代码讲解系列-CV(三)——Transformer系列
文章目录
- 一、Transformer结构解析
- 二、ViT图像分类
- 2.1 patch_embedding
- 2.2 cls token
- 2.3 Position Embedding
- 2.4 encoder
- 2.5 Architecture
- 2.6 Transformer Block
- 2.7 Attention Block
- 三、注意力的可视化
- 四、爱因斯坦标示法
- 4.1 Einops
- 五、作业
一、Transformer结构解析
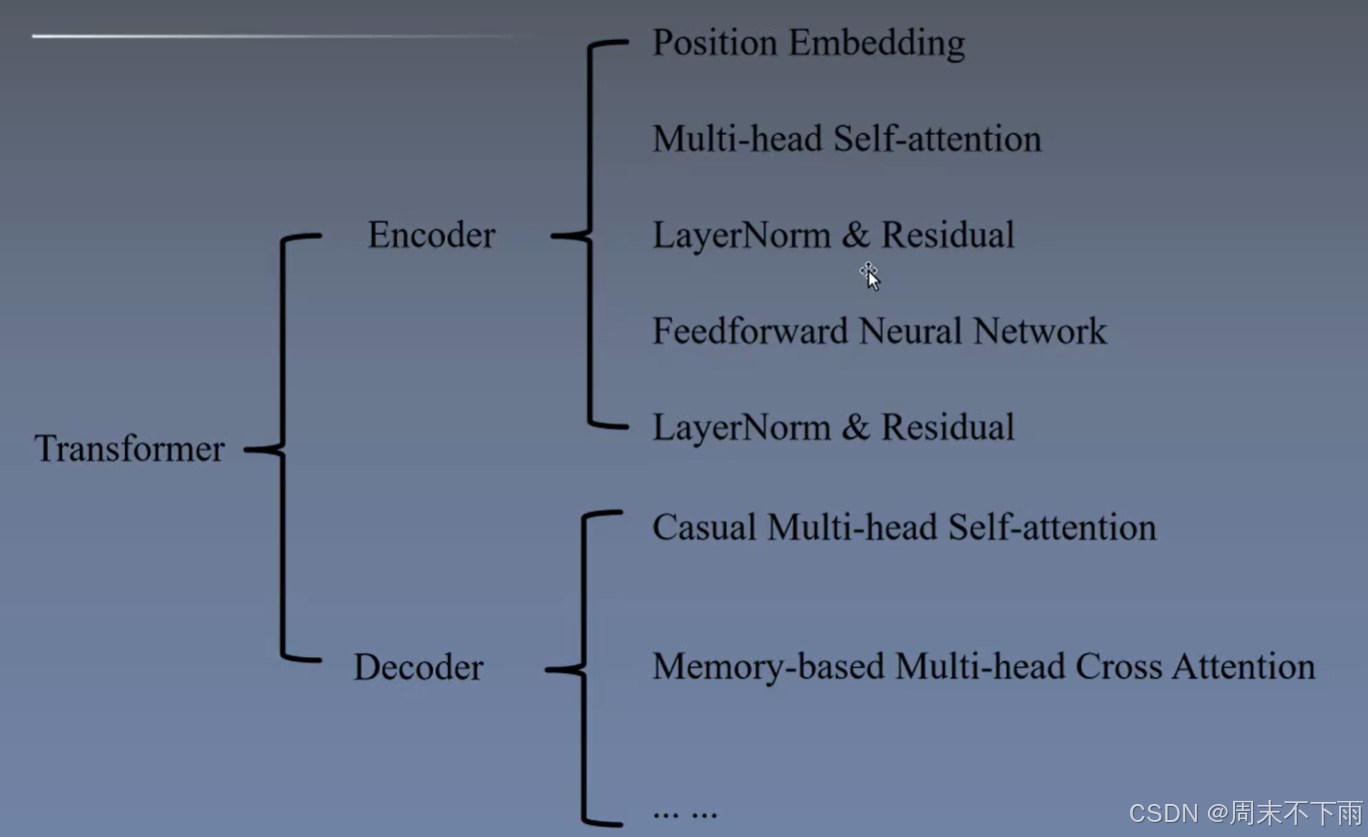
对于encoder中就是首先标定位置、多头自注意力、归一化、激活函数、FFN-全链接层-MLP
