第J2周:ResNet50V2 算法实战与解析
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
学习目标
✅ 根据TensorFlow代码,编写出相应的Python代码
✅ 了解ResNetV2和ResNet模型的区别
一、环境配置
二、数据预处理

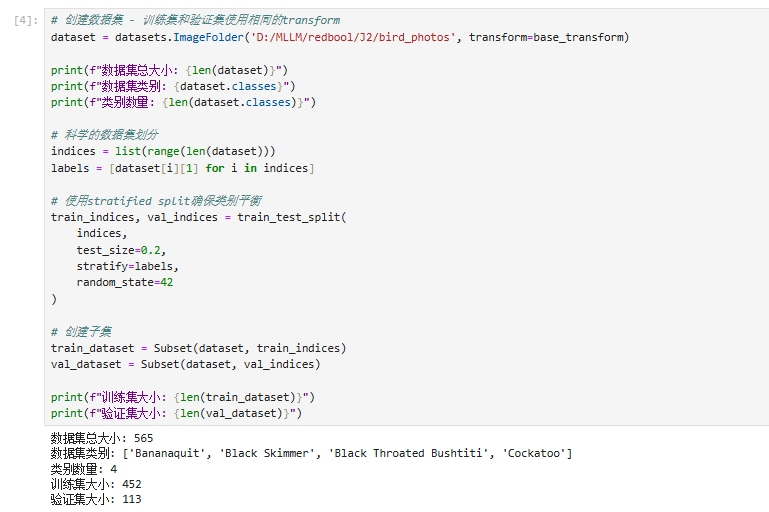
三、创建、划分数据集
四、 创建数据加载器
五、加载预训练

六、显示训练数据
# 显示一些训练图像示例
def show_images(loader, title="数据示例"):plt.figure(figsize=(12, 8))plt.suptitle(title, fontsize=16)try:for batch_idx, (images, labels) in enumerate(loader):images = images[:12]labels = labels[:12]breakfor i in range(min(12, len(images))):ax = plt.subplot(3, 4, i + 1)img = images[i].cpu().numpy().transpose((1, 2, 0))# 反标准化mean = np.array([0.485, 0.456, 0.406])std = np.array([0.229, 0.224, 0.225])img = std * img + meanimg = np.clip(img, 0, 1)ax.imshow(img)ax.set_title(f"{dataset.classes[labels[i]]}", fontsize=10)ax.axis("off")plt.tight_layout()plt.show()except Exception as e:print(f"无法显示图像示例: {e}")plt.close()# 显示训练数据示例
print("\n显示训练数据示例...")
show_images(train_loader, "训练数据示例(无数据增强)")

七、编写训练函数、测试函数、设置早停机制
# 训练函数
def train_epoch(model, device, train_loader, optimizer, criterion):model.train()running_loss = 0.0running_corrects = 0total = 0for batch_idx, (inputs, labels) in enumerate(train_loader):try:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, preds = torch.max(outputs, 1)running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)total += labels.size(0)if batch_idx % 10 == 0:print(f'Batch: {batch_idx}/{len(train_loader)}, Loss: {loss.item():.4f}')# 清理GPU内存del inputs, labels, outputs, lossif torch.cuda.is_available():torch.cuda.empty_cache()except Exception as e:print(f"训练批次 {batch_idx} 出现错误: {e}")if torch.cuda.is_available():torch.cuda.empty_cache()continueepoch_loss = running_loss / total if total > 0 else float('inf')epoch_acc = running_corrects.double() / total if total > 0 else 0return epoch_loss, epoch_acc# 验证函数
def validate(model, device, val_loader, criterion):model.eval()running_loss = 0.0running_corrects = 0total = 0with torch.no_grad():for inputs, labels in val_loader:try:inputs, labels = inputs.to(device), labels.to(device)outputs = model(inputs)loss = criterion(outputs, labels)_, preds = torch.max(outputs, 1)running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)total += labels.size(0)# 清理内存del inputs, labels, outputs, lossif torch.cuda.is_available():torch.cuda.empty_cache()except Exception as e:print(f"验证过程中出现错误: {e}")if torch.cuda.is_available():torch.cuda.empty_cache()continueepoch_loss = running_loss / total if total > 0 else float('inf')epoch_acc = running_corrects.double() / total if total > 0 else 0return epoch_loss, epoch_acc
# 早停机制
class EarlyStopping:def __init__(self, patience=7, verbose=False, delta=0.001, path='best_resnet50v2.pth'):self.patience = patienceself.verbose = verboseself.counter = 0self.best_score = Noneself.early_stop = Falseself.val_loss_min = np.Infself.delta = deltaself.path = pathdef __call__(self, val_loss, model):score = -val_lossif self.best_score is None:self.best_score = scoreself.save_checkpoint(val_loss, model)elif score < self.best_score + self.delta:self.counter += 1if self.verbose:print(f'EarlyStopping counter: {self.counter} out of {self.patience}')if self.counter >= self.patience:self.early_stop = Trueelse:self.best_score = scoreself.save_checkpoint(val_loss, model)self.counter = 0def save_checkpoint(self, val_loss, model):if self.verbose:print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')torch.save(model.state_dict(), self.path)self.val_loss_min = val_loss
八、开始训练
# 开始训练
print("\n开始训练...")
