连续空间链式推理与SoftCoT++介绍
论文标题
SoftCoT++: Test-Time Scaling with Soft Chain-of-Thought Reasoning
论文地址
https://arxiv.org/pdf/2505.11484
代码地址
https://github.com/xuyige/SoftCoT
作者背景
南阳理工大学,不列颠哥伦比亚大学,阿里巴巴,瑞士皇家理工学院
动机
“思维链”通过在推理时投入更多计算开销来提升大模型的表现,但传统的CoT方法都是在离散空间(即自然语言)下进行推理扩展,开销大、速度慢(需要多次采样产生长篇幅的文本思路)。此外,语言空间也并不一定是推理的最佳载体:生成的许多词语只是确保表述连贯,并非推理本质所需
“连续空间链式推理”便是一类不再让模型解码出可读的“思路”,而是在隐空间中进行“思考”的方法
Coconut:连续空间的思维链
Coconut是在连续空间进行推理的开创性工作之一,它让LLM跳过中间的文本输出,直接利用模型最后一层的隐藏状态向量作为思维的表示。具体地,对于一个需要多步推理的问题,Coconut让模型生成第一个思考步骤的隐藏向量,不将其解码成token,而是直接将该向量反馈给模型作为下一步的输入嵌入。如此迭代,模型在内部隐空间中开展一连串推理,直到问题解决。这种方法避免了用自然语言描述思路可能带来的冗余和信息丢失
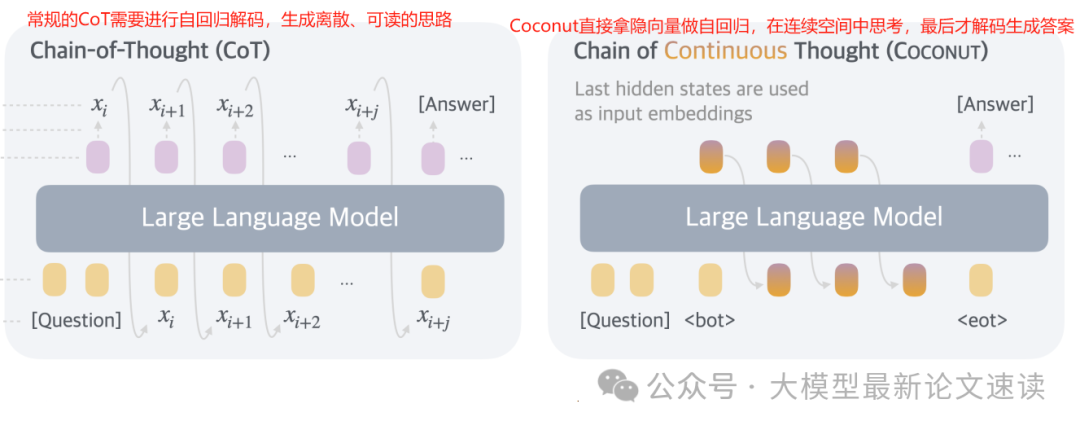
令人惊喜的是,在连续空间进行推理确实具备明显的优势:隐状态向量往往隐含了多个可能的后续推理分支,模型因此能够在内部对不同选项进行并行探索,就像在“脑海中”进行广度优先搜索一样。所以在需要大量回溯和规划的复杂逻辑任务上,Coconut 相比离散CoT 展现了更强性能,且因为省去了冗长的文本思路,推理token更少、效率更高
然而,要让大模型适应在连续空间中的推理,需要对其进行微调训练,这不仅面临着较大的计算开销,还非常容易造成灾难性遗忘。尤其是在如今模型越来越大、后训练流程越来越多的情况下,对一个已经良好掌握零样本推理的模型再进行此类训练,原本的性能难有保障

SoftCoT:软链式思维高效推理
SoftCoT 的目标是在不改动大模型主体的前提下,利用连续空间推理来提高效率和性能。与 Coconut 需要对模型本身进行重新训练不同,它引入了一个轻量级的辅助模块来生成潜在思维链。具体地,SoftCoT使用一个较小的语言模型来生成一系列隐式的思维步骤,这些步骤不是可读文字,而是一系列可学习的向量,称为软思考token或软思维嵌入;接下来,SoftCoT 通过一个可训练的投影模块,将这些软思维向量映射到大模型的表示空间,相当于在大模型的输入序列中插入了一段“隐式思路提示”;最后,大模型在自身参数不变的情况下,接收该潜在思路和原始问题一起作为输入,生成最终答案
