百度飞桨OCR(PP-OCRv4_server_det|PP-OCRv4_server_rec_doc)文本识别-Java项目实践
什么是OCR?
OCR(Optical Character Recognition,光学字符识别)是一种通过技术手段将图像或扫描件中的文字内容转换为可编辑、可搜索的文本格式(如TXT、Word、PDF等)的技术。它广泛应用于文档数字化、信息提取、自动化处理等领域。
OCR的核心功能
-
图像转文本
将纸质文档、照片、PDF扫描件等图像中的文字提取为计算机可识别的字符。- 例如:从一张发票中提取金额、日期等信息。
-
多语言支持
支持多种语言的字符识别(如中文、英文、日文、阿拉伯语等),甚至能处理手写体、特殊符号。 -
格式保留
部分高级OCR工具可保留原文档的排版、表格结构、字体样式等。
OCR的工作原理
-
图像预处理
- 去噪、二值化、倾斜校正等,优化图像质量以提高识别准确率。
-
字符检测与分割
- 定位图像中的文字区域,并将单个字符或单词分割出来。
-
特征提取与匹配
- 通过算法(如深度学习模型)分析字符形状,与已知字符库比对,确定最可能的字符。
-
后处理与优化
- 结合上下文语义修正识别结果(如将“0”修正为字母“O”),提升文本准确性。
常见应用场景
-
文档数字化
- 将纸质书籍、合同、档案扫描为电子文本,便于存储和检索。
-
自动化办公
- 提取发票、收据、表单中的数据,自动导入数据库或财务系统。
-
移动应用
- 手机APP(如Google Keep、扫描全能王)通过拍照提取文字,支持翻译、复制粘贴。
-
车牌识别与安防
- 监控摄像头捕捉车牌信息,用于交通管理或停车场系统。
-
残障人士辅助
- 帮助视障用户通过图像识别文字,再转为语音朗读。
技术挑战与局限性
- 复杂背景干扰:如花纹背景、低对比度文字可能导致识别失败。
- 特殊字体或手写体:艺术字体、潦草手写体可能降低准确率。
- 多语言混合:不同语言字符的混合场景需要更复杂的模型支持。
- 图像质量依赖:模糊、倾斜、光照不均的图像会影响识别效果。
主流OCR工具/服务
-
商业工具
- Adobe Acrobat(PDF文字提取)、Google Drive(在线OCR)、ABBYY FineReader。
-
开源项目
- Tesseract OCR(Google开源,支持多种语言)。
- PaddleOCR(基于深度学习的高精度识别)。
-
云服务API
- Google Cloud Vision API、Amazon Textract、百度AI开放平台OCR。
未来趋势
- 深度学习优化:通过Transformer、CNN等模型提升复杂场景的识别准确率。
- 端侧部署:轻量化模型(如移动端OCR)实现实时处理。
- 多模态融合:结合语音、图像、上下文信息提升语义理解能力。
来源于qwen3
百度飞桨OCR(python)
开源地址:
https://github.com/PaddlePaddle/PaddleOCR
文档:
https://paddlepaddle.github.io/PaddleOCR/latest/index.html
文本检测+方向分类+文本识别
以cpu为例:
conda create -n py310 python=3.10 -y
conda activate py310
python -m pip install paddlepaddle==3.0.0rc1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
pip install paddleocrfrom paddleocr import PaddleOCR, draw_ocr# Paddleocr supports Chinese, English, French, German, Korean and Japanese
# You can set the parameter `lang` as `ch`, `en`, `french`, `german`, `korean`, `japan`
# to switch the language model in order
ocr = PaddleOCR(use_angle_cls=True, lang='en') # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs_en/img_12.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):res = result[idx]for line in res:print(line)# draw result
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
低代码平台:
https://github.com/PaddlePaddle/PaddleX
文档:
https://paddlepaddle.github.io/PaddleX/latest/module_usage/tutorials/ocr_modules/text_detection.html
开箱即用:
PaddleX:
conda create -n py310 python=3.10 -y
conda activate py310from paddlex import create_model
## 文本检测 PP-OCRv4_server_det
## 文本识别 PP-OCRv4_server_rec_doc# 车牌检测 : PP-YOLOE-L_vehicle
# 车辆属性检测: PP-LCNet_x1_0_vehicle_attribute
model = create_model(model_name="PP-LCNet_x1_0_vehicle_attribute")
output = model.predict(input="img/cc.jpg", batch_size=1)
# print("----",str(output))for res in output:res.print()res.save_to_img(save_path="./output/")res.save_to_json(save_path="./output/res.json")cnocr 开源项目(python)
https://github.com/breezedeus/cnocr
