SQLord: 基于反向数据生成和任务拆解的 Text-to-SQL 企业落地方案
曾在Text-to-SQL方向做过深入的研究,以此为基础研发的DataAgent在B2B平台成功落地,因此作为第一作者,在 The Web Conference (WWW’2025, CCF-A) 会议上发表了相关论文:
SQLord: A Robust Enterprise Text-to-SQL Solution via Reverse Data Generation and Workflow Decomposition。
此文章是该论文的中文版。
阅读原文更清晰
摘要
将自然语言转换为 SQL 语句(NL2SQL)对于以数据驱动的商业应用至关重要。然而,现有框架大多依赖开源数据集进行训练,难以应对复杂的业务逻辑,并且缺乏用于微调的领域专属数据。此外,现有的评估方法通常依赖标注数据和可执行的数据库环境,而这些在实际应用中往往较为稀缺。
为了解决上述问题,我们提出了 SQLord,一个面向企业级应用的 NL2SQL 方案。首先,SQLord 引入了一种反向数据生成方法,将原始 SQL 语句转化为带标注的数据,用于有监督微调(SFT);其次,提出了一种基于自动化工作流生成的复杂查询分解方法;此外,还构建了一个全面的 GPT-Judge 评估框架,包括Execution 评估(EXE)、Query-SQL 评估(QSE)和 SQL-SQL 评估(SSE)三种评估方案,以适应多种应用场景。
离线测试结果表明,SQLord 的表现显著优于当前的先进基线方法;在线准确率持续超过 90%,充分体现了 SQLord 在复杂真实场景中的优势与有效性。目前,SQLord 已在全球最大的 B2B 电商平台多个场景中成功落地应用。
1. 引言
自然语言转 SQL(NL2SQL),仍然是自然语言处理与关系型数据库领域中的一个关键挑战 [9]。过去,该领域的研究主要集中于识别并抽象出问题与 SQL 之间的模式,并通过在 NL2SQL 数据集上训练的编码器-解码器架构对这些模式进行优化 [5, 6, 7, 15]。大型语言模型(LLMs)的出现,为解决 NL2SQL 问题带来了方法论上的范式转变 [4, 12, 13, 14]。Gao 等人 [4] 的研究成果尤为突出,他们利用 GPT-4 [11] 在 Spider 排行榜 [2] 上取得了第一名,Execution准确率达到 86.6%。与传统方法不同,基于 LLM 的 NL2SQL 框架的主要挑战在于如何通过提示工程(Prompt Engineering)策略性地引导生成精准的 SQL 语句。这一过程需要对问题表达进行精细的优化 [3, 12],精心选择示例 [8, 10],并对这些示例进行系统化组织。
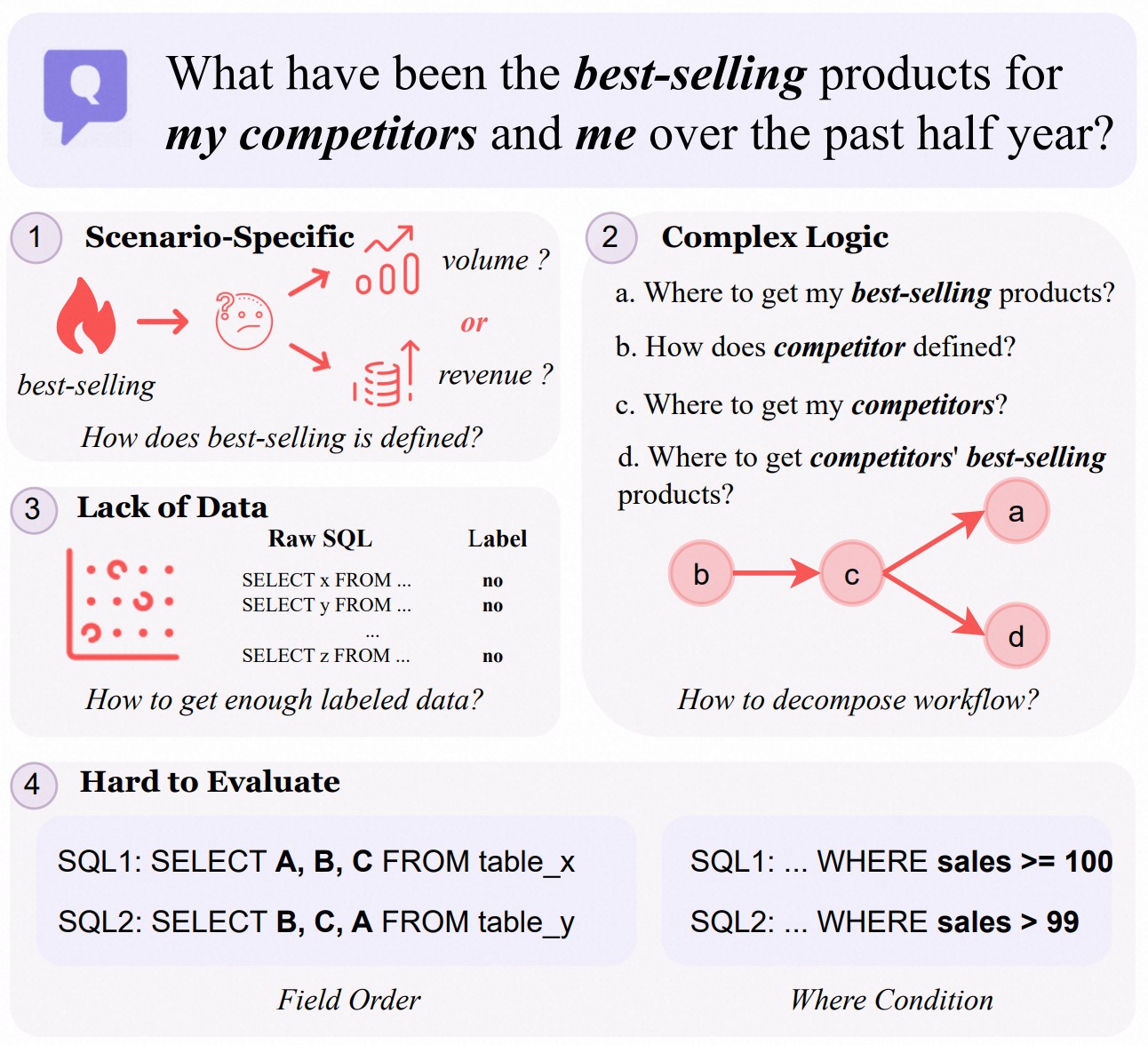
尽管基于 LLM 的方法在自然语言理解与 SQL 生成方面取得了进展,但在实际的企业级应用中仍面临诸多挑战。例如,如图 1 所示,当一位 B2B 电商平台用户询问过去六个月中自己与竞争对手的畅销产品时,会遇到以下问题:
