PaddleOCR的Pytorch推理模块
概述
在项目中,遇到文字识别OCR的使用场景。
然而,目前效果最好的PaddleOCR只能用百度的PaddlePaddle框架运行。
常见项目中,往往使用更普遍的Pytorch框架,单独安装PaddlePaddle不仅会让项目过于臃肿,而且可能存在冲突问题。
在前文拆解MinerU结构时,发现其用了基于PaddleOCR2Pytorch项目转换的PaddleOCR-v4的torch版本。
于是将此部分单独提取出来,做了一些解耦优化,单独构建了一个仓库,方便和其它项目进行集成。
仓库地址:https://github.com/zstar1003/PaddleOCR-Torch-Infer
所用模型
-
检测模型:ch_PP-OCRv4_det_infer.pth
-
识别模型:ch_PP-OCRv4_rec_infer.pth
-
字典文件:ppocr_keys_v1.txt
使用方法
安装依赖
- 安装uv包管理器
建议使用uv来管理依赖环境,若未安装uv,可通过pip进行安装:
pip install uv
- 创建虚拟环境
uv venv --python 3.10
- 激活虚拟环境
.\.venv\Scripts\activate
- 根据
uv.lock安装依赖
uv sync
命令行参数
--data_path:必需参数,指定输入图片路径或目录路径--save_path:可选参数,指定保存结果的路径或目录--show_confidence:可选参数,是否在结果图像中显示置信度(默认不显示)
单图片处理
python infer.py --data_path test_img/general_ocr_rec_001.png --save_path output/result.png
目录批量处理
python infer.py --data_path test_img --save_path output
识别效果展示



PP-OCRv5前瞻
PP-OCRv5简介
