计算机网络概要
⽹络相关基础知识
协议
两设备之间使⽤光电信号传输信息数据
要想传递不同信息 那么⼆者ᳵ就需要约定好的数据格式
层
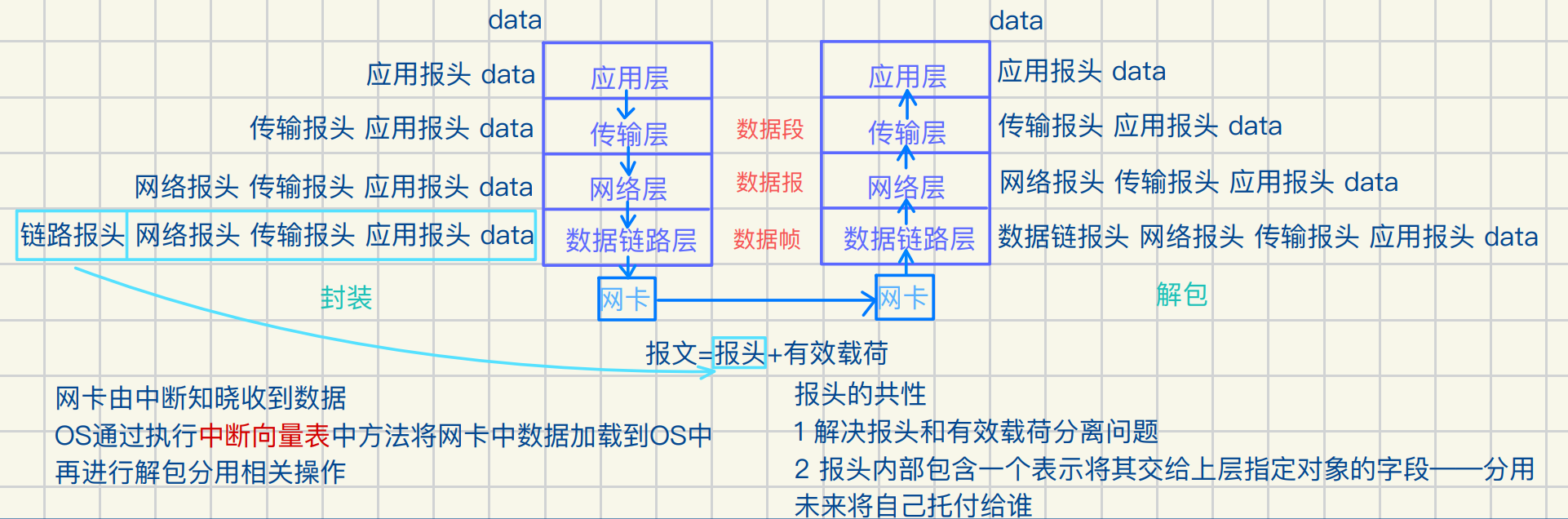
封装 继承 多态是计算机的性质 它们⽀持了软硬件分层的实现
同层协议可以ᳵ接通信
同层协议ᳵ不直接通信 是各⾃调⽤下层提供的结构能⼒完成通信
分层是解耦的有效⽅式 提⾼了软件的可维护性
⼀段优秀的代码是⾼内聚(class) 低耦合的
OSI(Open System Interconnection) 开放系统互联 七层模型
物理层 数据链路层 ⽹络层 传输层 会话层 表示层 应⽤层
严格来说只实现了2 3 4 7层
因为标准定制者和标准实现者是两码事
TCP/IP协议簇
存在意义 IP地址是⽹络中计某主机唯⼀标识符
计算机F诺伊曼体结构就是⼀个⽹络 只不过是距离问题
TCP/IP是为了给计算机之ᳵ的通信距离问题提供⽅案
通信是⼿段
⽹络和OS之间的关系
即使两台电脑ᳵOS不同 只要⼆者⽹络协议栈相同
它们便可以通信 所以传输层和⽹络层⼀定相同
⽹络层IP和传输层TCP⼀定在OS内核中实现
应⽤层在⽤户层实现 数据᱾路层属于驱动层
所以⽹络是OS的⼀个模块
OS存在⼤协议并以先描述 再组织的⽅式管理 所以协议就是结构体
不同机器需要通信那么协议结构体⽹络代码相同
协议就是双⽅共识的结构化数据类型
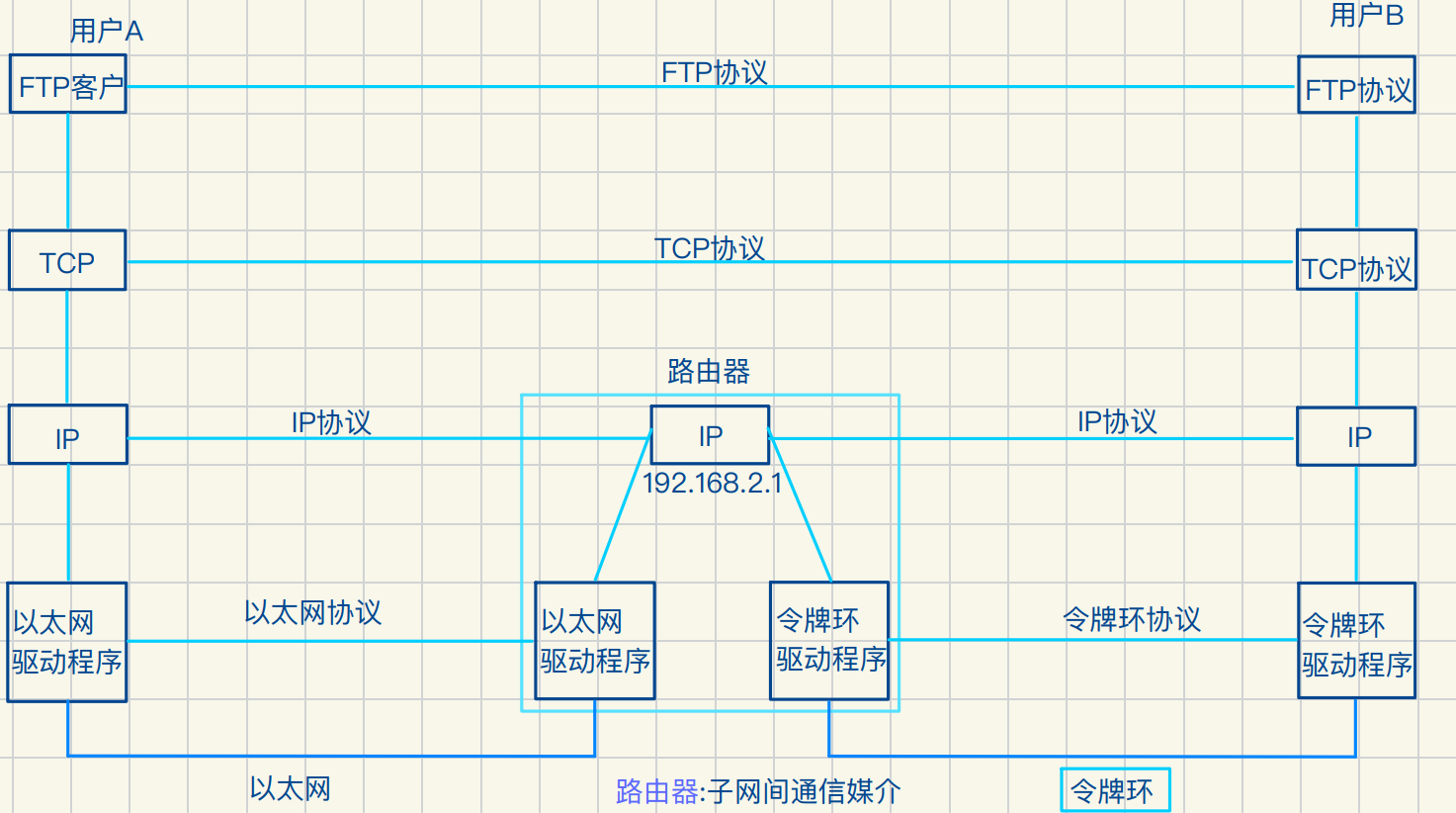
TCP/IP五层(四层)模型
TCP/IP是⼀组协议的代名词 它还包含许多协议 组成TCP/IP协议簇
TCP/IP⽤了五层结构 每⼀层都呼叫其下⼀层所组成的⽹络完成其需求
物理层:例如⽹卡 光纤 猫之类 ⽤于和外间1交换光电信号完成数据交互
集线器 ⽤于信号放⼤ 减少物理层数据衰减的影响
数据链路路层:例如交换机 ⽤于局域⽹(短距离)间通信
⽹络层:IP 如路由器 ⽤于短距离⽹络通信
传输层:如传输控制协议TCP ⽤于保证源机将数据传输到⽬标机
应⽤层:如⽂件传输协议 电⼦元件传输 负责程序ᳵ沟通
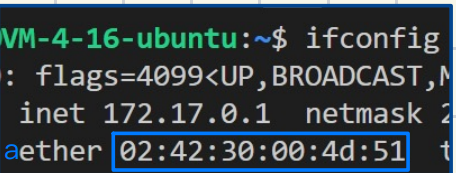
MAC地址
⽹卡出场⼚时⾃带的⼀串48位的序列号 发送信息是会⾃动带上
其他设备接受到此信号后会⽤⾃⼰的MAC地址与其进⾏⽐较
相同则接收 反之丢弃
MAC地址具有唯⼀性
很多设备都有类似唯⼀值
LAN的碰撞检测和碰撞避免
⼀个主机发送数据后会⼀直不断检测(碰撞检测)
此数据是否会和其他机器发送的数据发⽣碰撞
若发⽣碰撞 则休眠⼀⼩段时ᳵ再发送(碰撞避免)
⼀个以太⽹仅允许⼀段时ᳵ内⼀个主机发送数据 故以太⽹也是公共资源
碰撞检测和碰撞避免也是为了保证以太⽹被使⽤的唯⼀性
故⽽以太⽹也是临界资源 数个主机就是临界区或线程
交换机可以缓解碰撞避免导致的⽹络持续休眠问题
信号⽹络传输基本流程
IP地址
在IP协议中⽤于表示⽹络下的不同主机
IP协议有两个版本 ,分别是IPv4和IPv6,⼀般情况下指IPv4
IP地址是4字节32位整数

这是点分十进制表示方案
IP地址和MAC地址区别
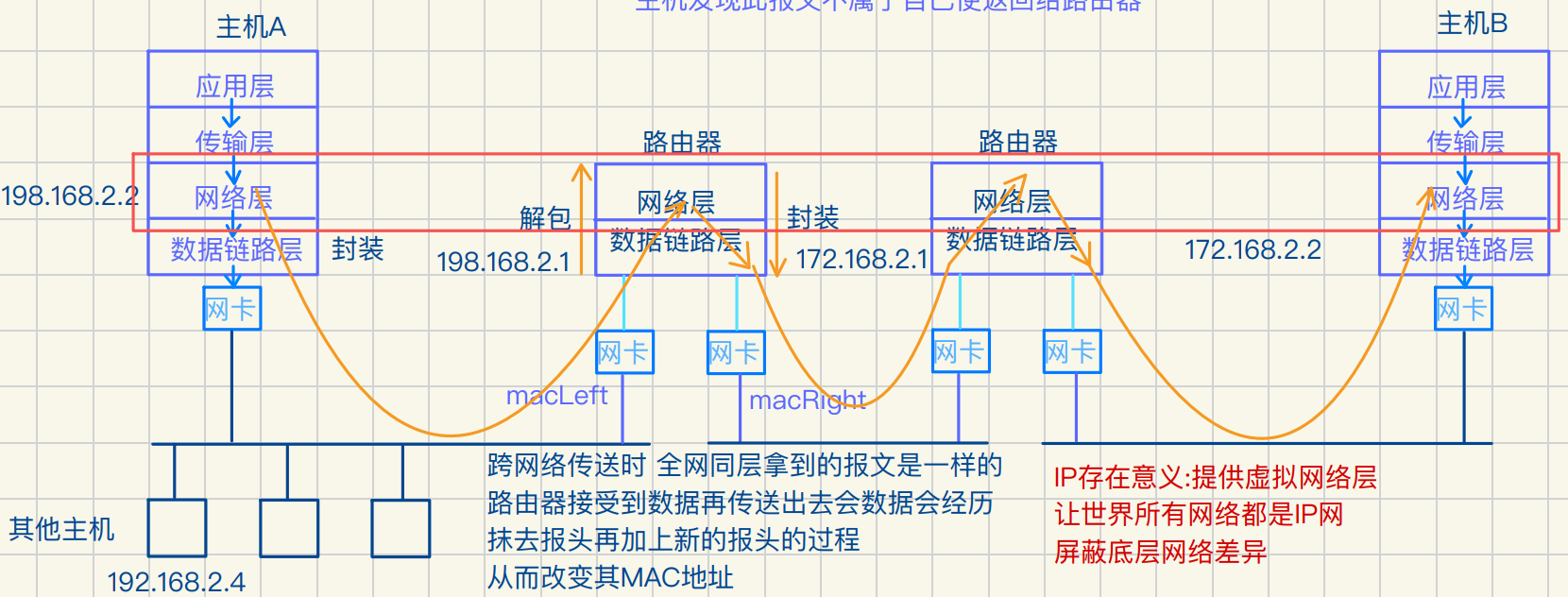
超长距离⽹络传输的本质是 按照指定路径
数据从⼀个局域⽹(⼦⽹)跃迁到下⼀个局域⽹
如此循环最终到达⽬的地
IP地址在⽹络信号传输中扮演⽬的地地址⻆⾊
⽽MAC地址扮演中继局域⽹主机地址⻆⾊
所以MAC地址仅在局域⽹或⼦⽹中有效
IP地址作为⽬的地地址⼏乎不变
主机依托路由器长距离通信简图
以太网
由于⼀开始科学不发达 声⾳传播需要媒介
于是物理学家误以为光传播也需要媒介
因此将传播光的媒介叫做aether
后来科技发展才知道光传播不需要媒介,便抛弃以太的概念
计算机科学中数据远距离传输需要媒介,将此媒介叫做以太
路由器
路由器:⼦⽹ᳵ通信媒介
处于⽹络层,路由器横跨两⽹络
就必须有链接两⽹络的接⼝,和连接两点⼦⽹的驱动程序
路由器可构建⼦⽹ 是⼦⽹出⼝,上⽹主机需要连接路由器
在连接路由器的同时路由器会主机的IP地址和MAC地址记录
主机发现此报⽂不属于⾃⼰便返回给路由器
端⼝号
端⼝号是传输层协议内容 是2字节16位整数
⽤户标识⼀个进程 当前数据要交给哪个进程处理
IP地址+端⼝号可以⽤于标识⽹络上某⼀个主机的某⼀个进程

