Pandas:数据分析步骤、分组函数groupby和基础画图
本文目录:
- 一、概念
- (一)数据分析的基本步骤
- (二)两个属性:loc[行标签,列标签 ] 和 iloc[行索引位置,列索引位置 ]
- 1.基本规则
- 2.两属性的相同和不同对比
- 二、加载数据
- (一)按列加载数据
- (二)按行加载数据
- 三、获取指定行列数据
- 四、DataFrame-分组聚合计算
- (一)数据分析操作步骤
- (二)groupby函数
- (三)实例:分组分析
- 五、Pandas-基本绘图
一、概念
Pandas是用于数据分析的开源Python库,可以实现数据加载,清洗,转换,统计处理,可视化等功能。
(一)数据分析的基本步骤
1.导包:pandas、numpy、smatplotlib等
2.加载数据:创建Series、read()函数等
3.了解数据:idim、shape、describe等
4.数据分析/可视化:groupy by、plot等
(二)两个属性:loc[行标签,列标签 ] 和 iloc[行索引位置,列索引位置 ]
1.基本规则
两种属性都可以接收单值、切片和列表,当参数只传入了一个时,默认为行标签和行索引位置,列名和列索引标签必须显式传递。
2.两属性的相同和不同对比
相同点:
loc[ ]和iloc[ ]都是获取数据的方式,且获取方式都跟索引有关。不同点:
1.获取数据方式不同:loc[ ]传入的是索引值/标签参数(数据类型可以为数值、字符串、列表、布尔值、切片等),iloc[ ]传入的是索引位置(从0开始的数值)参数;
2.loc[ ]是左闭右闭的,也就是说包含传入的数值两端(开始数值和结束数值);iloc[ ]是左闭右开的,也就是说只包含传入的数据左端(开始数值),不包含右端(结束数值);
3.两者的应用场景各不相同,loc[ ]用于有明确索引值的,iloc[ ]用于索引值不明确的时候。注意: 如果没有单独设置行列标签,那么行列标签就使用默认的索引位置,此时用索引位置或者索引标签都一样!!!
二、加载数据
(一)按列加载数据
import pandas as pd# 1. 加载数据
df = pd.read_csv('data/gapminder.tsv', sep='\t') # 指定切割符为\t
df.head()# 2. # 查看df类型
type(df)
df.shape # (1704, 6)
df.columns # Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object')
df.index # RangeIndex(start=0, stop=1704, step=1)
df.dtypes # 查看df对象 每列的数据类型
df.info() # 查看df对象 详细信息# 3. 加载一列数据
# country_series = df['country']
country_series = df.country # 效果同上
country_series.head() # 查看前5条数据
# 细节: 如果写 df['country'] 则是Series对象, 如果写 df[['country']]则是df对象# 4. 加载多列数据
subset = df[['country', 'continent', 'year']] # df对象
print(subset.tail())
(二)按行加载数据
# 1. 按行加载数据
df.head() # 获取前5条, 最左侧是一列行号, 也是 df的行索引, 即: Pandas默认使用行号作为 行索引.# 2. 使用 tail()方法, 获取最后一行数据
df.tail(n=1)# 3. 演示 iloc属性 和 loc属性的区别, loc属性写的是: 行索引值. iloc写的是行号.
df.tail(n=1).loc[1703]
df.tail(n=1).iloc[0] # 效果同上.# 4. loc属性 传入行索引, 来获取df的部分数据(一行, 或多行)
df.loc[0] # 获取 行索引为 0的行
df.loc[99] # 获取 行索引为 99的行
df.loc[[0, 99, 999]] # loc属性, 根据行索引值, 获取多条数据.# 5. 获取最后一条数据
# df.loc[-1] # 报错
df.iloc[-1] # 正确
三、获取指定行列数据
# 1. 获取指定 行|列 数据
df.loc[[0, 1, 2], ['country', 'year', 'lifeExp']] # 行索引, 列名
df.iloc[[0, 1, 2], [0, 2, 3]] # 行索引, 列的编号# 2. 使用loc 获取所有行的, 某些列
df.loc[:, ['year', 'pop']] # 获取所有行的 year 和 pop列数据# 3. 使用 iloc 获取所有行的, 某些列
df.iloc[:, [2, 3, -1]] # 获取所有行的, 索引为: 2, 3 以及 最后1列数据# 4. loc只接收 行列名, iloc只接收行列序号, 搞反了, 会报错.