decoder:不做过多说明
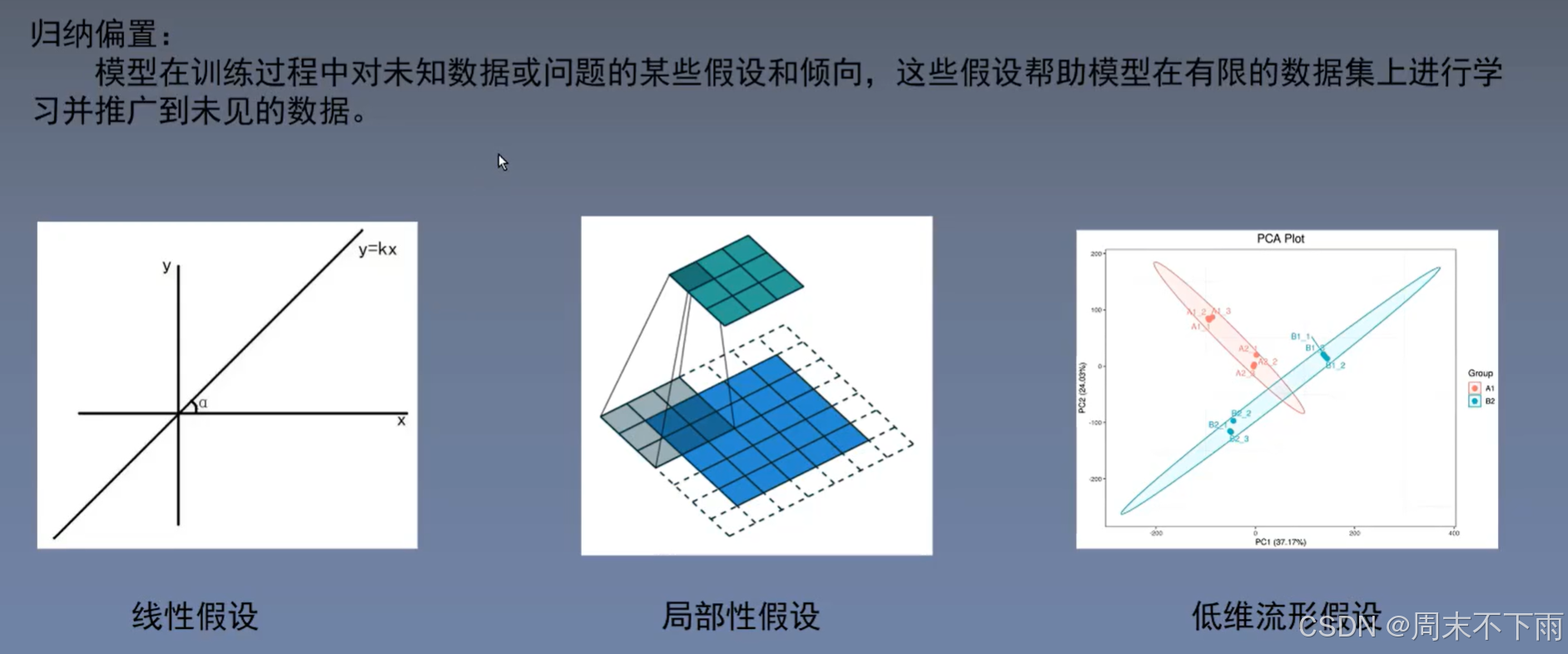
CNN和Transformer,如果选择Transformer的原因就是学习能力更强,但是参数量更大,需要的数据也更多。PCA就是降维
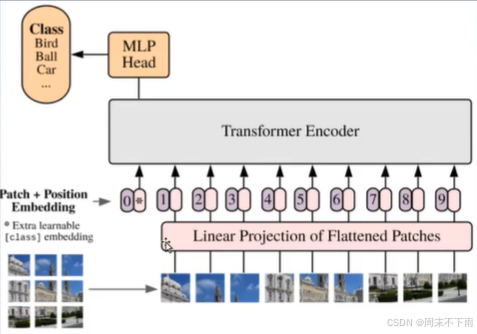
二、ViT图像分类
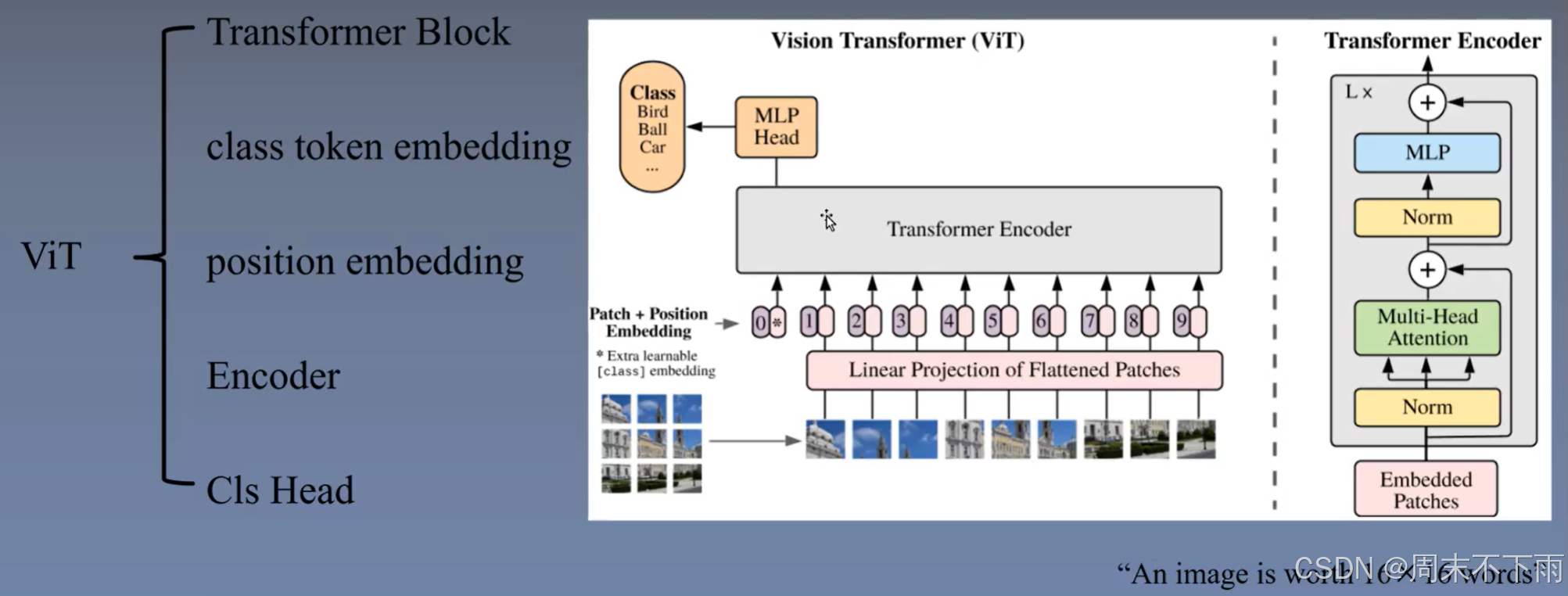
embedding和NLP里面的token是一样的。都是打散之后进行重新训练。
首先确定class token设置为头,之后就是加上patch的位置嵌入
2.1 patch_embedding

就是进行裁剪

