亿级核心表如何优雅扩展字段
1 导语
亿级数据的核心表新增一个字段,远不止一句简单的“ALTER TABLE”,锁表风险、页分裂、索引性能衰减……每一个问题都可能引发线上事故。如何在不影响业务的前提下,只需简单的配置,即可实现字段的动态扩展?本文将带你揭秘中台团队的实战解决方案。
2 背景
软件行业中,唯一不变的因素就是“变化”。一个新项目上线后,业务需要对现有功能做一些改动或升级,而实现这个功能必须要新增字段。新增字段乍一看无所谓,但如果加上一些前提条件,这张表是一张数亿级数据的表,而且是公司的核心热点表,你还能随心所欲地加么。抛开加字段过程中的锁表问题不说,后续随着字段和数据的不断增多,还会引发MySQL的页分裂、碎片化、索引性能衰减等一系列问题。
如何处理这个问题呢?我们最直接能想到的就是两种方式,扩展字段和扩展表。当然也有人可能会想到用非关系型数据库解决。而数据库选型往往是在项目初期时考虑,如果是老项目,实现起来就有不小的难度和风险,并且非关系型数据库也有自己无能为力的方面。所以其他方式我们暂且先按下不表,下面我们主要讨论怎么基于现有条件更优雅地解决这个问题。
3 扩展字段
扩展字段是最容易想到的解决方案,在表中增加一个扩展字段,以JSON格式存储数据。这也是我们之前一直采用的方式,我们的使用方式是这样的:
表结构:
| order_id | extend |
|---|---|
| 111 | {"uid":1,"name":"张三"} |
| 222 | {"uid":2,"name":"李四"} |
| ... | ... |
伪代码:
public class Order {private Long orderId;private String extend;/*** 为扩展字段extend建一个内部类*/@Datapublic static class ExtendObj implements Serializable {private Long uId;private String name;...}/*** 扩展字段的get、set方法*/public void setExtendObj(ExtendObj extendObj) {// 为展示方便,省略判空等逻辑this.extend = JSON.toJSONString(extendObj);}public ExtendObj getExtendObj() {// 为展示方便,省略判空等逻辑return JSON.parseObject(extend, ExtendObj.class);}
}
如代码所示,为了便于管理字段,我们为扩展字段创建了内部类,并实现get、set方法,以便于使用。如果你是独立部门,你的数据存储只服务于自己的系统,在表设计之初可以根据经验预留一些备用字段,再配合扩展字段,基本上可以做到很少添加字段了。但这个方案也存在一些问题:
-
不可索引。extend里的字段无法建立索引进行检索。这里有经验的读者可能会提出,MySQL 5.7.8版本支持JSON数据类型,可以为扩展字段中的某一个或一部分字段建立索引。是的没错,但如果你之前用的是更老的版本,就需要升级,MySQL版本升级也不是说升就能升的,懂的都懂,这里就不展开说了。
-
并发覆盖。当对extend并发更新的时候,会出现覆盖问题。这里我们采用了CAS更新的方式去避免,但是随着extend中的字段不断增多,冲突问题越来越频繁,CAS策略就影响到了接口成功率。
-
重复工作。每次新增字段都需要为内部类增加属性,拉分支,重新打包上线。
如果你是中台部门,除了上面的硬伤,还有一些更伤脑筋的问题在等着你:
-
数据膨胀。你不可能基于当前的扩展字段,来者不拒地存,字段总有一天会超长,就像一柄达摩克利斯之剑。当然,你拥有的剑还不止一柄,你同样需要担心字段不断膨胀之后的数据库性能。