PID属于进程管理范畴
端⼝号属于⽹络操作进程范畴
使⽤两种类型数据来管理进程是为了解耦
端⼝号范围划分
0-1023:主流端⼝号 HTTP FTS SSH 是⼴为流传的应⽤层协议
它们的端⼝号是固定的
1024-65535:操作系统动态分配的端⼝号 客户端程序的端⼝号
由OS从此范围分配
源端⼝号和⽬的端⼝号
传输层协议(TCP和UDP)的数据段有两个端⼝号 源端⼝号
和⽬的端⼝号
分别描述是谁发的和发给谁的
源IPscrip 源端⼝srcport ⽬的IPdstIP ⽬的端⼝dstprot
四元组便可标识互联⽹唯⼆两个进程
传输层的重要成员TCP和UDP
TCP 传输层协议 有连接 可靠传输 ⾯向字节流(按需收取)
UDP 传输层协议 ⽆连接 不可靠传输 ⾯向数据报(整个收取)
socket
socket分三种 ⽹络socket 本地socket(unix域间socket)
原始socket(和⽹络⼯具有关)
⽹络socket既可以本地通信 也可以远距离⽹络通信
套接字就是⽹络中两个app进通信时各⾃连接通信的端点
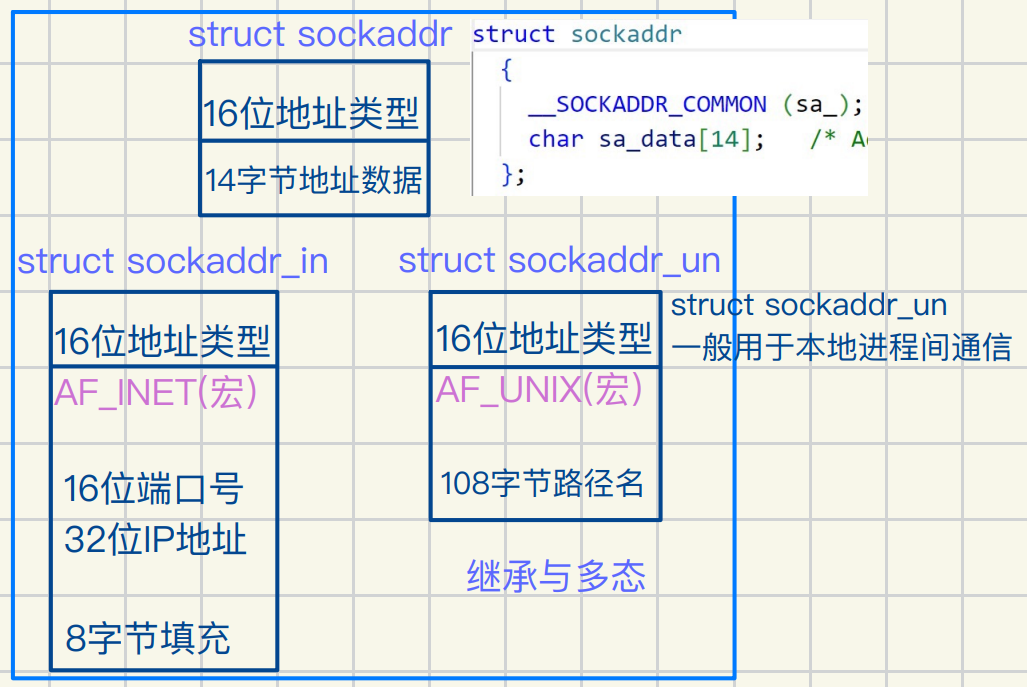
struct sockaddr
存在⽬的是为了socket常⽤接⼝参数类型统⼀
先声明⼀个struct sockaddr类型结构体
再强制类型转换成struct sockaddr_in
struct sockaddr_un即可

端口号转大端的函数接口
#include <arpa/inet.h>
字节序转换函数
功能:进⾏⽹络字节序和主机字节序的转换
因此需要使⽤这些函数将将要发送到⽹络中的端⼝号port转换
uint32_t htonl(uint32_t hostlong); 类型是⽆符号32位整数
htonl就是host to network long
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
常⻅IP地址如 192.168.34.45属于字符串⻛格IP地址
点分⼗进制 可读性较好
⽹络通信 char char char char 4字节表示IP地址IP地址转网络风格接口
in_addr_t inet_addr(const char *cp);对于IPv4:inet_pton,inet_addr对于IPv4和IPv6:inet_pton作⽤:它⽤于将⼀个点分⼗进制格式的 IPv4 地址字符串转换为⼀个32 位的⽆符号整整型(uint32_t)数值也称为⽹络字节序(network byte order) 是⼤端cp:指向⼀个以 null 结尾的字符串该字符串表示⼀个点分⼗进制的IPv4地址返回值:如果函数执⾏成功,它将返回⼀个⽆符号整整数该整数表示输⼊字符串对应的IPv4地址的⽹络字节序如果输⼊字符串不是⼀个合法的IPv4地址,函数将返回INADDR_NONE(通常定义为 -1)socket相关常⽤API介绍
1. socket()
功能:创建⼀个套接字。
函数原型:SOCKET socket(int domain, int type, int protocol);
参数
domain:指定应⽤程序使⽤的通信协议的协议族 对于TCP/IP协议族 该参数置为AF_INET(IPv4)
type:指定要创建的套接字类型 常⽤的有SOCK_STREAM(流式套接字 对应TCP协议)和SOCK_DGRAM)数据报套接字 对应UDP协议)
protocol:指定套接字使⽤的协议 常⽤的有IPPROTO_TCP(TCP协议)IPPROTO_UDP(UDP协议) ⼀般默认为0即可
返回值:成功时返回新创建的套接字的描述符 所以本质上是创建了⼀个⽂件 失败时返回INVALID_SOCKET
2. bind()
功能:将套接字与特定的IP地址和端⼝号绑定
函数原型:int bind(int sockfd, const struct sockaddr* addr, socklen_t addrlen);
参数
sockfd:套接字描述符 由socket()函数返回
addr:指向包含本地地址(IP+PORT)的套接字地址结构的指针
addrlen:套接字地址结构的⼤⼩ sizeof(addr)
返回值:成功时返回0 失败时返回SOCKET_ERROR
3.recvfrom()
功能:使⽤UDP协议进⾏数据传输时
这个函数主要⽤于从⼀个套接字接收数据,并且能够同时获取发送⽅的地址信息
即收取对象发送的报⽂和地址
函数原型:ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,struct sockaddr *src_addr, socklen_t *addrlen);
sockfd:指定要接收数据的套接字描述符
buf:指向⽤于存储接收到的数据的缓冲区
len:指定缓冲区buf的度,即最多能接收多少字节的数据
flags:指定接收数据的选项 通常设置为0 但也可以使⽤⼀些特定的标志来修改接收⾏为(如MSG_PEEK、MSG_WAITALL等)
src_addr:指向⼀个sockaddr结构体 ⽤于存储发送⽅的地址信息 即⽬标主机 如果不需要这个信息 可以设置为NULL
addrlen:是⼀个输⼊/输出参数 在调⽤前 它应该包含src_addr结构体的⼤⼩(通常是sizeof(struct sockaddr_in))
在调⽤后,它会被设置为实际存储在src_addr中的地址信息的⼤⼩。
参数具体含义:从指定的sockfd处以flag(⼀般为0阻塞⽅式)⽅式收取len长度的消息到buf中 成功返回收到的字节数
4.sendto()
功能
函数原型:ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,const struct sockaddr *dest_addr, socklen_t addrlen);
参数
sockfd:套接字描述符或套接字对象 ⽤于标识要发送数据的⽹络套接字
sockfd既可以向任意⽅发送数据 也可以接受来⾃任意⽅的数据 这种特性叫做---全双⼯
结论 sockfd即可以是接收⽅的套接字 也可以是发送⽅的套接字
buf:指向要发送数据的缓冲区的指针或字节数组
len:要发送的数据的度
flags:发送选项 通常设置为0即可 但也可以设置为其他值以改变发送⾏为,如MSG_DONTWAIT等
dest_addr:指向⽬标地址的指针 通常是⼀个sockaddr结构体 包含IP地址和端⼝号 ⽬标主机和进程
addrlen:⽬标地址的长度 通常为sizeof(struct sockaddr)
5.inet_aton()
功能:将字符串形式的IP地址转换为⼀个32位的⽹络序列(⼆进制)IP地址
函数原型:int inet_aton(const char *string, struct in_addr *addr);
参数
const char *string:这是⼀个指向以空字符结尾的字符串的指针
该字符串表示⼀个点分⼗进制的IPv4地址(如“192.168.1.1”)
struct in_addr *addr:这是⼀个指向in_addr结构的指针 该结构将⽤于存储转换后的32位⽹络序列IP地址
in_addr结构通常包含⼀个名为s_addr的成员 它是⼀个32位⽆符号整数 ⽤于存储IP地址的⼆进制表示
成功返回⼀个string类型的IP地址
struct sockaddr_in ⼀般如何设定
需要对三个成员变量进⾏初始化 分别是协议簇 IP地址与端⼝
服务器视⻆下三次握⼿和TCP常⽤握⼿相关接⼝和SYN ACK等对应
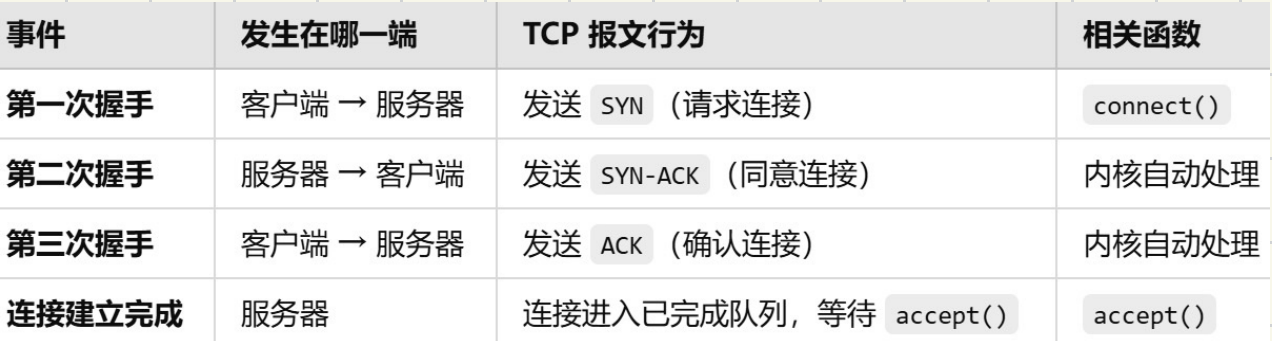
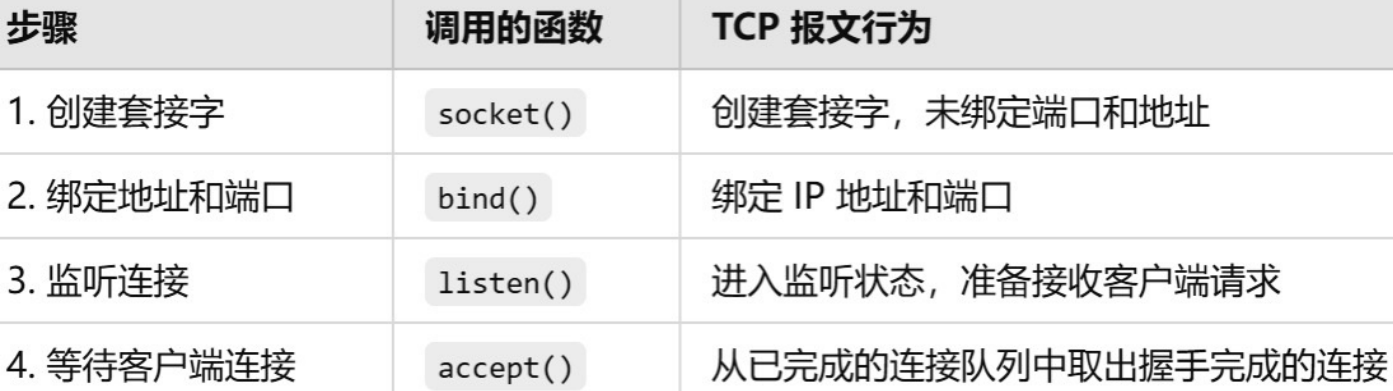
1.listen():开启监听,等待ᬳ接(但不接受ᬳ接)
2.connect():触发 第⼀次握⼿,发送 SYN
3.服务器收到SYN并回复SYN-ACK(第⼆次握⼿)
4.客户端收到SYN-ACK并回复ACK(第三次握⼿)
5.三次握⼿完成后,服务器的accept()取出已建⽴的链接
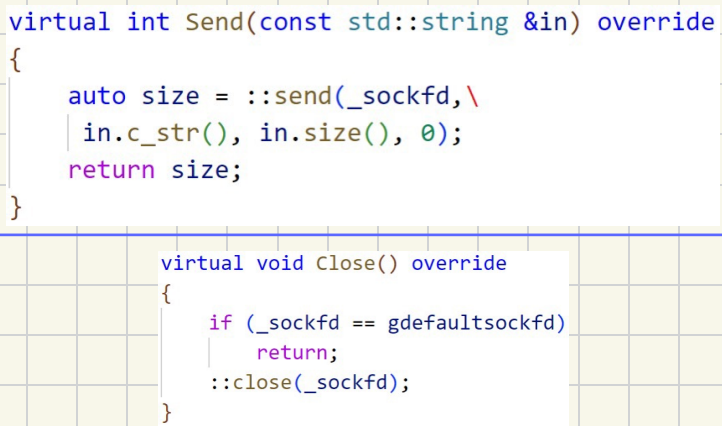
TCP_socket封装(服务端)
1.蓝图抽象类
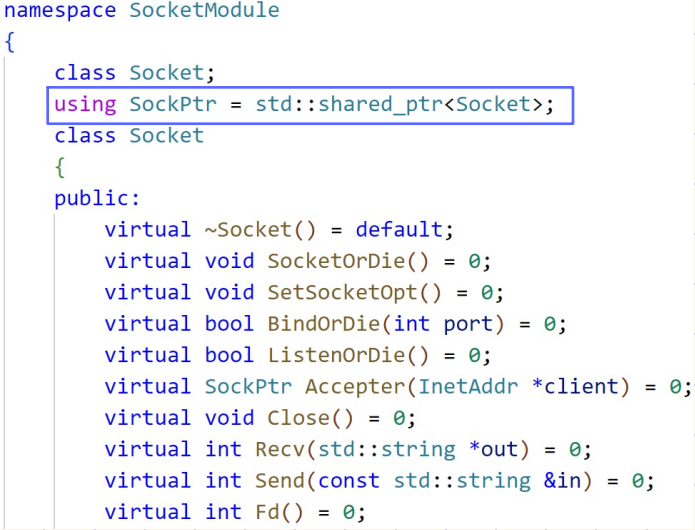
2.针对不同平台使⽤的不同代码

3.以生类具体实现
成员变量和构造函数

套接字创建

将已被bind的套接字变为被动套接字

使被动套接字请求与⽤户连接进⾏通信(与⽤户建⽴通信通道)