num_epochs = 25
early_stopping = EarlyStopping(patience=5, verbose=True)train_losses = []
train_accs = []
val_losses = []
val_accs = []
lr_history = []for epoch in range(num_epochs):print(f'\nEpoch {epoch+1}/{num_epochs}')print('-' * 10)try:# 记录当前学习率current_lr = optimizer.param_groups[0]['lr']lr_history.append(current_lr)# 训练阶段train_loss, train_acc = train_epoch(model, device, train_loader, optimizer, criterion)train_losses.append(train_loss)train_accs.append(train_acc.item())# 验证阶段val_loss, val_acc = validate(model, device, val_loader, criterion)val_losses.append(val_loss)val_accs.append(val_acc.item())# 更新学习率scheduler.step()# 打印结果print(f'Train Loss: {train_loss:.4f}, Train Acc: {train_acc*100:.2f}%')print(f'Val Loss: {val_loss:.4f}, Val Acc: {val_acc*100:.2f}%')print(f'Learning Rate: {current_lr:.6f}')# 早停检查early_stopping(val_loss, model)if early_stopping.early_stop:print("Early stopping")breakexcept Exception as e:print(f"Epoch {epoch+1} 出现错误: {e}")print("尝试清理内存并继续...")if torch.cuda.is_available():torch.cuda.empty_cache()continueprint("\n训练完成!")
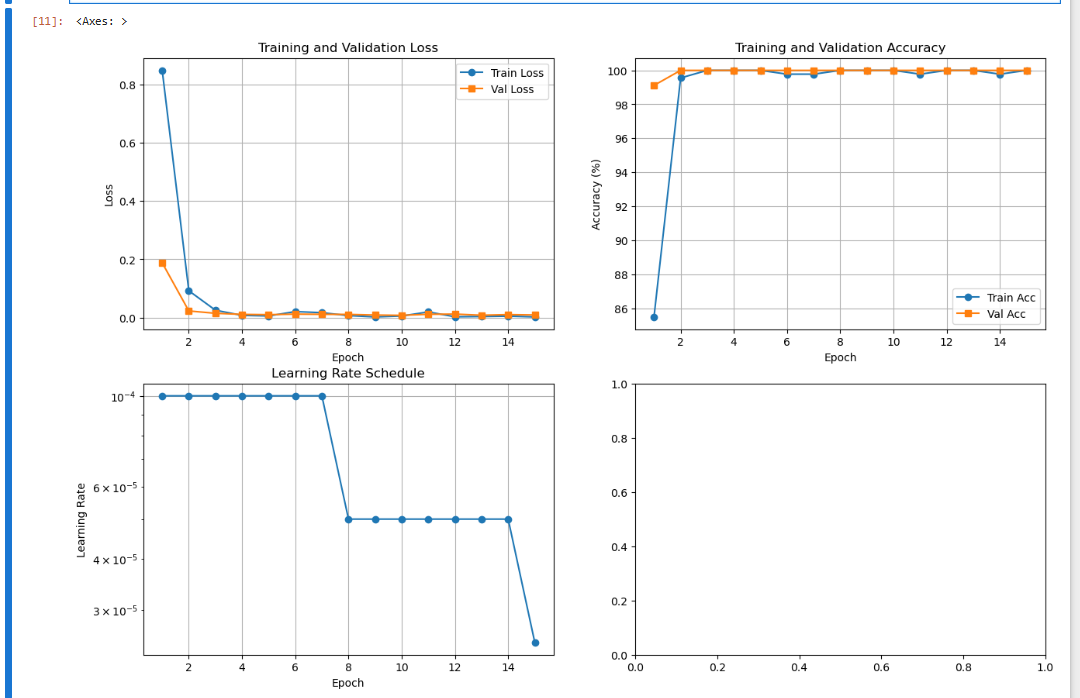
开始训练...Epoch 1/25
----------
Batch: 0/28, Loss: 1.3802
Batch: 10/28, Loss: 1.0213
Batch: 20/28, Loss: 0.4903
Train Loss: 0.8478, Train Acc: 85.49%
Val Loss: 0.1881, Val Acc: 99.12%
Learning Rate: 0.000100
Validation loss decreased (inf --> 0.188087). Saving model ...Epoch 2/25
----------
Batch: 0/28, Loss: 0.2666
Batch: 10/28, Loss: 0.0800
Batch: 20/28, Loss: 0.0263
Train Loss: 0.0922, Train Acc: 99.55%
Val Loss: 0.0231, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.188087 --> 0.023144). Saving model ...Epoch 3/25
----------
Batch: 0/28, Loss: 0.0139
Batch: 10/28, Loss: 0.0292
Batch: 20/28, Loss: 0.0233
Train Loss: 0.0256, Train Acc: 100.00%
Val Loss: 0.0150, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.023144 --> 0.015029). Saving model ...Epoch 4/25
----------
Batch: 0/28, Loss: 0.0086
Batch: 10/28, Loss: 0.0055
Batch: 20/28, Loss: 0.0183
Train Loss: 0.0079, Train Acc: 100.00%