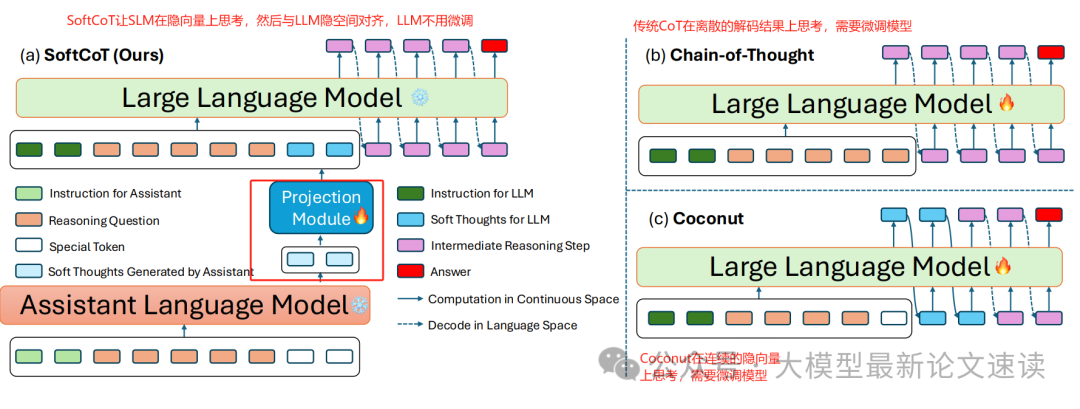
然而,SoftCoT 对于每个输入仅生成一条软链式思维路径,缺乏补救或探索其它思路的机制,回答的质量高度依赖于小模型一次性猜想的准确性,这在实践中很可能是负优化:丧失了原始的CoT本身还可以通过多次采样+多数表决提高正确率的优势
这里其实体现了在连续空间进行思考的劣势:由于缺少了token解码这一步骤,模型很难去生成截然不同的多种思路(连续空间中隐向量的生成过程是固定的)
下面将要介绍的SoftCoT++方法,便是解决了上述劣势,让模型具备了生成多样化连续空间思维链的方法
本文方法
SoftCoT++ 是对 SoftCoT 的改进,核心思想包括:
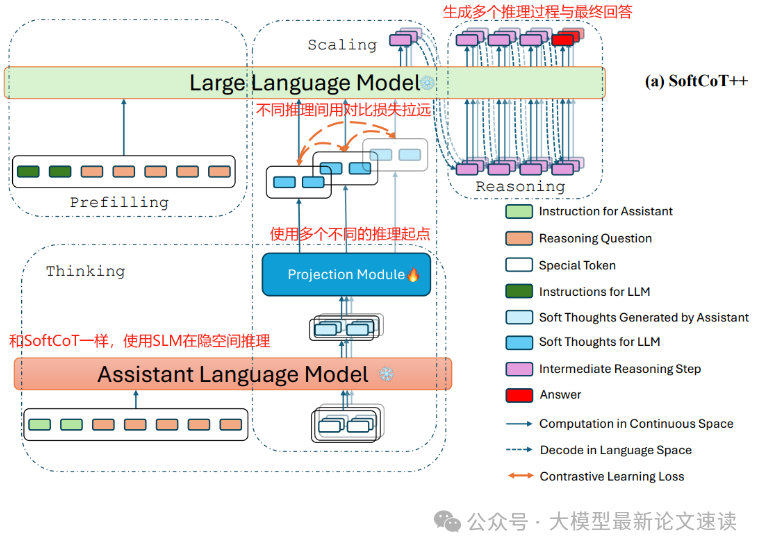
一、多样化的初始Token扰动
在辅助模型生成软思维链时,SoftCoT++ 准备了若干个特殊的“初始隐向量”。可以把它们理解为不同的“思考起手式”——每个初始向量都是可学习的参数,代表一种独特的思维模式或推理角度。对于同一道问题,SoftCoT++会分别在每个初始向量的引导下,从略有不同的起点出发思考,进而自发形成多样化的推理过程。例如,初始向量A可能引导模型优先进行算术演算,初始向量B则可能引导模型先进行逻辑排除
二、对比学习确保思维差异
为了强化不同软思维路径之间的差异性,SoftCoT++在训练过程中引入了对比学习目标:我们希望模型针对同一问题产生的不同思维表示彼此距离较远,而不是互相聚集。具体可采用 InfoNCE 损失等手段,将不同路径的隐表示视为相互的“负样本”,鼓励模型能区分“这是由初始向量A产生的思路”还是“由B产生的思路”。通过这样的训练,SoftCoT++有效地促进软思维表示的多样性——每个初始token都会开发出相对独特的推理方式,极大减少了不同路径“思维同质化”的情况
三、保持路径质量
多样性虽重要,但最终目的仍是求解正确答案。为此,SoftCoT++在训练中会对每条路径的输出进行监督学习,促使每个推理序列都能引导模型得到正确结果。这相当于给模型提出一个严格要求:不管用哪种思维起手式,都应该学会得到正确答案
四、测试时的推理扩展
在推理阶段,SoftCoT++会针对提问平行地生成多条潜在思维链,然后通过投影模块将其注入到主LLM的表示层,与问题一起构成不同的“提示”;主LLM对此进行推理,输出多个答案候选;接下来通过投票或者置信度从多个候选中决定最终结果
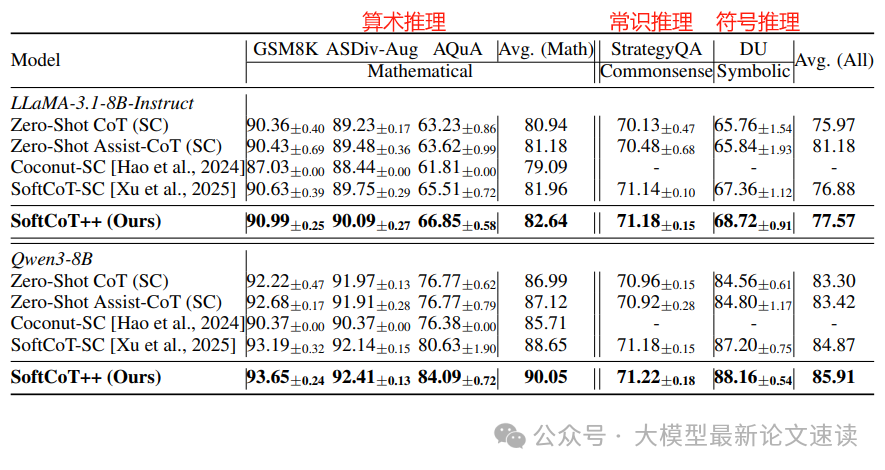
实验结果
作者在LLaMA3.1-8B和Qwen3-8B两种模型上实现了SoftCoT++,并在数学、常识、符号推理基准任务上进行测试,效果稳定提升