- 首先,定义“畅销”(是销量最高还是销售额最高)需要领域知识来理解业务逻辑;
- 其次,LLM 的上下文学习能力在处理复杂的 NL2SQL 任务时往往表现不足。尽管可以通过微调模型来提升性能,但由于实际应用中的大多数 SQL 未被标注,缺乏可用于训练的标注数据,这一方法也受到限制;
- 最后,NL2SQL 性能评估较为困难,因为 SQL 语句在字段顺序或条件表达(如 “sales >= 100” 与 “sales > 99”)上存在多样性,使得基于字符串匹配的评估方法不够准确,尤其是在查询结果为空的情况下更加复杂。
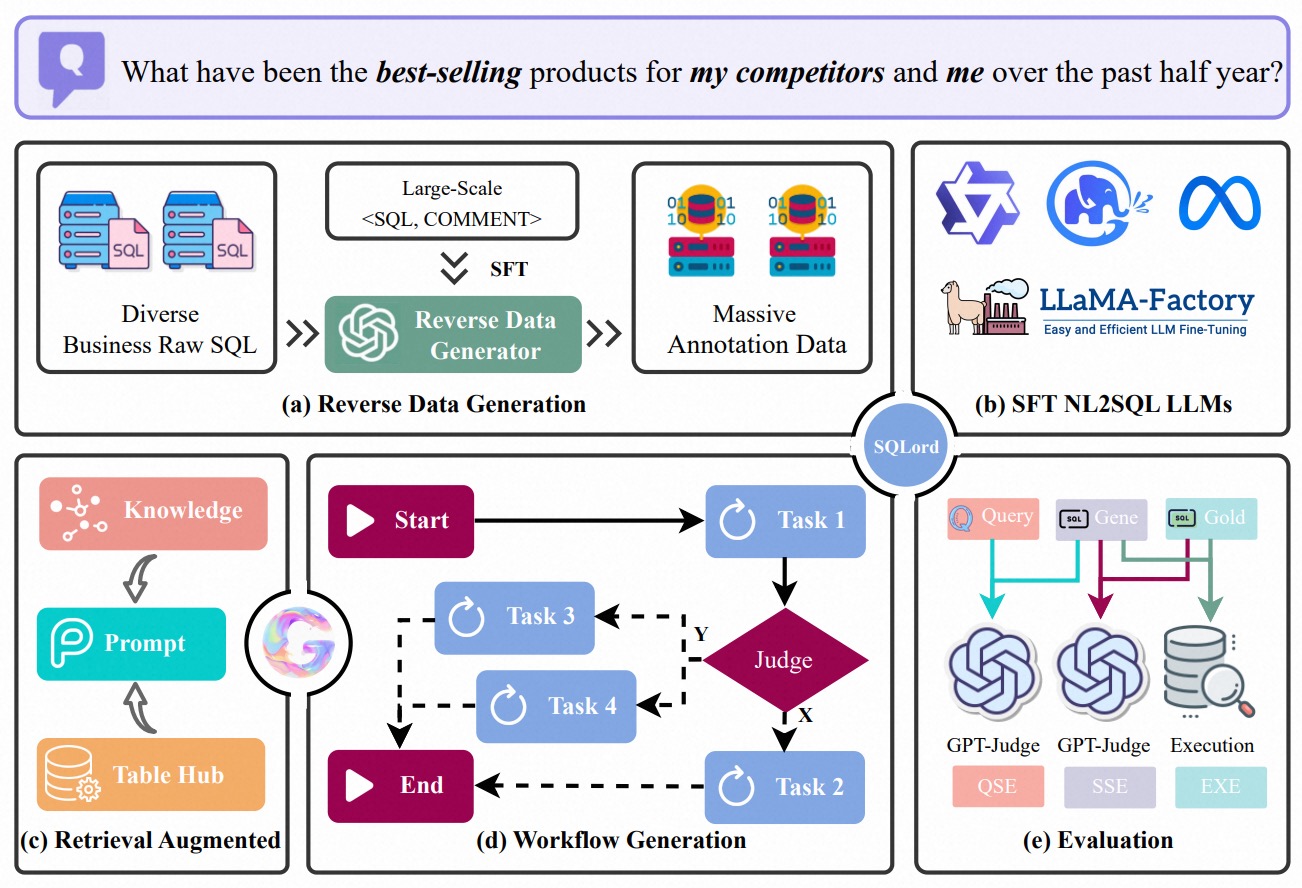
为了解决 NL2SQL 在真实场景中的应用难题,我们提出了 SQLord。首先,我们引入了一种数据反向生成方法,利用开发者日常编写的 SQL 语句及其注释(COMMENT),生成 <SQL, COMMENT> 数据对。这些数据对被用于训练反向生成模型 RevLLM,该模型可以为 SQL 语句生成自然语言描述(可以看做是用户的Query)。RevLLM 能够从日常开发中编写的原始 SQL 中自动生成高质量的 <Query, SQL> 数据对,从而有效缓解领域特定 NL2SQL 微调所面临的数据稀缺问题;其次,我们提出了一种结合领域知识与自动工作流生成的任务分解策略,该方法可将复杂查询系统性地分解为多个简单的子任务,从而有效应对现实业务中常见的复杂逻辑,如多表连接和 SQL 嵌套;最后,我们构建了一个灵活的基于 GPT-Judge 的评估框架,适用于三类场景:
- EXE(执行评估):比较两个 SQL 语句的执行结果;
- QSE(Query-SQL 评估):通过大型语言模型评估自然语言 Query 与 SQL 语句之间的一致性;
- SSE(SQL-SQL 评估):利用 LLM 比较两个 SQL 在结构和语义上的一致性。
大量离线实验验证了 SQLord 在解决关键 NL2SQL 问题上的有效性;在线测试也证实了 SQLord 在实时查询处理中的可扩展性与稳定性。SQLord 已成功部署于全球最大的 B2B 电商平台中,并支持多个核心业务场景。
2. 框架
2.1 反向数据生成
在特定领域中,标注好的 <Query,SQL> 数量稀缺,这为 NL2SQL 模型训练带来了重大挑战。为了解决这一问题,我们提出了一种反向数据生成方法,如图 2(a) 和 (b) 所示。具体来说,我们使用一小部分标注好的 <SQL, COMMENT> 对来训练一个反向生成模型,称为 RevLLM。训练数据集记作: D t r a i n = { ( s j , c j ) ∣ j = 1 , … , m } D_{train} = \{(s_j, c_j) | j = 1, …, m\} Dtrain={(sj,cj)∣j=1,…,m},其中, s j s_j sj 表示第 j j j 条 SQL 语句用作为模型的输入, c j c_j cj 为其对应的 COMMENT 作为输出。