4.正式开始通信
与⽤户进⾏通信--接受消息接⼝

与⽤户进⾏用信--发送消息接⼝
序列化和反序列化
序列化:将字符串多变⼀的过程(例如将结构体中数据合并为⼀个字符串)
反序列化:将字符串还原成结构体(结构化数据)的过程
序列化的⽬的是⽅便⽹络发送 反序列化是为了⽅便上层处理
协议定制:定制双⽅都能认识,符合通信业务所需的结构化数据,就是struct或class
有关TCP的全双⼯性
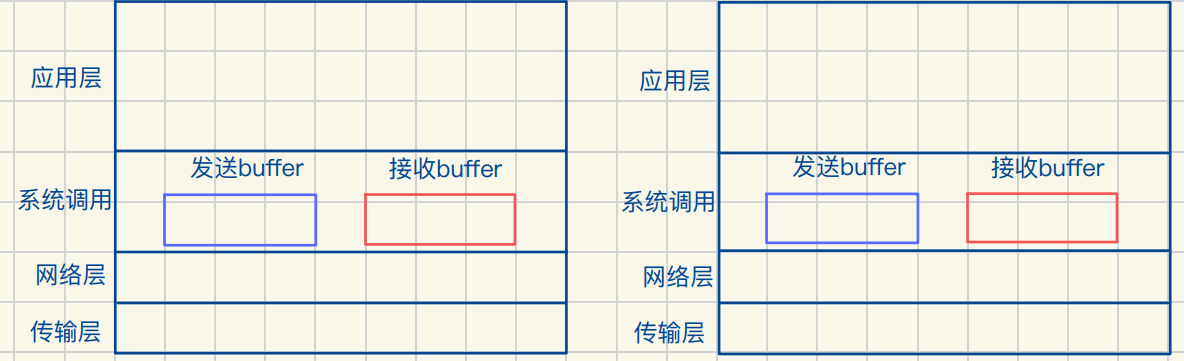
UDP发送的报⽂⼀定是完整的 TCP发送报⽂可以不完整
发送数据的本质是将数据拷⻉到缓冲区中
OS中存在⼤量报⽂且⽤先描述后组织的⽅式管理
使⽤链表进⾏组织
JSON实现序列化和反序列化
序列化接⼝
这个序列化步骤⼤致分为三个步骤
1:初始化JSON配置root
2:配置写⼊⾏为
3:将root序列化⼊stringstream

反序列化接⼝

应⽤层HTTP协议

对搜索引擎关键词进行编址
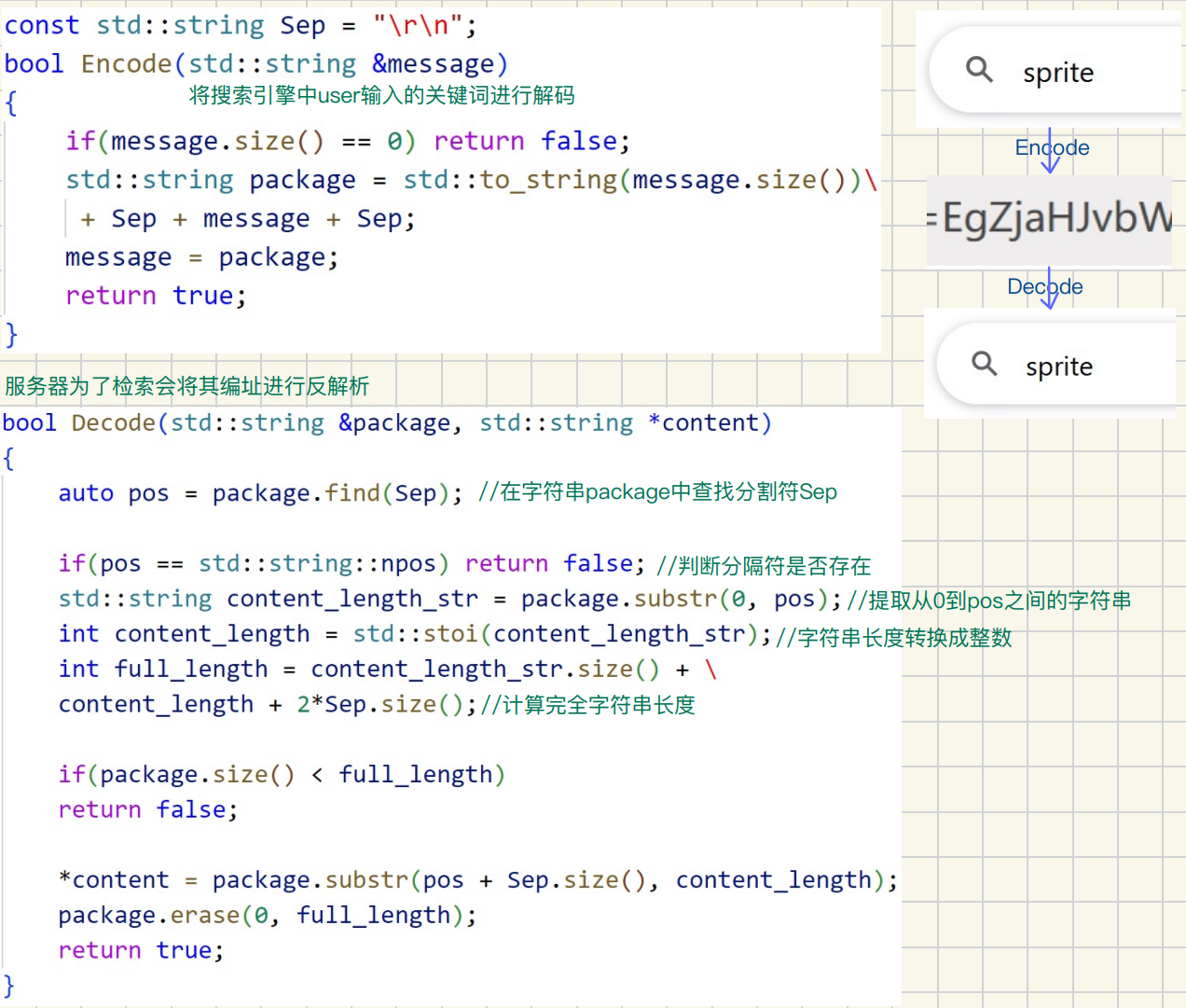
Encode的⽬的是为了避免搜索关Ძ字和URL中的关键字形成冲突进⽽导致URL解析失败
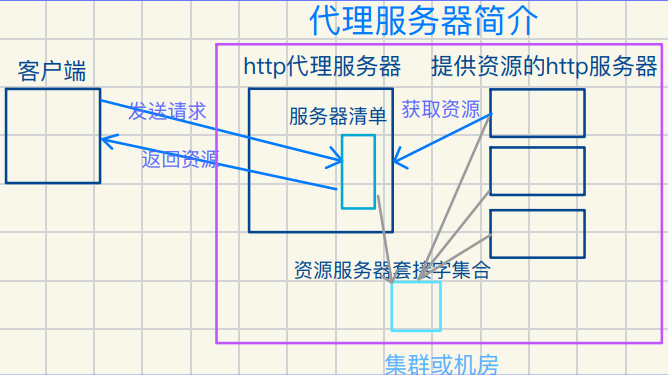
图示代理服务器基本运作方式
状态码
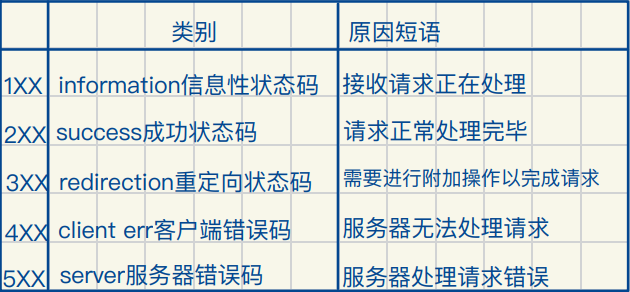
静态数据和交互式数据
静态资源:图⽚ css js 视频等
交互式资源:user上传数据后服务器要对其进⾏处理(例如登录)

PUT 传输⽂件⽅法
DELETE 删除⽂件⽅法
cookie
http基于cookie的会话保持原理
情景:打开B站 此时处于未登录状态 登录 关闭B站
再打开B站 它就保持登录状态
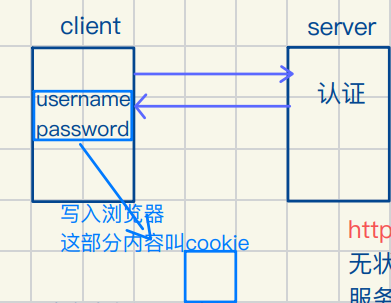
cookie也有内存级和硬盘级
浏览器关闭后要重新登录就是内存级
http是⽆连接 ⽆状态的协议
⽆状态意思是每个HTTP请求独⽴
服务器不记录之前任何请求(每次访问新⽹⻚都要登录)
为了提⾼user体验 所以我们将user相关数据放⼊cookie
PS ⾯向链接!=有链接
Session

如果服务器检测到userのip地址变化异常
服务器会使user的session_id失效
达成冻结账号效果 使hacker⽆法盗取数据
总结:session的主要功能
1 状态管理(有状态) 服务端存储会话数据
2 ⽤户认证 记录登录(记住账号密码)
3 数据持久化 记录会话期ᳵ⽤户数据(收藏)
4 避免重复请求和攻击守护
5 跨⻚⾯传递状态
实现⽅式
客户端 通过cookie存储session ID or URL传递
服务端 通过session ID查找在内存or数据库中会话数据
综上:cookie+session=http会话保持方法
Fiddler
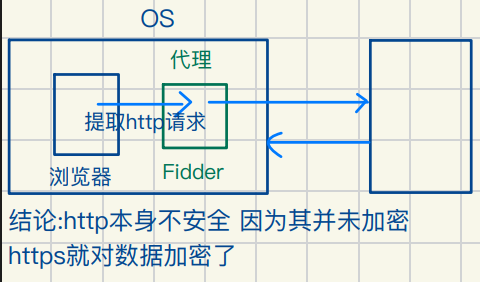
https加密概念简述
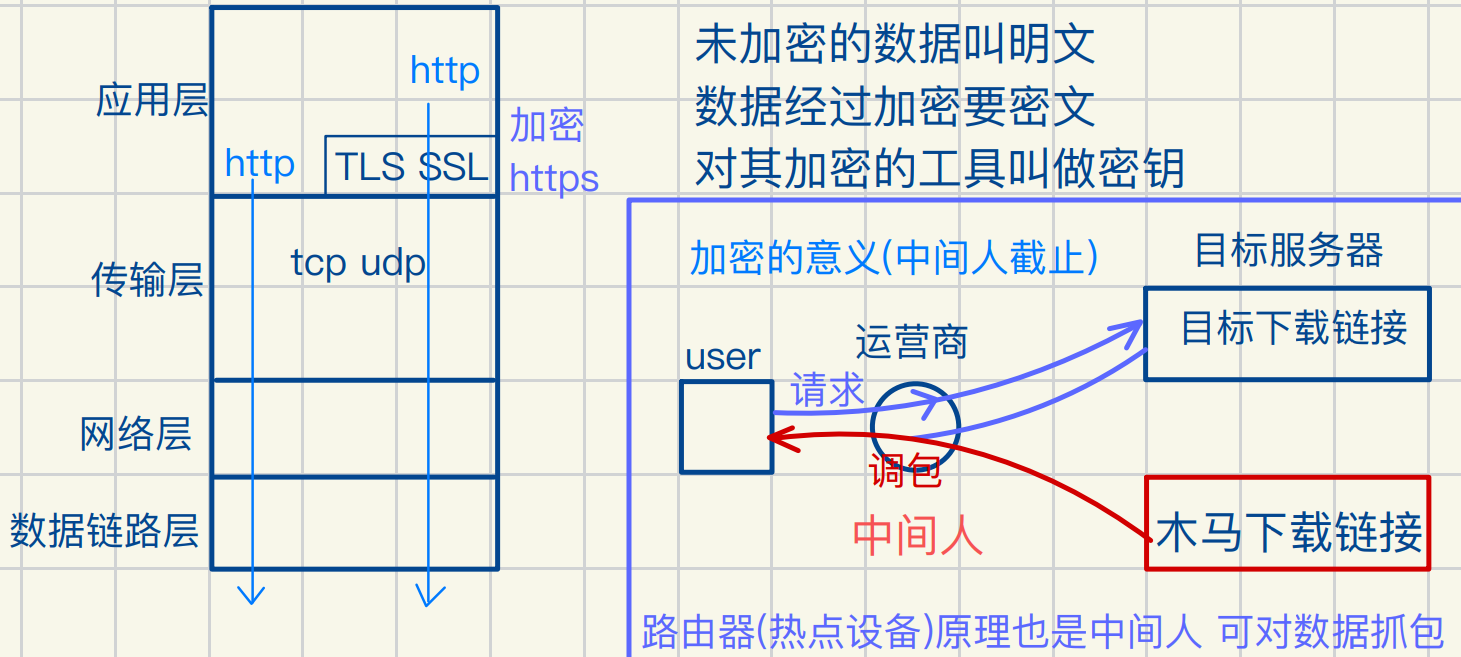
加密方式简述
对称加密 什么⽅法加密 对应⽅法解密 常⻅算法AES DES RC4
⾮对称加密 ⼀个公钥 另⼀私钥 公钥加密 私钥解密 算法更复杂
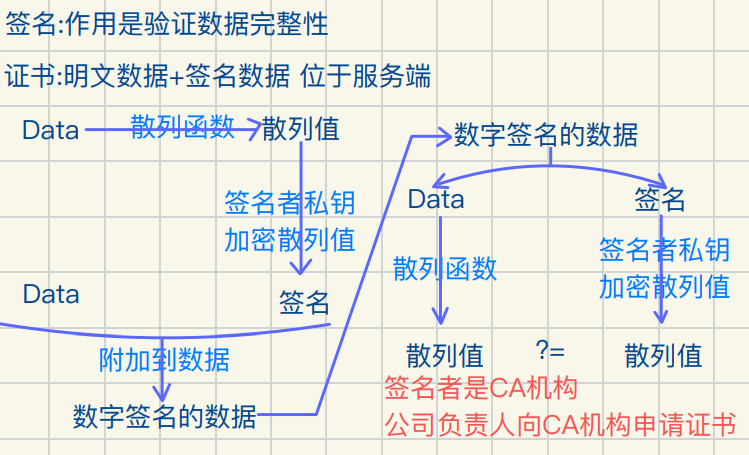
数据摘要&数据指纹 哈希函数对数据运算⽣成固定长度数据摘要
⽤于判断数据有没有被篡改
秒传的原理就是将user的传递⽂件数据摘要进⾏对⽐
有同样的保留⼀份 让这⼀份独⾃上传即可
为了同时保证安全性与效率性 常⽤混合加密⽅式
⾮对称加密⽤于密钥交换(cli和ser)
对称加密⽤于数据传输
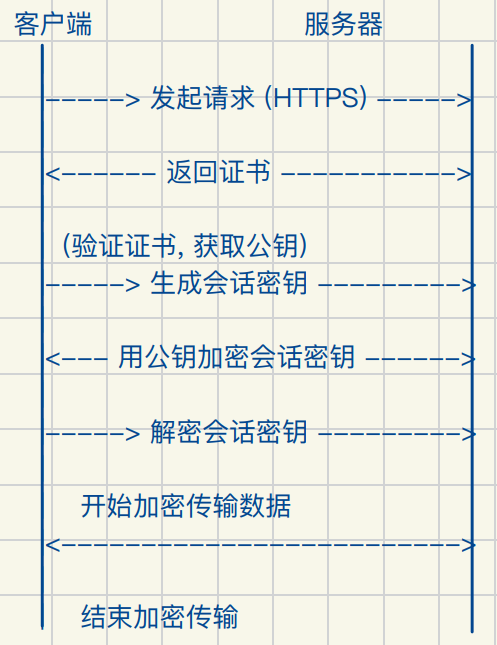
中间人攻击原理简述
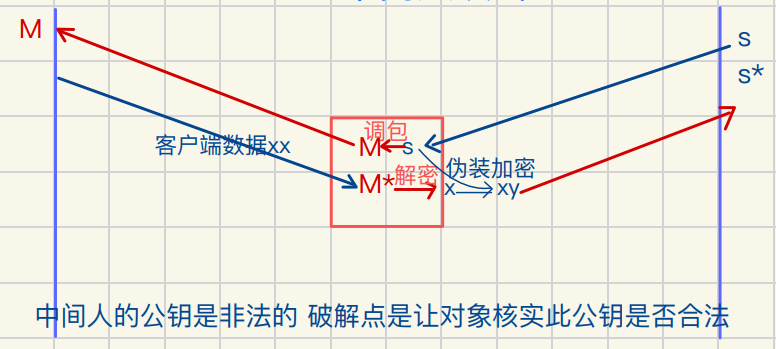
证书(反中间⼈攻击)
UDP协议
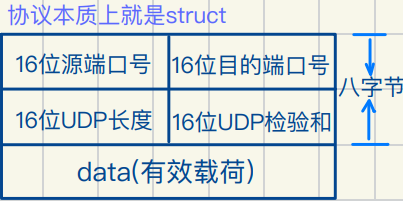
UDP如何做到解包 直接读取UDP报⽂前⼋个字节
UDP是如何做到分⽤ 看哪个进程和16位端⼝号关联
将特定报⽂转给特定进程 进⽽对报⽂进⾏分⽤
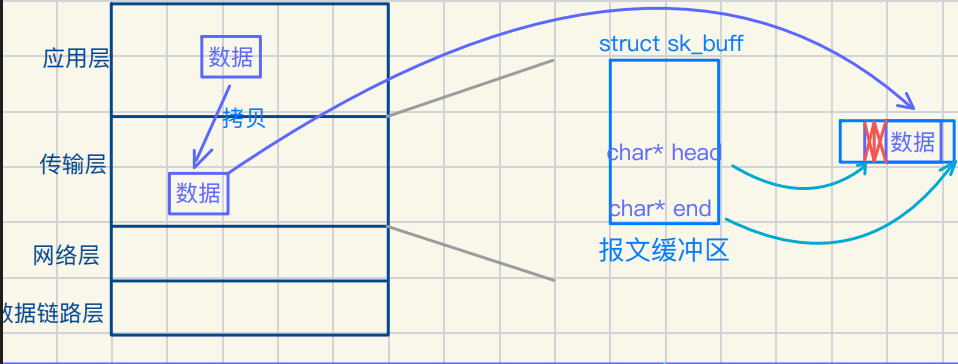
UDP添加报头过程
step1:head-=sizeof(struct udphdr)
step2:(struct udphdr*)head->source = 8080;
(struct udphdr*)head->dst = 9090;UDP⽆法送buffer 只有接收buffer TCP是两者都有
UDP接收到的报⽂未必是发送顺序 但是TCP⼀定是
TCP协议
TCP基本字段

