【论文阅读 | CVPR 2024 |RSDet:去除再选择:一种用于 RGB - 红外目标检测的由粗到精融合视角】
论文阅读 | CVPR 2024 |RSDet:去除再选择:一种用于 RGB - 红外目标检测的由粗到精融合视角
- 1.摘要&&引言
- 2. 方法
- 2.1 “由粗到细”融合策略
- 2.2 冗余光谱去除模块(RSR)
- 2.3 动态特征选择模块(DFS)
- 2.4 去除与选择检测器(RSDet)
- 3.实验
- 3.1实验设置
- 3.1.1数据集
- 3.1.2评估指标
- 3.1.3实现细节
- 3.2 消融研究
- 3.3 中间结果可视化
- 3.4 与最先进方法的比较
- 4.结论

题目:Removal then Selection: A Coarse-to-Fine Fusion Perspective for RGB-Infrared Object Detection
会议:Computer Vision and Pattern Recognition(CVPR)
论文:https://arxiv.org/abs/2401.10731
代码:https://github.com/Zhao-Tian-yi/RSDet.git
年份:2024
1.摘要&&引言
近年来,利用可见光(RGB)和热红外(IR)图像的目标检测技术已受到广泛关注,并在众多领域得到广泛应用。通过利用 RGB 和 IR 图像之间的互补特性,目标检测任务能够在从白天到夜间的各种光照条件下实现可靠且鲁棒的目标定位。大多数现有的多模态目标检测方法直接将 RGB 和 IR 图像输入深度神经网络,导致检测性能较差。
我们认为,这一问题不仅源于有效融合多模态信息的挑战,还源于 RGB 和 IR 模态中均存在冗余特征。每种模态的冗余信息会在传播过程中加剧融合不精确的问题。
为解决这一问题,我们从人脑处理多模态信息的机制中获得启发,提出了一种新颖的由粗到精的特征净化与融合视角。
具体而言,基于这一视角,我们设计了冗余光谱去除模块(Redundant Spectrum Removal module)以粗略去除各模态内的干扰信息,并设计了动态特征选择模块(Dynamic Feature Selection module)以精细选择所需特征用于特征融合。为验证由粗到精融合策略的有效性,我们构建了一种新的目标检测器,称为先去除后选择检测器(Removal then Selection Detector,RSDet)。
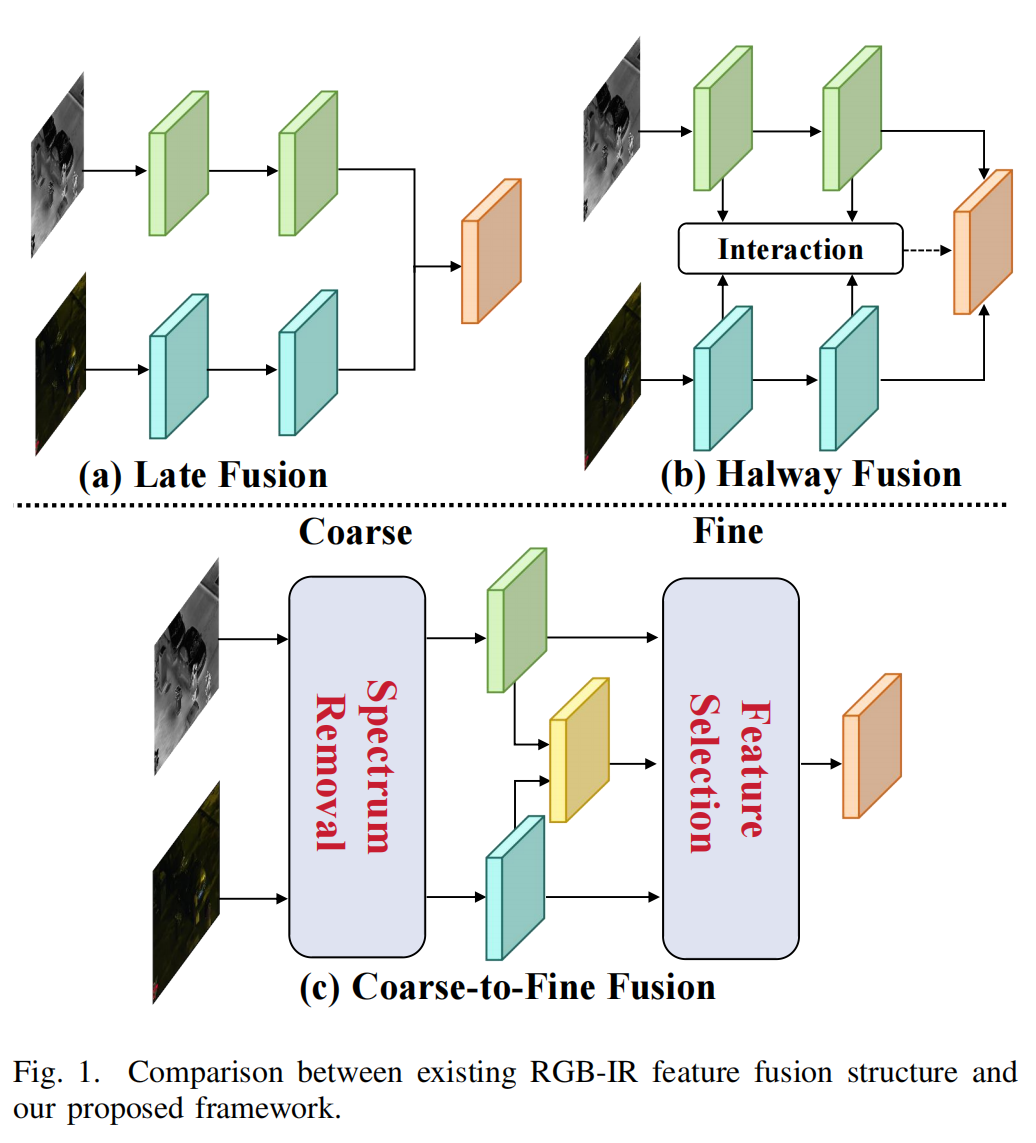
图1. 现有RGB-红外特征融合结构与我们提出的框架的对比。
在 RGB - 红外目标检测中,有效的 RGB 与红外图像特征融合方法至关重要。大多数现有方法独立提取 RGB 和红外图像的模态特定特征,然后直接对特征执行相加或拼接操作,如图 1(a)所示。
由于缺乏显式的跨模态融合,这种 “晚期融合” 策略在学习互补信息方面存在局限,导致性能较差。为探索最优融合策略,许多研究人员提出 “中途融合” 策略,设计不同模态特征间的交互模块,如图 1(b)所示。
例如,Zhou 等人 构建 MBNet 以挖掘 RGB 与红外模态差异,在特征层面引入更多有用信息;Xie 等人 提出动态跨模态模块,聚合来自两种模态的局部和全局特征。尽管这些方法取得了一定进展,但它们仅显式强化互补信息的学习,却忽略了冗余特征在传播过程中的负面影响,导致互补融合难以有效实现。
事实上,人类大脑处理多模态信息时,首先会过滤干扰信息,再精细选择所需信息,这一过程在认知理论(“衰减理论”)中被建模为 “由粗到精” 的机制。受此启发,我们提出一种融合 RGB 与红外特征的新视角,如图 1(c)所示.
