深度学习优化器相关问题
问题汇总
- 各类优化器
- SGD
- Momentum
- Nesterov
- Adagard
- Adadelta
- RMSprop
- Adam优化器
- 为什么Adam不一定最优而SGD最优的
- 深度网络中loss除以10和学习率除以10等价吗
- L1,L2正则化是如何让模型变得稀疏的,正则化的原理
- L1不可导的时候该怎么办
- 梯度消失和梯度爆炸什么原因?怎么避免?
- 消失的原因
- 梯度消失的解决方法
- 梯度爆炸的原因
- 如何避免梯度爆炸
各类优化器
SGD
一般说的 SGD 其实就指的是 Mini-batch GD:把所有样本分为n个batch,每次计算损失和梯度时用一个batch进行计算,并更新参数。
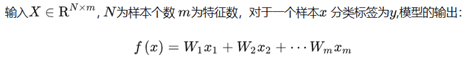
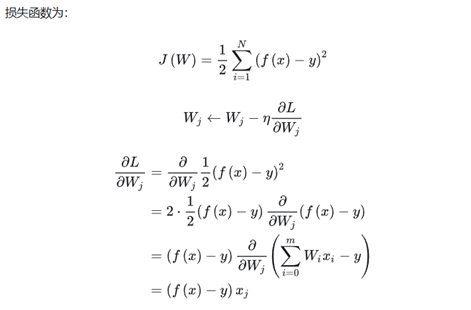
Momentum
每次计算新一次的更新值时考虑当前梯度和历史更新值,其实就是用一阶梯度的指数移动平均代替梯度值进行参数更新。
引入momentum动量α,就是在对当前样本进行梯度更新时,同时考虑历史的更新方向。α就是指数平均的作用,将过去的更新方向和当前的梯度方向进行加权,Momentum梯度下降呈指数衰减。
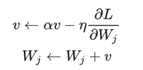
Nesterov
由于momentum考虑了历史的梯度信息,可以加速优化的进程,但如果参数已经处于最优附近,很有可能会因为累积的梯度导致过大的动量,再一次远离最优。
 然后进行标准的梯度下降W← W+v,完成本次迭代真正的梯度更新。
然后进行标准的梯度下降W← W+v,完成本次迭代真正的梯度更新。
Adagard
Adagrad期望利用每个维度的梯度值大小动态调整每个维度的更新步长,就是让快的慢一点,慢的快一点。针对不同的变量提供不同的学习率,设置一个全局的学习率,而实际的学习率与以往的梯度开方的和成反比。


Adadelta
Adadelta是对Adagrad的一个改进,没有选择将梯度的平方和全部累加,而是使用指数加权的形式对梯度进行累积。此外,为了实现加速更新进程的效果,Adadelta还维护了一个更新步长平方的指数加权。

RMSprop
MSProp同样是对Adagrad的改进,相比Adadelta更加直观。只维护一个历史的梯度平方的指数加权,然后用其来影响当前的梯度

Adam优化器
结合了Momentum和 RMSProp 的思想,旨在通过计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率(理解为变化的梯度为Momentum得到的梯度,学习率为原本的学习率/历史梯度平方和的加权)