之后就是从768(16163)降维到128
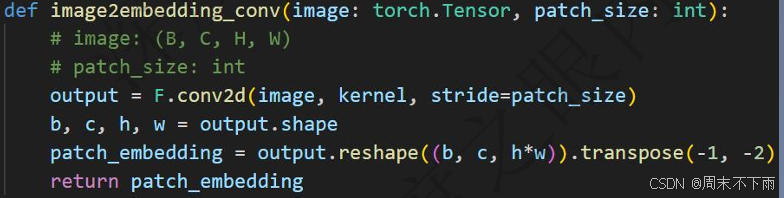
上下两个做的是同一件事情(卷积操作是可以代替embedding)
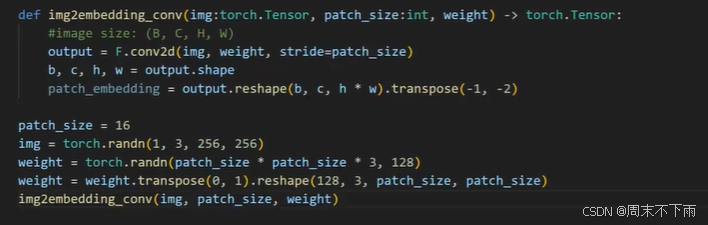
输出都是[1,256,128]:256是token的训练的长度,128就是特征长度
在256上添加1个维度(添加头)变成257
2.2 cls token

1,1,128,True(梯度打开)
cat就是拼接
2.3 Position Embedding
加入头之后,就是把位置进行嵌入

model_dim就是模型的维度,这里为128
2.4 encoder
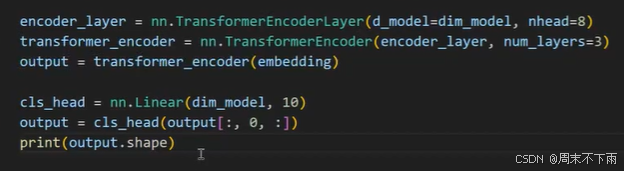