我们设计了 “由粗到精融合” 策略以实现特征互补融合。
- “粗” 指首先过滤干扰信息,粗略去除无关光谱:鉴于图像冗余信息存在于频谱中 ,我们提出冗余光谱去除(RSR)模块,通过将图像转换至频域并引入动态滤波器,自适应抑制 RGB 和红外模态内的无关频谱。
- “精” 指在粗过滤后进行特征精细选择:我们设计动态特征选择(DFS)模块,通过探索尺度感知专家混合(mixture of scale-aware experts),对目标检测所需的不同尺度特征进行加权,实现模态间所需特征的精准筛选。

图2. 我们的由粗到精融合方法的有效性。(a)为当前的中途融合方法,其直接提取的特征受到来自RGB图像的背景信息干扰,并对最终融合的特征产生抑制作用,这将导致检测结果较差。(b)我们的由粗到精融合方法能够减少无关信息并选择所需特征进行融合,从而实现更优的性能。
图 2 可视化了由粗到精融合策略的示例结果。为验证该策略的有效性,我们构建了嵌入该融合机制的新型检测框架 —— 先去除后选择检测器(Removal then Selection Detector,RSDet)。
2. 方法
2.1 “由粗到细”融合策略
提出的 “由粗到细” 融合策略灵感来源于人类信息处理的认知模型,特别是认知心理学中的选择性注意理论。典型例子包括布罗德本特的过滤器模型 和特雷斯曼的衰减模型,这些模型构成了认知心理学中注意机制理论的基石。
如图 4 所示,特雷斯曼的衰减模型认为,人脑在处理多个刺激时,会首先根据特定标准对不重要或无关的信息进行衰减,然后对剩余信息进行更精细化的处理 —— 通过细致的分层分析与加工,提取有意义的特征和见解,最终将处理后的信息送入大脑的工作记忆。
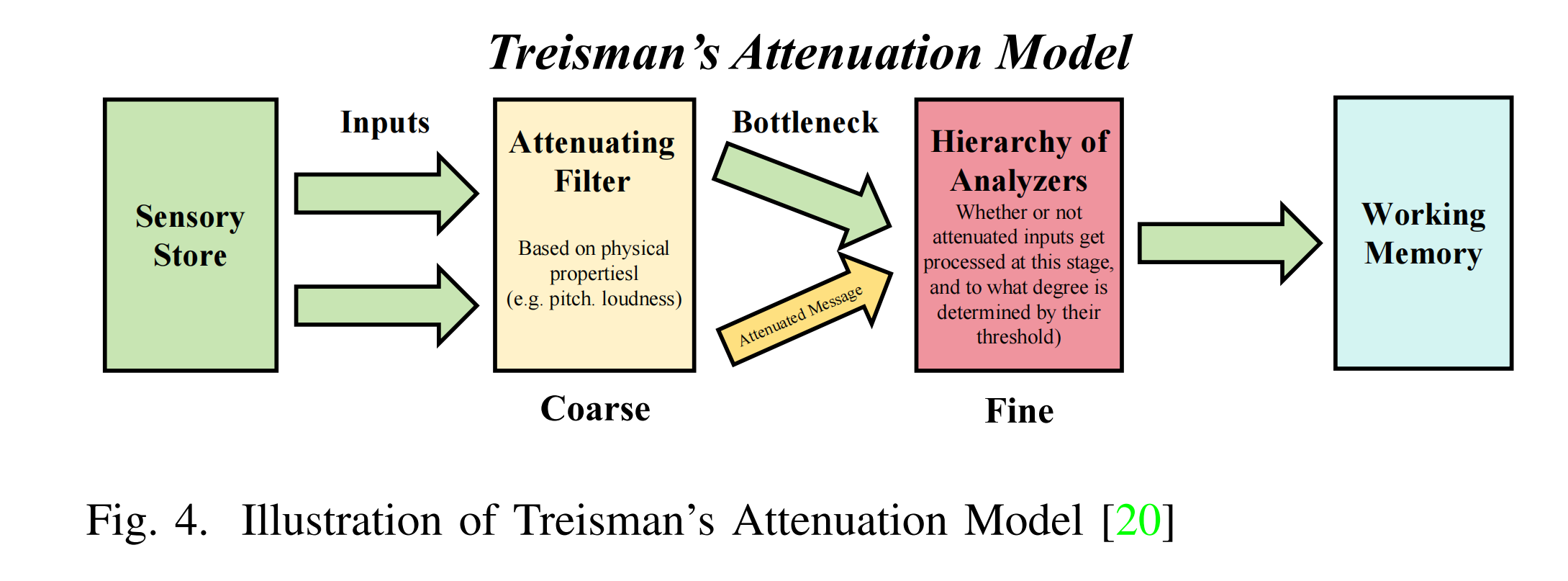
图4. 特雷斯曼衰减模型示意图
受特雷斯曼衰减模型的启发,我们设计了"由粗到细"融合策略。
"粗"对应冗余光谱去除(RSR)模块,用于在频域进行粗粒度过滤;"细"对应动态特征选择(DFS)模块,用于在RGB-红外模态间精细选择所需特征。
由于两种模态的特征常存在交叉,我们引入解耦表示学习对其进行纯化和分离,以实现互补融合。
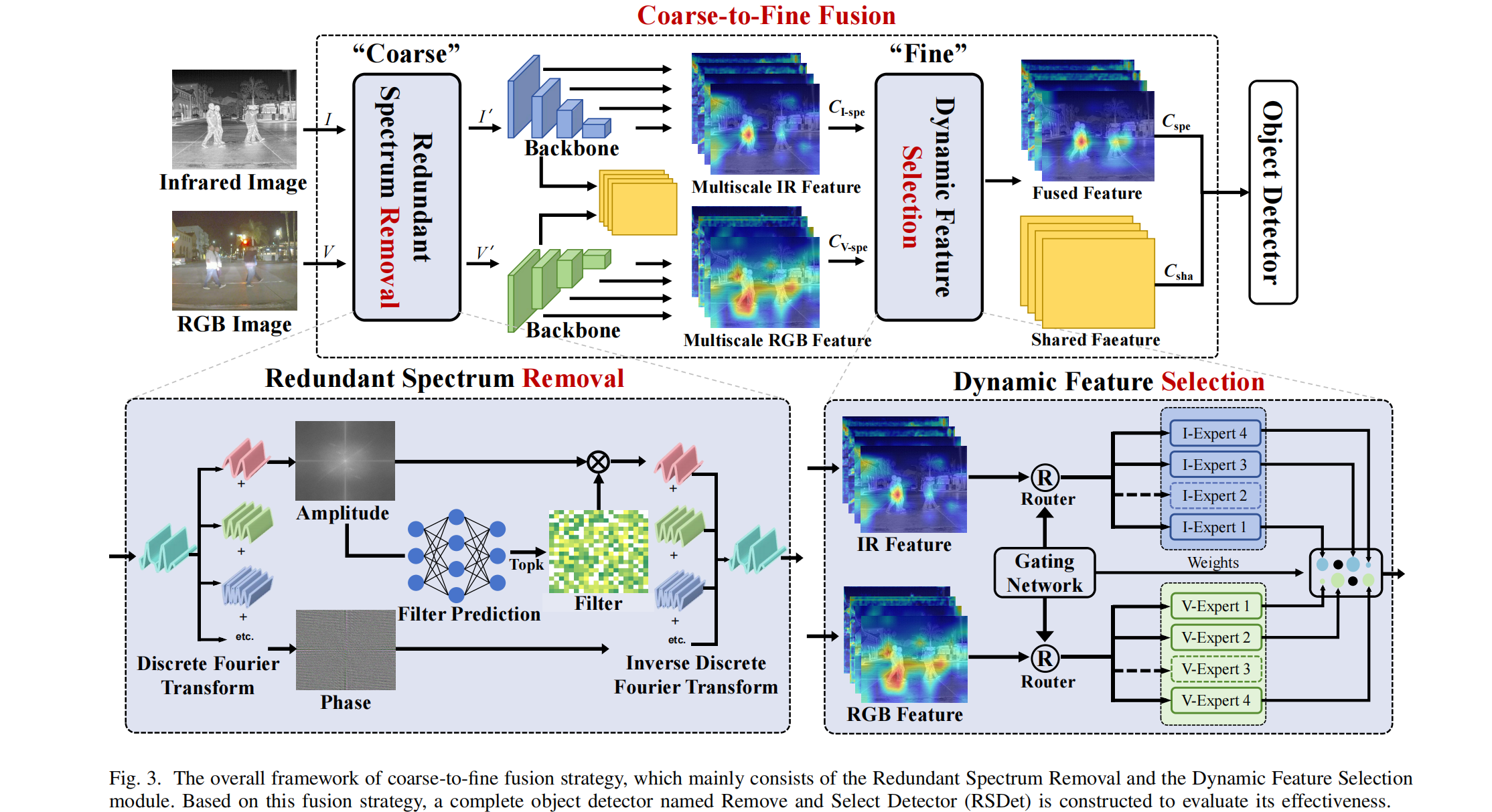
图3. 由粗到细融合策略的整体框架图,其主要由冗余光谱去除模块和动态特征选择模块组成。基于该融合策略,构建了一个完整的目标检测器——去除与选择检测器(RSDet),以评估其有效性。
如图3所示,我们将RSR和DFS模块集成到共享-特定结构中,以实现"由粗到细"融合。具体步骤如下:
- 首先,将RGB( V V V)和红外( I I I)图像分别输入RSR模块,去除干扰信息,得到剔除无关冗余光谱的图像 V ′ V' V′和 I ′ I' I′。
- 然后,引入共享-特定结构提取两种模态的特定多尺度特征 C I - s p c C_{I\text{-}spc} CI-spc和 C V - s p e c C_{V\text{-}spec} CV-spec,该结构采用ResNet作为主干网络。对于共享特征 C s h a C_{sha} Csha,我们同样使用若干ResBlock作为特征提取器。
- 随后,将这些不同尺度的特定特征 C I - s p c C_{I\text{-}spc} CI-spc和 C V - s p e C_{V\text{-}spe} CV-spe输入DFS模块,该模块通过所提出的尺度感知专家混合机制对特征进行动态聚合,得到特定特征 C s p e C_{spe} Cspe。
- 最后,将特定特征 C s p e C_{spe} Cspe与共享特征 C s h a C_{sha} Csha相加,得到最终的融合特征 C C C,其表达式为:
C = C s h a + C s p e (1) C = C_{sha} + C_{spe} \tag{1} C=Csha+Cspe(1)
2.2 冗余光谱去除模块(RSR)
对于 “粗” 处理部分,我们选择在频域对图像进行处理,这是因为频域具有固有的全局建模特性,并且仅通过逐点乘法运算即可过滤出相同的特征。由于频域具有固有的全局建模特性,且仅通过逐点乘法运算即可在全图像范围内过滤相同频段的特征,因此我们选择在频域对图像进行 “粗” 处理。然而,在空间域中难以处理目标特征的紧密耦合问题。因此,我们提出了冗余光谱去除(RSR)模块,以在频域中执行粗过滤。我们首先将每个输入图像转换到频域,然后预测一个动态滤波器,以自适应地衰减 RGB 和红外模态内的无关光谱。
具体来说,将成对的 RGB 图像 V ∈ R H × W × 3 V \in \mathbb{R}^{H \times W \times 3} V∈RH×W×3和红外图像 I ∈ R H × W × 1 I \in \mathbb{R}^{H \times W \times 1} I∈RH×W×1作为 RSR 模块的输入。对它们进行离散傅里叶变换(DFT(・)),得到频域图像 F I ( u , v ) F_{I}(u, v) FI(u,v)和 F V ( u , v ) F_{V}(u, v) FV(u,v):
F I ( u , v ) = DFT ( I ) , F V ( u , v ) = DFT ( V ) . \begin{aligned} F_{I}(u, v) &= \text{DFT}(I), \\ F_{V}(u, v) &= \text{DFT}(V). \end{aligned} FI(u,v)FV(u,v)=DFT(I),=DFT(V).