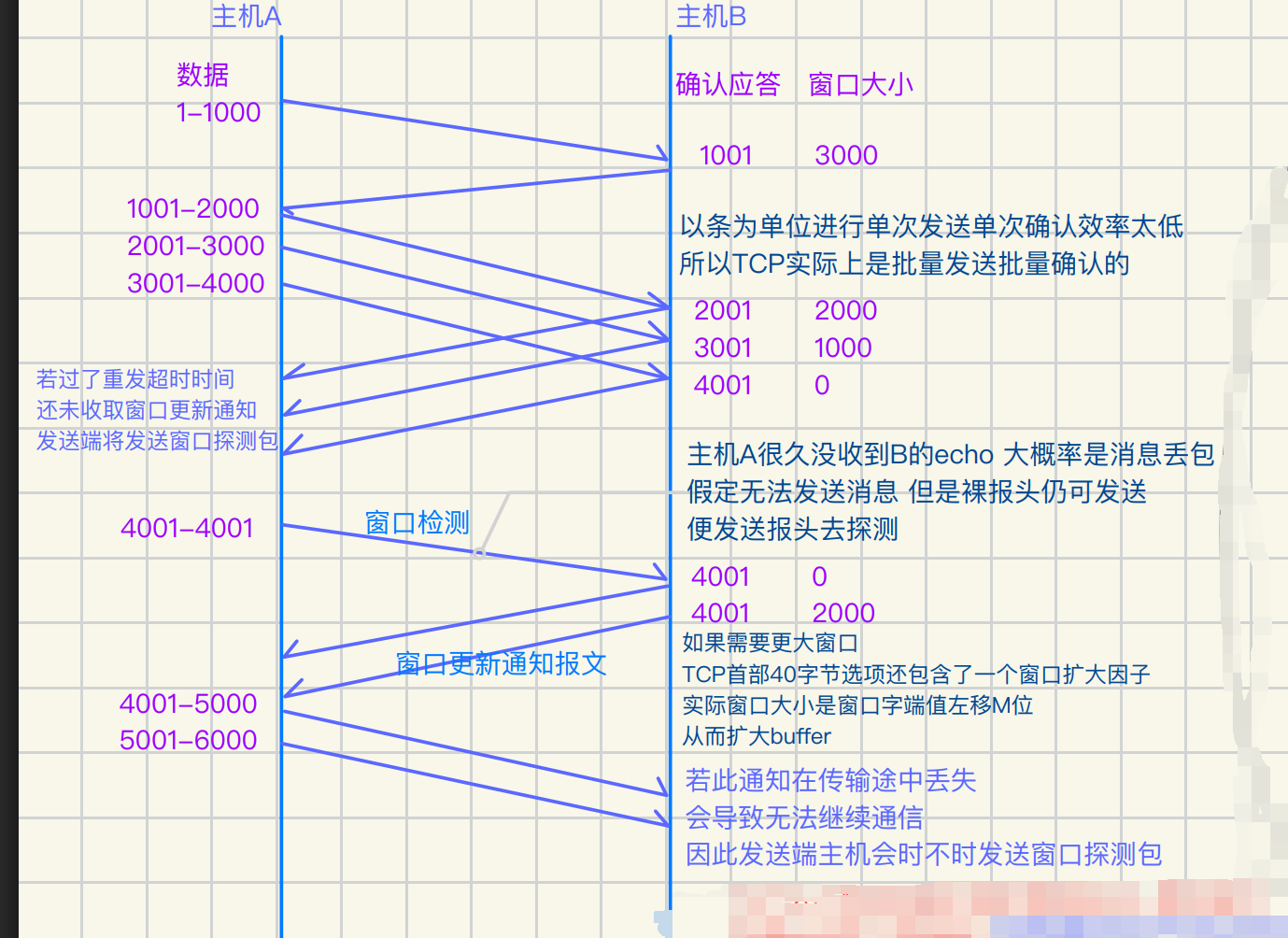
TCP确认应答ACK机制

实际上TCP发送⽅式是⼀次发送N个报⽂
且⼀次返回N个报头确认(有丢包⻛险)
Q 消息太多服务器来不及接收咋办
A 流量控制:服务器(将要)过载减缓cli发送速率直⾄0
Q 发送⽅如何知到对⽅将要过载?
A 16位窗⼝⼤⼩就是接收buffer剩余空ᳵ⼤⼩
传递过来的数据是2000 确认应答序列号是2001
其真正含义是2001及其之前所有的数据都确认收到
什么是连接
⼀个连接⼀定和⼀个⽂件(fd)对应 所以OS对链接 先描述 后组织管理
所以对连接的管理就是增删查改 维护连接需要时间和内存
超时重传 TCP丢包问题
丢包存在两种情况:1 数据未到接收⽅ 2 应答未echo到发送⽅
主机⽆法确认是哪种丢包 只可知到⽆echo
这种情况下只能超时重传 ᳵ隔的时ᳵ较短且不固定
标志位作用
TCP报⽂=报头+有效载荷
标志位⽤于区分不同报⽂类型
ACK(acknowledgment)确认报⽂ 需关注序列号
由于捎带应答 tcp的ACK⼤部分为1
SYN(synchronize)同步标志位 建⽴链接请求
FIN(final) 链接断开标志位
TCP三次握⼿和四次挥⼿
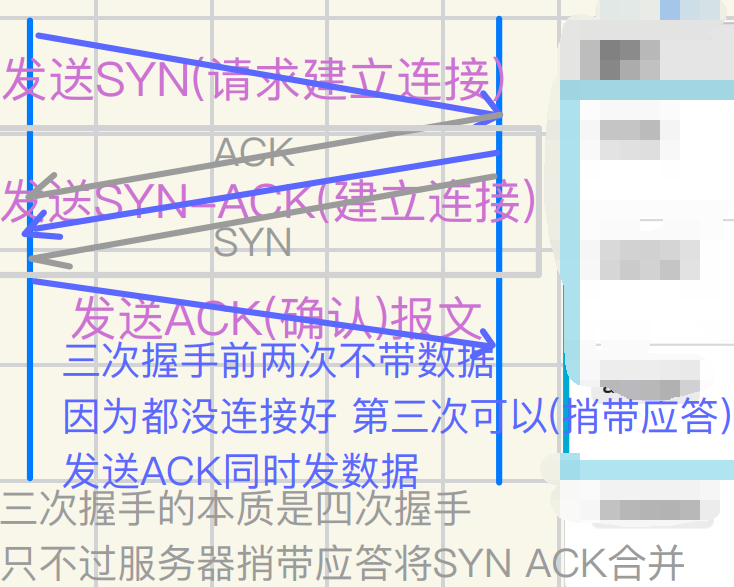

