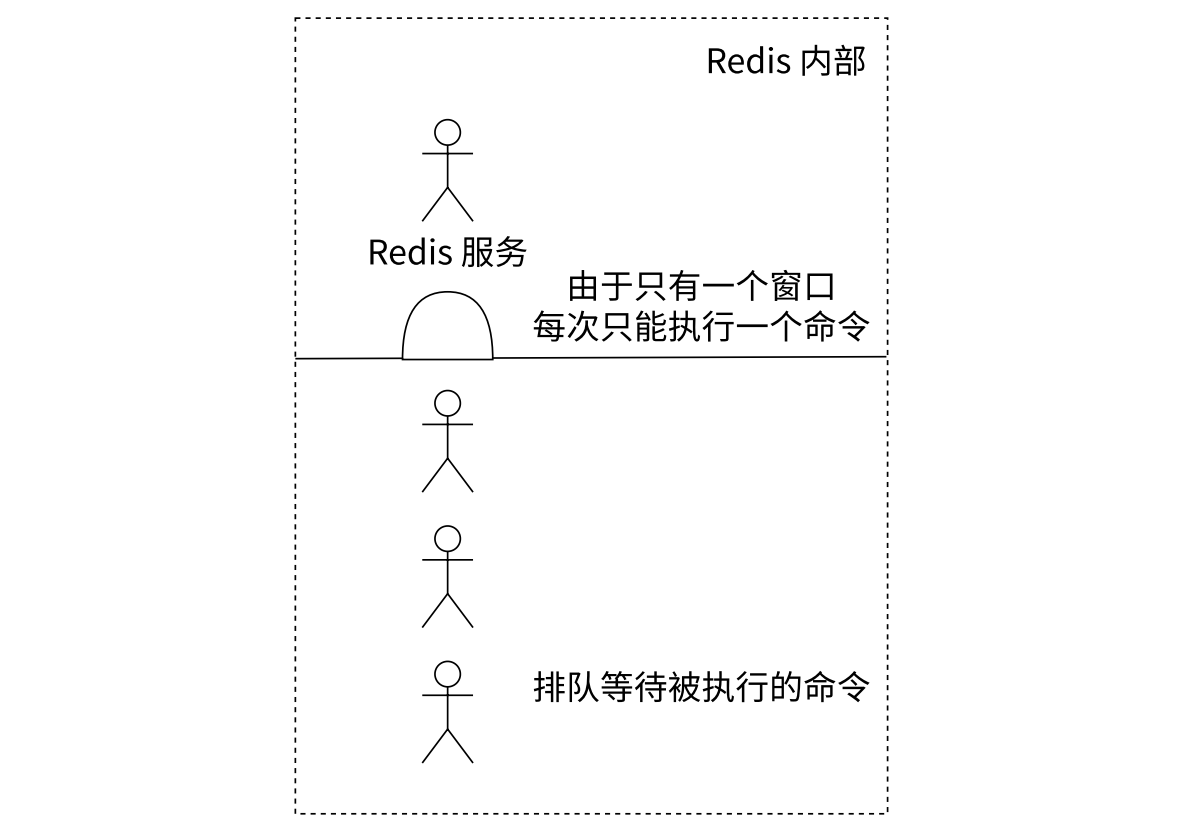
- Redis 能够使用 “单线程模型” 很好的工作,原因主要是 Redis 的核心业务逻辑都是短平快的,不太消耗 CPU 资源也就不太吃多核。
- Redis 的弊端:使用时必须要特别小心,某个操作占用时间长,就会阻塞其它命令的执行。
实际开发中是否使用单线程/多线程,还是要结合具体场景,具体分析。
2. 为什么单线程还能这么快
面试题:Redis 虽然是单线程模型,为什么效率这么高呢?速度这么快呢?