开箱即用:
conda create -n py310 python=3.10 -y
conda activate py310
## cpu版本
pip install cnocr[ort-cpu] -i https://mirrors.aliyun.com/pypi/simple## gpu版本
pip install cnocr[ort-gpu] -i https://mirrors.aliyun.com/pypi/simple# 简单使用
from cnocr import CnOcr
img_fp = './docs/examples/huochepiao.jpeg'
ocr = CnOcr() # 所有参数都使用默认值
out = ocr.ocr(img_fp)
print(out)## 使用百度飞桨的版本
from cnocr import CnOcr
img_fp = './docs/examples/shupai.png'
ocr = CnOcr(rec_model_name='ch_PP-OCRv4')
out = ocr.ocr(img_fp)
print(out)RapidOCR
用于PaddleOCR onnx的跨平台 (python|java|C++|C#)
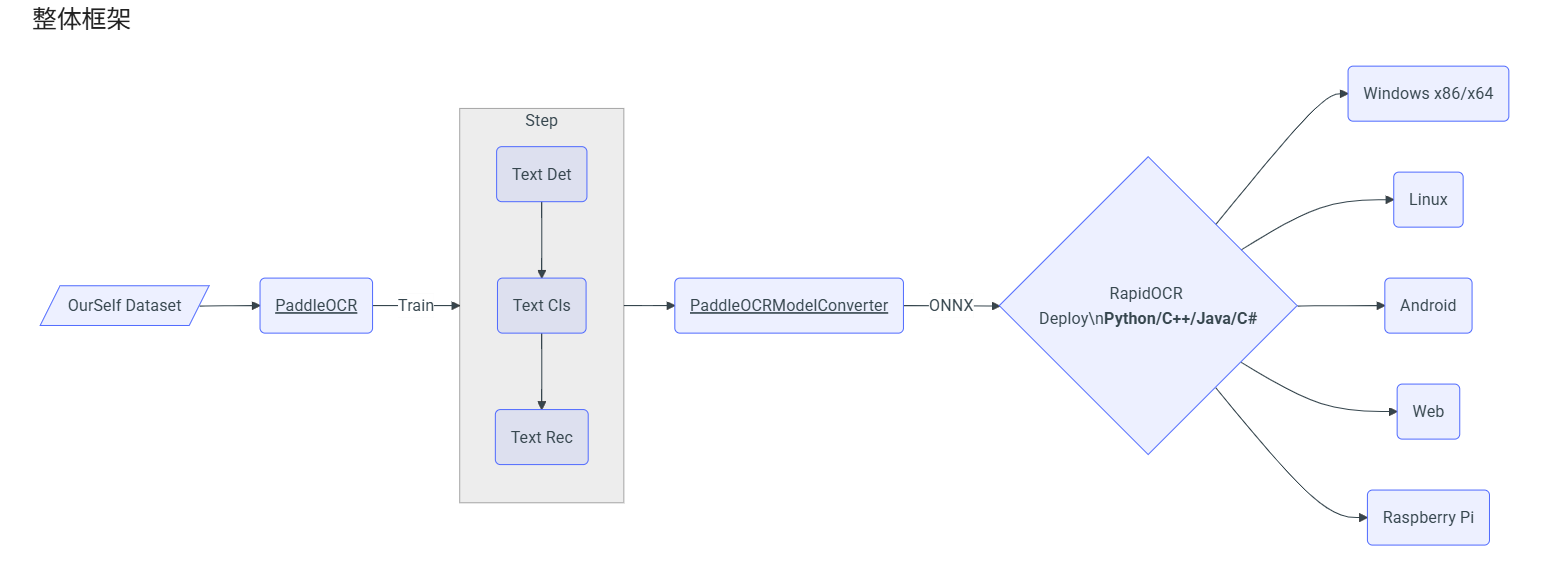
开源地址:
https://github.com/RapidAI/RapidOCR
文档:
https://rapidai.github.io/RapidOCRDocs/main/
jvm:jni 方式调用 onnx
https://github.com/RapidAI/RapidOcrOnnxJvm
https://github.com/RapidAI/RapidOcrOnnx
开箱即用
conda create -n py310 python=3.10 -y
conda activate py310pip install onnxruntime
pip install rapidocrfrom rapidocr import RapidOCR
engine = RapidOCR(params={"Global.with_torch": True})
img_url = "https://img1.baidu.com/it/u=3619974146,1266987475&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=516"
result = engine(img_url)
print(result)
result.vis("vis_result.jpg")RapidOCRJava
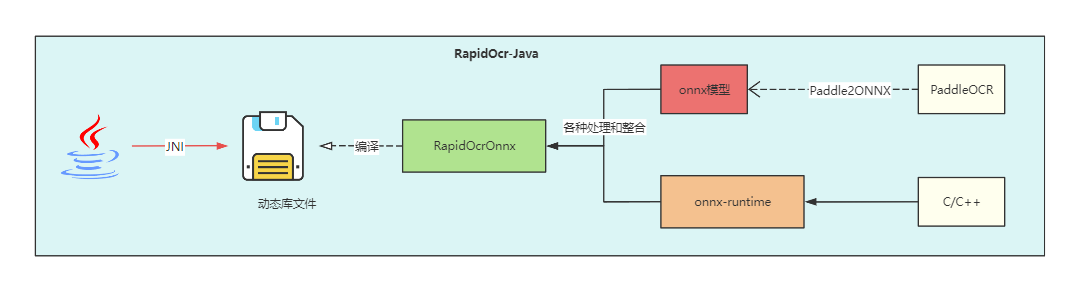
开源地址:
https://gitee.com/lc_monster/rapid-ocr-java
开箱即用:
<dependency><groupId>io.github.mymonstercat</groupId><artifactId>rapidocr-onnx-platform</artifactId><version>0.0.7</version>
</dependency><dependency><groupId>io.github.mymonstercat</groupId><artifactId>rapidocr-ncnn-platform</artifactId><version>0.0.7</version>
</dependency>public static void main(String[] args) {InferenceEngine engine = InferenceEngine.getInstance(Model.ONNX_PPOCR_V4);OcrResult ocrResult = engine.runOcr("/images/test.png");System.out.println(ocrResult.getStrRes().trim());}场景
(标准的印刷体电子文档识别和数据抽取)
一般地OCR识别底层处理
1, 文字区域识别 (det)
2,方向分类(cls)
3,文字光学识别 (rec)
PaddleOCR to onnx
## det
paddle2onnx --model_dir C:/Users/linpx/.paddlex/official_models/PP-OCRv4_server_det --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./ppocrv4_det.onnx --opset_version 11# rec
paddle2onnx --model_dir C:/Users/linpx/.paddlex/official_models/PP-OCRv4_server_rec_doc --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./ppocrv4_rec_doc.onnx --opset_version 11
项目使用
- 底层使用 PP-OCRv4_server_det + PP-OCRv4_server_rec_doc
- onnxruntime(2onnx): ppocrv4_det.onnx + ppocrv4_rec_doc.onnx
- 使用rapidOCR的跨平台的jni
- rapidOCRJava pom依赖 快速的项目集成简单ocr能力
代码部分
主要有:pdf文件转图片》图片OCR》结果重画
package app;import com.alibaba.fastjson.JSON;
import com.benjaminwan.ocrlibrary.OcrResult;
import com.benjaminwan.ocrlibrary.Point;
import com.benjaminwan.ocrlibrary.TextBlock;
import com.visual.open.anpr.core.domain.DrawImage;