connect是触发三次握⼿ 其本身不直接参与三次握⼿过程
三次握⼿是因为 1.建⽴发接需要双⽅的同意 2验证全双⼯通道通畅性 即⽹络允许
总之需要双⽅和环境的同时许可
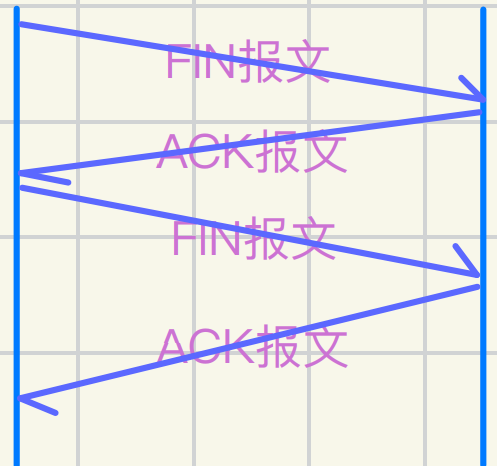
第⼀次 客户端发送FIN请求关闭连接
第⼆次 服务器收到FIN后,发ᭆACK确认
第三次 服务器发送FIN请求关闭连接
第四次 客户端收到服务器的FIN后 发送ACK确认
由于TCP的全双⼯性 所以要关闭两个朝上的连接
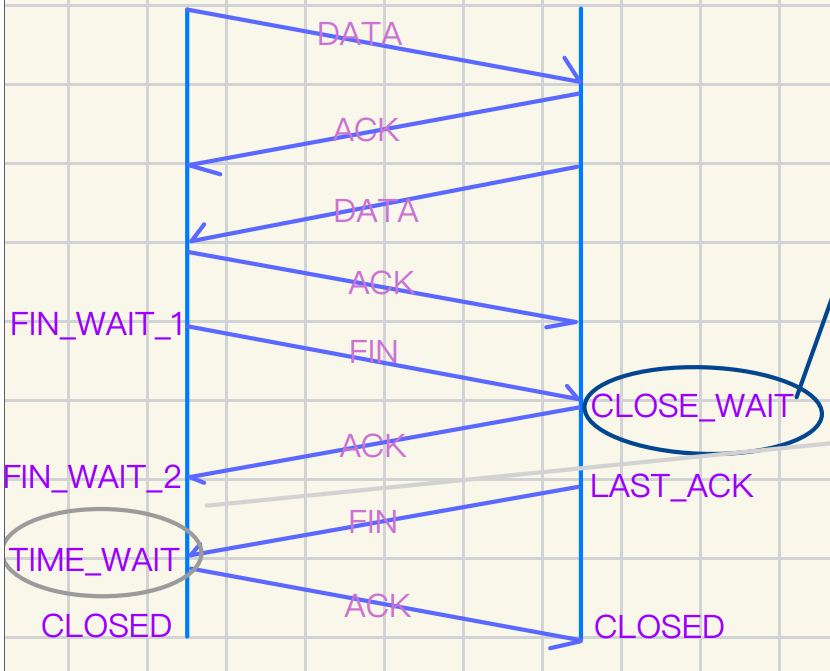
详解四次挥⼿
int shutdown(int sockfd, int how); 了解 ⽆需会⽤
sockfd:需要关ᳮ的套接字描述符
how:指定关闭的⽅式,表示关闭套接字的哪个部分(发送,接收或两者)
how
SHUT_RD (0):只关ᳮ套接字的接收⽅向(即不再接收数据)
发送数据仍然可以进⾏
SHUT_WR (1):只关闭套接字的发送⽅向(即不再发送数据)
接收数据仍然可以进⾏
SHUT_RDWR (2):关闭套接字的发送和接收⽅向
套接字将完全被关闭
既不能发送也不能接收数据如果服务器不关闭sockfd 仅完成两次挥⼿
BUG:如果服务器出现⼤量CLOSE_WAIT状态 说明服务器并且真正关闭socket
加上对应的close即可(现象就是服务器很卡)
FIN_WAIT_1:表示主动关闭⽅已经发送了 FIN 包
并等待对⽅的 ACK 确认
此时,主动关闭⽅仍可以接收数据
FIN_WAIT_2:表示主动关闭⽅已经收到对⽅的 ACK 确认
并且处于等待对⽅发送 FIN 包的状态
等待对⽅关闭连接
TIME_WAIT:表示连接的⼀个端点已经完成了连接的关闭
但仍然保持⼀段时间 (这个状态下连接并为真正被关闭)
以确保所有的报⽂都能正确到达并且不会丢失
主动断开闭接⼀端 发送完毕最后⼀次握⼿后
会等待两个MSL(max segment lifetime)时间
BUG:为什么在TCP下第⼀次在客户端连接服务器后再杀进程(关闭连接)
再次ᬳ接服务器会出现“bind error”的错误
A:原因在于端⼝占⽤ 在 TCP 连接关闭时,客户端进⼊ TIME_WAIT 状态,
这个状态会持续⼀段时ᳵ, TIME_WAIT 状态期间,客户端的源端⼝被占
⽤,即使连接已经断开,操作系统也不允许⽴即⽤这个端⼝,因为它需要
确保所有可能的延长报⽂都已经到达并被处理
C:可以等四分或使⽤其他端⼝
也可以使⽤setsockopt减少端⼝被调⽤时间
TCP策略
滑动窗口
窗⼝⼤⼩:TCP 连接中,接收⽅为每个连接设置⼀个接收窗⼝(Receive Window)
表示接收⽅当前可以接收的最⼤字节数。接收⽅会在每个 ACK 包中向发送⽅告它的窗⼝⼤⼩
每个窗⼝最⼤64k
为什么不将滑动窗⼝里的数据达成⼀整块报⽂⽽是分成数个数据段?
数据链路层规定单次发送的数据帧有效载荷长度
(IP报⽂进⼊数据链路层会被封装成数据帧)不可超过mtu长度(⼀般是1500)
由⽹络层⾃⼰分⽚和组装
滑动窗口简图示意
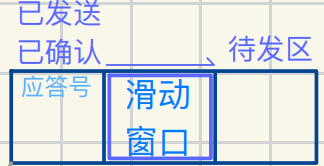
滑动窗⼝数据结构上就是个⼀位数组
滑动窗⼝⼤⼩=接收⽅窗⼝⼤⼩
滑动窗⼝⼯作模式是⼀边向右移⼀边将范围内数据发送,所以流量控制是通过滑动窗⼝实现的
发送buffer可以看成⼀个环形顺序表 不会越界
已发送确认数据区域本质是数据被释放
所以这就是“环形产消模型”
滑动窗⼝丢包问题
1 最左侧丢失
滑动窗⼝不会右移 因为后续数据会阻塞
直到丢包数据被重传并确认
(ps被发出数据不会被⽴即删除
⽽是暂存在滑动窗⼝左侧
收到应答后才可删除)
2 中间丢失 同1
3 最右侧丢包 同1
确认数据报定义是之前所有数据都收到
哪里开始丢失就在哪里停滞然后重传
超重传
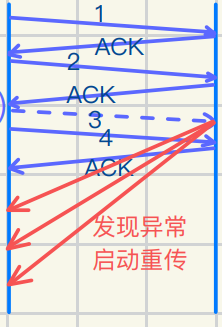
快速传的⼯作原理
丢包检测:当 TCP 发送⽅发送的数据包到达接收⽅时
接收⽅会对每个正确接收的数据包发送⼀个确认(ACK)
如果接收⽅发现⼀个数据包丢失,它会继续重复确认最后⼀个成功接收的数据包
这些重复的 ACK 就是快速传机制的信号
重复 ACK:当发送⽅收到多个重复的 ACK 时(通常是三个重复的 ACK)
就意味着某个数据包丢失了
此时,发送⽅不需要等待超时,⽽是⽴即认为丢失的数据包需要重传
触发重传:在收到三个重复 ACK 后,发送⽅会⽴即重传丢失的数据包
⽽不是继续等待重传超时
PSH标志位:PUSH=1 请尽快将你的buffer数据交给上层
RST标志位:三次握⼿建⽴链接异常时 双⽅皆可reset(ᬳ接重置)
URG标志位:值为1时处理紧急数据
例如:
1 发送⽅发送的数据包 1, 2, 3, 4, 5;
接收⽅收到 1, 2, ,4, 5(假设包 3 丢失)
2 接收⽅会重复发ᭆ ACK 3 次
3 确认数据包 2(即重复 ACK)
4 发送⽅收到三个重复的 ACK 后
⽴即重传丢失的包 3
⽹路拥塞
⽹路拥塞⼤量数据丢包会发⽣⽹络拥塞ᳯ题
解决ᳯ题不是重传 ⽽是慢启动
先发送少量数据测试当前⽹络压⼒
如果每次都会得到对⽅的ACK 则多次加倍发送数据
这是⼀个指数算法
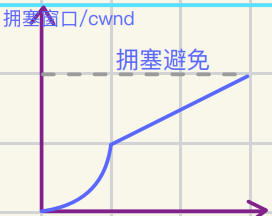
拥塞窗口
为了衡量接收主机接收能⼒问题 使⽤滑动窗⼝解决
为了衡量传输数据能⼒ᳯ题 可以使⽤拥塞窗⼝
每次发送数据包 将拥塞窗⼝和接受端主机反馈窗⼝进⾏⽐较 取⼩的
拥塞窗⼝增加已开始是指数 到达⼀定阈值(慢启动阈值)后呈线形增加
拥塞控制算法:慢启动+加法增⼤+乘法减少
拥塞窗⼝本质是对⽹络健康拥堵状态的评估
延时应答
⼯作原理:
TCP协议在收到数据段时
通常会⽴即发送⼀个ACK报⽂来确认收到数据
但是在某些情况下,TCP可以延迟这个确认
(每收到固定数量的报⽂就应答⼀次)
以便在⼀定时间内合并多个确认应答
减少⽹络上的ACK报⽂数量
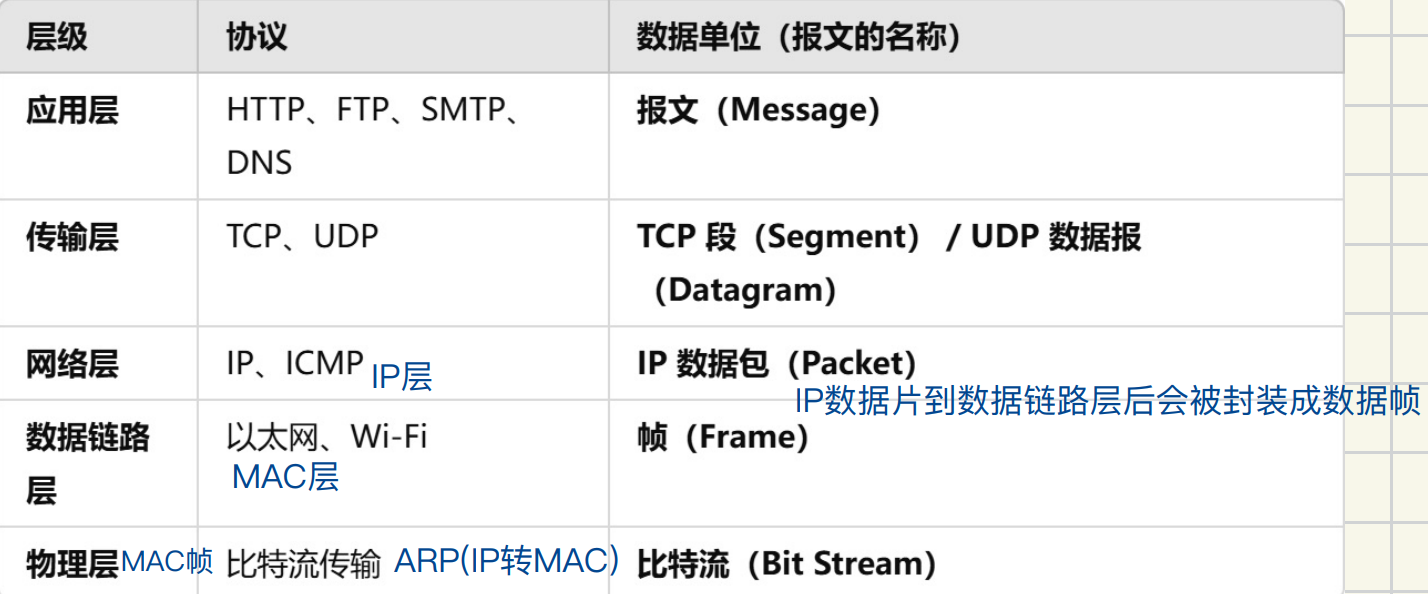
不同层下协议及数据单位
⽹络层结构浅析
路径选择
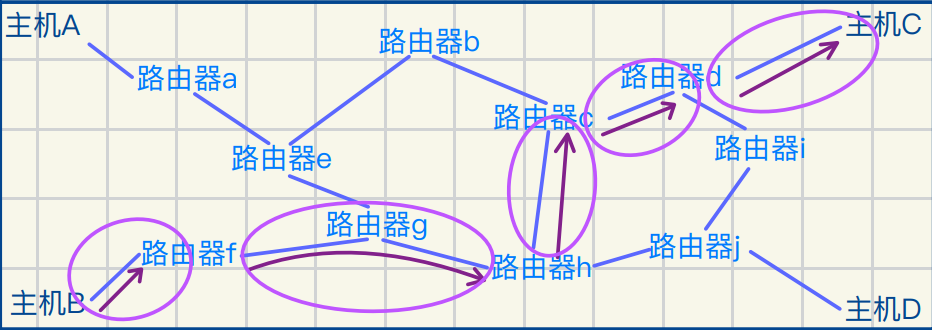
⽬标决定路径
凭借什么交给下⼀个route(⽹络层IP问题)
根据⽬的IP和⾃身路由表&从⽽确定⽹络号
然后不停在⼦⽹间转发直⾄到公⽹
为何将数据交给路由器F(局域⽹通信问题)
⽬的IP地址=⽬标⽹络+⽬标主机
TCP和IP的关系
IP核⼼作⽤是将数据报跨⽹络传输给⽬标主机
如果丢包不需要关⼼ 由TCP协议的超时重传机制解决
所以滑动窗⼝ 超时重传 拥塞窗⼝ ⽹络拥塞都是TCP的策略
IP报头简述
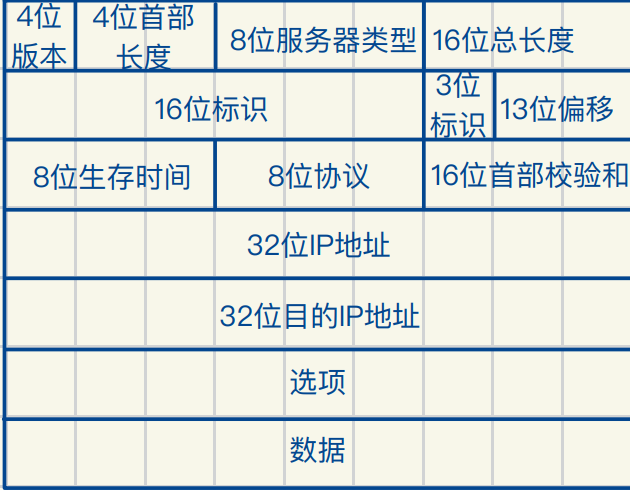
IP=⽬标(⼦)⽹络地址+主机地址
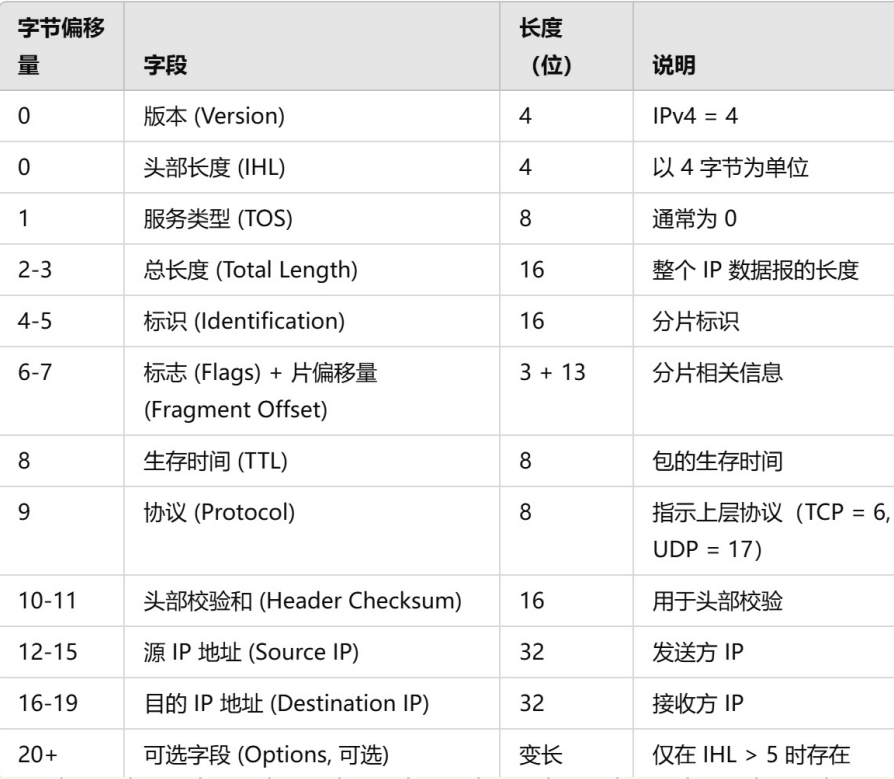
⼦⽹
路由器拥有构建⼦⽹能⼒
⼀个IP地址 被转发:
1 根据⽬标⽹络 转发报⽂到⽬标(内)⽹络
2 转发到⽬标⽹络后 再在内⽹进⾏转发
⼦⽹划分
⼦⽹划分就是调整⼦⽹掩码,把⼀个⼤⽹络分成多个⼩⽹络
⼦⽹掩码越长(如 /26, /27),⼦⽹数量越多,但每个⼦⽹可⽤主机越少
合理划分⼦⽹可以提⾼⽹络性能,管理效率和安全性
为什么要划分⼦⽹?
提⾼⽹络性能:减少⼴播域,降低⽹络拥塞
增强安全性:不同⼦⽹可以隔离,提⾼安全管理能⼒
优化IP地址使⽤:避免IP浪费,提⾼IP地址利⽤率
⽅便管理
如何进⾏⼦⽹划分
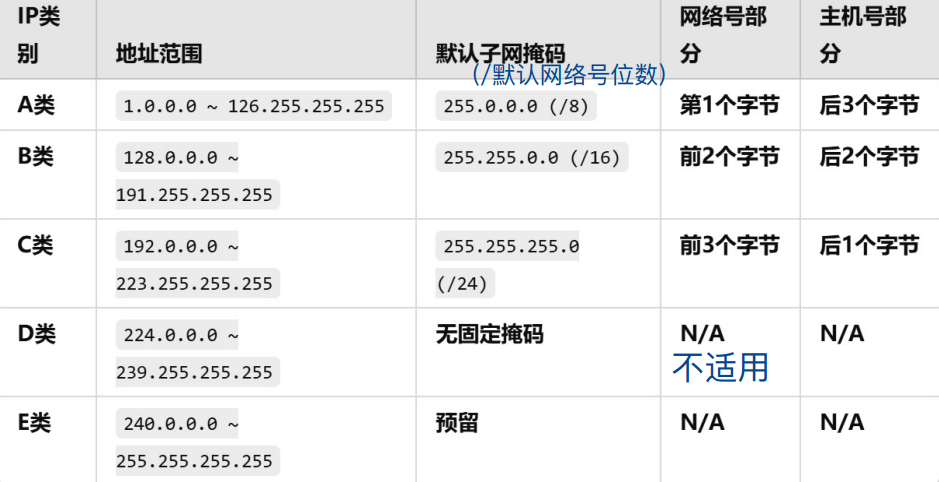
IP地址 = ⽹络号 + 主机号
⽹络号:确定IP地址属于哪个⽹路(⼦⽹地址)
主机号:区分具体设备
⼦⽹IP是⽤⼀个IP地址块(A/B/C类⽹络)划分出来的
⼦⽹掩码
⼦⽹掩码作⽤于区分IP地址中⽹络号(⼦⽹)和主机号的⼀个32位数
⼦⽹掩码的1表示⽹络号 0表示主机号
⼦⽹掩码的格式
A类默认⼦⽹掩码:255.0.0.0
(11111111.00000000.00000000.00000000)
B类默认⼦⽹掩码:255.255.0.0
(11111111.11111111.00000000.00000000)
C类默认⼦⽹掩码:255.255.255.0
(11111111.11111111.11111111.00000000)
⼦⽹掩码的作⽤
⽤于区分⽹络号和主机号
计算公式: IP地址^⼦⽹掩码=⽹络号
⼦⽹掩码计算示例
设备A:192.168.1.10
设备B:192.168.1.20
⼦⽹掩码:255.255.255.0
⽹络号计算:
A 的⽹络号:192.168.1.0
B 的⽹络号:192.168.1.0
✅
相同,A和B在同⼀⼦⽹
可直接通信
如果设备C的 IP 是 192.168.2.5
C 的⽹络号:192.168.2.0
❌
不同⽹络,必须通过路由器通信
⼦⽹掩码决定了此⼦⽹⼤⼩(多少个IP可⽤于主机)
(⼦⽹)
IP地址=⽹络号(⽬标⼦⽹)+主机号(⽬标主机)
⼦⽹掩码⽤来区分⽹络号和主机号的界限
网段划分具体运算概述
⼦⽹划分的主要步骤就是使⽤⼦⽹掩码和 IP 地址进⾏计算
1.确定原始 IP 地址和⼦⽹掩码
先确定要划分的 ⽹络地址 和 默认⼦⽹掩码。
例如:
IP地址:192.168.1.0/24
(其中/24表示前24位是⽹络号,后8位是主机号 24+8=32)
默认⼦⽹掩码:255.255.255.0(/24)
2.确定要划分的⼦⽹数量
如果要划分成 N 个⼦⽹,需要借⽤主机位来创建更多的⽹络号
计算需要的额外⽹络位数:(N:需要的⼦⽹数)
计算 2^X = N,求出X值(X 是额外增加的⼦⽹位数)
新的⼦⽹掩码就是 原⼦⽹掩码 + X。
3.计算新的⼦⽹掩码
默认/24(255.255.255.0)的主机位是8位,如果要划分4个⼦⽹2^3 = 8(所以借⽤ 3 位主机位)
新的⼦⽹掩码变为 /27(255.255.255.192)
旧的默认⼦⽹掩码
11111111.11111111.11111111.00000000
( 255 . 255 . 255 . 0 )
现有新的⼦⽹掩码
11111111.11111111.11111111.11100000
( 255 . 255 . 255 . 224 )
转换成⼗进制:255.255.255.224
4.计算每个⼦⽹的 IP 范围
⼦⽹的增ᰁ(步长):256 - ⼦⽹掩码的最后⼀᮱分
256 - 192 = 64
私有IP和公⽹IP

