【论文阅读】人脸修复(face restoration ) 不同先验代表算法整理2
文章目录
- 一、前述
- 二、不同的先验及代表性论文
- 2.1 几何先验(Geometric Prior)
- 2.2 生成式先验(Generative Prior)
- 2.3 codebook先验(Vector Quantized Codebook Prior)
- 2.4 扩散先验 (Diffusion Prior)
- 2.5 参考人脸的先验(Reference Prior)
一、前述
人脸修复(face restoration)任务,起源于人脸超分辨率(face super resolution),可以算是从超分出来的一个分支。作为图像低级任务(low level)中的一个,主要目的就是在低清、受损画质中尽可能的恢复人脸细节。与传统的全图超分的区别在于,人脸是有明确的先验知识在里面的,可以利用这些先验增加模型的信息量,尽可能的恢复人脸的细节。这些先验可以包括面部特征,也称为几何先验(Geometric Prior),有基于高清参考人脸的先验(Reference Prior) ,有基于强的生成器先验(Generative Prior),也有基于离散的codebook的先验(Vector Quantized Codebook Prior),当然,还有近几年爆火的diffusion,作为强的文生图基本模型,他可以作为一种扩散先验(Diffusion Prior)。
论文整理链接:
https://blog.csdn.net/weixin_43707042/article/details/147993213?spm=1011.2124.3001.6209
或
https://github.com/qianx77/Face_Restoration_Ref
整理下各个先验个人觉得比较有代表性的论文。
二、不同的先验及代表性论文
2.1 几何先验(Geometric Prior)
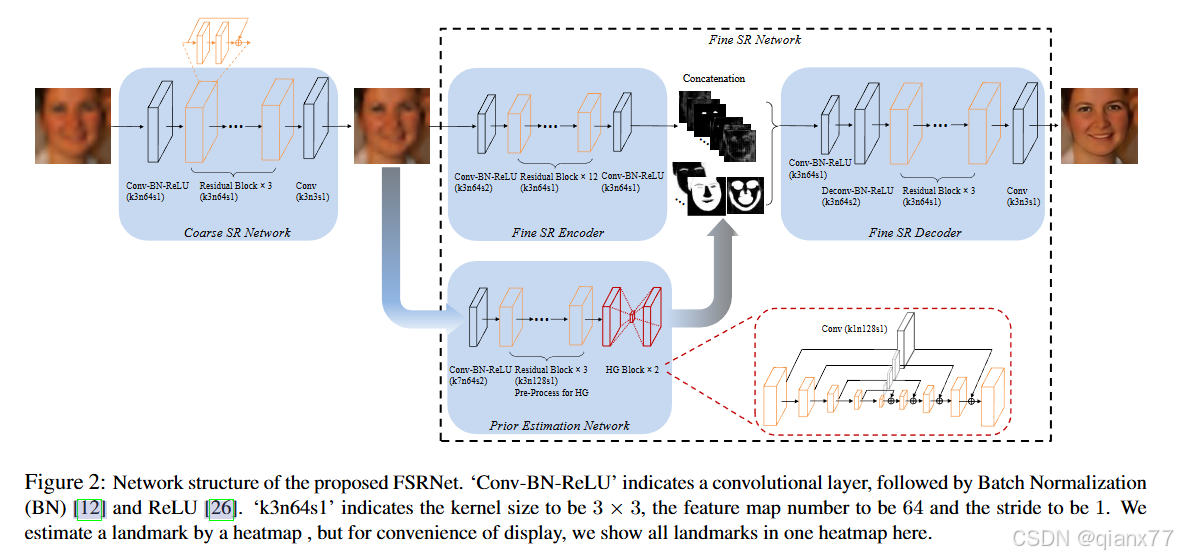
