H2数据库源码学习+debug, 数据库 sql、数据库引擎、数据库存储从此不再神秘
一、源码结构概览
H2源码采用标准Maven结构,核心模块在src/main/org/h2目录下:
├── command/ # SQL解析与执行
├── engine/ # 数据库引擎核心(会话、事务)
├── table/ # 表结构定义与操作
├── index/ # 索引实现(B-Tree、MVCC)
├── store/ # 存储引擎(页管理、日志)
├── jdbc/ # JDBC驱动实现
├── mvstore/ # MVStore存储引擎(v1.4+)
├── expression/ # SQL表达式处理
└── util/ # 工具类(缓存、字符串处理)
二、核心模块深度解析
1. SQL解析与执行(command包)
-
解析流程:通过手写递归下降解析器(
Parser.java)将SQL语句转换为抽象语法树(AST)。// 示例:解析SELECT语句
public Prepared parseQuery() {
Prepared prep = readQuery();
prep.prepare();
return prep;
} -
查询优化:
Query类处理逻辑优化,Optimizer负责选择执行计划(如索引选择)。
2. 存储引擎(store包)
-
页式存储:
PageStore类管理数据页(默认4KB),支持B-Tree索引结构。- 页类型:数据页、索引页、空闲列表页
-
事务日志:
WriteAheadLog实现WAL机制,确保ACID特性。// 日志写入示例
wal.logRecord(Loggable.TRANSACTION_LOG, data);
3. MVCC与事务管理(engine包)
-
多版本控制:
TransactionStore跟踪数据版本,通过Row的版本链实现快照隔离。 -
锁机制:
LockManager管理行级锁,Session隔离级别控制可见性。// 事务提交关键代码
session.commit(false);
4. 索引实现(index包)
- B-Tree索引:
PageBtreeIndex实现范围查询优化。 - 哈希索引:
NonUniqueHashIndex用于等值查询加速。 - MVStore索引:新版MVStore采用跳跃表结构(
org.h2.mvstore)。
三、关键设计亮点
-
双存储引擎支持:
- 传统
PageStore(兼容性优先) - 新版
MVStore(高并发优化,K/V设计)
- 传统
-
内存优化技术:
- 对象池化(
ValuePool重用常用对象) - 延迟反序列化(
DataPage按需加载列)
- 对象池化(
-
查询编译缓存:
// 缓存已编译的查询计划
Prepared prep = cache.get(sql);