滤波器预测网络旨在基于原始图像的幅度信息 ∣ F I ( u , v ) ∣ |F_{I}(u, v)| ∣FI(u,v)∣和 ∣ F V ( u , v ) ∣ |F_{V}(u, v)| ∣FV(u,v)∣动态生成冗余光谱滤波器,如图3所示。对于每个模态的图像,我们对幅度图像执行简单的编码器操作以获得特征嵌入:
M l I = Encoder I ( ∣ F I ( u , v ) ∣ ) , M l V = Encoder V ( ∣ F V ( u , v ) ∣ ) , \begin{aligned} M_{l_{I}} &= \text{Encoder}_{I}\left(|F_{I}(u, v)|\right), \\ M_{l_{V}} &= \text{Encoder}_{V}\left(|F_{V}(u, v)|\right), \end{aligned} MlIMlV=EncoderI(∣FI(u,v)∣),=EncoderV(∣FV(u,v)∣),
嵌入向量 M l I M_{l_{I}} MlI、 M l V ∈ R m M_{l_{V}} \in \mathbb{R}^{m} MlV∈Rm的每个值表示 F I ( u , v ) F_{I}(u, v) FI(u,v)和 F V ( u , v ) F_{V}(u, v) FV(u,v)图像中不同块区域的重要性。为了在衰减无用光谱成分的同时充分保留有效成分,我们对 M l I M_{l_{I}} MlI和 M l V M_{l_{V}} MlV采用前K值操作:
M m I = top K ( M l I ) , M m V = top K ( M l V ) , \begin{aligned} M_{m_{I}} &= \text{top } K(M_{l_{I}}), \\ M_{m_{V}} &= \text{top } K(M_{l_{V}}), \end{aligned} MmIMmV=top K(MlI),=top K(MlV),
接下来,我们使用最近邻插值法对嵌入向量进行尺寸重塑,使其与原始图像尺寸匹配,从而得到滤波器 H I ( u , v ) H_{I}(u, v) HI(u,v)和 H V ( u , v ) H_{V}(u, v) HV(u,v):
H I ( u , v ) = Reshape ( M m I ) , H V ( u , v ) = Reshape ( M m V ) , \begin{aligned} H_{I}(u, v) &= \text{Reshape}\left(M_{m_{I}}\right), \\ H_{V}(u, v) &= \text{Reshape}\left(M_{m_{V}}\right), \end{aligned} HI(u,v)HV(u,v)=Reshape(MmI),=Reshape(MmV),
直观地,我们将可学习的滤波器 H I ( u , v ) H_{I}(u, v) HI(u,v)和 H V ( u , v ) H_{V}(u, v) HV(u,v)进行可视化,如图5所示。从"滤波后的幅度"中可以观察到,学习到的滤波器去除了每个模态中的一些高频噪声,这些噪声可被视为目标检测任务中的冗余信息。
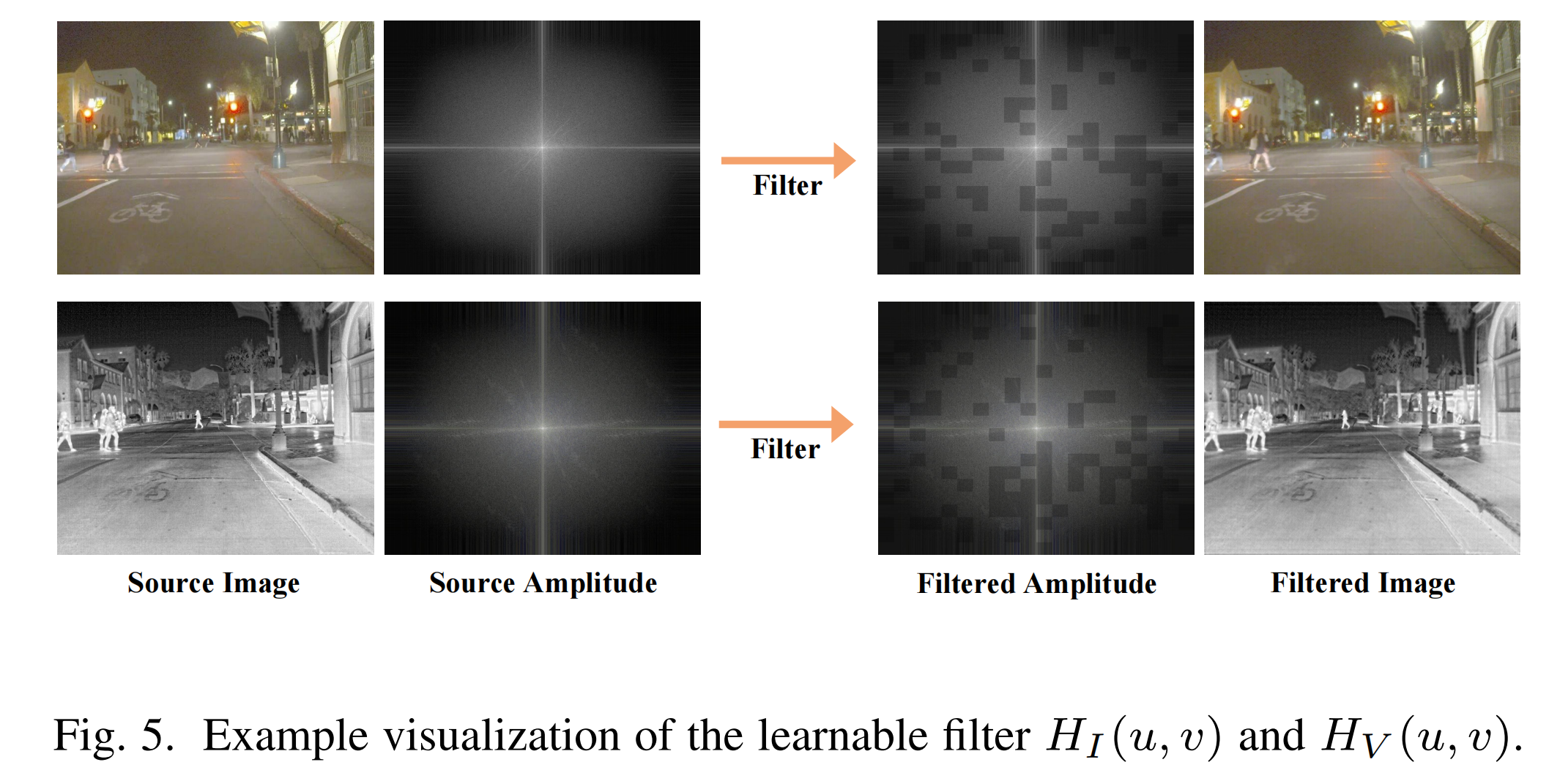
图5. 可学习滤波器(H_{I}(u, v))和(H_{V}(u, v))的可视化示例。
随后,我们将 H I ( u , v ) H_{I}(u, v) HI(u,v)和 H V ( u , v ) H_{V}(u, v) HV(u,v)与频域图像 F I ( u , v ) F_{I}(u, v) FI(u,v)和 F V ( u , v ) F_{V}(u, v) FV(u,v)进行逐元素相乘:
F I ′ ( u , v ) = F I ( u , v ) ⊗ H I ( u , v ) , F V ′ ( u , v ) = F V ( u , v ) ⊗ H V ( u , v ) . \begin{aligned} F_{I}'(u, v) &= F_{I}(u, v) \otimes H_{I}(u, v), \\ F_{V}'(u, v) &= F_{V}(u, v) \otimes H_{V}(u, v). \end{aligned} FI′(u,v)FV′(u,v)=FI(u,v)⊗HI(u,v),=FV(u,v)⊗HV(u,v).