训练好的 RevLLM 模型随后被用于对大量的原始 SQL 语句 S = { s 1 , s 2 , . . . , s n } S = \{s_1, s_2, ..., s_n\} S={s1,s2,...,sn}生成大规模伪标注的 <Query,SQL> 数据对。这些原始 SQL 同样来自日常开发,对于每一条 SQL 语句 s i s_i si,RevLLM 生成其对应的自然语言描述 q i q_i qi,即 Query。该过程可以形式化为:
q i = RevLLM ( s i ; θ ) q_i = \text{RevLLM}(s_i; θ) qi=RevLLM(si;θ)
其中, θ \theta θ 为模型参数。
最终生成的数据集为:
D g e n = { ( q i , s i ) ∣ i = 1 , . . . , n } , D_{gen} = \{(q_i, s_i) | i = 1, ..., n\}, Dgen={(qi,si)∣i=1,...,n},
它作为一个标注语料集,用于后续模型训练。
接下来,我们使用生成的数据集 D g e n D_{gen} Dgen 对开源大语言模型(如 Qwen [1])进行微调,得到一个面向特定业务场景的 NL2SQL 模型,称为 SQLLM。该模型通过优化以下损失函数进行训练:
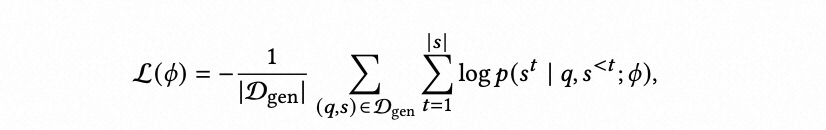
其中:
- ϕ \phi ϕ 表示 SQLLM 模型的参数,
- q q q 是自然语言查询,
- s s s 是 SQL 语句,
- s t s_t st 是 SQL 中的第 t 个 token,
- s < t s^{<t} s<t 是 s t s_t st 之前的所有 token 组成的前缀。
2.2 自动化工作流生成
自动化处理复杂业务 Query 的关键在于:将高层次目标拆解为更小、更简单、可管理的子任务,并按照其依赖关系顺序执行。这个过程可被视为一种“检索增强生成”(Retrieval-Augmented Generation,RAG)方式,结合领域知识与表结构检索动态生成子任务,以应对子任务之间的顺序和并行特性。
2.2.1 检索增强
如图 2© 所示,给定用户查询 q q q,第一步是从领域知识库 K \mathcal{K} K 和表结构库 T \mathcal{T} T(TableHub) 中检索相关信息。该步骤提供了数据库的基本上下文与结构信息,确保后续任务拆解既满足业务需求,又符合底层数据结构:
d q = RA ( q ; K , T ) d_q = \text{RA}(q; \mathcal{K}, \mathcal{T}) dq=RA(q;K,T)
其中, RA ( ⋅ ) \text{RA}(·) RA(⋅) 表示基于向量相似度的检索系统,用于收集特定领域知识和数据库模式信息。输出 d q d_q dq 表示全面的查询上下文。