多头注意力,这里设置头为8,也就是128个维度,平均分配给这8个头
定义3个层,即会经过3此encoder_layer
下面的10,就是分类成10个,这10个也就是概率,之后选取概率的最大的分类
2.5 Architecture
定义模型
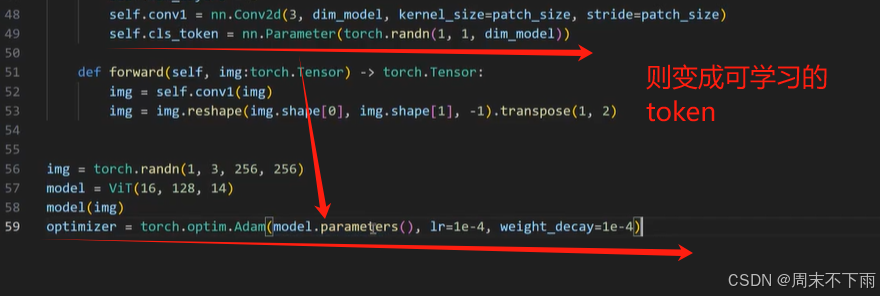
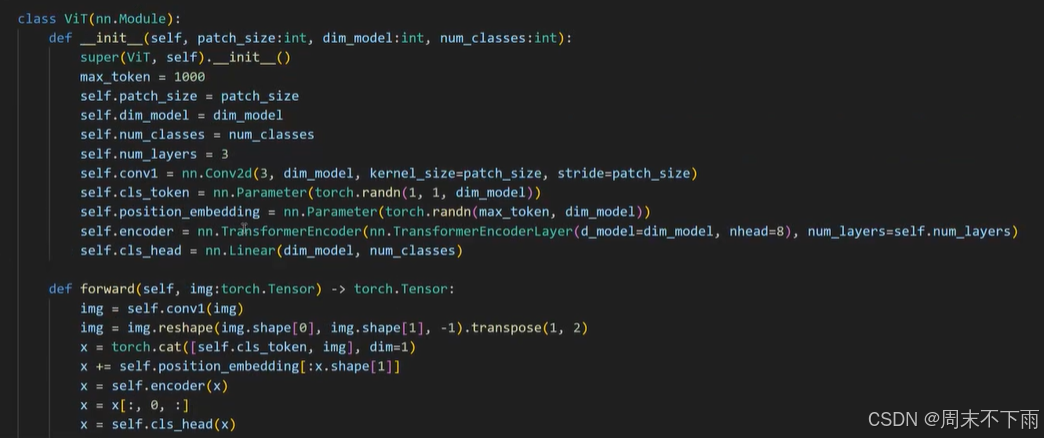
2.6 Transformer Block
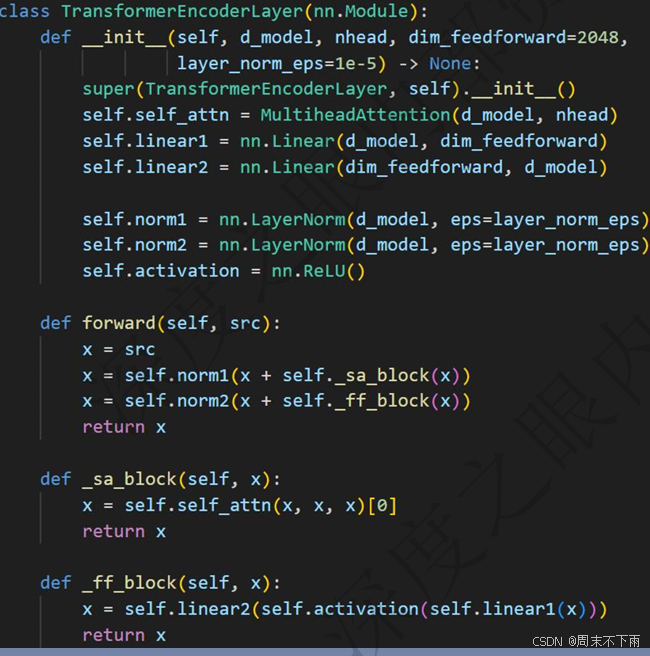
layer的核心组件就是attention
之后就是定义两个线性层,也就是FNN,原理是先膨胀再收缩
之后就是归一化层还有就是残差的设计
