【TKDE25】Large-Scale Clustering With Anchor-BasedConstrained Laplacian Rank
1、摘要
基于图的聚类技术因其能够通过成对的图相似性精确地刻画信息而受到广泛关注。然而,传统方法中的后处理步骤常常导致关键信息的丢失,从而限制了聚类效果。为了解决这一问题,受限拉普拉斯秩(Constrained Laplacian Rank, CLR)理论被提出,旨在直接从最优结构图中获取离散标签,并取得了良好的效果。
然而,CLR方法存在显著的时间开销问题,导致其难以应用于大规模数据分析。为了解决这一问题,我们提出了一种简单而高效的基于锚点的CLR方法(ACLR),以实现高效的大规模聚类。
ACLR方法包括四个阶段:
-
选择可以粗略覆盖原始数据的锚点,以便构建二部图;
-
提出一种新颖的两步概率传递策略(TSPT),在锚点之间以随机游走概率初始化小规模图;
-
通过主模型交替优化图的连接结构,并直接生成锚点的离散标签,得益于大幅缩减的图规模,使得时间复杂度与样本数无关;
-
利用K近邻(K-NN)算法将锚点标签传播至所有样本。
大量实验表明,ACLR在聚类准确性和效率上均表现出色,尤其在处理大规模数据时更具优势。
代码地址:GitHub - MarathonZhenyuMa/2025-TKDE-ACLR: Source Code for Large-scale clustering with Anchor-based Constraint Laplacian Rank (ACLR) accepted by IEEE TKDE
2、相关工作
3、方法
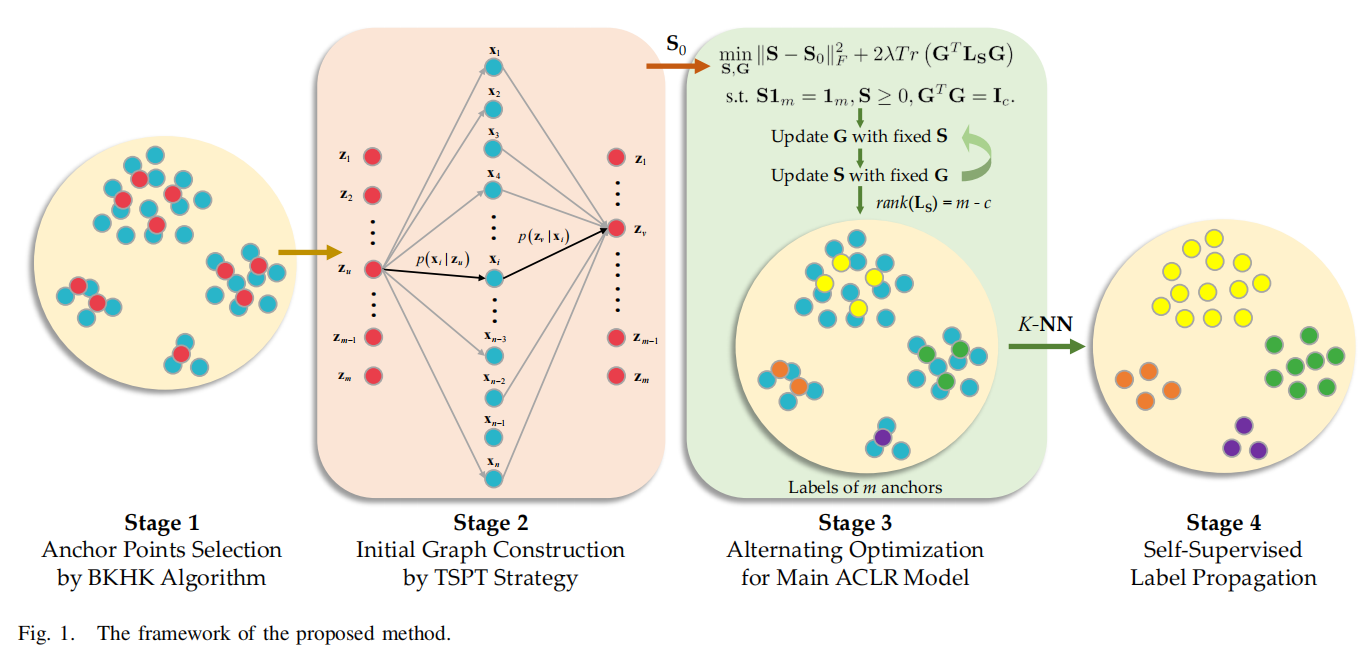
3.1选锚点(四种方法)
随机、KM、KM++、BKHK
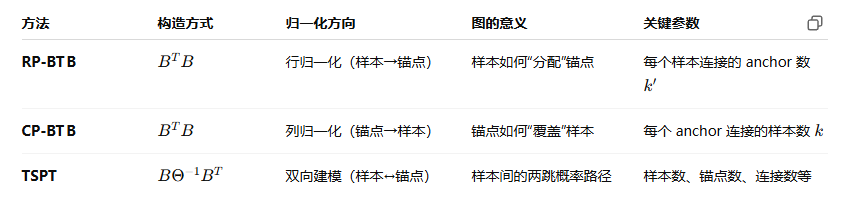
3.2构造初始图(三种方法)
3.3迭代算法model(6)
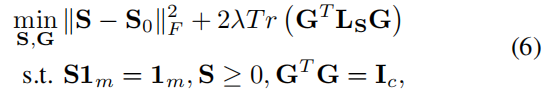
3.4锚点级到样本集标签传播
k近邻投票
4、主要创新
初始图构造的TSPT方法,以及锚点到样本的标签传播