Kafka Broker 总体工作流程
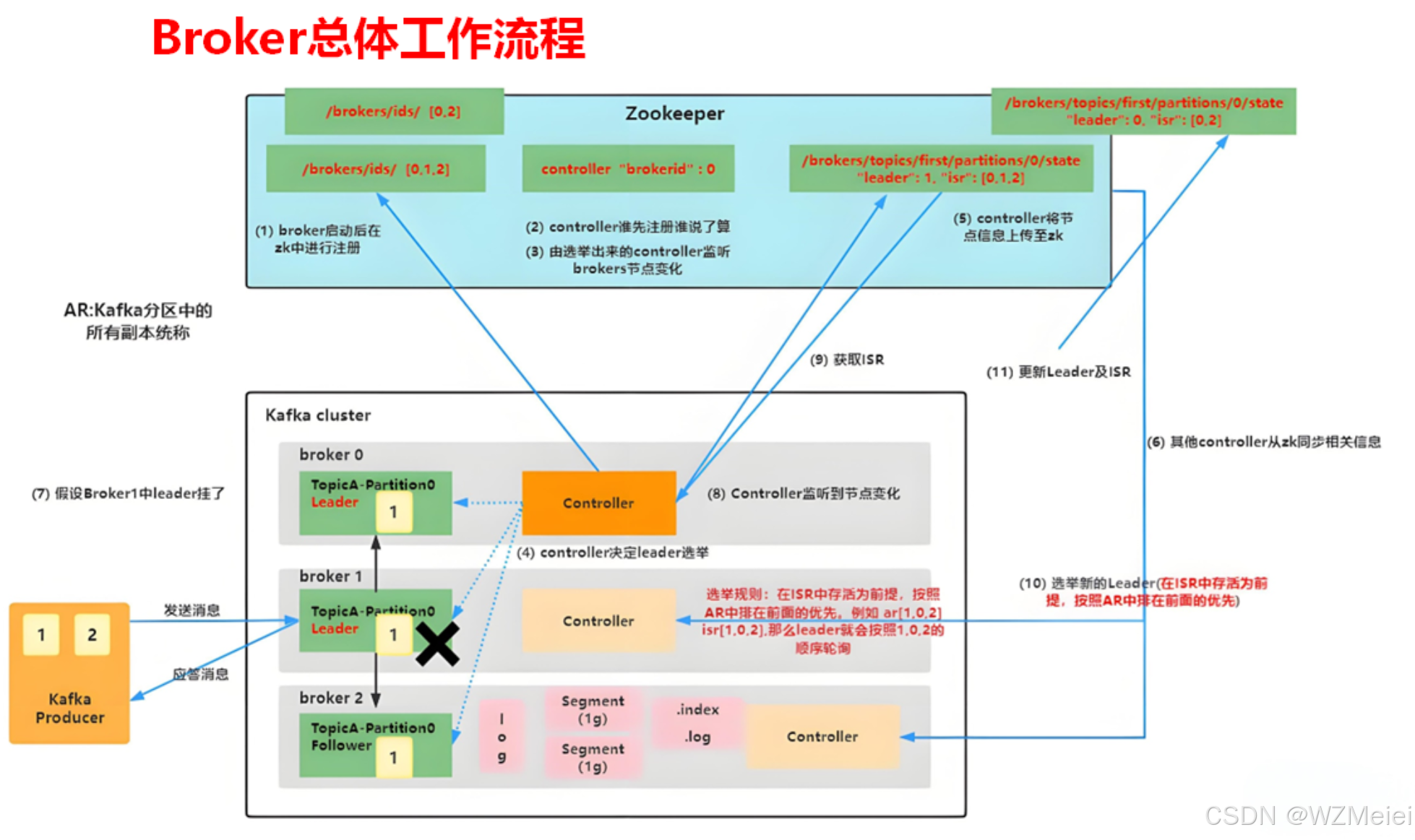
以下是结合图片对 Kafka Broker 工作流程的介绍:
一、启动注册阶段
- 在 ZooKeeper 注册 :Broker 启动后,会在 ZooKeeper 中进行注册,在
/brokers/ids/路径下创建代表自己的节点 ,比如图中broker0、broker1和broker2对应的节点 。这一步让集群中的其他组件(如 Controller )能够感知到 Broker 的存在。 - Controller 选举 :多个 Broker 启动时,会竞争成为 Controller 。谁先在 ZooKeeper 上成功注册相关信息(如
controller "brokerid": 0)谁就成为 Controller 。Controller 在 Kafka 集群中起着至关重要的作用,负责管理集群中 Broker 和 Topic 分区等的相关变化。 - Controller 监听 :当选的 Controller 会监听 ZooKeeper 中
brokers节点的变化情况 。一旦有 Broker 节点新增、删除或者状态改变等情况发生,Controller 能够及时感知到。
二、运行及状态维护阶段
- Leader 选举决策 :Controller 负责决定 Topic 分区的 Leader 选举相关事宜 。对于每个 Topic 的分区,都需要确定一个 Leader 副本,其他副本作为 Follower 副本 。
- 节点信息上传 :Controller 将 Broker 节点以及 Topic 分区等相关信息上传至 ZooKeeper ,比如在
/brokers/topics/first/partitions/0/state路径下记录分区的 Leader 和 ISR(In - Sync Replicas,同步副本集 )信息。 - 信息同步 :其他 Broker 从 ZooKeeper 同步这些相关信息,确保每个 Broker 都能知晓集群中 Topic 分区的 Leader 和 ISR 等状态 。
三、故障处理及 Leader 重选阶段
- 故障假设 :假设 Broker1 中某个分区的 Leader 副本挂掉了 ,比如图中
TopicA - Partition0在 Broker1 上的 Leader 副本出现故障 。 - 故障感知 :Controller 监听到 Broker 节点或者分区状态的变化 ,得知有 Leader 副本失效的情况发生。
- 获取 ISR :Controller 获取故障分区对应的 ISR ,即与 Leader 副本保持同步的 Follower 副本集合 。
- 新 Leader 选举 :按照选举规则(在 ISR 中存活的前提下,按照 AR(所有副本集合 )中排在前面的优先 )选举新的 Leader 。例如
ar[1,0,2],isr[1,0,2],则 leader 会按照 1,0,2 的顺序轮询选举 。 - 更新信息 :选举出新 Leader 后,Controller 更新 ZooKeeper 中相应分区的 Leader 及 ISR 信息 ,并通知其他 Broker 节点进行状态更新 。
四、消息收发阶段