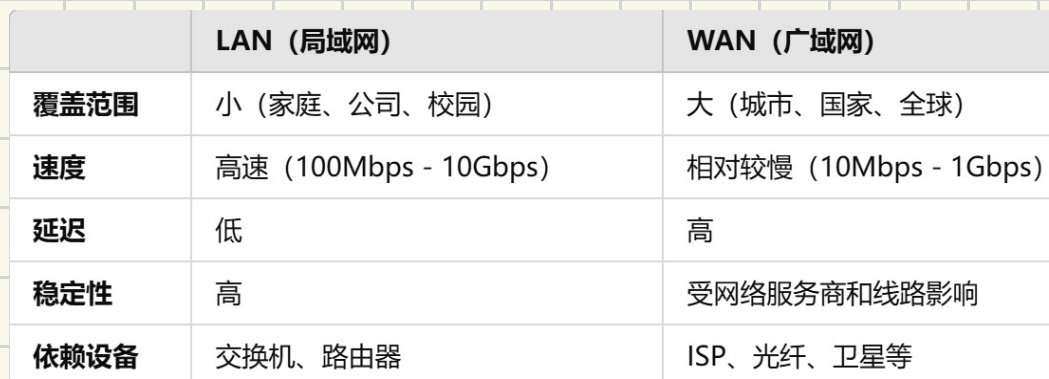
WAN和LAN
运营商
基本⽹络状况
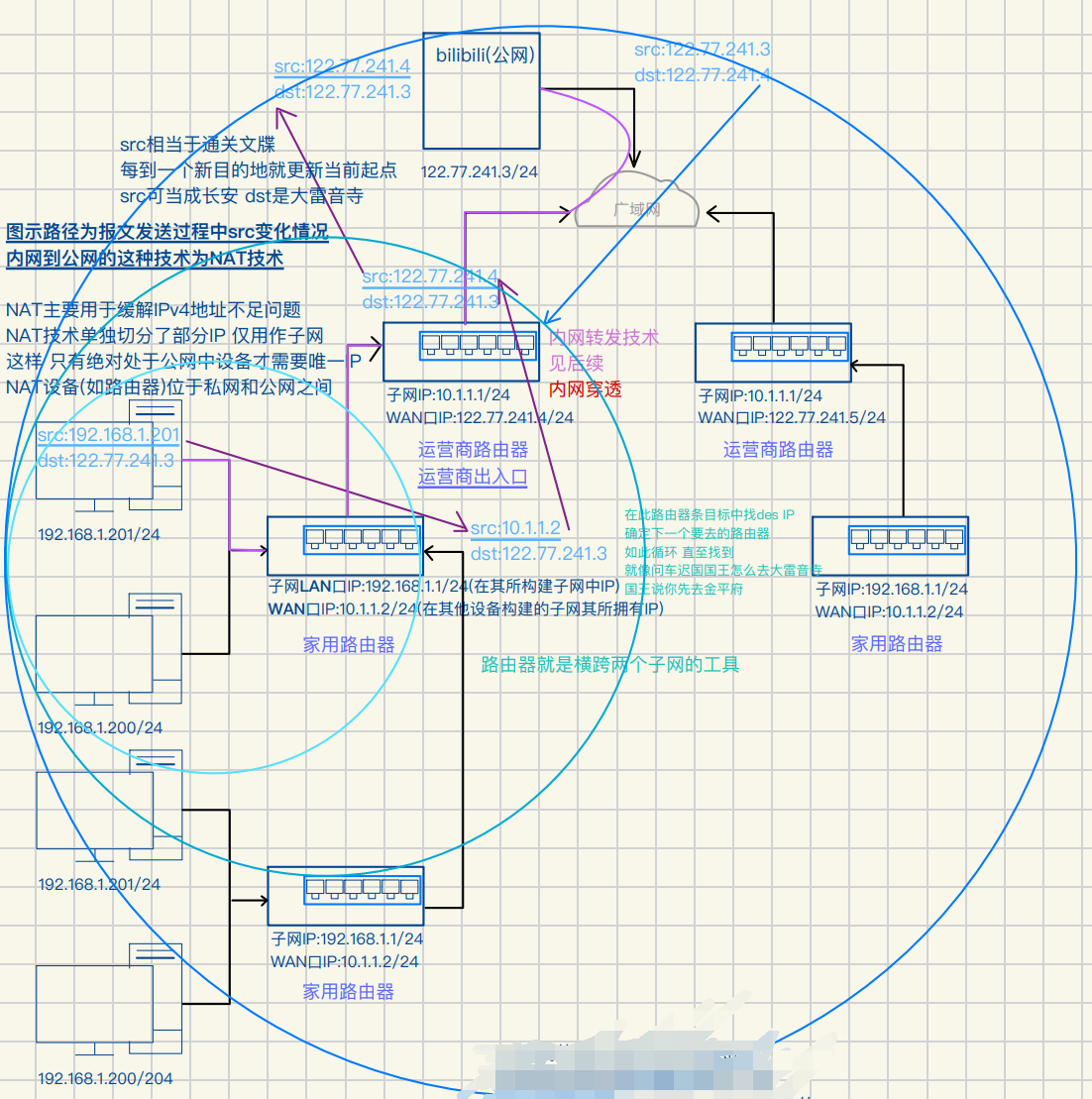
1:普通路由器不会存储所有公⽹IP的路径
只存"如何到达下⼀跳"的信息
2:家庭/公司路由器只存本地⽹络和默认路由
它们根本不知到具体的公⽹服务器IP地址如何到达
3:ISP和⻣⼲⽹路由器存储全球BGP路由表
但它们存的是⼤块IP前缀的路由信息
⽽不会存单个主机的路径
4:IP数据包的转发是逐跳(Hop-by-Hop)进⾏的
每个路由器只负责找到下⼀跳,⽽不是提前计算整个路径
1.互联⽹的路径是预先规划好的吗?
不是完全规划好的,⽽是动态学习的!
2.路由器是如何知道其"下⼀跳"是有效的
(1).路由器主要通过路由协议来学习和维护可达的路径
这些协议可以分为内联⽹关协议(IGP)和外部⽹关协议(EGP)
常⻅协议有:
RIP(路由信息协议):⽼旧,基于"跳数"选择路径
OSPF(开放最短路径优先):基于Dijkstra算法,计算最优路径
IS-IS(中ᳵ系统-中ᳵ系统):ISP内部⼴泛使⽤
(2).如何⼯作
邻居发现:路由器会定期向周围的路由器发送Hello消息,确保对⽅在线(爬⾍)
路径计算:每个路由器会计算从⾃⼰到所有⽬标的最佳路径
动态更新:如果某条路径故障,路由表会⾃动更新
公⽹(全球⽹络)
本质就是对全球IP进⾏划分的过程
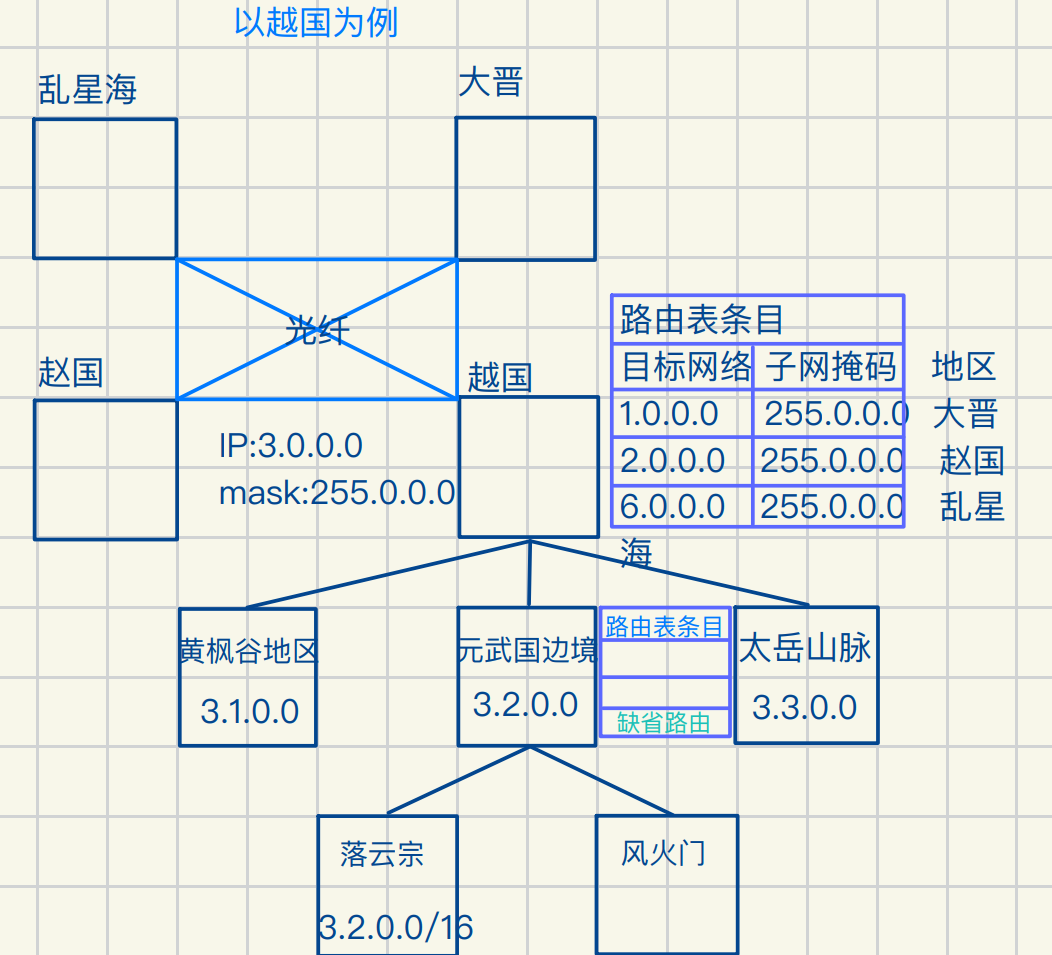
⽹络通信必须经过带有公⽹ip的服务器
这就是为什么我们需要qq微信
登录同⼀台公⽹IP服务器
ps:申请公⽹IP以组织为单位(如落云宗公⽹IP)
由IANA统⼀进⾏分部 管理
如果路由表中没有⽬标怎么办
缺省路由(Default Route)是⽹络路由中的⼀种特殊路由
⽤于在路由表中找不到匹选项时提供默认的去向
它们常⽤于处理⾮本地或未知⽬的地址的流量
指向⼀个默认的下⼀跳⽹关
数据链路层和以太⽹协议
数据链路层作用
数据᱾路层解决相邻主机直接通信问题
「⽹络层」和「数据链路层」间关系
就是唐僧和⽩⻰⻢
以太⽹
不是具体⽹络 ⽽是⼀种技术标准
是⼀种软硬件结合的协议
以太⽹的⽹线必须是双绞线
它是当前最⼴泛使⽤的局域⽹技术协议
以太⽹帧格式