有意思的是,当我昨天写完准备发这篇文章时,突然看见PP-OCRv5发布(上一次发布v4在2024.02.20)。
根据官方介绍[11,PP-OCRv5的主要有以下优势:
-
1.单模型支持5种文字类型(简体中文、繁体中文、中文拼音、英文和日文)
-
2.支持复杂手写体识别
-
3.比上一版本PP-OCRv4,识别精度提升13个百分点
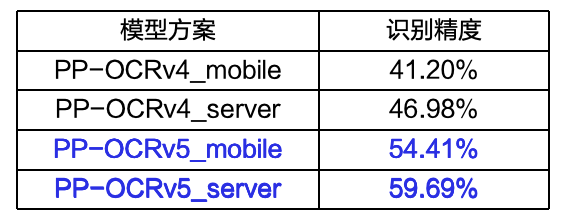
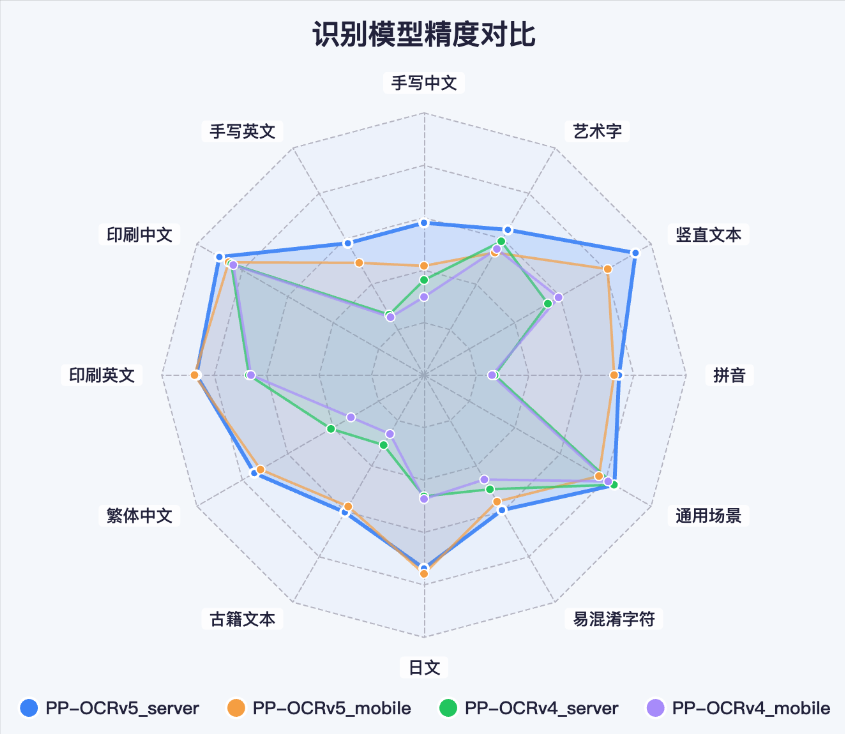
PP-OCRv5模型结构
根据模型的结构配置文件,可以看出,v5和v4的算法和Head部分没有显著差异,核心是修改了Backbone的网络结构。
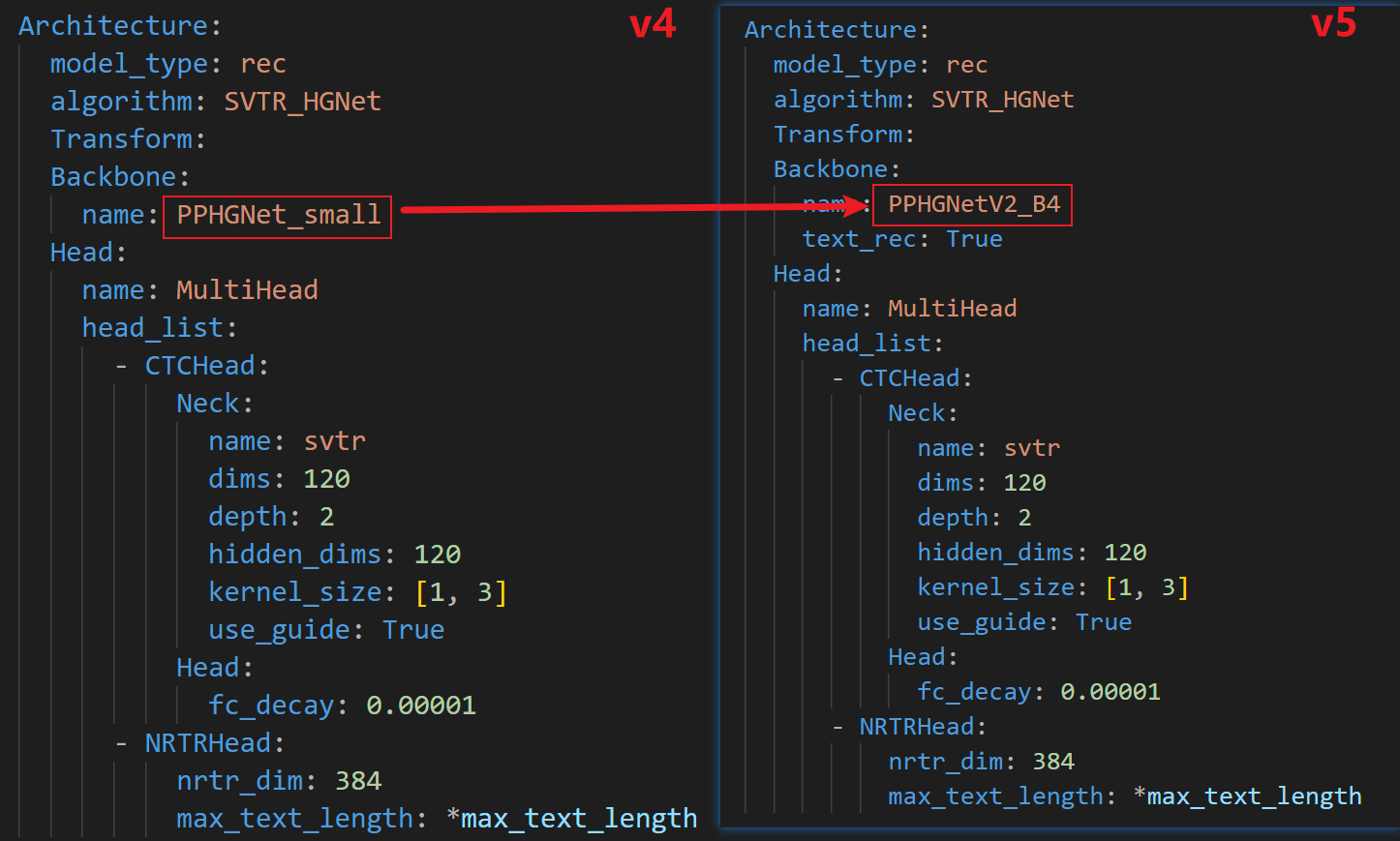
新的PPHGNetV2_B4结构在
ppocr\modeling\backbones\rec_pphgnetv2.py
理论上,用pytorch将该backbone重新实现,就可以进行模型转换。
于是Fork了PaddleOCR2Pytorch这个仓库,尝试用Agent帮我转换了一下。
仓库地址:https://github.com/zstar1003/PaddleOCR2Pytorch
结果发现,能够转换成pth文件,但存在不少参数对齐的问题。
捣鼓了一晚上,发觉还需要投入很多精力去深入了解、精调对其参数结构,遂放弃,等高人解决。
参考
1.PP-OCRv5官方文档:https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/version3.x/algorithm/PP-OCRv5/PP-OCRv5.md
2.PaddleOCR: https://github.com/PaddlePaddle/PaddleOCR)
3.PaddleOCR2Pytorch: https://github.com/frotms/PaddleOCR2Pytorch
4.MinerU: https://github.com/opendatalab/MinerU