要回答什么是几何先验,可以先问一下,人脸超分比全图超分优势点在哪里?直观感受就是人脸有比较统一的分布规律,例如,正常的人脸都有一个嘴巴、一个鼻子、一双眼睛、有眉毛、有额头等等,这些器官在每个人身上都是不一样的,但是大体形状又是一样的。因此可以利用这些特点来增强人脸的细节。这方面的代表性论文有2018 年 CVPR的FSRNet,利用额外的网络结构预测parsingmap,然后利用parsingmap辅助人脸恢复。
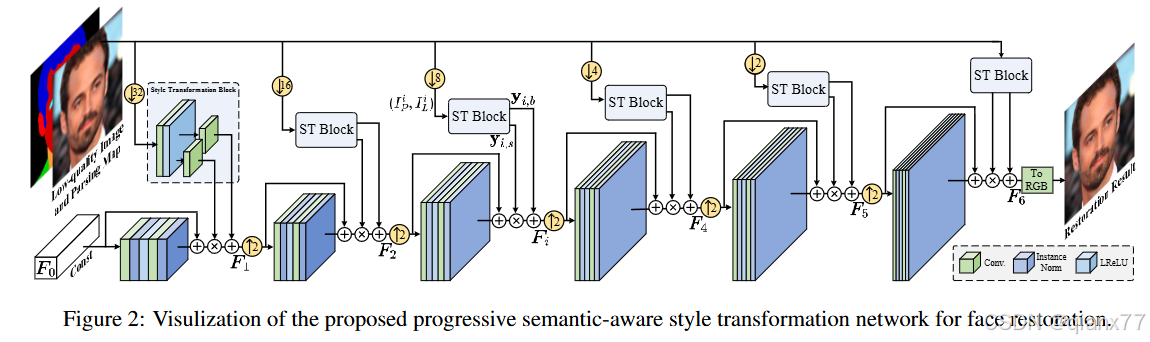
在2023年之前我觉得这方面效果最好的当属2021 CVPR PSFRGAN 主要思想其实是借鉴PGGAN、Stylegan这种渐进式生成的启发,从小尺度到大尺度生成图像,然后在这期间使用LQ image 和 parsingmap作为引导,利用style transformation block,将信息嵌入backbone。
但是我在实际使用中发现,如果LQ的图像太差,影响了parsingmap的提取,错误的parsingmap会对整体恢复效果产生不好的影响。
2.2 生成式先验(Generative Prior)
生成式先验得益于stylegan的发展,stylegan是一个强大的生成器,可以生成十分逼真的图像,如果使用人脸数据进行训练(FFHQ),那么将会生成很多生活中不存在的面孔,且十分逼真。生成式先验中的人脸恢复的想法就是,既然你的生成器这么厉害,可以生成逼真的图像,那我直接把你的生成器拿过来用,作为我的解码器,那不就是可以恢复十分逼真的纹理了?
想法确实就是这样,但是还有一个问题,就是LQ信息怎么嵌入?如果只是单纯的生成,那我随机数给生成器就行了,但是现在做的是恢复任务,增加了一个LQ信息,怎么处理好这个LQ信息?
可以预想到,LQ利用的最优结果是:模型输出结果中的人脸id信息完全遵从LQ,然后又可以恢复逼真的细节。
GFPGAN! 腾讯作品,生成式先验的集大成者! 目前这个算法在GitHub上已经斩获30+k的star了,是一个非常经典且恢复效果泛化性挺好的一个算法。像上段中描述的GAN预训练模型已经是可以作为解码器了,应该考虑的是如何将LQ信息进行嵌入。
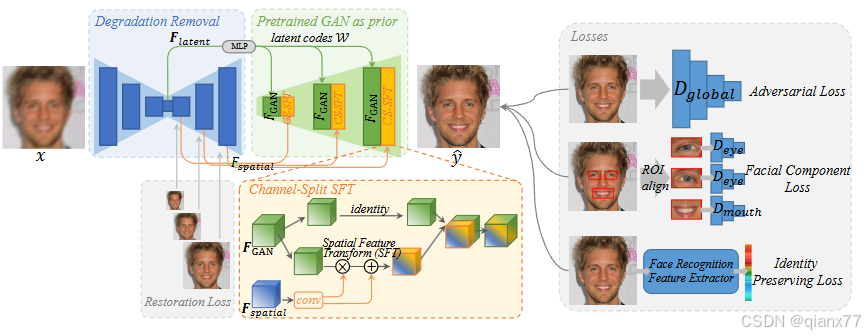