每次调用线性层之后都需要使用一次激活函数,之后再进行下一次的线性层
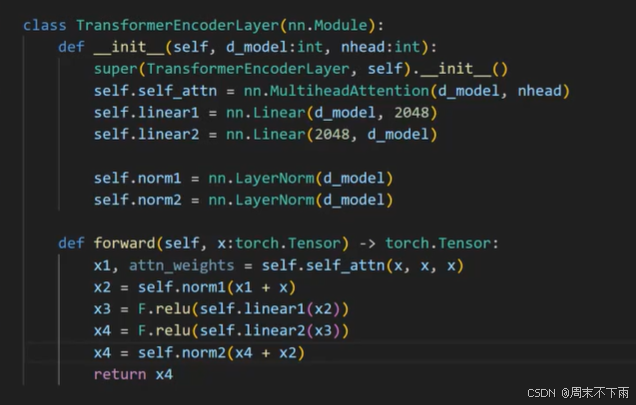
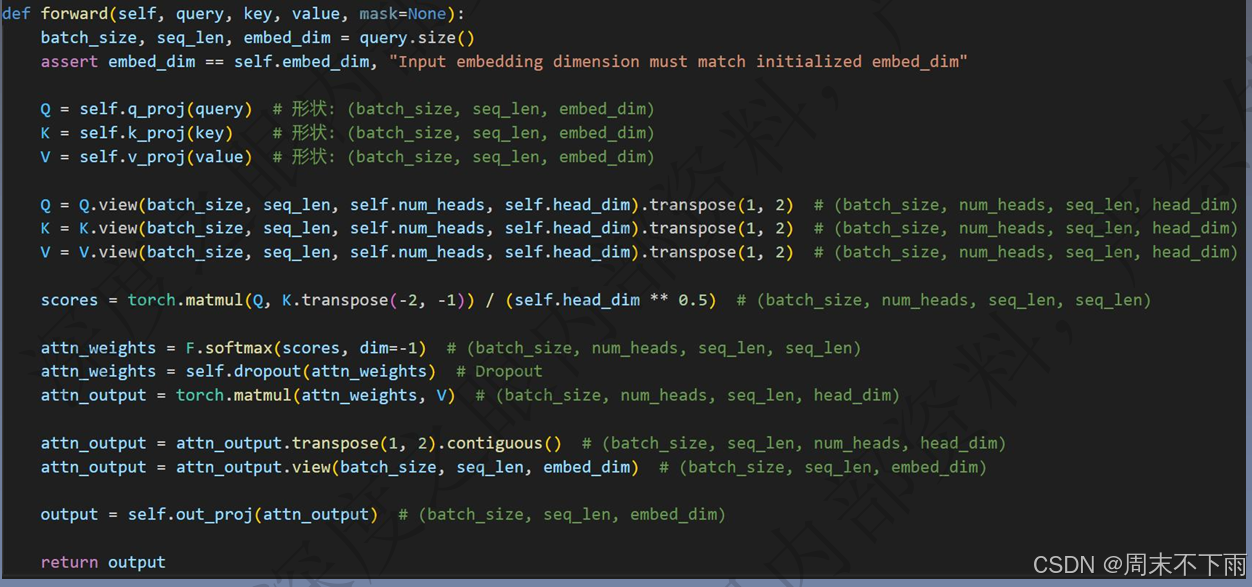
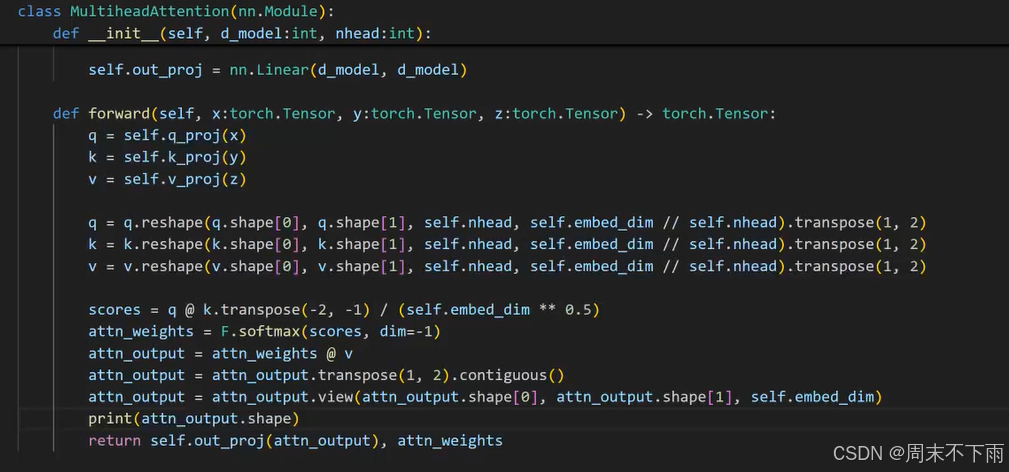
多头注意力
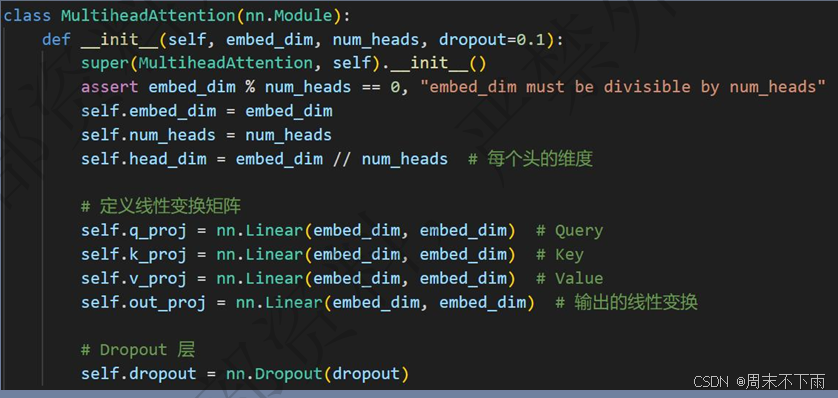
关于这个自注意力中,q,k,v是三个部分
在自注意力机制中,Q(Query)、K(Key)和V(Value)是核心组成部分,它们共同工作以实现对序列中信息的动态聚焦。
Query向量代表当前正在处理的token或位置,它表示模型需要“查询”的信息。