import io.github.mymonstercat.Model;
import io.github.mymonstercat.ocr.InferenceEngine;
import io.github.mymonstercat.ocr.config.ParamConfig;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import nu.pattern.OpenCV;
import org.apache.commons.collections4.list.TreeList;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.*;
import java.util.List;public class RapidOCRJavaDemo {static {OpenCV.loadShared();System.out.println("Loaded OpenCV version: " + Core.VERSION);}public static void main(String[] args) throws IOException {System.out.println("----------start-----------------");String parentPath = "D:\\work\\ocr-img\\pdf";pdfToPng(parentPath);File parent = new File(parentPath,"pdf2img");File[] files = parent.listFiles();for (File file : files){runOcr(file.getAbsolutePath());}System.out.println("----------end-----------------");}private static void runOcr(String filePath) {File file = new File(filePath);File parent = file.getParentFile();new File(parent.getAbsolutePath()+"/ocr").mkdirs();ParamConfig paramConfig = ParamConfig.getDefaultConfig();// 图像外接白框,用于提升识别率,文字框没有正确框住所有文字时,增加此值。默认50。paramConfig.setPadding(50);// 按图像长边进行总体缩放,放大增加识别耗时但精度更高,缩小减小耗时但精度降低,maxSideLen为0表示不缩放paramConfig.setMaxSideLen(0);// 文字框置信度门限,文字框没有正确框住所有文字时,减小此值paramConfig.setBoxScoreThresh(0.5f);// 同上,自行试验paramConfig.setBoxThresh(0.3f);// 单个文字框大小倍率,越大时单个文字框越大paramConfig.setUnClipRatio(1.6f);// 启用(true)/禁用(false) 文字方向检测,只有图片倒置的情况下(旋转90~270度的图片),才需要启用文字方向检测,默认关闭paramConfig.setDoAngle(false);// 启用(1)/禁用(0) 角度投票(整张图片以最大可能文字方向来识别),当禁用文字方向检测时,此项也不起作用,默认关闭paramConfig.setMostAngle(false);InferenceEngine engine = InferenceEngine.getInstance(Model.ONNX_PPOCR_V4);String outFileBox = parent.getAbsolutePath()+"/ocr/result_box_"+file.getName();String outFileFill = parent.getAbsolutePath()+"/ocr/result_fill_"+file.getName();OcrResult ocrResult = engine.runOcr(filePath, paramConfig);System.out.println(JSON.toJSONString(ocrResult));
// System.out.println(ocrResult.getStrRes().trim());// 画框版本DrawImage drawBox = DrawImage.build(filePath);drawTextToImg(ocrResult.getTextBlocks(), drawBox);saveFileToDir(drawBox, outFileBox);createGrayBackgroundImage(filePath, outFileFill);// 填充文本版本DrawImage drawFill = DrawImage.build(outFileFill);drawFilledTextToImg(ocrResult.getTextBlocks(), drawFill);saveFileToDir(drawFill, outFileFill);}private static void pdfToPng(String parentPath) throws IOException {File parent = new File(parentPath);File[] files = parent.listFiles();new File(parent.getAbsolutePath()+"/pdf2img").mkdirs();for (int i = 0; i < files.length; i++) {File file = files[i];PDDocument document = PDDocument.load(file);PDFRenderer renderer = new PDFRenderer(document);String newFileName = UUID.randomUUID().toString().replace("-","");for (int j = 0; j < document.getNumberOfPages(); j++) {BufferedImage image = renderer.renderImageWithDPI(j, 300); // 300 DPIImageIO.write(image, "PNG", new File(parent.getAbsolutePath()+"/pdf2img",newFileName+"_page_" + (j + 1) + ".png"));}document.close();}}/*** 根据源图片生成一个灰色背景的新空白图片** @param sourceImagePath 源图片路径* @param outputImagePath 输出图片路径* @param grayValue 灰色值(0~255),推荐 128*/public static void createGrayBackgroundImage(String sourceImagePath, String outputImagePath) {int grayValue = 100;// 读取源图片Mat src = Imgcodecs.imread(sourceImagePath);if (src.empty()) {throw new RuntimeException("无法读取源图片: " + sourceImagePath);}// 获取源图尺寸int width = src.cols();int height = src.rows();// 创建一个与源图尺寸相同的新 Mat 对象,3 通道,8 位无符号整型Mat grayImage = new Mat(height, width, CvType.CV_8UC3, new Scalar(grayValue, grayValue, grayValue));// 释放源图资源(如果不需要后续使用)src.release();// 保存新图片boolean success = Imgcodecs.imwrite(outputImagePath, grayImage);if (!success) {throw new RuntimeException("无法保存新图片到: " + outputImagePath);}System.out.println("灰色背景图片已保存至: " + outputImagePath);// 释放新图片资源(如果不需要后续使用)grayImage.release();}private static void drawTextToImg(List<TextBlock> textBlocks, DrawImage drawImage) {for (TextBlock block : textBlocks) {List<Point> points = block.getBoxPoint();if (points == null || points.size() != 4) {continue; // 忽略无效数据}// 依次绘制四条线,形成闭合四边形for (int i = 0; i < 4; i++) {Point p1 = points.get(i);Point p2 = points.get((i + 1) % 4);drawImage.drawLine(new DrawImage.Point(p1.getX(), p1.getY()),new DrawImage.Point(p2.getX(), p2.getY()),2, Color.RED);}// 可选:绘制文本内容和置信度String displayText = String.format("%s", block.getText());// 文本位置设置在框的上方Point topLeft = points.get(0);int textX = topLeft.getX();int textY = topLeft.getY() - 25;drawImage.drawText(displayText,new DrawImage.Point(textX, textY),13,Color.GREEN);}}private static void saveFileToDir( DrawImage drawImage, String outputFilePath) {Mat outputMat = drawImage.toMat();Imgcodecs.imwrite(outputFilePath, outputMat);ByteArrayOutputStream plateStream = convertMatToStream(outputMat);saveStreamToFile(plateStream, outputFilePath);System.out.println("Saved to: " + outputFilePath);outputMat.release();}public static ByteArrayOutputStream convertMatToStream(Mat image) {MatOfByte matOfByte = new MatOfByte();Imgcodecs.imencode(".jpg", image, matOfByte); // 将 Mat 编码成 JPG 格式ByteArrayOutputStream outputStream = new ByteArrayOutputStream();try {outputStream.write(matOfByte.toArray()); // 写入字节流} catch (IOException e) {throw new RuntimeException("Error converting Mat to stream", e);}image.release();return outputStream;}public static void saveStreamToFile(ByteArrayOutputStream stream, String filePath) {try (FileOutputStream fileOutputStream = new FileOutputStream(filePath)) {stream.writeTo(fileOutputStream); // 将流写入文件} catch (IOException e) {throw new RuntimeException("Error writing stream to file", e);}}@Data@AllArgsConstructor@NoArgsConstructor@Builderstatic class OcrTextDTO{private String text;private int x1;private int x2;private int y1;private int y2;}private static void drawFilledTextToImg(List<TextBlock> textBlocks, DrawImage drawImage) {// System.out.println("textBlocks sort pre:"+JSON.toJSONString(textBlocks));Map<String,List<OcrTextDTO>> tableGroup = new LinkedHashMap<>();int currentY = 0;textBlocks.sort(Comparator.comparingInt(o ->o.getBoxPoint().stream().mapToInt(Point::getY).min().orElse(Integer.MAX_VALUE)));
// System.out.println("textBlocks sort end:"+JSON.toJSONString(textBlocks));for (TextBlock block : textBlocks) {List<Point> points = block.getBoxPoint();if (points == null || points.size() != 4) {continue; // 忽略无效数据}int minY = Integer.MAX_VALUE;int maxY = Integer.MIN_VALUE;int minX = Integer.MAX_VALUE;int maxX = Integer.MIN_VALUE;System.out.println("points:"+JSON.toJSONString(points));// [{"x":1022,"y":971},{"x":1116,"y":971},{"x":1116,"y":1000},{"x":1022,"y":1000}]// 依次绘制四条线,形成闭合四边形for (int i = 0; i < 4; i++) {Point p1 = points.get(i);Point p2 = points.get((i + 1) % 4);drawImage.drawLine(new DrawImage.Point(p1.getX(), p1.getY()),new DrawImage.Point(p2.getX(), p2.getY()),2, Color.RED);minY = Math.min(minY, p1.getY());maxY = Math.max(maxY, p1.getY());minX = Math.min(minX, p1.getX());maxX = Math.max(maxX, p1.getX());}int height = maxY - minY;// 可选:绘制文本内容和置信度String displayText = String.format("%s", block.getText());// 文本位置设置在框的上方Point topLeft = points.get(0);int textX = topLeft.getX();int textY = topLeft.getY();
// System.out.println("maxY:"+maxY+",minY:"+minY+",height:"+height);
// System.out.println("currentY:"+currentY+",minY-currentY:"+(minY-currentY)+",minY:"+minY);if(currentY == 0){currentY = minY;}else {if(minY-currentY > 18){currentY = minY;}}
// System.out.println("----currentY:"+currentY+",minY:"+minY+",height:"+height);List<OcrTextDTO> orDefault = tableGroup.getOrDefault(currentY+"", new TreeList<>());orDefault.add(OcrTextDTO.builder().text(displayText).x1(minX).y1(minY).x2(maxX).y2(maxY).build());orDefault.sort(Comparator.comparingInt(OcrTextDTO::getX1));tableGroup.put(currentY+"",orDefault);
// System.out.println("textY:"+textY+",height:"+height+",text:"+displayText);int fontSize;if (height > 40) {fontSize = (int) (height * 0.6);} else if (height > 25) {fontSize = (int) (height * 0.7);} else if (height > 15) {fontSize = (int) (height * 0.8);}else {fontSize = height;}drawImage.drawText(displayText,new DrawImage.Point(textX, textY),fontSize,Color.GREEN);}System.out.println(JSON.toJSONString(tableGroup));}
}扩展
在java平台可以直接使用 onnxrunntime来进行解析,不使用 jni的方式
免责声明:样例仅供参考,如有错误还请纠正!谢谢