1.Preamble(前导码)和SFD(起始定界符)在以太⽹帧的最前⾯,主要⽤于同步和标识帧的开始
Preamble使⽤0xAA字节来标记数据流的开始,SFD字段标识帧的开始(固定值 0xAB)
2.Destination MAC Address和Source MAC Address
⽤于标识⽹络中接收⽅和发送⽅的硬件地址(MAC地址)
每个MAC地址是⼀个48位(6 字节)地址
3.Type/Length字段表示数据的类型或长度,常⻅的类型值有:
0x0800:IPv4
0x0806:ARP
0x86DD:IPv6
0x8847:MPLS
...⽤于确定将报⽂传递给上层哪个协议
4.Data 字段是实际承载的数据,长度可以变化,通常包含上层协议数据(如IP数据包)
5.FCS(帧校验序列)是⼀个4字节的CRC校验码,⽤于检查数据传输中的错误
MAC地址:mac地址是当前地址或下⼀跳地址
作⽤:位于⽹卡层⽤于识别数据᱾路层中相ᬳ的节点 仅可⽤于局域⽹通信
MTU对UDP影响
MTU对UDP影响设MTU=20
⼀旦UDP携带的数据超过1472(1500-20(IP⾸᮱)-8(UDP⾸部)),那么⽹络层会分成多个IP数据报
但此IP数据报有任意⼀个丢失,那会引起⽹络层重组失败,所以UDP的数据报分⽚使重传的概率增⼤
MTU对TCP影响
TCP数据报⼤⼩受制于MTU TCP单个数据报最⼤消息长度,成为MSS(Max Segment Size)
TCP建⽴时,送信双⽅会进⾏MSS协商
双⽅发送SYN时会进⾏协商在TCP头部写⼊⽀持的MSS值
得知双⽅的MSS后,会取较⼩的MSS位最终值
IP地址和MAC地址的区别和联系
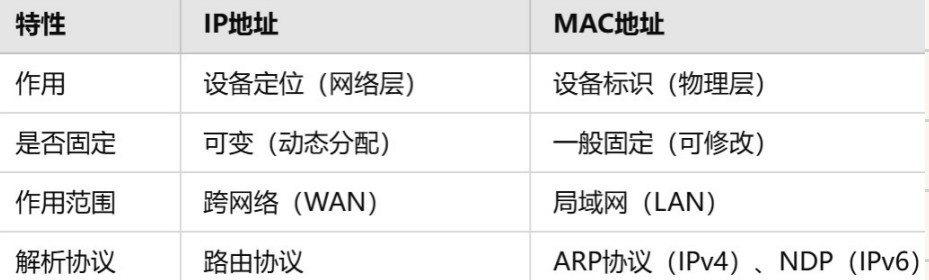
由于⽹络是临界资源 所以任何时刻仅容许⼀台主机发送的信号
涉及和别的主机发⽣碰撞 那么碰撞的主机会进⾏休眠 让数据链路层重发
整个局域⽹ 我们可称其为碰撞域 所以⼀个碰撞域中主机越少越好
单主机发送数据帧应尽量短[45,1500]
如何骇⼀个局域⽹?不断向局域⽹发送垃圾数据,⽆条件触发碰撞
映射关系:
局域⽹中,IP地址通过ARP(地址解析协议)映射到MAC地址
设备需要知到⽬标MAC地址才能正确发送数据包
传输过程:
发送端根据⽬标IP查找⽬标MAC(ARP请求)
数据包在局域⽹内根据MAC地址传输
如果数据包要跨⽹传输,会经过路由器,路由器使⽤IP地址决定下⼀跳
但每⼀跳的MAC地址那可能改变
收到的报⽂会在数据链路层进行MAC地址核实 如果不是就直接丢弃
如何缓解碰撞问题?交换机划分交换域
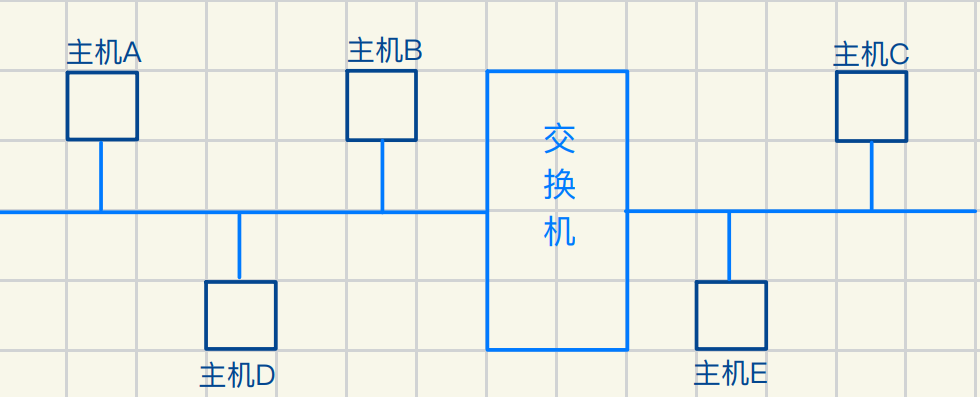
ABD组成⼀个碰撞域,CE组成⼀个碰撞域
如果A要发送数据给D,数据会先交给交换机
交换机发现AD在⼀个碰撞域,就将数据转发给主机D
这样就避免了和CD所形成的碰撞域发⽣碰撞
ARP协议(地址解析协议)
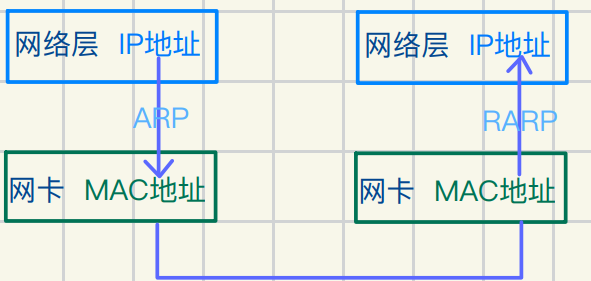
数据报发送主要依靠IP路由
但实际转发依赖于⽹卡层MAC地址
先看op 是请求还是应答
ARP 过程
发送ARP请求(ARP Request):
发送⽅(主机A)想要知道⽬标IP地址(主机B)的MAC地址
发送⽅会构成⼀个ARP请求数据包
并使⽤⼴播(MAC地址FF:FF:FF:FF:FF:FF)在局域⽹内发送该数据包
接收并响应ARP 请求(ARP Reply):
⽬标设备(主机B)收到ARP请求后,检查其中的⽬标IP地址是否与⾃⼰的IP地址匹配
如果匹配,主机B构成⼀个ARP应答包(ARP Reply)
其中包含⾃⼰的MAC地址,并以单播(unicast)⽅式发送回给主机A
缓存 ARP 信息并送信:
发送⽅(主机A)收到ARP应答后,会将⽬标的MAC地址缓存到⾃⼰ARP表中
以便后续送信时⽆需再次发送ARP请求
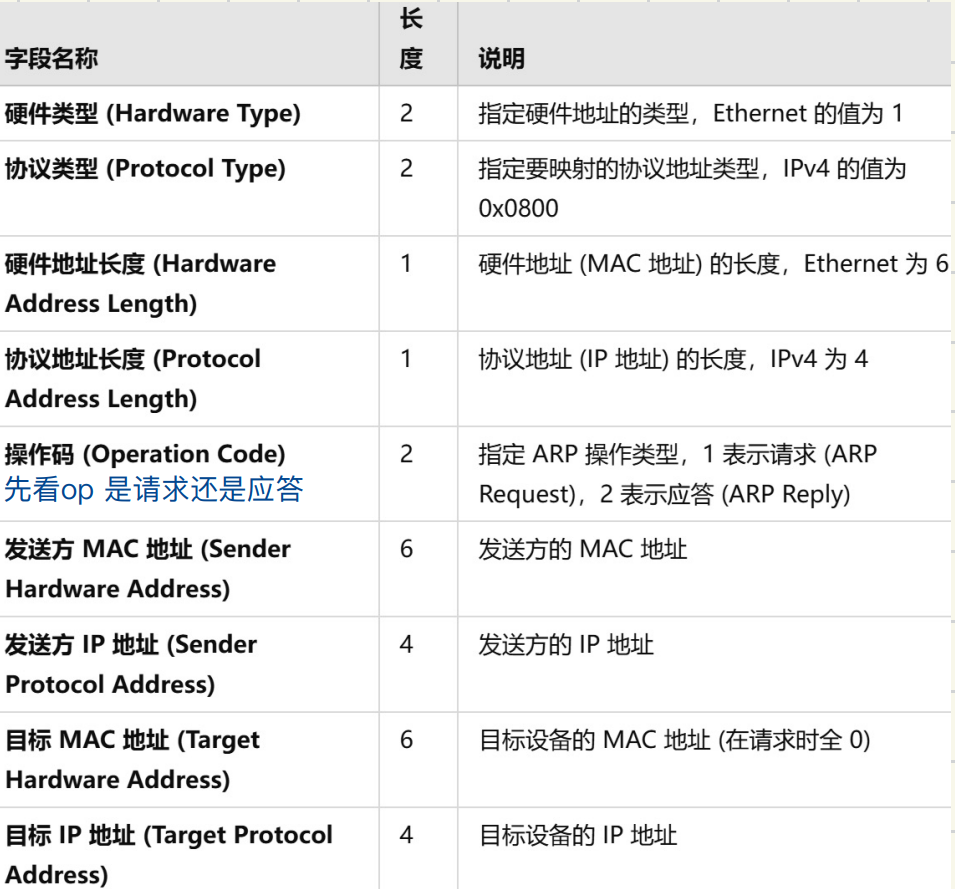


NAPT转换表
内网穿透
内⽹穿透(NAT穿透)是⼀种技术,⽤于突破 NAT(⽹络地址转换)或放⽕墙的机制
使得位于私有⽹络(内⽹)中的设备能够直接与外部⽹络进⾏通信
由于⼤多数家庭或企业⽹络都使⽤路由器进⾏ NAT,这会导致外⽹⽆法直接访问内⽹设备
内⽹穿透技术通过各种⽅式解决了这个ᳯ题,常⻅的应⽤场景包括远程访问,视频监控,即时通讯等
内⽹打洞
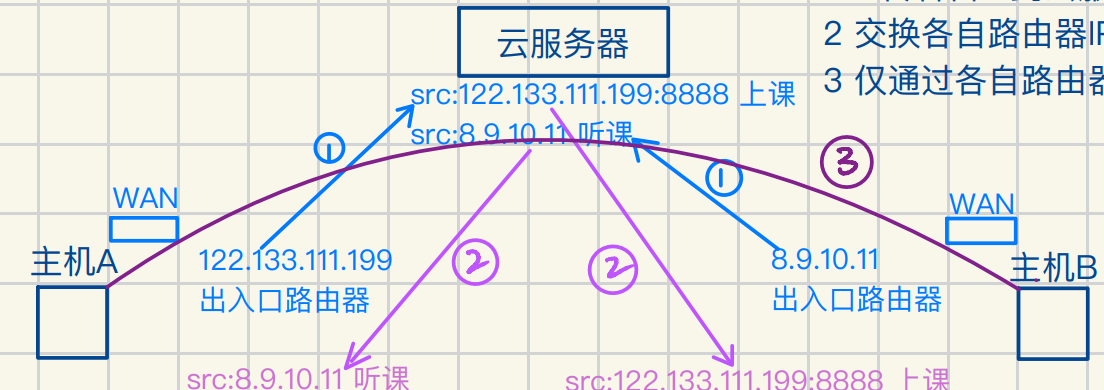
1 上传各⾃IP到云服务器
2 交换各⾃路由器IP
3 仅通过各⾃路由器进⾏通信 完成内⽹打洞
P2P模式概述 Peer-to-Peer
如果甲要在某视频⽹站下载电影A
且⼄正好在看此电影
⽹络打洞会将甲⼄的路由器连接形成通道
使⼄看电影的同时也将数据推送给甲下载
此时⼄即是客户端 也是服务器
代理服务器
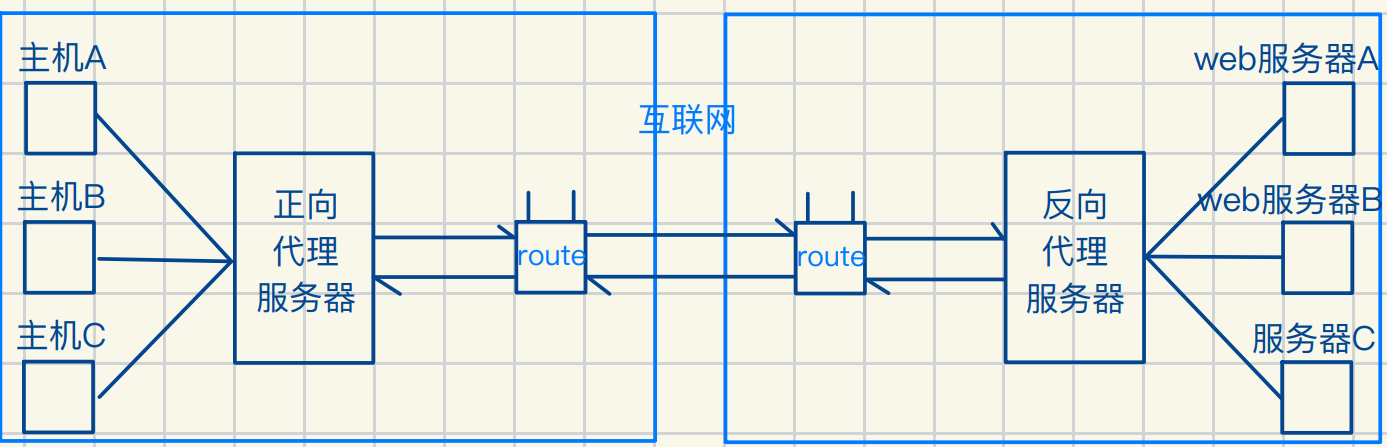
NAT和代理服务器区别和联系
NAT位于路由器中 属于⽹络层
代理服务器属于应⽤层
代理服务器通过充当客户端和⽬标服务器之间的中介
提供多种功能,包括匿名访问,内容过滤,缓存加速,安全性增强等
相当于⼀个⽤于路由器和主机之间传递数据的中间⼈
可以对资源进⾏缓存 优化上⽹体验
客户端发出请求会互联⽹会将此请求给反向代理
反向代理再分配给服务器
防⽕墙突破—欺骗运营商路由器
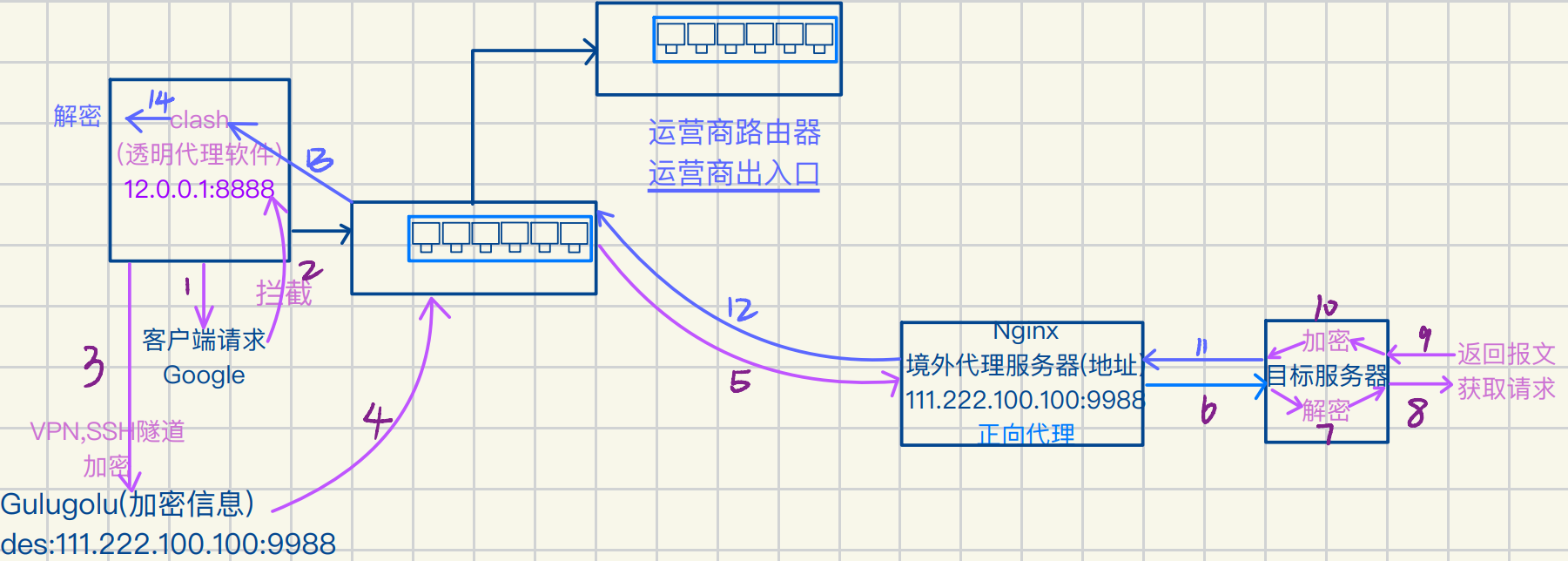
由于威权管控愈加严格
运营商路由器发现异常报⽂会直接丢弃
所以开发商会买复数台代理服务器
打开clash,会有HongKong代理1,新加坡代理2…
⼀台被封死换另⼀台,针对防⽕墙GFW,IP封锁
提供更多流量⼊⼝,增加访问成功率
DNS
Domain Name System
域名会被DNS转换成IP地址
com:⼀级域名,表示机构性质
baidu:⼆级域名,表示具体机构
根域名服务器(Root Name Servers)是 DNS(域名系统)的核⼼组成部分
负责将域名解析为IP地址的最顶层的服务器
它们在全球范围内提供域名解析服务
确保整个互联⽹的域名解析体系能够正常运作
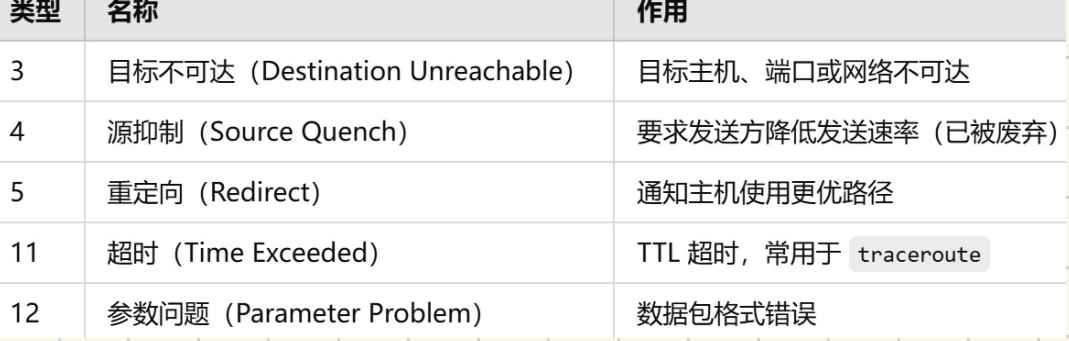
ICMP