2.2.2 动态任务生成
接下来,查询 q q q 被逐步分解为子任务 t 1 , t 2 , . . . , t k t_1, t_2, ..., t_k t1,t2,...,tk,通过一个生成器 G ( ⋅ ) \text{G}(·) G(⋅)(例如 Qwen 这样的 LLM)实现。每个子任务 t i t_i ti 依赖于前序任务的结果 { r 1 , . . . , r i − 1 } \{r_1, ..., r_{i-1}\} {r1,...,ri−1} 以及分析阶段检索到的信息。生成器 G ( ⋅ ) \text{G}(·) G(⋅) 在任务拆解过程中会考虑上下文 d q d_q dq 和中间结果,以实现动态调整:
t i = G ( q , d q , { r 1 , . . . , r i − 1 } ) t_i = \text{G}(q, d_q, \{r_1, ..., r_{i-1}\}) ti=G(q,dq,{r1,...,ri−1})
这种方式确保任务的拆解不仅满足原始查询的需求,也保证子任务之间的依赖关系。
2.2.3 SQL 生成与执行
对于每一个子任务 t i t_i ti,使用训练好的 SQLLM 生成对应的 SQL 语句 s i s_i si,该模型融合了领域知识和表结构信息。随后,这条 SQL 语句在数据库上执行,得到结果 r i r_i ri:
s i = SQLLM ( t i , d q ; ϕ ) , r i = E ( s i ) , s_i = \text{SQLLM}(t_i, d_q; \phi), \quad r_i = \mathcal{E}(s_i), si=SQLLM(ti,dq;ϕ),ri=E(si),
其中, E ( ⋅ ) \mathcal{E}(·) E(⋅) 表示 SQL 执行引擎, ϕ \phi ϕ 为模型 SQLLM 的微调参数。
如图 2(d) 所示,子任务 t 1 , t 2 , . . . , t k t_1, t_2, ..., t_k t1,t2,...,tk 会根据其依赖关系进行执行:当子任务相互独立时,可并行执行;若存在依赖关系,则需顺序执行。这种混合执行策略确保了查询处理的效率与灵活性。
2.2.4 结果汇总
当所有子任务执行完毕后,中间结果 r 1 , r 2 , . . . , r k {r_1, r_2, ..., r_k} r1,r2,...,rk 会被聚合,生成最终结果 r q r_q rq,用于回答最初的用户查询 q q q。这个聚合步骤可以直接合并多个子结果,也可以使用大语言模型进行总结、提炼并生成最终答案:
r q = Summary ( { r 1 , … , r k } ) , r_q = \text{Summary}(\{r_1, \dots, r_k\}), rq=Summary({r1,…,rk}),