最后,对滤波后的 F I ′ ( u , v ) F_{I}'(u, v) FI′(u,v)和 F V ′ ( u , v ) F_{V}'(u, v) FV′(u,v)进行离散傅里叶逆变换(记为IDFT(·)),将图像转换回空间域。此过程得到剔除了冗余和无关光谱的图像 I ′ I' I′和 V ′ V' V′,表达式为:
I ′ = IDFT ( F I ′ ( u , v ) ) , V ′ = IDFT ( F V ′ ( u , v ) ) (7) I' = \text{IDFT}\left(F_{I}'(u, v)\right), \quad V' = \text{IDFT}\left(F_{V}'(u, v)\right) \tag{7} I′=IDFT(FI′(u,v)),V′=IDFT(FV′(u,v))(7)
2.3 动态特征选择模块(DFS)
对于"细"处理部分,我们在融合过程中通过采用尺度感知专家混合机制实现动态模态特征选择,利用其动态融合机制对多尺度特征进行门控,以促进不同尺度间的互补融合。如图3所示,我们为每个尺度的模态特定特征设计了专用的专家模块,然后通过门控网络预测一组动态权重来聚合这些特征。具体而言,在通过对 I ′ I' I′和 V ′ V' V′进行特征提取获得不同尺度的特征 C I - s p e i C_{I\text{-}spe}^{i} CI-spei和 C V - s p c i C_{V\text{-}spc}^{i} CV-spci后,我们首先对 C I - s p e i C_{I\text{-}spe}^{i} CI-spei和 C V - s p c i C_{V\text{-}spc}^{i} CV-spci执行平均池化操作,并将其展平为一维向量 X I i ∈ R M X_{I}^{i} \in \mathbb{R}^{M} XIi∈RM和 X V i ∈ R M X_{V}^{i} \in \mathbb{R}^{M} XVi∈RM,以预测门控网络 G G G的权重 w I i w_{I}^{i} wIi和 w V i w_{V}^{i} wVi。其公式如下:
w I i , w V i = G ( X I i , X V i ) = Softmax ( [ X I i , X V i ] ⋅ W ) (8) w_{I}^{i}, w_{V}^{i} = G\left(X_{I}^{i}, X_{V}^{i}\right) = \text{Softmax}\left([X_{I}^{i}, X_{V}^{i}] \cdot W\right) \tag{8} wIi,wVi=G(XIi,XVi)=Softmax([XIi,XVi]⋅W)(8)
其中, W ∈ R M × N W \in \mathbb{R}^{M \times N} W∈RM×N是可学习的权重矩阵,通过Softmax操作进行归一化, i i i为专家索引。随后,权重 w I w_{I} wI和 w V w_{V} wV通过路由模块 R R R转换为门控信号,保留两种模态间所需的特征以进行不同尺度的融合。因此,路由模块 R R R的公式如下:
( r I i , r V i ) = R ( w I i , w V i ) = { ( 1 , 1 ) , w I i ≥ t , w V i ≥ t ( 1 , 0 ) , w I i ≥ t , w V i < t ( 0 , 1 ) , w I i < t , w V i ≥ t (9) \left(r_{I}^{i}, r_{V}^{i}\right) = R\left(w_{I}^{i}, w_{V}^{i}\right) = \begin{cases} (1,1), & w_{I}^{i} \geq t, \ w_{V}^{i} \geq t \\ (1,0), & w_{I}^{i} \geq t, \ w_{V}^{i} < t \\ (0,1), & w_{I}^{i} < t, \ w_{V}^{i} \geq t \end{cases} \tag{9} (rIi,rVi)=R(wIi,wVi)=⎩ ⎨ ⎧(1,1),(1,0),(0,1),wIi≥t, wVi≥twIi≥t, wVi<twIi<t, wVi≥t(9)
其中 t t t为阈值。然后利用 N N N个尺度感知专家网络 E I i E_{I}^{i} EIi和 E V i E_{V}^{i} EVi进一步提取模态特定特征,公式如下:
C I i = E I i ( x I i ⋅ r I i ) , C V i = E V i ( x V i ⋅ r V i ) (10) C_{I}^{i} = \mathcal{E}_{I}^{i}(x_{I}^{i} \cdot r_{I}^{i}), \quad C_{V}^{i} = \mathcal{E}_{V}^{i}(x_{V}^{i} \cdot r_{V}^{i}) \tag{10} CIi=EIi(xIi⋅rIi),CVi=EVi(xVi⋅rVi)(10)