Kafka Producer 发送消息时,会根据分区信息将消息发送到对应的 Leader 副本所在的 Broker 。Broker 接收到消息后进行存储等操作,同时 Follower 副本会从 Leader 副本同步消息,以保持数据的一致性 。当 Consumer 消费消息时,也是从 Leader 副本所在的 Broker 拉取消息 。
有无ZK的 Broker 工作流程对比
①有 ZooKeeper 时 Kafka Broker 工作流程要点
- 注册与发现:Broker 启动后在 ZooKeeper 的特定路径下注册节点,宣告自身存在,方便其他组件(如 Controller )发现 。
注册登记
原理:就像一群学生到学校报到注册,Kafka 的 Broker 启动后,要到 ZooKeeper 这个 “登记处” 去登记自己的信息。在 ZooKeeper 的特定路径下创建一个代表自己的 “小房间”(节点) ,告诉大家 “我来了” 。比如broker0、broker1等都会在/brokers/ids/下面有自己的节点 。
作用:这样其他组件(比如 Controller ,类似班级管理员 )就能知道有哪些 Broker 存在,方便后续管理。
- Controller 选举与管理:多个 Broker 竞争在 ZooKeeper 上创建 Controller 相关节点,先成功创建者成为 Controller 。Controller 监听 ZooKeeper 中 Broker、Topic 分区等节点变化,决策 Leader 选举等事宜,并将相关信息更新到 ZooKeeper ,供其他 Broker 同步 。
Controller 选举
原理:多个 Broker 就像竞选班长一样竞争成为 Controller 。它们都往 ZooKeeper 里放一个 “竞选牌子” ,谁先放进去谁就当选。当选的 Controller 负责管理班级(Kafka 集群 )的很多事情 。
作用:Controller 要负责关注班级里(集群中 )Broker 的变化情况,比如有新同学(新 Broker )加入,或者有同学请假(Broker 故障 )等。
- 状态维护:Broker 依赖 ZooKeeper 存储和获取 Topic 分区的 Leader、ISR 等状态信息 ,确保集群状态一致性 。
原理:ZooKeeper 就像一个班级公告栏,Controller 把班级里(集群中 )Topic 分区的一些重要信息(比如哪个 Broker 是某个分区的 Leader ,哪些是 Follower 等 )都写在公告栏上 。Broker 们就像学生看公告栏一样,从 ZooKeeper 获取这些信息 。
作用:保证每个 Broker 都知道集群的最新状态,大家信息一致,才能好好 “干活” 。
②无 ZooKeeper 时 Kafka Broker 工作流程
(以 Kafka 4.0 及后续版本采用 KRaft 协议为例 )
- 集群元数据管理:使用自研的 KRaft 协议,Kafka 自身的 Controller 负责管理集群元数据 ,包括 Broker 信息、Topic 和分区的元数据等 。Controller 节点在集群中通过类似 raft 协议的选举机制产生,不再依赖 ZooKeeper 进行元数据存储和管理 。
内部管理
原理:没有了 ZooKeeper 这个 “登记处” ,Kafka 自己搞了一套内部管理机制(KRaft 协议 )。Controller 就像班级里自己选出的管理员,它自己负责管理班级(集群 )的信息,不需要跑到外面的 “登记处” 去登记了 。