# df.loc[:, [2, 3, -1]] # 报错
# df.iloc[:, ['country', 'continent']] # 报错# 5. 也可以通过 range()生成序号, 结合 iloc 获取连续多列数据.
df.iloc[:, range(1, 5, 2)]
df.iloc[:, list(range(1, 5, 2))] # 把range()转成列表, 再传入, 也可以.# 6. 在iloc中, 使用切片语法 获取 n列数据.
df.iloc[:, 3:5] # 获取列编号为 3 ~ 5 区间的数据, 包左不包右, 即: 只获取索引为3, 4列的数据.
df.iloc[:, 0:6:2] # 获取列编号为 0 ~ 6 区间, 步长为2的数据, 即: 只获取索引为0, 2, 4列的数据.# 7. 使用loc 和 iloc 获取指定行, 指定列的数据.
df.loc[42, 'country'] # 行索引为42, 列名为:country 的数据
df.iloc[42, 0] # 行号为42, 列编号为: 0 的数据# 8. 获取多行多列
df.iloc[[0, 1, 2], [0, 2, 3]] # 行号, 列的编号
df.loc[2:6, ['country', 'lifeExp', 'gdpPercap']] # 行索引, 列名 推荐用法.
四、DataFrame-分组聚合计算
(一)数据分析操作步骤
1.先将数据分组(**比如:每一年的平均预期寿命问题,按照年份将相同年份的数据分成一组**);
2.对每组的数据再去进行**统计计算**如,求平均,求每组数据条目数(频数)等;
3.再将每一组计算的**结果合并**起来。
(二)groupby函数
格式:
df.groupby('分组字段')['要聚合的字段'].聚合函数()
df.groupby(['分组字段','分组字段2'])[['要聚合的字段','要聚合的字段2']].聚合函数()注意:分组后默认会把**分组字段作为结果的行索引(index)**。
(三)实例:分组分析
# 1. 统计每年, 平均预期寿命
# SQL写法: select year, avg(lifeExp) from 表名 group by year;
df.groupby('year')['lifeExp'].mean()# 2. 上述代码, 拆解介绍.
df.groupby('year') # 它是1个 DataFrameGroupBy df分组对象.
df.groupby('year')['lifeExp'] # 从df分组对象中提取的 SeriesGroupBy Series分组对象(即: 分组后的数据)
df.groupby('year')['lifeExp'].mean() # 对 Series分组对象(即: 分组后的数据), 具体求平均值的动作.# 3. 对多列值, 进行分组聚合操作.
# 需求: 按照年, 大洲分组, 统计每年, 每个大洲的 平均预期寿命, 平均gdp
df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean()# 4. 统计每个大洲, 列出了多少个国家和地区.
df.groupby('continent')['country'].value_counts() # 频数计算, 即: 每个洲, 每个国家和地区 出现了多少次.
df.groupby('continent')['country'].nunique() # 唯一值计数, 即: 每个大洲, 共有多少个国家和地区 参与统计.
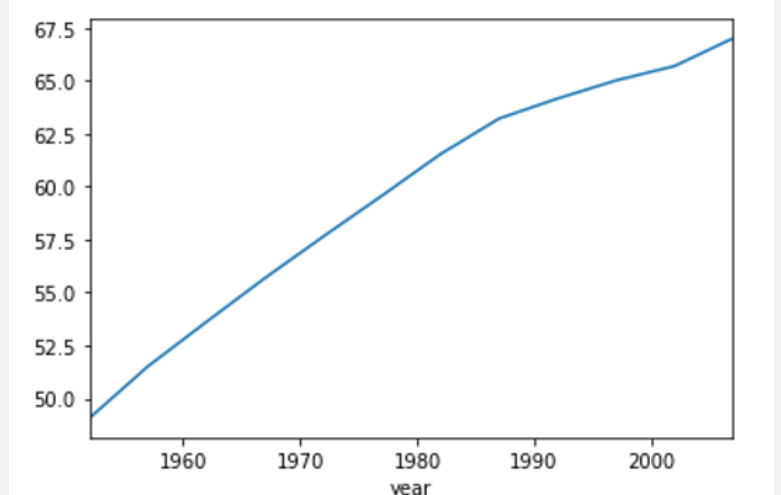
五、Pandas-基本绘图
在理解或清理数据时,可视化(绘图)有助于识别数据中的趋势,所以它很重要。
例:
data = df.groupby('year')['lifeExp'].mean() # Series对象
data.plot() # 可传入kind参数,设置图形样式,如:kind=bar;此处默认绘制的是: 折线图
运行结果如下:
今天的分享到此结束。