if (prep == null) {
prep = parse(sql);
cache.put(sql, prep);
}
四、调试与学习建议
- 入口跟踪:从
org.h2.command.Parser的parse()方法开始,跟踪SQL执行全流程。 - 单元测试:运行
test目录下的TestAll,观察功能测试用例。 - 可视化工具:结合H2 Console调试SQL执行计划(
EXPLAIN ANALYZE)。
具体debug 过程如下:
下载源码:
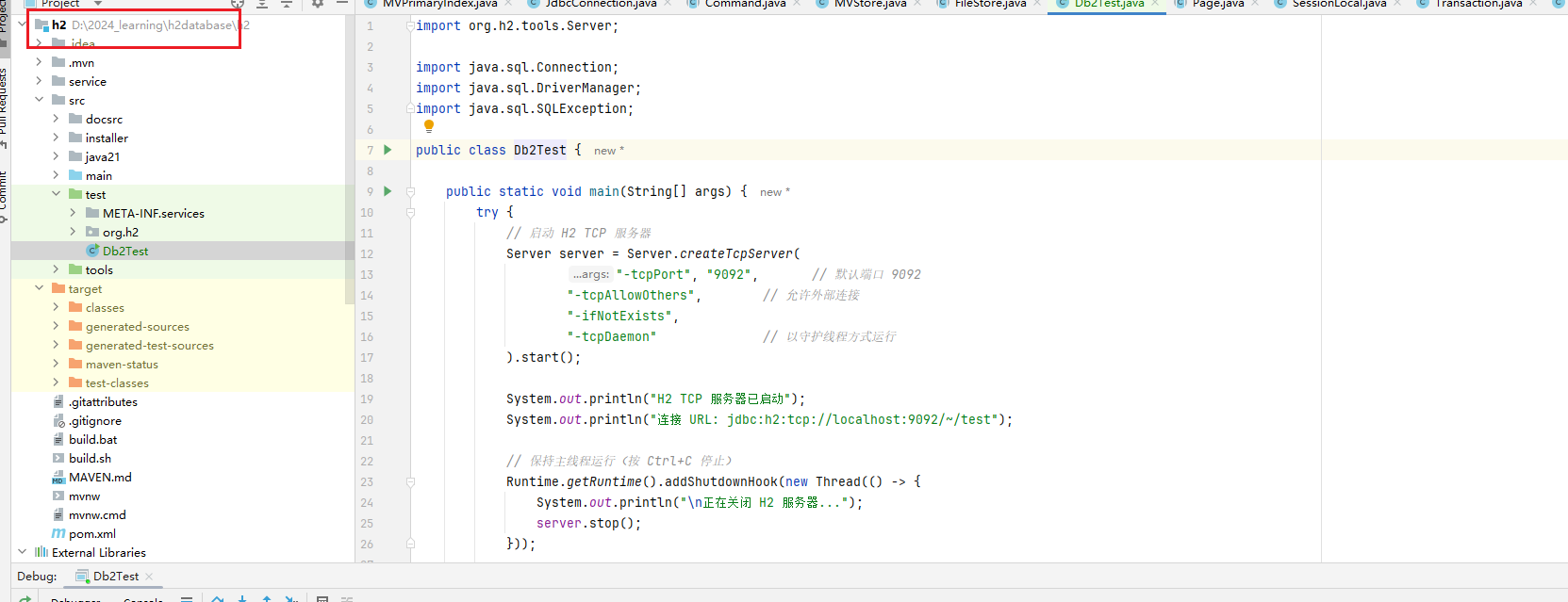
TCP 模式启动H2 server
public static void main(String[] args) {try {// 启动 H2 TCP 服务器Server server = Server.createTcpServer("-tcpPort", "9092", // 默认端口 9092"-tcpAllowOthers", // 允许外部连接"-ifNotExists","-tcpDaemon" // 以守护线程方式运行).start();System.out.println("H2 TCP 服务器已启动");System.out.println("连接 URL: jdbc:h2:tcp://localhost:9092/~/test");// 保持主线程运行(按 