这种类 RAG 的方法确保了复杂业务查询的系统化处理。通过基于检索知识的动态任务生成和适应性的执行策略,该流程能高效应对复杂的任务依赖,适用于大规模真实世界的应用场景。
3. 实验
我们在开源数据集 Spider [2] 以及两个企业场景中人工标注的数据集上进行了大量的离线评估,并在全球最大的 B2B 电商平台上多个真实应用场景中对 SQLord 进行了在线验证。
数据集 该数据集包含 6000 对 <Query, SQL> 样本,来自两个在线业务场景:1. 海关进出口数据问答:用于贸易数据分析;2. 智能选品:用于帮助商家进行商品采购。这些数据真实反映了全球最大 B2B 电商平台中自然语言转 SQL(NL2SQL)任务的复杂性。此外,还使用了 Spider 数据集,这是一个由 11 位耶鲁大学学生标注的、开源的大规模跨领域 NL2SQL 数据集。
实现 以 Qwen2-7B-Instruct(简称 Qwen)为基础大语言模型实现 [1]。反向数据生成模型 RevLLM 在 73,589 对 <SQL, COMMENT> 样本上训练,并生成了 35,948 对标注的 <Query, SQL> 数据,用于微调 SQL 模型(SQLLM)。训练设置为 3 个 epoch,学习率为 1e-5,batch size 为 1。所有实验均在 8 块 NVIDIA H100 GPU 上进行,评估标准包括:
- EXE:执行准确率(Execution Accuracy)、
- QSE:Query 与 SQL 的一致性(Query-SQL Consistency)、
- SSE:SQL 之间的结构与语义等价性(SQL-SQL Equivalence)。
 |  |
|---|---|
 |  |
3.1 离线评估
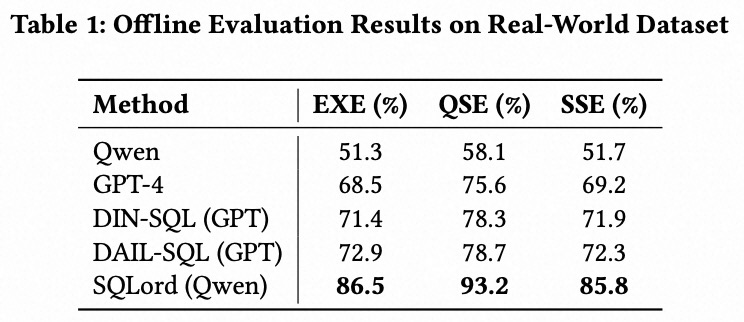
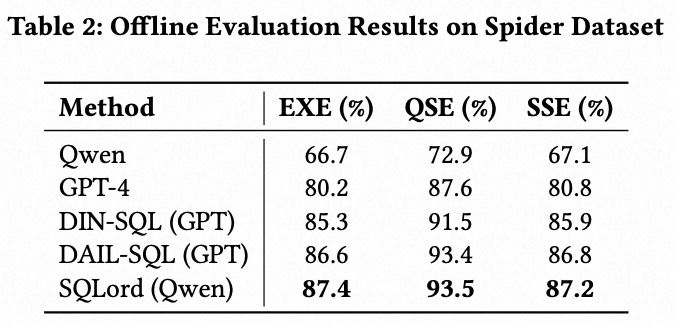
我们在两个数据集上评估了 SQLord:一个是由两个企业场景中标注的 6000 个 <Query, SQL> 对组成的真实场景数据集(Real-World Dataset),另一个是 Spider 数据集。评估指标包括执行准确率(EXE)、Query-SQL 一致性(QSE)和 SQL-SQL 等价性(SSE)。我们将 SQLord 与多个基线模型进行对比:Qwen;使用上下文学习的 GPT-4 [11];基于 GPT 的框架 DIN-SQL (GPT) [12] 和 DAIL-SQL (GPT) [4];以及以 Qwen 为基础 LLM 的 SQLord (Qwen)。结果如表 1 和表 2 所示。
SQLord 在所有基线上表现最优,其中 SQLord (Qwen) 在两个评估数据集上均取得了最高分。在真实场景数据集上,其 EXE 达到 86.5%,比 DAIL-SQL (GPT) 高出 13.6 个百分点;在 Spider 数据集上达到 87.4%,展现了其泛化能力。此外,QSE 和 SSE 分数的一致性差异(±7%)进一步验证了 GPT-Judge 的可靠性,EXE 与 GPT-Judge 之间的稳定差距(QSE 为 ±7%,SSE 为 ±1%)也表明它作为一种不依赖于执行结果的评估方法是有效的。这些结果突出了 SQLord 在多样化任务中的稳健性。