GFPGAN多种策略来使用LQ信息,
1、首先,LQ需要经过一个简单的UNet结构,这个UNet结构作为一些降质的去除(Degradation Removal),这个结构的目的就是将原始LQ的一些噪声模糊去除,确保进行到预训练GAN中的信息是干净的。因此有个额外的restoration loss 来监督这个过程。
2、简单UNet结构中的解码器特征和GAN预训练模型中的特征进行空间特征的变换(spatial feature transform)。主要目的是将干净的解码器特征和stylegan2生成器特征结合在一起。
多说一句,GFPGAN有多个版本v1、v1.2、v1.3、v1.4.效果都不太一样。不知道是数据原因还是啥。反正我最后通过一些方式只能复现出1.4版本的效果。
GPEN阿里作品,另外一个经典作品,也是2021年产出的。
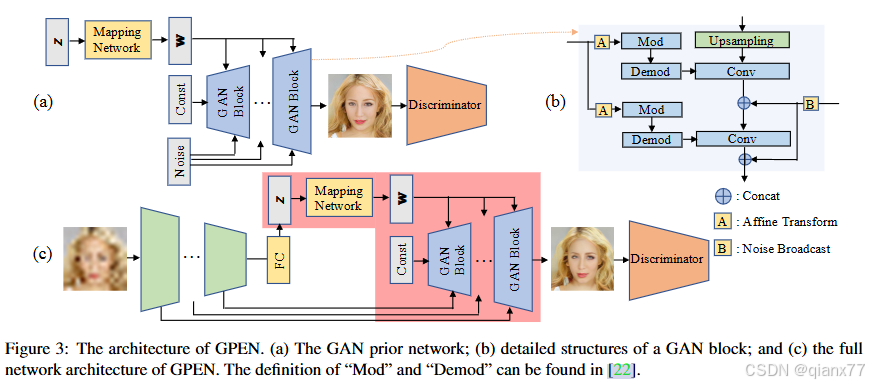
GPEN,我个人认为是一个非常简便的结构,甚至可以直接看出是一个UNet结构+w空间的调控,他没有GFPGAN中对于LQ信息的预处理,同时LQ编码器特征嵌入stylegan结构的过程也不一样,采用的是将LQ特征作为noise嵌入生成器。然后由于结构发生一点改变,并没有使用预训练模型,而是端对端直接训练。
由于结构比较简单,且缺少对LQ降质的去除,不管在我的测试数据或者复现中,效果都比不上GFPGAN,当然,对于轻度降质来说,其效果其实还不错。
2.3 codebook先验(Vector Quantized Codebook Prior)
我们知道stylegan中的w空间是连续的,因此相同的GT,不同的退化,可能产生的差距会很大,模型也会增加一些模棱两可的困境,因此Vector Quantized Codebook来解决这个问题。最经典最能打的论文,莫过于CodeFormer!
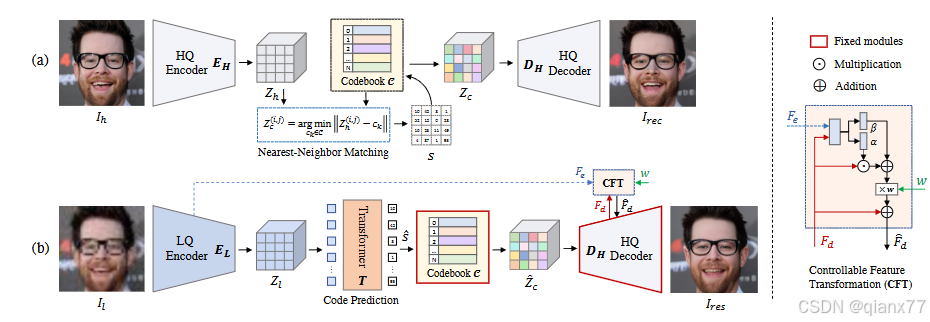