作用:Controller 自己管理 Broker 信息、Topic 和分区的信息等,就像班长自己记录班级同学信息和班级事务安排 。
- 节点通信与协调:Broker 之间直接通过基于 KRaft 协议的通信机制进行节点状态信息交换、Leader 选举等操作 。比如,当某个 Broker 节点故障或分区 Leader 副本故障时,Controller 通过内部通信机制协调新 Leader 选举 ,并将新的集群状态信息同步给其他 Broker 。
直接沟通
原理:Broker 之间不再通过 ZooKeeper 这个 “传话筒” 交流了,它们直接互相沟通 。比如某个 Broker 出问题了,其他 Broker 能直接通过内部的沟通机制(基于 KRaft 协议 )知道情况,然后一起商量选新的 Leader 。
作用:这样沟通更直接,减少了中间环节,能更快地处理问题 。
- 消费者组管理:消费者组的管理相关操作(如重平衡 )也不再依赖 ZooKeeper 。新的消费者重平衡协议将分区分配逻辑从客户端转移到服务端 ,服务端可以从全局视角优化重平衡操作,当某个消费者发生变更时,其他消费者可独立进行重平衡,提高系统可靠性和扩展性 。
消费者组管理
原理:以前消费者组管理有点依赖 ZooKeeper 这个 “协调员” ,现在 Kafka 自己把这个活揽过来了。就像班级里以前有些事情要找校外的人帮忙协调,现在班长自己就能协调了 。
作用:能更灵活地管理消费者组,比如在消费者增减时,能更快更好地进行任务分配(重平衡 )。
二者差别
- 依赖组件:有 ZooKeeper 时依赖外部的 ZooKeeper 集群实现 Broker 注册、Controller 选举、元数据存储等功能;无 ZooKeeper 时通过内部的 KRaft 协议,Kafka 自身完成上述功能,降低对外部组件的依赖 。
就比如像有 ZooKeeper 时,Kafka 像个依赖家长(ZooKeeper )的孩子,很多事要家长帮忙做;没 ZooKeeper 时,Kafka 像长大了能独立的孩子,自己能处理很多事 。
- 性能与扩展性:无 ZooKeeper 架构下,Kafka 突破了 ZooKeeper 万级集群限制,扩展能力提升到百万级分区级别,元数据同步延迟降低,故障恢复时间从分钟级缩短到秒级 。有 ZooKeeper 时,在大规模集群场景下,ZooKeeper 可能成为性能瓶颈 。
就比如像没 ZooKeeper 时,Kafka 能处理更多的 “班级事务”(百万级分区 ),反应也更快(故障恢复从慢腾腾的分钟级变成快速的秒级 );有 ZooKeeper 时,在 “班级” 规模大了之后,ZooKeeper 这个 “家长” 可能会忙不过来,成为瓶颈 。
- 部署与运维复杂度:有 ZooKeeper 时,需同时部署、维护 Kafka 和 ZooKeeper 集群,配置和管理较为复杂;无 ZooKeeper 时,只需专注于 Kafka 集群本身,简化了部署和运维工作 。
就比如像有 ZooKeeper 时,要照顾 Kafka 和 ZooKeeper 两个 “孩子” ,管理起来麻烦;没 ZooKeeper 时,只需要照顾 Kafka 一个 “孩子” ,管理起来轻松多了 。