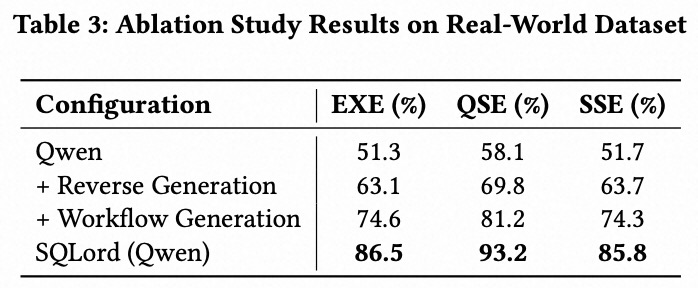
3.2 消融实验
为了评估 SQLord 核心组件的贡献,我们在真实场景数据集上使用 Qwen 作为基础 LLM 进行了消融实验。测试的配置包括:基础 Qwen 模型、加入反向数据生成、加入工作流生成,以及完整的 SQLord 框架。结果如表 3 所示,表明每一个组件都显著提升了 SQLord 的性能。反向数据生成和工作流生成带来了最大的性能提升,其中 SQLord (Qwen) 实现了 86.5% 的 EXE 得分、93.2% 的 QSE 得分以及 85.8% 的 SSE 得分,分别比基础 Qwen 模型提高了 35.2%、35.1% 和 34.1%。
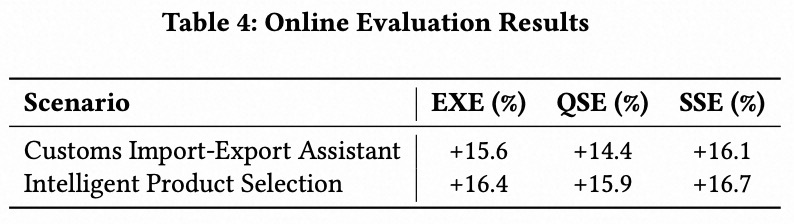
3.3 在线评估
SQLord (Qwen) 被应用于两个企业应用场景中,以评估其在真实环境下生成 SQL 语句的准确性,评估指标包括执行准确率(EXE)、Query-SQL 一致性(QSE)和 SQL-SQL 等价性(SSE)。我们对比了上线前后的实验性能,结果如表 4 所示。结果表明,SQLord 在两个场景中均表现出色,EXE 得分有显著提升:在“关务进出口助手”场景中提升了 15.6%,在“智能选品”场景中提升了 16.4%,凸显了其在应对复杂真实查询时的稳健性和适应性。
4. 结论
本文提出了 SQLord, 一个面向企业的 NL2SQL 框架,通过反向数据生成、工作流分解以及稳健的评估机制,有效应对了领域特定的挑战。在真实世界数据集上的实验以及在企业场景中的成功部署表明,SQLord 在处理复杂业务查询方面相较于现有方法具有更高的准确性和效率。SQLord 的模块化架构保证了其对不断变化的业务需求的适应能力,同时与大型语言模型的集成也展示了其在 NL2SQL 领域持续优化和创新的潜力。通过连接学术研究与实际应用,SQLord 为推动各行业智能数据系统的可扩展发展奠定了基础。
@inproceedings{cheng2025sqlord,title={SQLord: A Robust Enterprise Text-to-SQL Solution via Reverse Data Generation and Workflow Decomposition},author={Cheng, Song and Cheng, Qiannan and Jin, Linbo and Yi, Lei and Zhang, Guannan},booktitle={Companion Proceedings of the ACM on Web Conference 2025},pages={919--923},year={2025}