Val Loss: 0.0113, Val Acc: 100.00%
Learning Rate: 0.000100
Validation loss decreased (0.015029 --> 0.011310). Saving model ...Epoch 5/25
----------
Batch: 0/28, Loss: 0.0280
Batch: 10/28, Loss: 0.0064
Batch: 20/28, Loss: 0.0134
Train Loss: 0.0059, Train Acc: 100.00%
Val Loss: 0.0104, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 1 out of 5Epoch 6/25
----------
Batch: 0/28, Loss: 0.0039
Batch: 10/28, Loss: 0.0042
Batch: 20/28, Loss: 0.0041
Train Loss: 0.0209, Train Acc: 99.78%
Val Loss: 0.0122, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 2 out of 5Epoch 7/25
----------
Batch: 0/28, Loss: 0.0015
Batch: 10/28, Loss: 0.0026
Batch: 20/28, Loss: 0.0007
Train Loss: 0.0171, Train Acc: 99.78%
Val Loss: 0.0115, Val Acc: 100.00%
Learning Rate: 0.000100
EarlyStopping counter: 3 out of 5Epoch 8/25
----------
Batch: 0/28, Loss: 0.0041
Batch: 10/28, Loss: 0.0077
Batch: 20/28, Loss: 0.0032
Train Loss: 0.0071, Train Acc: 100.00%
Val Loss: 0.0112, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 4 out of 5Epoch 9/25
----------
Batch: 0/28, Loss: 0.0051
Batch: 10/28, Loss: 0.0014
Batch: 20/28, Loss: 0.0037
Train Loss: 0.0026, Train Acc: 100.00%
Val Loss: 0.0091, Val Acc: 100.00%
Learning Rate: 0.000050
Validation loss decreased (0.011310 --> 0.009129). Saving model ...Epoch 10/25
----------
Batch: 0/28, Loss: 0.0164
Batch: 10/28, Loss: 0.0057
Batch: 20/28, Loss: 0.0015
Train Loss: 0.0058, Train Acc: 100.00%
Val Loss: 0.0080, Val Acc: 100.00%
Learning Rate: 0.000050
Validation loss decreased (0.009129 --> 0.008041). Saving model ...Epoch 11/25
----------
Batch: 0/28, Loss: 0.0019
Batch: 10/28, Loss: 0.0017
Batch: 20/28, Loss: 0.0009
Train Loss: 0.0197, Train Acc: 99.78%
Val Loss: 0.0116, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 1 out of 5Epoch 12/25
----------
Batch: 0/28, Loss: 0.0011
Batch: 10/28, Loss: 0.0018
Batch: 20/28, Loss: 0.0016
Train Loss: 0.0030, Train Acc: 100.00%
Val Loss: 0.0123, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 2 out of 5Epoch 13/25