ICMP是⽹络层协议
会通知出错原因
⽤于在⽹络设备(如路由器主机)之间传递控制信息
帮助诊断和管理 IP ⽹络的通信状况
它主要⽤于报告⽹络错误,测试联通性和提供调试信息
ping ww.baidu.com 测试是否能进⼊此⽹址 若不能 返回错误
IO的简介和阻塞⽅式的介绍以及对IO阻塞⽅式的控制⽅法介绍
I/O操作中,通常可以分解为两个主要阶段:
I/O 操作的时ᳵ = 等待数据的时ᳵ + 复制数据的时间
等待数据 (Wait)
例如,读取⽂件时,操作系统需要从磁盘加载数据到内核缓冲区,这个过程可能涉及等待(例如磁盘I/O,⽹络I/O)
这个ᴤ段可能会导致线程阻塞,特别是在同步I/O模型下
拷⻉数据 (Copy)
数据从内核缓冲区复制到⽤户态缓冲区(例如 read()系统调⽤)
这个数据拷⻉过程也需要时间,尤其是在⼤量数据传输时会影响性能。
其中,等待时间占主要⽐重,
⾼效IO就是单位时间内⼤⼤减少等待时间
建⽴链接后进程需要⼀直阻塞等待
等待<--->不等待 有条件变化
1阻塞和⾮阻塞
1.1阻塞是⽆论buffer有⽆数据都会等待
1.2⾮阻塞是buffer⽆数据就⽴即返回,有数据才拷⻉
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* 可变参数 */);
⽂件描述符控制函数,可以修改I/O⾏为,设置⽂件锁,管理进程信号...
fd:要操作的⽂件描述符
cmd:控制命令,决定 fcntl 执⾏什么操作
F_GETFL:获取 fd 的⽂件状态标志(如 O_NONBLOCK)
F_SETFL:设置 fd 的⽂件状态标志
...:根据cmd可能需要提供额外的参数
2信号驱使
通过信号(signal)来通知进程I/O事件的发⽣,⽐如某个⽂件描述符(socket⽂件等)变得可读或可写
3多路转接/复⽤
⼀个监测者同时监测多个IO进程,谁有数据就拷⻉谁
4异步I/O
异步I/O的核⼼就是先让进程先提交I/O请求,OS负责执⾏I/O操作,进程则继续执⾏其他任务,不会被I/O阻塞
当 I/O完成后,OS会通知进程,进程再回来处理数据
异步IO效率最⾼,但也是最受ᴴ于平台的
同步I/O vs 异步I/O
同步I/O:进程在发起I/O请求后,必须等待I/O完成后才能继续执⾏后续操作
异步I/O:进程在发起I/O请求后,⽴即返回并继续执⾏其他任务,I/O由OS负责处理,完成后通知进程
控制IO⾏为
阻塞和⾮阻塞
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* 可变参数 */);
⽂件描述符控制函数,可以修改I/O⾏为,设置⽂件锁,管理进程信号...
fd:要操作的⽂件描述符
cmd:控制命令,决定 fcntl 执⾏什么操作
F_GETFL:获取 fd 的⽂件状态标志(如 O_NONBLOCK)
F_SETFL:设置 fd 的⽂件状态标志
...:根据cmd可能需要提供额外的参数
select系统调用
#include <sys/select.h>
#include <sys/time.h>
int select(int nfds, fd_set *readfds,fd_set *writefds, fd_set *exceptfds,struct timeval *timeout);
作⽤:允许进程同时监听多个⽂件描述符(如socket,pipe,⽂件)
并在其中任意⼀个变为可读/可写时返回,从⽽避免阻塞等待单个I/O事件
fe_set:是使⽤bitmap实现的集合数据类型,OS给⽤户提供的数据类型,可以添加多个⽂件描述符
其每⼀个fd对应⼀个⼆进制位
使⽤位图这⼀数据结构来保存0,1,2,3...,向select传递这些数据
nfds:输⼊输出型参数,⽂件描述符的最⼤值 +1(即max_fd+1)
输⼊时:⽤户告诉内核,哪些fd被设置成可读
⽐特位位置:fd具体编号
⽐特位内容:是否关⼼
输出时:内核通知⽤户,在⽤户关⼼的readfds中,谁已就绪
fd :0123 4567
状态:0000 0010:fd=7的读事件已就绪
总结,在admin要关⼼的fd中,fd=max{fd},且nfds=max{fd}+1
readfds:这是⼀个指针,监听可读事件的fd_set指指针(若不关⼼填NULL)->buffer是否有数据
writefds:监听可写事件的fd_set 指针(若不关⼼填 NULL)->buffer是否有space
⽐特位位置:fd具体编号
⽐特位内容:是否就绪 对已就绪的fd进⾏IO读取 读取⼀次⼀定不会被阻塞
exceptfds:监听异常事件的fd_set 指针(通常⽤于OOB数据(带外数据))⼀般填 NULL->fd是否正确
这三个参数意义是将指定fd设置进⼊某个集合
timeout:
NULL:阻塞等待(直到某个 fd 发⽣事件)。
{0, 0}:⽴即返回(⾮阻塞模式)。
{sec, usec}:等待指定时间,超时后返回。
就绪:
读就绪:底层有数据
写就绪:底层有空间
select的优缺点
每次调⽤select之前都要进⾏参数重置,接⼝使⽤不⽅便
每次调⽤select都要在内核遍历所有的fd,开销较⼤
⽀持的fd数量较少
返回值
> 0:有I/O事件发⽣,返回就绪的fd数量
= 0:超时,⽆事件发⽣
-1:出错,errno记录错误原因
注意:每次调⽤select之前,我们都需要将位图重新设置
因为我们给了select⼀张位图之后它会将位图进⾏更改给我们⼀张全新的位图
也正因如此,我们也需要⼀个辅助数组将历史的所有⽂件描述(fd)保存起来
说⽩了select就是使⽤位图readfds来表示哪些fd上的哪些数据已经就绪
ps:常辅助select函数⼀起使⽤的接⼝
FD_ZERO(&fd_set):清空⽂件描述符集合fd_set,即将集合中的所有位设置为0
FD_SET(fd, &fd_set):将⽂件描述符fd加⼊到fd_set集合中,表示该⽂件描述符在select函数检查时应该被关注
FD_CLR(fd, &fd_set):从fd_set集合中移除⽂件描述符fd,即表示该⽂件描述符不再被select关注
FD_ISSET(fd, &fd_set):检查⽂件描述符 fd 是否在 fd_set 集合中
位图bitmap简介
位图的核⼼思想是使⽤**位数组(bit array)**来表示数据,每⼀位(bit)只有两种状态:
0:通常表示"不存在"或"关闭"
1:通常表示"存在"或"开启"
所以,具体关⼼两个⽅⾯,1:⽐特位位置表示(⽂件描述符)fd具体编号 2:⽐特位内容表示是否关⼼
例如,假设要存储0~15这16个整数,并且只存储其中的{1, 3, 4, 8, 12, 15}:
索引: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
位图: 0 1 0 1 1 0 0 0 1 0 0 0 1 0 0 1
// 位图结构体
typedef struct {unsigned char *bits; // 存储位的数组size_t size; // 位的总数
} Bitmap;
为什么使⽤结构体对数组封装?为了防⽌数组传参可能发⽣的降维问题
fd_set
代码⼤致如下
typedef struct {unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} fd_set;fd_set:就是⼀个struct+数组的位图
fd_set:就是⼀个具体数据类型,其⼤⼩固定,表示其可包含的fd个数有上ᴴ(可管理⽂件描述符(fd)为1024个)
fd_set 是 select() 的⽂件描述符集合,主要⽤于监视多个⽂件描述符的状态(可读,可写,异常)
需要配合 FD_ZERO、FD_SET、FD_CLR、FD_ISSET 进⾏操作。
受 FD_SETSIZE ᴴ制,不ᭇ合⾼并发场景,᭗常在现代开发中被 poll() 和 epoll() 取代。
所以说select可管理的fd有上ᴴ
得出结论--->poll,epoll
--->上限是多少
epoll多路转接简介与常⽤接⼝
poll⽤于检查多个⽂件描述符(通常是⽤于 I/O 操作的)是否就绪
是否可以执⾏某些操作(如读,写,异常处理等)它᭗常在事件驱动的程序设计中使⽤
尤其是在需要处理多个I/O流(如⽹络ᬳ接)的情况下
所以说poll就是"select+"
poll是为了select存在的fatalᳯ题
1.输⼊输出参数是⼀个bitmap,导致参数每次都需要重置
2.等待的fd个数有上ᴴ
所以poll可以做到将输⼊输出参数进⾏分离同时其可等待的fd没有上ᴴ
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
fds:指向⼀个 pollfd 结构体数组的指ᰒ.每个pollfd结构体表示⼀个待监控的⽂件描述符及其相关事件
struct pollfd {int fd; // ⽂件描述符short events; // 表示此fd是否就绪的标记short revents; // 发⽣的事件类型};events:指定感兴趣的事件类型,可以是以下之⼀或多个的组合(按位或):
(ps:这些事件都是宏,short类型可以⽤来表示bitmap)
POLLIN:⽂件描述符可读(数据可⽤)//#define POLLIN
0x001
POLLOUT:⽂件描述符可写(可以写⼊数据)
POLLERR:⽂件描述符发⽣Კ误
POLLHUP:⽂件描述符被挂起
POLLNVAL:⽂件描述符⽆效
events:表示期望的⽂件描述符功能或状态(如⽂件描述符是否可读,可写等)
它是你对⽂件描述符的"需求"
revents:返回的事件类型,表示实际发⽣的事件.这个字段会由poll()填充
综上所述
revents:表示⽂件描述符是否就绪,也就是实ᴬ发⽣的事件类型
它反映了⽂件描述符的当前状态,即是否满⾜你在events中设置的条件(如是否可读,是否可写等)
nfds:fds 数组中的元素个数,也就是需要监控的⽂件描述符数量
timeout:等待事件发⽣的时间,单位为毫秒.timeout 的值可以有三种情况:
正数:表示等待的最⼤时间(ms),如果在此时ᳵ内没有事件发⽣,则返回
0:表示⾮阻塞模式,即⽴即返回,检查是否有事件
-1:表示阻塞模式,poll()将会⼀直等待直到有事件发⽣或被信号中断
返回值:
n>0:有n个fd就绪
n=0:timeout
n<0:error
EpollServer常⻅接⼝简介
epoll和poll select⼀样,都是就绪事件通知机制
int epoll_create(int size);
功能:创建⼀个epoll模型
size:已废弃,但是必须>0
成功返回值:fd
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
功能:向epoll中添加要关⼼的事件,admin告诉内核想要关⼼的fd的事件
作⽤说明:向指定的epoll模型epfd(epoll_create返回值)中"增删改(op)"指定fd上的指定事件event
epfd:通过epoll_create或epoll_create1 创建的epoll⽂件描述符
op:操作类型,以下是常⽤的操作:
EPOLL_CTL_ADD:将⽂件描述符fd加⼊到epoll实例中进⾏监听
EPOLL_CTL_MOD:修改已经添加的⽂件描述符fd的监听事件
EPOLL_CTL_DEL:从epoll实例中删除⽂件描述符fd
fd:需要添加,修改或删除的⽂件描述符
event:描述⽂件描述符的事件类型,struct epoll_event 类型,定义如下:
输⼊输出型参数
struct epoll_event {__uint32_t events; // 表示输⼊输出时代表的事件epoll_data_t data; // 关联的数据(᭗常是⽂件描述符)};events=:宏(marco)
EPOLLIN:有数据可读
EPOLLOUT:可以写数据
EPOLLERR:发⽣错误
EPOLLHUP:挂起状态
EPOLLRDHUP:远程挂起(即远程关链接)
EPOLLET:边缘触发模式(Edge-Triggered)在此模式下,事件只会在⽂件描述符的状态发⽣变化时通知⼀次
typedef union epoll_data {void *ptr; // ⽤户⾃定义的指ᰒint fd; // ⽂件描述符uint32_t u32; // ⽆符号 32 位整数uint64_t u64; // ⽆符号 64 位整数} epoll_data_t;※MAIN POINT:事件中,admin应重点关注的是
epoll_event.events(事件类型)
epoll_data_t.fd(⽂件描述符)
综上:_epfd是epoll_create的返回值,这个函数需要重点关注的是struct epoll_event *event
返回值:成功返回0,失败-1
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
功能:⽤于等待事件的发⽣,并返回已就绪的⽂件描述符
作⽤说明:
epfd:由epoll_create或epoll_create1创建的epoll实例的⽂件描述符
events:输出型参数,告诉admin所关⼼的fd上哪些事件已就绪
maxevents:events数组的最⼤容量,epoll_wait最多返回maxevents个事件
timeout:等待时间