为什么Adam不一定最优而SGD最优的
- 可能不收敛:SGD没有用到二阶动量,因此学习率是恒定的(实际使用过程中会采用学习率衰减策略,因此学习率递减)。AdaGrad的二阶动量不断累积,单调递增,因此学习率是单调递减的。因此,这两类算法会使得学习率不断递减,最终收敛到0,模型也得以收敛。但AdaDelta和Adam则不然。二阶动量是固定时间窗口内的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得Vt可能会时大时小,不是单调变化。这就可能在训练后期引起学习率的震荡,导致模型无法收敛。
- 可能错过全局最优解: Adam的收敛速度比SGD要快,但最终收敛的结果并没有SGD好。他们进一步实验发现,主要是后期Adam的学习率太低,影响了有效的收敛。
深度网络中loss除以10和学习率除以10等价吗
取决于优化器
a) 传统优化器(如 SGD 和 Momentum SGD):loss缩放和学习率缩放是等价的
b) 带有二阶动量的优化器(如 Adagrad、RMSprop):当将 loss 乘以一个常数(如10或0.1),其影响主要在梯度计算过程中,但不会对参数的更新产生直接影响。这意味着对于这类优化器,将 loss缩放与调整学习率并不等价。
c) 带有自适应学习率的优化器(如 Adam):在Adam中,当loss被缩放时,虽然一阶动量与二阶动量都会受影响,但由于该算法对梯度的处理方式,整体更新的影响很小。因此, loss的缩放不会轻微改变Adam的参数更新,而学习率的变化会对更新产生较大影响。
L1,L2正则化是如何让模型变得稀疏的,正则化的原理
- 正则化的核心思想是在损失函数中加入一个额外的惩罚项,使得模型不仅要拟合数据,还要控制模型的复杂度。这样做的目的是防止模型对训练数据的噪声或过细的细节进行过度拟合,从而提高模型的泛化能力
- L1 正则化通过在损失函数中加入系数的绝对值的和,使得某些特征的系数被压缩为零,因此它具有自然的特征选择效果。L1 正则化鼓励模型的部分系数为零,从而使得模型更加稀疏。当我们最小化损失函数时,L1 正则化项会对大多数特征的系数施加惩罚,同时由于绝对值的性质,它会使得某些系数变为零。这种零化现象的原因是L1 正则化倾向于选择一小部分重要的特征,而将其他不重要的特征系数压缩为零。
- L2 正则化通过在损失函数中加入系数的平方和,惩罚较大的系数。与 L1 正则化不同,L2 正则化不会导致系数为零,而是会将系数收缩到更小的数值,从而使得模型变得更加“平滑”且不易过拟合,L2 正则化不会导致稀疏
L1不可导的时候该怎么办
a) 当损失函数不可导,梯度下降不再有效,可以使用坐标轴下降法。梯度下降是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方法。假设有m个特征个数,坐标轴下降法进行参数更新的时候,先固定m-1个值,然后再求另外一个的局部最优解,从而避免损失函数不可导的问题。
梯度消失和梯度爆炸什么原因?怎么避免?
消失的原因
- 激活函数的选择:某些激活函数(如Sigmoid和Tanh)在输入值较大或较小时,导数接近于0。这会导致在反向传播过程中,梯度逐渐变小,甚至趋近于0。
- 网络深度:在网络层数较多时,梯度在反向传播过程中需要经过多个层的乘法运算。如果每一层的梯度都小于1,多次乘法后梯度会变得非常小,从而导致梯度消失。
3.权重初始化问题:如果权重初始化不当,尤其是初始化值过小,前层的输出值会变得很小,导致后面的梯度也变得非常小,从而加剧梯度消失的现象
梯度消失的解决方法
- 选择合适的激活函数:使用ReLU及其变种(如Leaky ReLU、Parametric ReLU)等激活函数,这些激活函数在正半轴上的导数为1,可以有效避免梯度消失。
- 合理的权重初始化:使用Xavier/Glorot初始化或He初始化等方法,确保初始权重的方差适中,有助于保持梯度的稳定性。
- 使用Batch Normalization:使得数据分布更加稳定,从而避免激活值过大或过小,减少梯度消失的风险。
- 使用残差连接(Residual Connection):残差网络(ResNet)引入了跳跃连接(skip connections),使得梯度可以直接通过残差路径进行传播,减少了梯度消失的影响。通过这种方式,网络可以更深而不会遇到梯度消失问题。
- 选择适当的优化器:一些优化器如Adam、RMSProp等,相比传统的梯度下降算法,它们能够自适应调整学习率,并在训练过程中更加有效地避免梯度消失问题。
梯度爆炸的原因
- 网络层数过深:当网络层数非常深时,梯度在传播过程中,可能会通过某些层积累并放大,导致梯度变得非常大
- 权重初始化不当、学习率过高
- 激活函数导致的梯度放大
如何避免梯度爆炸
- 梯度裁剪(Gradient Clipping):梯度裁剪是一种常用的防止梯度爆炸的方法。在训练过程中,当梯度的L2范数(或其他范数)超过某个阈值时,对梯度进行裁剪,将梯度值缩放到一定范围。这样可以防止梯度变得过大,从而保护网络的稳定性。
- 合理的权重初始化、使用适当的优化器、降低学习率、Batch Normalization、使用残差连接