----------
Batch: 0/28, Loss: 0.0019
Batch: 10/28, Loss: 0.0079
Batch: 20/28, Loss: 0.0068
Train Loss: 0.0040, Train Acc: 100.00%
Val Loss: 0.0085, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 3 out of 5Epoch 14/25
----------
Batch: 0/28, Loss: 0.0009
Batch: 10/28, Loss: 0.0091
Batch: 20/28, Loss: 0.0007
Train Loss: 0.0052, Train Acc: 99.78%
Val Loss: 0.0106, Val Acc: 100.00%
Learning Rate: 0.000050
EarlyStopping counter: 4 out of 5Epoch 15/25
----------
Batch: 0/28, Loss: 0.0020
Batch: 10/28, Loss: 0.0004
Batch: 20/28, Loss: 0.0061
Train Loss: 0.0026, Train Acc: 100.00%
Val Loss: 0.0094, Val Acc: 100.00%
Learning Rate: 0.000025
EarlyStopping counter: 5 out of 5
Early stopping训练完成!
九、评估
# 绘制训练曲线
plt.figure(figsize=(15, 10))plt.subplot(2, 2, 1)
plt.plot(range(1, len(train_losses)+1), train_losses, label='Train Loss', marker='o')
plt.plot(range(1, len(val_losses)+1), val_losses, label='Val Loss', marker='s')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)plt.subplot(2, 2, 2)
plt.plot(range(1, len(train_accs)+1), [acc*100 for acc in train_accs], label='Train Acc', marker='o')
plt.plot(range(1, len(val_accs)+1), [acc*100 for acc in val_accs], label='Val Acc', marker='s')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.grid(True)plt.subplot(2, 2, 3)
plt.plot(range(1, len(lr_history)+1), lr_history, marker='o')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('Learning Rate Schedule')
plt.yscale('log')
plt.grid(True)plt.subplot(2, 2, 4)
十、总结
ResNet v2的主要改进点。可能包括:1. 使用预激活结构,把BatchNorm和ReLU放在卷积之前。这样在残差块中,激活函数先于卷积层应用,这样梯度流动更顺畅,更有效地解决梯度消失的问题。2. 可能还调整了残差路径的设计,比如在跳跃连接中避免不必要的操作,保持恒等映射。3. 可能还涉及到了更深的网络结构或者更高效的训练方法。
然后,我需要总结ResNet v2的架构变化。比如,原来的残差块是conv-BN-ReLU的序列,而v2可能调整为BN-ReLU-conv的顺序,也就是预激活。这样的调整如何影响网络的表现?比如训练更稳定,准确率更高。此外,可能还探讨了不同的残差块设计,比如是否在跳跃连接中加入额外的卷积或BN层,而v2可能简化了这部分,保持跳跃连接尽可能简单,以保留恒等映射的特性。
另外,ResNet v2可能还进行了实验验证,比如在CIFAR-10、ImageNet等数据集上的表现,证明其有效性。比如,更深的网络(如1000层)是否能够稳定训练,准确率是否有提升。
需要注意的是,用户可能需要对比ResNet v1和v2的区别,所以总结时应该明确列出这些区别。比如预激活结构、恒等映射的改进、更优的梯度流动等。