这个文章首先先利用高清图像HQ生成codebook,然后LQ经过encoder之后,利用transformer结构找到对应的码本索引,从而实现高清图像的恢复。由于前后仅有码本约束会让结果产生极大的不确定性,因此引入CFT结构和调控因子W,来控制LQ信息的嵌入,让用户可以选择fidelity 或者 quality。
第二个经典可能是VQFR
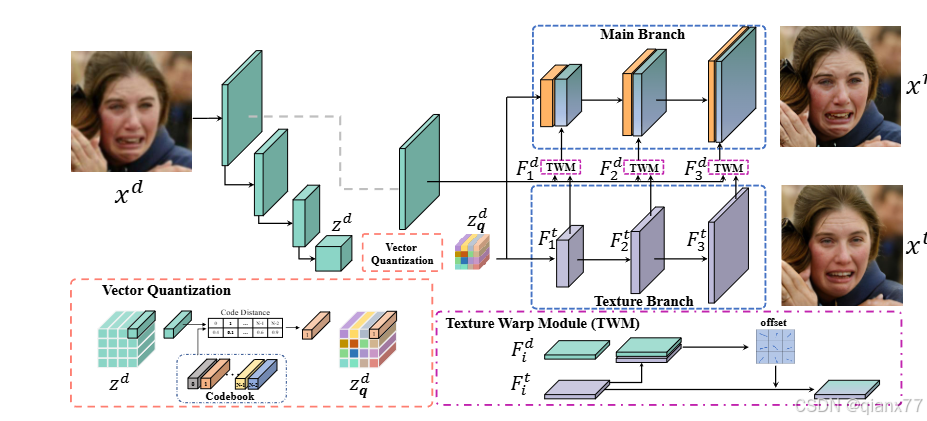
讲真虽然挺火,但是我论文看过印象不深,可能是因为我用预训练模型测了我数据,发现效果并不惊艳。
2.4 扩散先验 (Diffusion Prior)
和GAN先验类似,就是使用强大的生成能力来辅助人脸的恢复,两篇比较经典的应该是2023 NeurIPS的PGDiff 以及2024 TCSVT 的BFRffusion,但是这两篇我在自己数据集测试中发现效果一般。
远不如real world image super resolution中的DiffBIR 和 OSEDiff。后面这两个直接使用ffhq训练就吊打上面两个了。
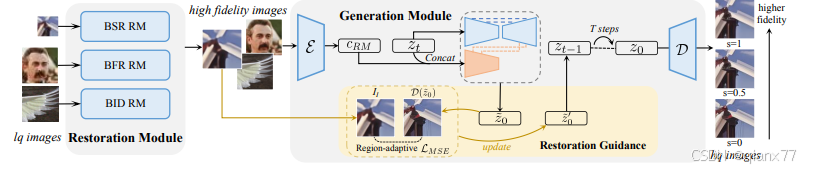
上图是DiffBIR 的模型结构,他其实将恢复分割成两个子任务,一个是高保真,一个是增加细节,因此前面一个网络可以仅仅使用L1损失来确保内容是保真但是模糊的,然后再用扩散在保真的图像中增加细节。
OSEDiff 则是单步扩散,已经落地在OPPO手机上了。
2.5 参考人脸的先验(Reference Prior)
这个为啥写在最后,因为我发现这个挺有意思的,一开始我只追溯到2022年,发现这部分的论文基本都是CNN结构,而且很多都是Xiaoming Li 这个大佬的文章,例如GFRNet 、DFDNet、ASFFNet、DMDNet,说实在的,面部细节确实是一般。
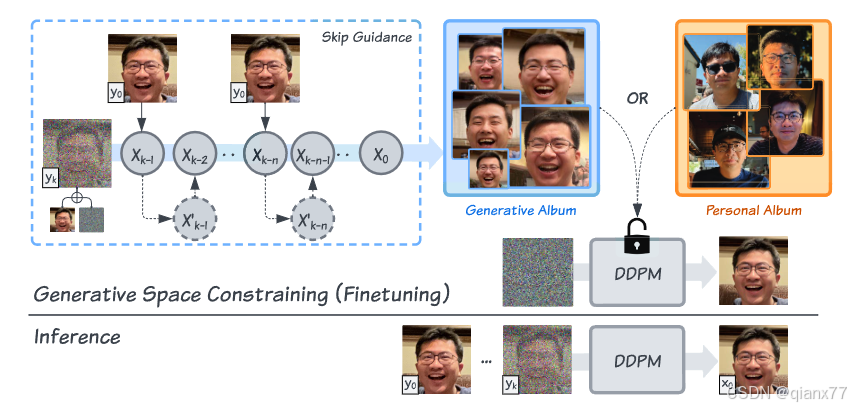
后面有这个需求之后,发现后面还是挺多相关工作的,甚至变成了Personalized Face Restoration 这种特殊的子领域。我认为其中我跑完觉得结果比较好的是adobe 2024 CVPR gen2res,
通过个人相册或者生成的相册来约束扩散模型的生成空间,我觉得效果还挺不错的,但是时序上可能会抖动。