其中 x I i x_{I}^{i} xIi和 x V i x_{V}^{i} xVi分别为不同模态输入 I ′ I' I′和 V ′ V' V′的多尺度特征。每个尺度感知专家 E \mathcal{E} E的详细结构相同,主要由两个卷积块组成。在获取不同尺度专家模型的输出结果后,我们对其进行动态加权求和并级联,得到最终的多模态特定特征 C s p e C_{spe} Cspe:
C s p e = ⋃ i = 1 n ( w I i C I i + w V i C V i ) (11) C_{spe} = \bigcup_{i=1}^{n} \left( w_{I}^{i} C_{I}^{i} + w_{V}^{i} C_{V}^{i} \right) \tag{11} Cspe=i=1⋃n(wIiCIi+wViCVi)(11)

图6. 各专家学习到的特征( C I - S p e C_{I\text{-}Spe} CI-Spe和 C V - S p e C_{V\text{-}Spe} CV-Spe)及融合特征( C S p e C_{Spe} CSpe)的可视化结果。为便于清晰观察,我们用红色方框标注目标,并将特征叠加到原始RGB或红外图像上。从左到右,特征尺度由大到小,对应物体尺寸由小到大。
为了说明DFS模块的有效性,我们对四个不同专家提取的特征进行了可视化,如图6所示。从左到右可以看出,不同的专家专注于不同尺度的物体。每个专家从两种模态特征( C I - S p e C_{I\text{-}Spe} CI-Spe和 C V - S p e C_{V\text{-}Spe} CV-Spe)中选择所需特征,使得融合后的特征 C S p e C_{Spe} CSpe在目标检测中表现出更强的显著性。可视化结果表明,该融合方法有效地整合了不同模态在不同尺度下的互补特征,形成了全面的特征表示。
2.4 去除与选择检测器(RSDet)
为了评估我们提出的由粗到细融合策略的有效性,我们将其嵌入到现有的目标检测框架中。具体来说,我们采用两阶段检测器Faster RCNN作为基线模型,并将其主干网络替换为我们的融合策略,从而构建了一个名为RSDet的新型目标检测器。其他模块(如区域建议网络(RPN)和R-CNN头部)保持不变。
损失函数。为了从经过RSR模块处理后的图像 I ′ I' I′和 V ′ V' V′中提取共享特征和特定模态特征,我们通过共享特征 C s h a C_{sha} Csha最大化 C I - s p e C_{I\text{-}spe} CI-spe与 C V - s p e C_{V\text{-}spe} CV-spe之间的互信息。互信息可作为深度监督损失函数 L I - s p e L_{I\text{-}spe} LI-spe和 L V - s p e c L_{V\text{-}spec} LV-spec,引导共享-特定特征的学习。其定义如下:
L I - s p e = MI ( C s h a , C I - s p e ) (12) \mathcal{L}_{I\text{-}spe} = \text{MI}(C_{sha}, C_{I\text{-}spe}) \tag{12} LI-spe=MI(Csha,CI-spe)(12)
L V - s p e = MI ( C s h a , C V - s p e ) (13) \mathcal{L}_{V\text{-}spe} = \text{MI}(C_{sha}, C_{V\text{-}spe}) \tag{13} LV-spe=MI(Csha,CV-spe)(13)
其中,MI表示互信息运算。我们使用交叉熵(CE)和KL散度(KL)来近似等效优化隐空间中不同特征之间的互信息:
max MI ( x , y ) ⇒ max { CE ( x , y ) − KL ( x ∥ y ) + CE ( y , x ) − KL ( y ∥ x ) } \begin{aligned} \max \text{MI}(x, y) & \Rightarrow \max \left\{ \text{CE}(x, y) - \text{KL}(x \| y) \right. \\ & \quad \left. + \text{CE}(y, x) - \text{KL}(y \| x) \right\} \end{aligned} maxMI(x,y)⇒max{CE(x,y)−KL(x∥y)+CE(y,x)−KL(y∥x)}
至于检测损失,我们采用与Faster R-CNN相同的 L r p n L_{rpn} Lrpn、 L r e g L_{reg} Lreg和 L c l s L_{cls} Lcls来监督RSDet的检测过程。总损失为这些单个损失的总和:
L = γ ( L I - s p e + L V - s p e ) + L r p n + L r e g + L c l s (15) \mathcal{L} = \gamma\left(\mathcal{L}_{I\text{-}spe} + \mathcal{L}_{V\text{-}spe}\right) + \mathcal{L}_{rpn} + \mathcal{L}_{reg} + \mathcal{L}_{cls} \tag{15} L=γ(LI-spe+LV-spe)+Lrpn+Lreg+Lcls(15)