Ctrl+C 停止)Runtime.getRuntime().addShutdownHook(new Thread(() -> {System.out.println("\n正在关闭 H2 服务器...");server.stop();}));Thread.currentThread().join(); // 阻塞主线程} catch (SQLException | InterruptedException e) {e.printStackTrace();}}
DBeaver 连上数据库
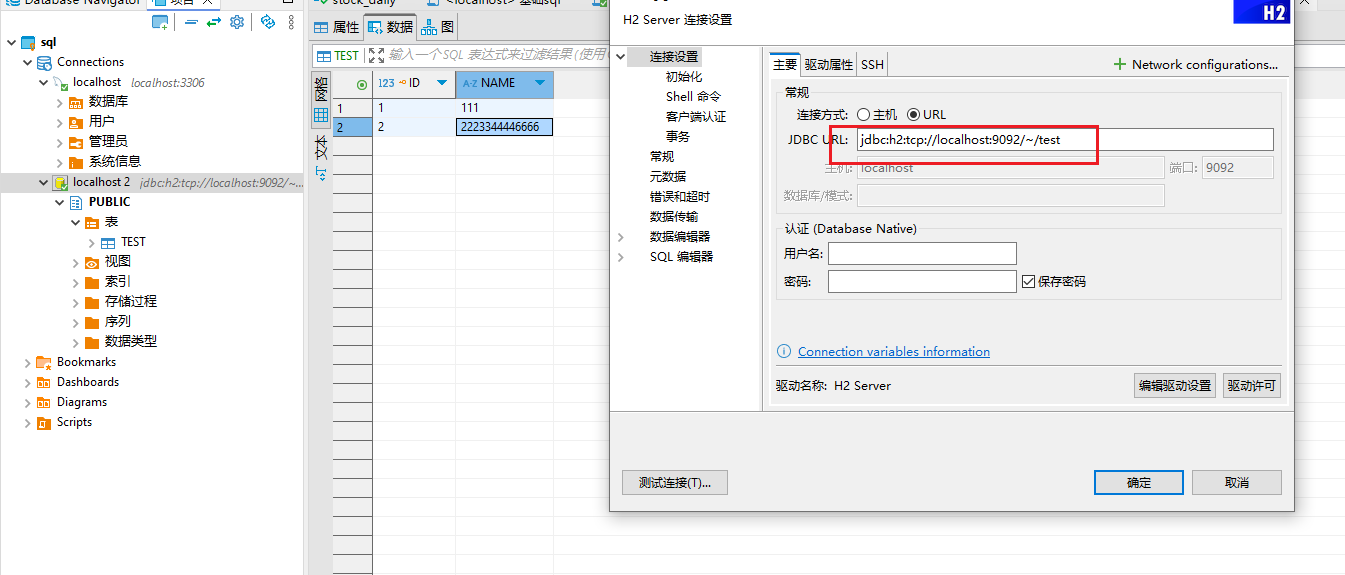
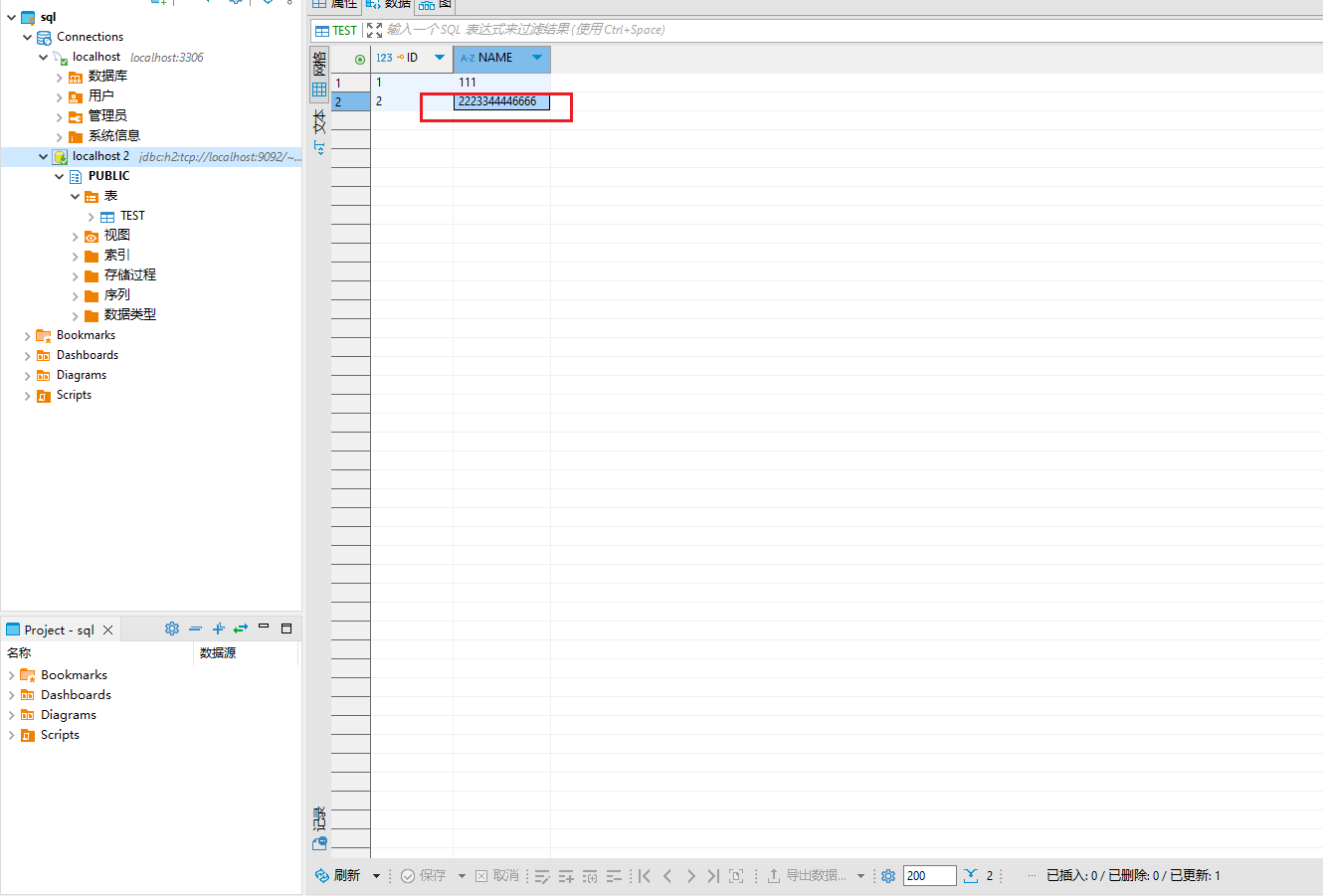
建表,插入数据
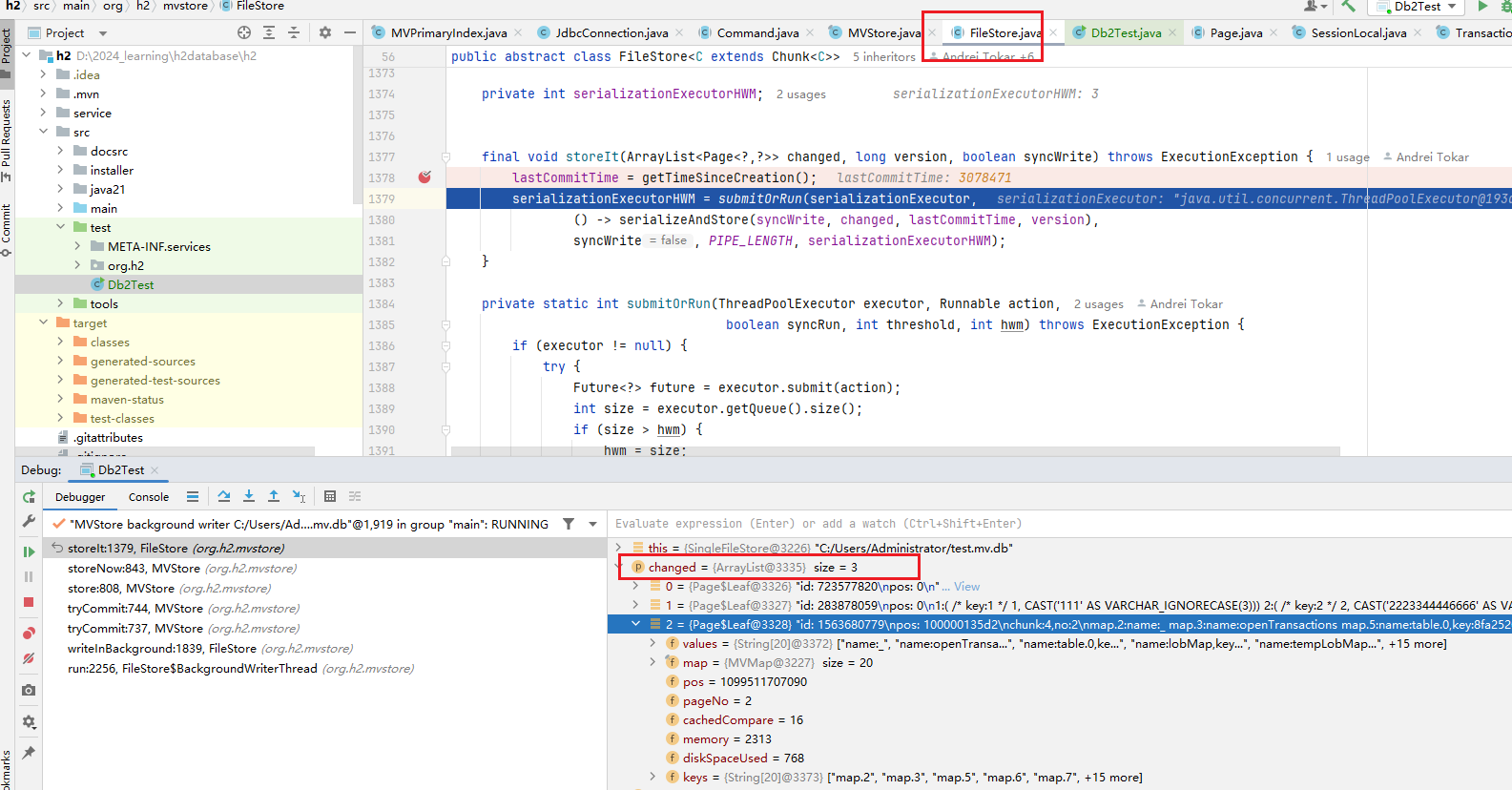
加断点, debug insert 过程
五、性能优化案例分析
场景:高频写入导致锁争用
源码定位:org.h2.table.RegularTable的addRow()方法
优化方案:
// 调整批量提交策略
connection.setAutoCommit(false);
for (Row row : batch) {
table.addRow(session, row);
if (count++ % 1000 == 0) {
session.commit();
}
}