参照物是数据库 (MySQL、Oracle、SQL server)
- Redis 的操作是访问内存,数据库则是访问硬盘。
- Redis 的核心功能,比数据库的核心功能更简单。
- Redis 干的活少,提供的功能相比于数据库也是少了很多。
- 数据库对于数据的插入、删除查询,都有更复杂的功能支持,这样的功能势必要花费更多的开销,比如,针对插入、删除操作,数据库中的各种约束,都会使数据库做额外的工作。
- 单线程模型,避免了一些不必要的线程切换和线程竞争的开销。
- Redis 每个基本操作,都是短平快的,就是简单操作一些内存数据,不是什么特别消耗 CPU 的操作,就算搞多个线程,也提升不大。
- Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在网络 I/O 上浪费过多的时间。
- 一个线程就可以管理多个 socket,针对 TCP 来说,服务器这边每次要服务一个客户端,都需要给这个客户端安排一个 socket,一个服务器服务多个客户端,同时就有很多个 socket,这些 socket 上都是无时无刻通信的吗?
- 很多情况下,每个客户端和服务器之间的通信没有那么频繁,此时这么多 socket 大部分时间上面是没有数据需要传输的,同一时刻只有少数 socket 是活跃的。
- 如果给每一个客户端都分配一个线程,随着客户端的增多,线程就增多了,系统的开销就大了。IO 多路复用就解决了这样的问题,做到一个线程来处理多个 socket。操作系统给程序员提供的机制,提供了一套 API,内部的功能都是操作系统内核实现的,有 select、poll、epoll,其中 epoll 的效率最高。
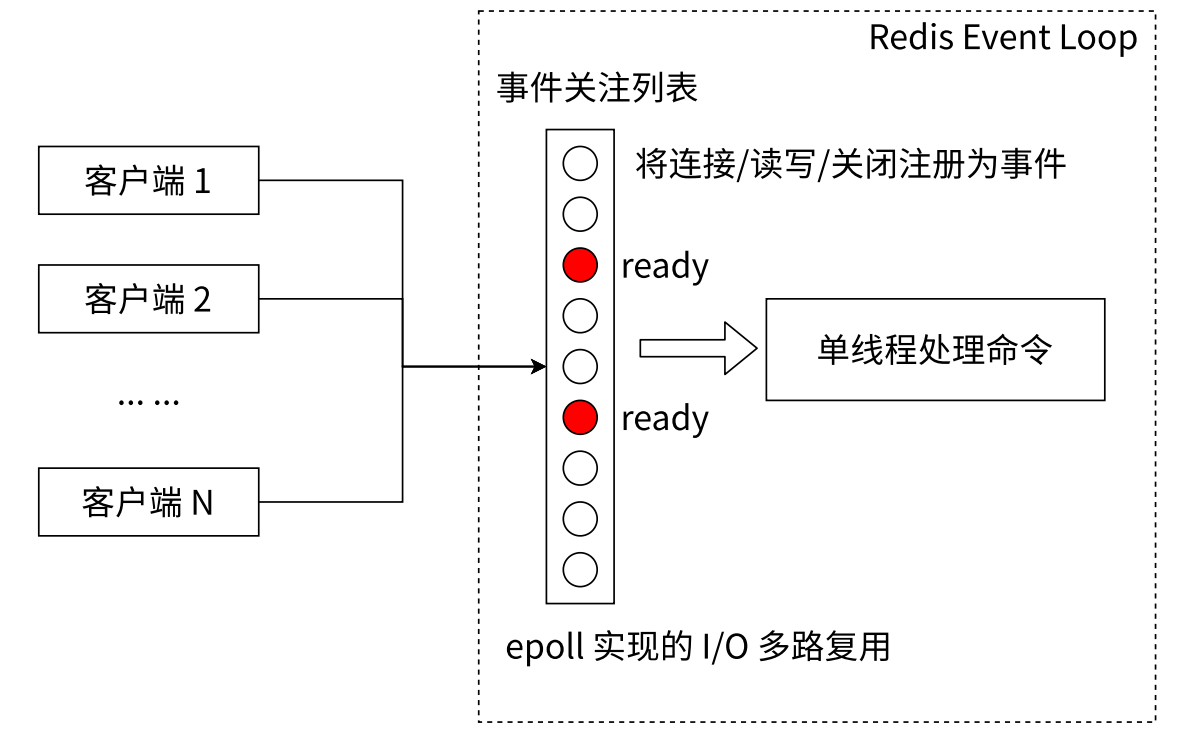
虽然单线程给 Redis 带来很多好处,但还是有一个致命的问题:对于单个命令的执行时间都是有要求的。如果某个命令执行过长,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客户端的阻塞,对于 Redis 这种高性能的服务来说是非常严重的,所以 Redis 是面向快速执行场景的数据库。