其中, γ = 0.001 \gamma = 0.001 γ=0.001是用于平衡不同损失函数的系数。
3.实验
3.1实验设置
3.1.1数据集
-
KAIST是一个公开的多光谱行人检测数据集。由于原始数据集中存在标注问题,后续研究对训练集和测试集的标注进行了改进。我们的方法在8,963对图像对上进行训练,并在2,252对改进标注的图像对上进行评估。KAIST数据集分为不同的子集:近距、中距和远距(“尺度”);无遮挡、部分遮挡和严重遮挡(“遮挡”);白天、夜晚和全时段(“全部”和“合理”)。特别地,“全部”设置评估模型在KAIST测试数据集所有对象上的性能,而“合理”设置仅包含未/部分遮挡且尺寸大于55像素的对象。为全面评估我们方法的性能,我们在“全部”设置下进行了对比实验。
-
FLIR-aligned是一个包含白天和夜间场景的配对RGB-红外目标检测数据集。由于原始数据集中的图像存在未对齐问题,我们使用了FLIR-aligned数据集。该数据集包含5,142对对齐的RGB-红外图像对,其中4,129对用于训练,1,013对用于测试,包含三类物体:“人”、“汽车”和“自行车”。由于FLIR-aligned数据集中“狗”类别的实例极少,我们清理了标注并从数据集中移除了“狗”类别。
-
LLVIP是一个用于低光视觉的严格对齐RGB-红外目标检测数据集。它在低光环境中采集,大部分数据拍摄于极暗场景。该数据集包含15,488对对齐的RGB-红外图像,其中12,025张图像用于训练,3463张用于测试。
3.1.2评估指标
对数平均漏检率 ( M R − 2 (MR^{-2} (MR−2):对于KAIST数据集,我们采用标准的KAIST评估方法:基于每图像假阳性数(也表示为 M R − 2 MR^{-2} MR−2)的漏检率(MR)。该指标计算在对数区间内均匀采样的9个FPPI值下的平均漏检率,数值越低表明性能越好。
平均精度均值(mAP):对于FLIR和LLVIP数据集,我们采用目标检测中常用的评估指标——平均精度(AP)。正负样本需根据分类正确性和交并比(IoU)阈值进行划分。 m A P 50 mAP_{50} mAP50指标表示在IoU=0.50时的平均精度均值,而mAP指标则表示在IoU范围从0.50到0.95(步长为0.05)时的平均精度均值。
3.1.3实现细节
所有实验均在mmdetection工具箱中实现,并在NVIDIA GeForce RTX 3090上进行。我们使用Faster R-CNN作为目标检测器,主干网络为ResNet50。在训练阶段,采用随机梯度下降(SGD)优化器,动量为0.9,权重衰减为 1 × 10 − 4 1×10^{-4} 1×10−4。为方便设计DFS模块,我们调整了各数据集的输入图像分辨率,使其与LLVIP数据集的分辨率匹配。对于FLIR-align和KAIST数据集,所有实验最多训练12个 epoch,初始学习率为 1 × 10 − 2 1×10^{-2} 1×10−2;对于LLVIP数据集,初始学习率为 1 × 10 − 3 1×10^{-3} 1×10−3。在数据增强方面,我们仅使用概率为0.5的随机翻转来增加输入多样性。
3.2 消融研究
1)各组件的有效性:
为严格评估RSR和DFS模块的有效性,我们对RSDet中的每个组件进行了消融研究,并在FLIR、LLVIP和KAIST数据集上开展了一系列实验,结果如表I所示。在FLIR、LLVIP和KAIST数据集上,RSR和DFS模块各自均展现出一致的性能提升。此外,从表I中的加粗结果可以看出,同时使用RSR和DFS模块可获得更优的结果。这些结果凸显了RSR和DFS模块在增强模型检测能力方面的有效性。
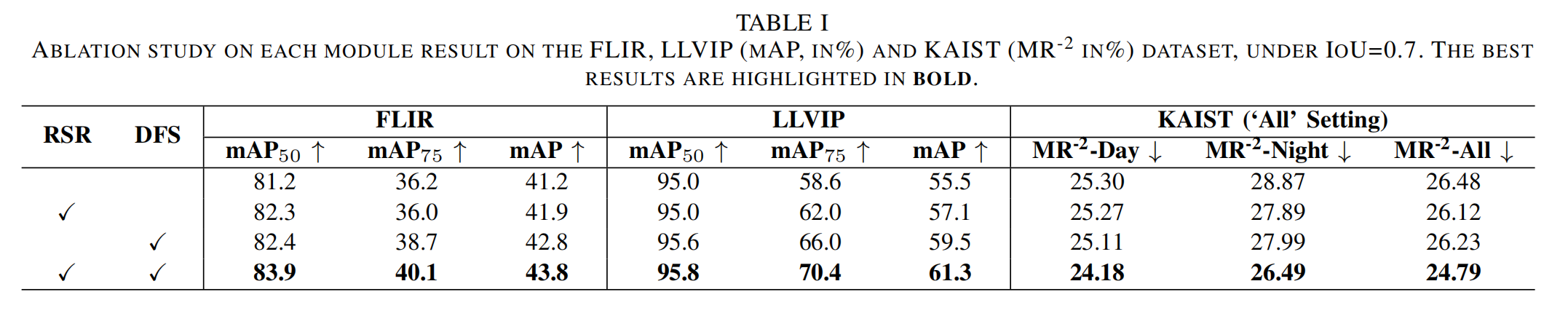
表I FLIR、LLVIP数据集上各模块消融研究结果(mAP,%)及KAIST数据集结果 ( M R − 2 (MR^{-2} (MR−2,%),在IoU=0.7条件下。最佳结果以粗体突出显示。
2)DFS模块的有效性:
为验证我们提出的DFS方法的优越性,我们将DFS模块替换为其他现有的RGB-红外融合模块。我们在统一的主干网络和检测器下进行了对比实验。具体来说,我们使用双流Faster R-CNN作为基线模型,并对RGB和红外特征应用直接特征相加的融合方法。对于其他研究中的对比融合方法,我们将特征相加操作替换为其各自的特征融合模块,并在FLIR数据集上进行了公平的实验。此外,我们还从参数数量和推理计算复杂度方面对模型进行了比较。
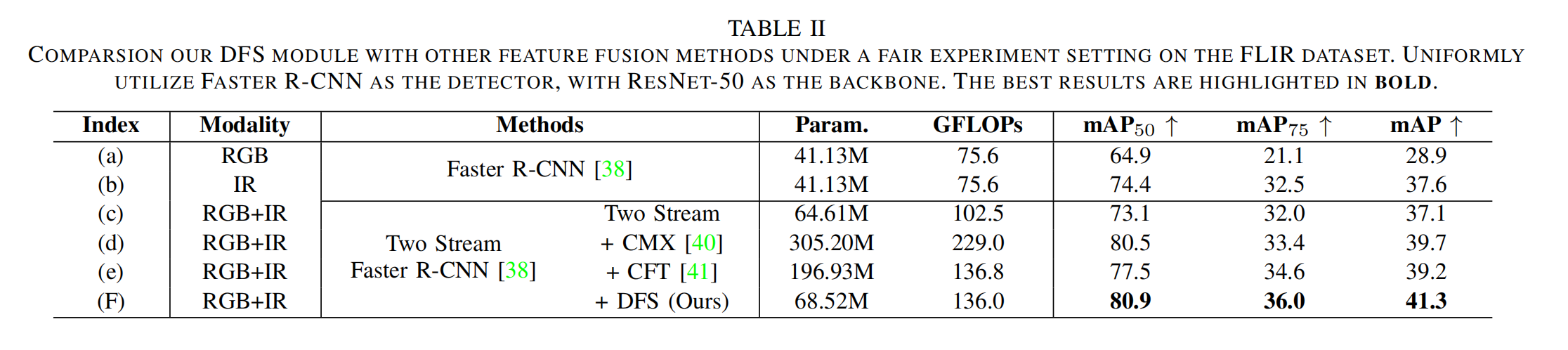
表II 在FLIR数据集公平实验设置下我们的DFS模块与其他特征融合方法的对比。统一使用Faster R-CNN作为检测器,ResNet-50作为主干网络。最佳结果以粗体突出显示。