在自注意力机制中,Query用于与所有的Key进行比较,以确定每个Key与当前token的相关性。这个比较的结果决定了Value的加权和,从而生成当前token的输出。
Key向量代表序列中每个token的唯一标识,用于与Query进行比较。Key向量用于计算与Query的相似度或匹配程度,这个相似度得分决定了相应Value在最终输出中的权重。
Value向量包含序列中每个token的实际内容或特征,它对生成当前token的输出有贡献。Value向量根据与Query的相似度得分(由Key确定)被加权求和,生成当前token的输出。
在自回归推理过程中,模型一次生成一个token,并且每个新token都会基于之前所有token的信息。因此,对于每个新生成的token,Q需要重新计算,因为它依赖于当前token的信息,而K和V可以被缓存(即KV Cache),因为它们代表之前已经生成的token的信息,这些信息在生成后续token时不需要重新计算。Q代表了当前token的查询需求,而K和V则提供了序列中每个token的标识和内容,使得模型能够根据当前token的需求加权组合之前的信息,生成连贯和相关的输出。
q*k 做一个softmax拿到注意力分数,把token之间的分数,都乘以v,就得到缓和之后的token
2.7 Attention Block
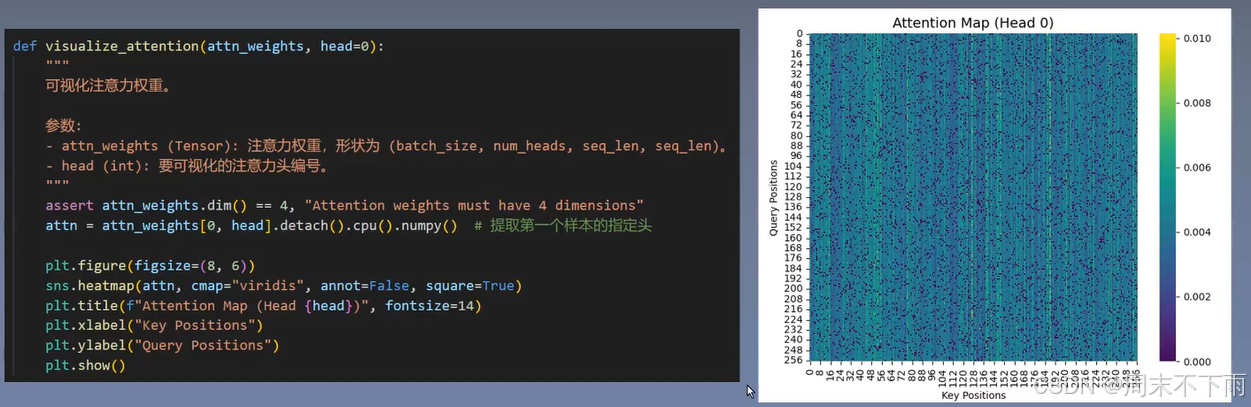
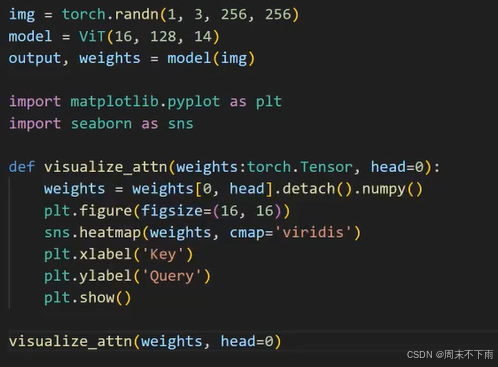
三、注意力的可视化

四、爱因斯坦标示法
4.1 Einops

重排用的多

五、作业