}
阅读原文
参考文献
-
2024. Qwen2 Technical Report. (2024).
-
LILY Group at Yale University. 2018. Spider 1.0, Yale Semantic Parsing and Text-to-SQL Challenge. (2018). https://yale-lily.github.io/spider
-
Xuemei Dong, Chao Zhang, Yuhang Ge, Yuren Mao, Yunjun Gao, Lu Chen, Jinshu Lin, and Dongfang Lou. 2023. C3: Zero-shot Text-to-SQL with ChatGPT. CoRR abs/2307.07306 (2023).
-
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation. Proceedings of the VLDB Endowment 17, 5 (2024).
-
Binyuan Hui, Ruiying Geng, Lihan Wang, Bowen Qin, Yanyang Li, Bowen Li, Jian Sun, and Yongbin Li. 2022. S2SQL: Injecting Syntax to Question-Schema Interaction Graph Encoder for Text-to-SQL Parsers. In Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22–27, 2022. Association for Computational Linguistics, 1254–1262.
-
Haoyang Li, Jing Zhang, Cuiping Li, and Hong Chen. 2023. Resdsql: Decoupling schema linking and skeleton parsing for text-to-sql. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 13067–13075.
-
Jinyang Li, Binyuan Hui, Reynold Cheng, Bowen Qin, Chenhao Ma, Nan Huo, Fei Huang, Wenyu Du, Luo Si, and Yongbin Li. 2023. Graphix-t5: Mixing pre-trained transformers with graph-aware layers for text-to-sql parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 13076–13084.
-
Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What Makes Good In-Context Examples for GPT-3?. In Proceedings of Deep Learning Inside Out: The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, DeeLIO@ACL 2022, Dublin, Ireland and Online, May 27, 2022. Association for Computational Linguistics, 100–114.
-
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuyu Luo, Yuxin Zhang, Ju Fan, Guoliang Li, and Nan Tang. 2024. A Survey of NL2SQL with Large Language Models: Where are we, and where are we going? CoRR abs/2408.05109 (2024).
-
Linyong Nan, Yilun Zhao, Weijin Zou, Narutatsu Ri, Jaesung Tae, Ellen Zhang, Arman Cohan, and Dragomir Radev. 2023. Enhancing text-to-SQL capabilities of large language models: A study on prompt design strategies. In Findings of the Association for Computational Linguistics: EMNLP 2023. 14935–14956.
-
OpenAI. 2023. GPT-4 Technical Report. CoRR abs/2303.08774 (2023). https://doi.org/10.48550/arXiv.2303.08774
-
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10–16, 2023.
-
Nitarshan Rajkumar, Raymond Li, and Dzmitry Bahdanau. 2022. Evaluating the Text-to-SQL Capabilities of Large Language Models. CoRR abs/2204.00498 (2022).
-
Immanuel Trummer. 2022. CodexDB: Synthesizing code for query processing from natural language instructions using GPT-3 Codex. Proceedings of the VLDB Endowment 15, 11, 2921–2928.
-
Bailin Wang, Richard Shin, Xiaodong Liu, Oleksandr Polozov, and Matthew Richardson. 2020. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5–10, 2020. Association for Computational Linguistics, 7567–7578.