实验结果如表II所示。与基线模型相比,我们的方法仅增加了391万个参数,但显著提升了检测性能,其中 m A P 50 mAP_{50} mAP50提高了7.8%, m A P 75 mAP_{75} mAP75提高了4.0%,mAP提高了4.2%。此外,我们的DFS模块在保持更少参数数量和计算复杂度的同时,展现出更优越的综合性能。即使参数少2.3668亿个、FLOPS少93G,我们的方法仍优于第二优的融合方法,在 m A P 50 mAP_{50} mAP50上领先0.4%,在 m A P 75 mAP_{75} mAP75上优势达2.6%,在mAP上提升1.6%,在不同的RGB-红外特征融合方法中表现最佳。
3)RSR模块内滤波器设计的对比分析:
我们进一步探究了RSR模块中不同滤波器类型设计和不同K值的影响。具体来说,若 M m I M_{m_I} MmI和 M m V M_{m_V} MmV中不对应前K个值的位置处于[0, 1]范围内,则该滤波器为软滤波器;若直接设置为0,则为硬滤波器。我们在FLIR数据集上针对不同滤波器类型,将K值从300调整至400进行了实验。需注意的是,400为图像的总补丁数,因此 K = 400 K=400 K=400表示不进行任何移除。
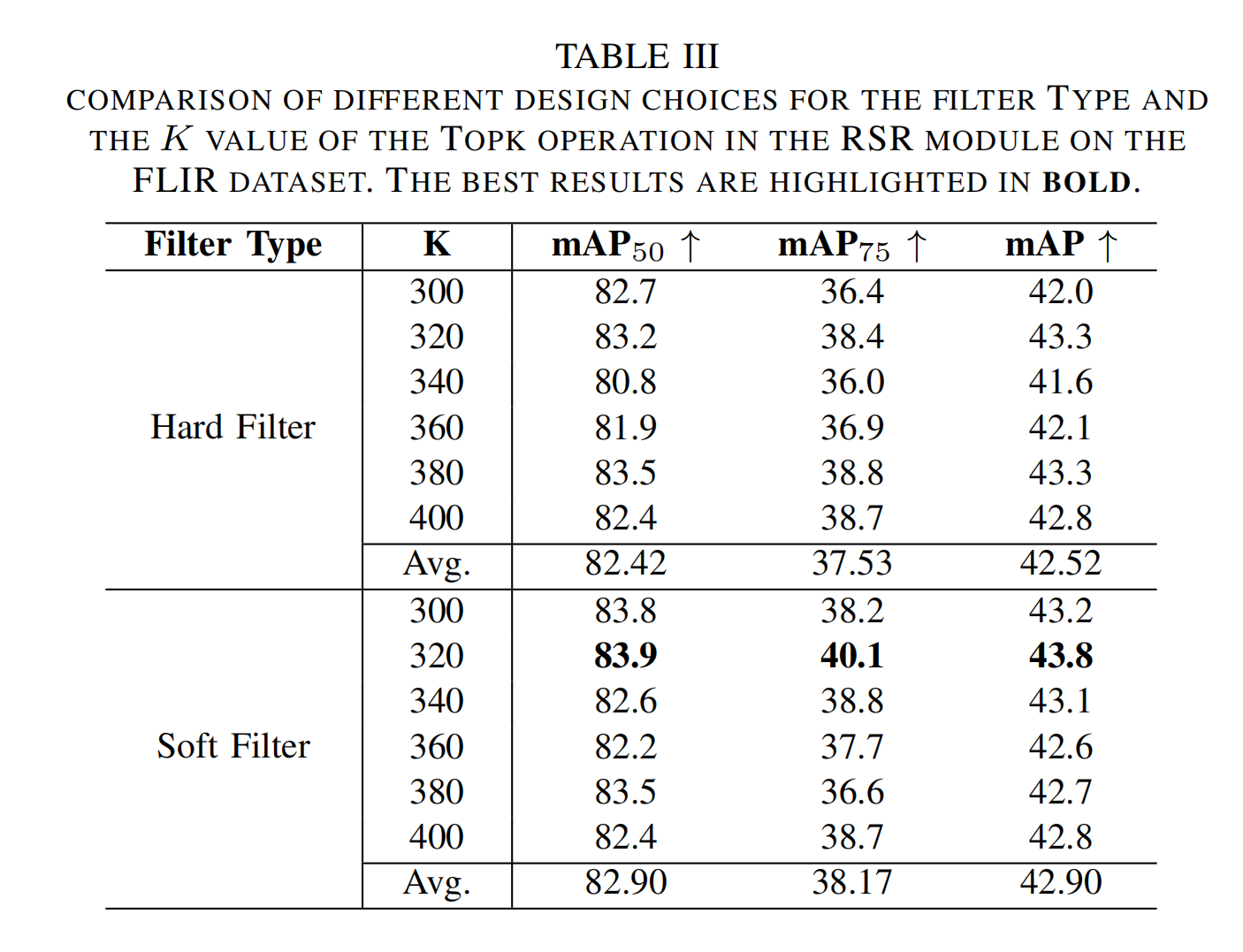
表III FLIR数据集上RSR模块中滤波器类型与TopK操作K值的不同设计选择对比。最佳结果以粗体突出显示。
如表III所示,当 K = 320 K=320 K=320时,我们的检测器使用软滤波器实现了最高检测性能。除考虑最佳性能外,我们还评估了每种滤波器类型的稳定性。为此,我们计算了每种滤波器类型在不同K值下的平均(Avg.)mAP值。从表III可知,在FLIR-aligned数据集上,软滤波器在所有指标上始终优于其他滤波器,且最佳结果也由软滤波器实现。因此,我们选择软滤波器和 K = 320 K=320 K=320作为滤波器超参数。
3.3 中间结果可视化
1)RSR模块中间结果的可视化:
为展示RSR模块的有效性,我们对中间结果进行了可视化,如图7所示。显然,目标区域在通过RSR模块处理后基本保持不变,而被滤除的信息主要集中在背景区域。这表明RSR模块能够自适应地过滤掉与检测任务无关的冗余背景噪声。为了进行更客观的比较,我们计算了信噪比(SNR)以量化差异。结果显示,原始图像通过RSR模块后信噪比略有提升,进一步证实了RSR模块的有效性。

为便于观察和比较RSR模块处理前后目标区域与背景区域的变化,对这些区域进行了放大显示。图7展示了RSR模块在FLIR(左)和LLVIP(右)数据集上的中间输出可视化结果。其中,V和I分别表示输入的RGB图像和红外图像, V ′ V' V′和 I ∗ I^{*} I∗表示经RSR模块去除无关冗余光谱后的图像。“SNR”表示信噪比,绿色边界框标注目标(前景),红色边界框标注背景(无目标类别)。
2)共享特征、特定特征与融合特征的可视化:
我们对共享特征和特定特征(分别表示为 C s h a C_{sha} Csha、 C I − s p e C_{I-spe} CI−spe和 C V − s p e c C_{V-spec} CV−spec)进行了可视化,如图8所示。在这些可视化结果中,红色框用于突出感兴趣的对象。通过观察融合过程前后的特征,我们可以清晰地看到我们方法的影响。具体而言,DFS模块增强了共享特征空间中非显著对象的可见性,将其转化为更易于区分检测的显著特征。这表明,该融合方法有效地整合了不同模态的信息,形成了更全面的特征表示。

图8. DFS模块在FLIR数据集上的特征融合结果可视化。为便于更清晰地观察,我们将特征叠加到了原始RGB或红外图像上。
3)RSR模块的tSNE可视化:
我们还对FLIR数据集上的共享特征 ( C s h a (C_{sha} (Csha)和特定特征( C I − s p e C_{I-spe} CI−spe和 C V − s p e c C_{V-spec} CV−spec)进行了tSNE可视化。如图9所示,可观察到:未使用RSR模块时,共享特征与特定特征中仍存在大量混合的特征点,导致在DFS模块中难以筛选出所需的特定特征;添加RSR模块后,混合特征的数量显著减少。这验证了去除冗余光谱有助于特征解耦,从而使DFS模块更有效地获取融合特征。

“w/o RSR”(a)和“w RSR”(b)分别表示不含和包含RSR模块。图9. 模态特定特征与共享特征的tSNE可视化。
3.4 与最先进方法的比较
1)KAIST数据集上的比较:我们将提出的RSDet与12种最先进的方法在KAIST数据集上进行了比较。表IV提供了性能对比结果,我们计算了在IoU阈值为0.5和0.7下的 M R − 2 MR^{-2} MR−2值。值得注意的是,"All"设置更具挑战性,因为它包含小尺寸(小于55像素)和严重遮挡的物体。我们的方法在"All"设置下取得了最先进的结果,这不仅表明其具有强大的整体检测性能,还证明了其在检测小尺寸和严重遮挡物体方面的有效性。
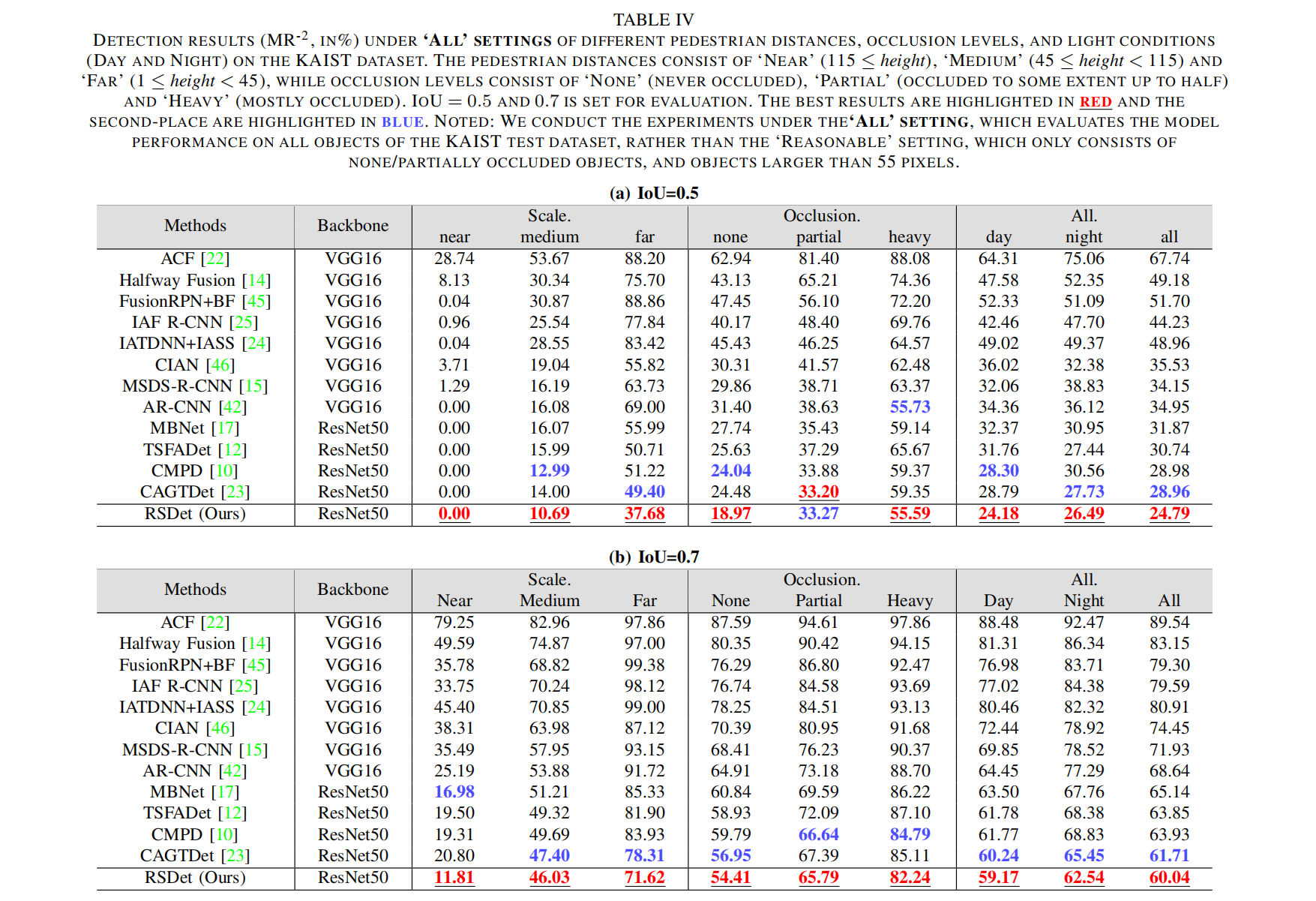