然而你也不能来者皆拒,业务部门因为你的拒绝,需要为一两个字段去自己新建一张表存储维护,成也很高,于是你陷入了两难。 -
维护黑洞。随着业务迭代,你的维护成本会越来越高,面对几百个扩展字段,你无法快速知道这些字段具体是哪个业务、什么场景在用,当前还有没有在使用、可不可以被下掉。
4 扩展表
另一种方案是扩展表。扩展表将扩展字段中的每个字段转成一行,存储到另外一张表中:
| order_id | key | value |
|---|---|---|
| 111 | uId | 1 |
| 111 | name | 张三 |
| 222 | uId | 2 |
| 222 | name | 李四 |
如果后续新增了age属性,数据就变为:
| order_id | key | value |
|---|---|---|
| 111 | uId | 1 |
| 111 | name | 张三 |
| 222 | uId | 2 |
| 222 | name | 李四 |
| 111 | age | 26 |
| 222 | age | 38 |
扩展表解决了扩展字段无法索引的问题,由于把字段拆开了存,也很大程度上缓解了并发问题。同时,由于扩展数据不在主表存储了,也释放了主表的压力,让加字段更从容一些。但也引进来一个新问题:本来一条记录的许多属性,变成了多条记录,行数成倍增加了。为解决这个问题,我们基于主表现有的分库分表逻辑,对扩展表也进行了分库和分表。
扩展表方案貌似解决了扩展字段方案的大部分问题,可索引、没有并发覆盖问题、不影响主表性能。但还是没有解决字段维护问题,你还是不知道哪些字段场景在用什么字段,哪些字段可以下线。并且在实践中,我们还归纳出其他一些使用场景:
场景1:有些业务期望将数据存储在订单中台后,在订单的后续某个节点传递给下游服务。
场景2:有些业务期望扩展字段中的某些字段与主表上的某些字段一起进行检索。
这两个场景实现起来比较机械,我们也不希望每次都去开发。
5 现在的方案
为了满足上面两种使用场景,并且实现只需简单的配置,即可实现字段的动态扩展的愿景,最终,我们将整个系统拆分为三部分:数据管理、数据存储、数据检索。数据管理部分用于管理动态字段准入、接口透传信息、检索要求、归属以及其他基本信息,数据存储部分核心还是采用扩展表的方案,数据检索采用ES集群及自研ES管理系统ECP。
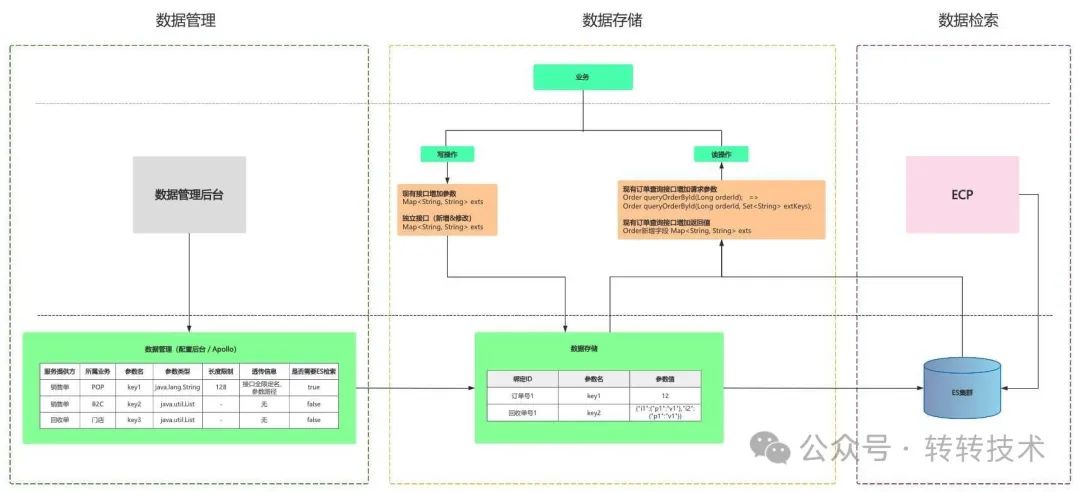
现在,我们来看看当前的系统能做什么:
-
首先,有了管理系统之后,字段的归属、作用域、场景都很清晰,不再是一个黑盒,生效状态也可以进行标记,被标记失效的字段后续就可以逐步下线。
-
对于场景1,业务可以将数据通过下单接口(或其他节点接口)传入订单系统,并保存到数据库。当订单流转到对应节点,需要调用相关接口时,会检查参数透传信息,搜集需要透传到当前接口的所有参数数据,然后根据参数路径,将之前保存的值设置到对应请求参数中透传下去。
-
对于场景2,为了规避连表查询,我们还是借助了ES,通过ES合并主表和扩展表数据进行检索。
至此,业务方再提出新增字段诉求,只需要在数据管理后台进行配置上线,使用者即可通过指定接口,或接口的指定参数将数据传入,实现数据的存储、传递、检索能力,全程无需开发介入。
6 结语
在大数据量表上的动态扩展字段,本质上是灵活性与稳定性的博弈,既要支撑业务快速迭代,又要规避“野蛮生长”的技术风险。基于分治思想,我们将核心数据与扩展数据分离;在系统设计上,对数据管理、数据存储、数据检索三部分进行解耦,把问题拆解,降低每一部分的设计难度;而在具体实践上,我们也将整个系统功能进行了封装,以便其他有同样困境的系统能够快速扩展该项能力。