表IV KAIST数据集上“ALL”设置下不同行人距离、遮挡程度和光照条件(白天和夜晚)的检测结果((MR^{-2}),%)。行人距离包括“近”(高度≥115像素)、“中”(45像素≤高度<115像素)和“远”(1像素≤高度<45像素),遮挡程度包括“无”(从未遮挡)、“部分”(遮挡程度达一半)和“严重”(大部分遮挡)。评估时设置IoU=0.5和0.7。最佳结果用红色突出显示,次优结果用蓝色突出显示。
注:我们在“ALL”设置下进行实验,该设置评估模型在KAIST测试数据集所有目标上的性能,而非仅包含无/部分遮挡目标及大于55像素目标的“合理”设置。
当 I o U = 0.5 IoU=0.5 IoU=0.5时,根据表IV(a),RSDet表现出卓越的性能,在"ALL"设置(包括"all"、“day"和"night”)中领先,并在六个子集中的五个(near、medium、far、none、heavy)占据主导地位,仅在partial子集上排名第二。值得注意的是,RSDet在不同尺度的子集(None、Medium、Far)中表现出显著优势,尤其在Far子集中,其性能比第二优方法高出约11.72%,优势显著。我们推断,这种优越性能可归因于DFS模块中尺度感知专家的混合机制,该机制显著增强了模型对不同距离物体的感知能力。此外,在整个测试数据集(all)上,RSDet比第二优方法高出4.17%,凸显了其整体优越性。
当 I o U = 0.7 IoU=0.7 IoU=0.7时,如表IV(b)所示,RSDet在所有测试中也表现最佳。随着IoU的增加,对检测精度的要求变得更加严格。在这种情况下,我们方法的优越性更加明显。例如,在IoU提高到0.7之前,所有最新方法在’near’子集下的 M R − 2 MR^{-2} MR−2均为0。然而,这些方法的漏检率增幅在16.98%(最小值)到25.19%(最大值)之间,而我们的方法仅上升11.81%。RSDet的 M R − 2 MR^{-2} MR−2显著优于其他方法,表明我们提出的方法能产生更准确的检测结果。
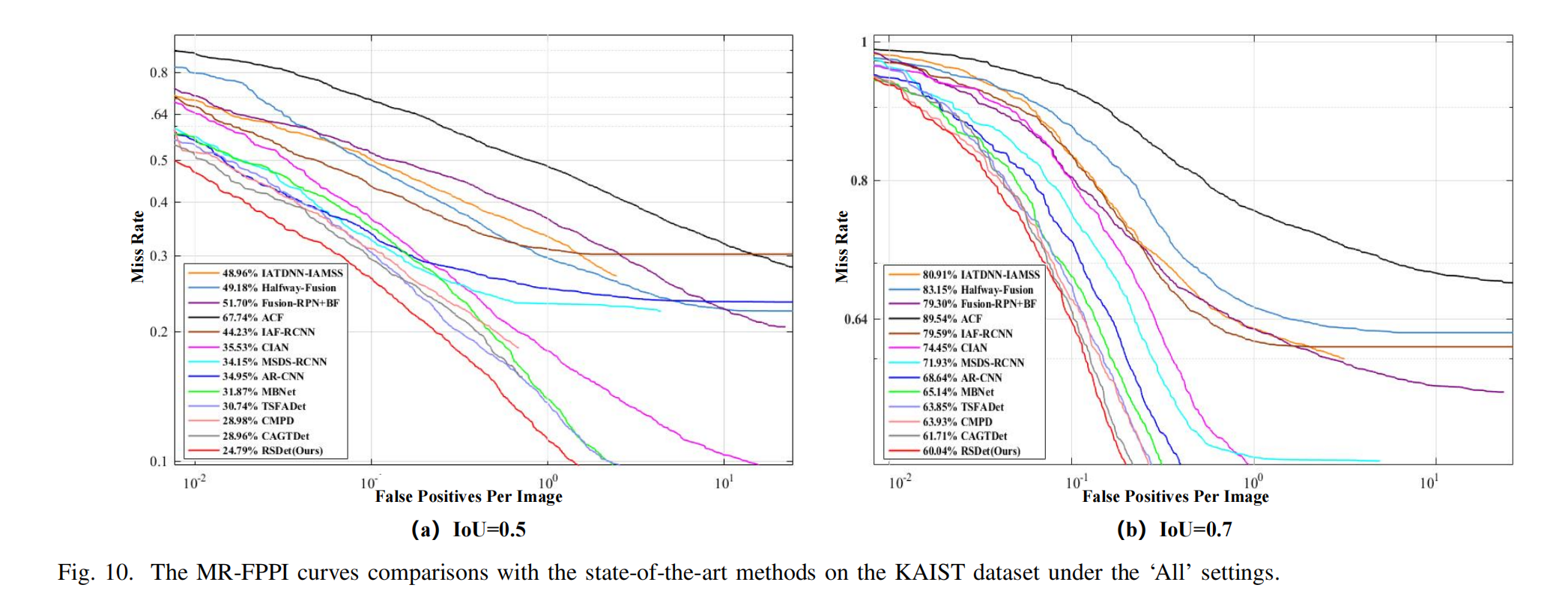
图10. 在“All”设置下,KAIST数据集上所提方法与最先进方法的MR-FPPI曲线对比。
为了进行更全面的分析,我们在图10中绘制了每图像假阳性率(FPPI)对应的对数平均漏检率曲线,该曲线凸显了我们方法的优越性,主要体现在以下几点:
- 显著的漏检率优势:RSDet在所有方法中实现了最低的漏检率,表明其即使在更严格的条件下也能更精准地识别目标。
- 出色的假阳性控制能力:RSDet即使在较低的FPPI下仍能保持显著更低的漏检率(MR),证明其在维持高检测精度的同时,能有效减少误检,提升了检测系统的可靠性。
- 平滑的曲线表现:随着FPPI的增加,RSDet的MR-FPPI曲线更为平滑,这表明其在各种条件下均能提供稳定的性能,适用于多样化的场景。
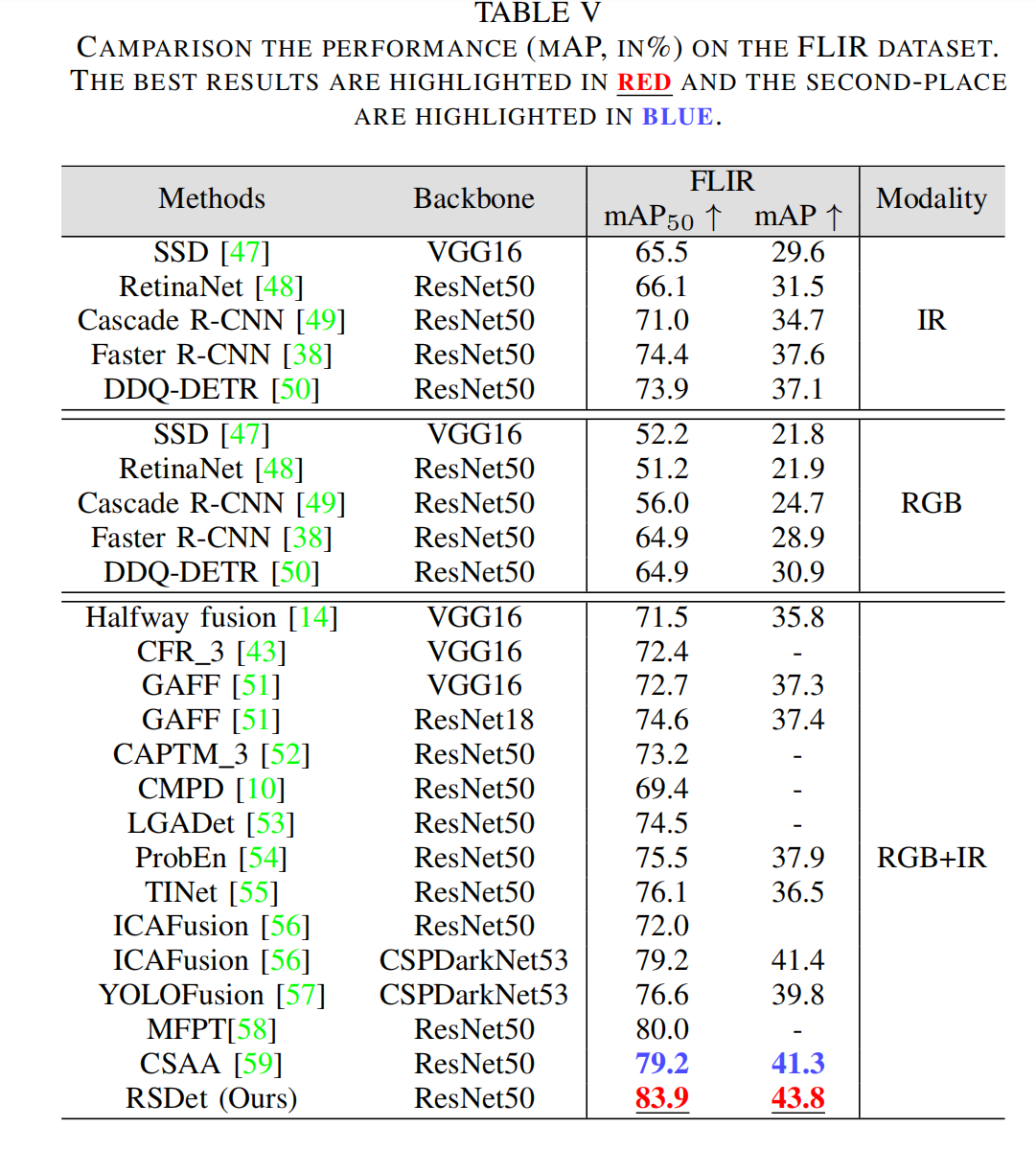
表V FLIR数据集上的性能对比(mAP,%)。最佳结果用红色突出显示,次优结果用蓝色突出显示。
2)FLIR数据集上的比较:不同方法在FLIR数据集上的定量结果如表V所示。在FLIR数据集上与12种最先进的RGB-红外目标检测方法进行了比较。从表V可以看出,融合方法在FLIR数据集上的表现普遍优于单模态方法。我们的RSDet方法也表现突出,实现了83.9%的 m A P 50 mAP_{50} mAP50和43.8%的mAP,分别显著超过第二优的RGB-红外方法4.7%和2.5%,这表明我们的方法在FLIR数据集上具有优越的性能。
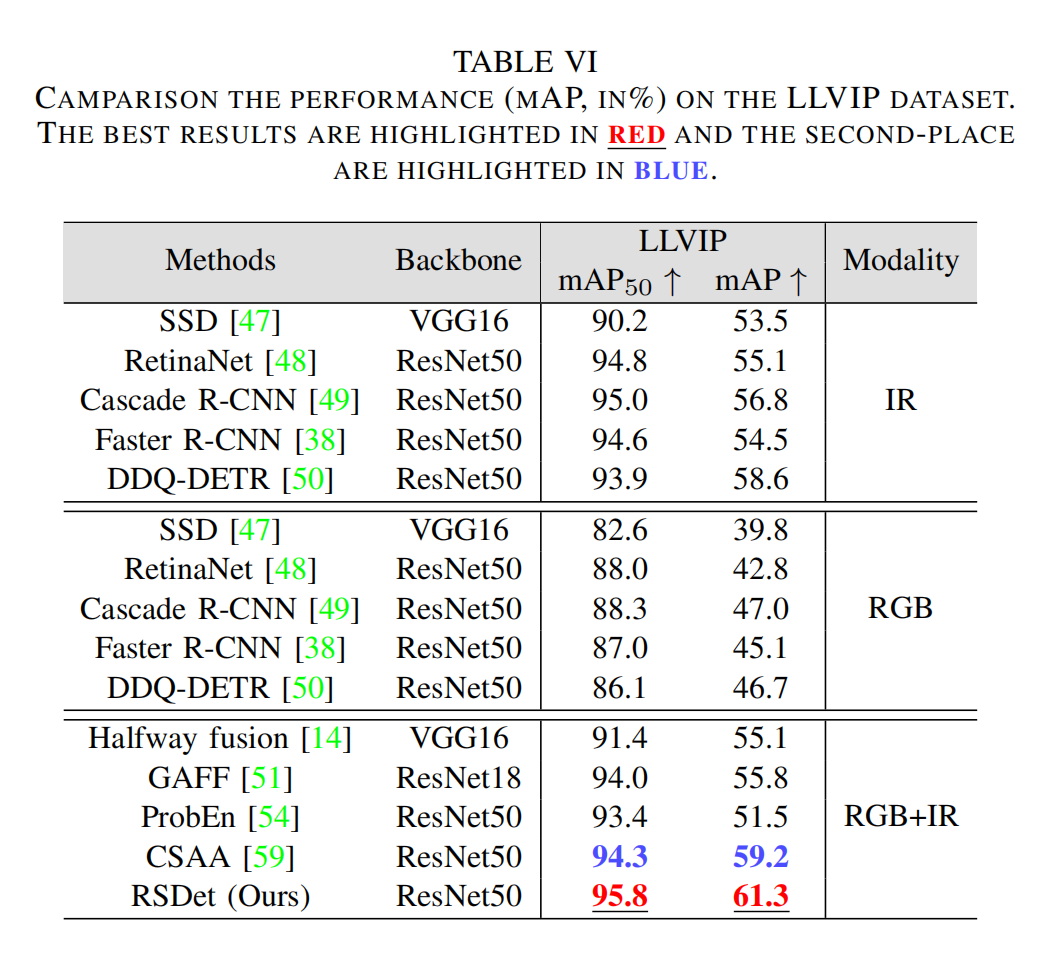
3)LLVIP数据集上的比较:不同方法在LLVIP数据集上的定量结果如表VI所示。由于LLVIP数据集最近才公开,因此在该数据集上进行实验的已发表方法相对较少。因此,我们与在FLIR对比实验中曾参与比较的四种SOTA(最先进)RGB-红外方法以及五种单模态方法进行了对比。在LLVIP数据集中,恶劣的光照条件导致RGB特征在多模态特征融合过程中对红外特征产生干扰,使得RGB-红外检测方法的检测结果始终不如单红外模态方法。我们的方法有效解决了这一问题,实现了95.8%的 m A P 50 mAP_{50} mAP50和61.3%的mAP,分别超过第二优的RGB-红外方法1.2%和2.1%。充分的对比实验验证了我们从粗到细融合策略的有效性,并在KAIST、FLIR和LLVIP数据集上均实现了最先进的性能。
表VI LLVIP数据集上的性能对比(mAP,%)。最佳结果用红色突出显示,次优结果用蓝色突出显示。
4.结论
在本文中,我们提出了一种新的从粗到细的视角来融合可见光和红外模态特征。具体而言,首先设计了冗余光谱去除(RSR)模块来粗略过滤掉无关光谱,然后提出动态特征选择(DFS)模块来精细选择所需特征,以用于RGB-红外的最终特征融合过程。我们构建了一个名为去除与选择检测器(RSDet)的新目标检测器,以评估其有效性和通用性。在三个公开的RGB-红外检测数据集上进行的大量实验表明,我们的方法能够有效促进互补融合,并实现了最先进的性能。我们相信,我们的方法可以应用于RGB-红外特征融合任务的各种研究中。