Protobuf——Protocol Buffer详解(1)
目录
一、前言
二、序列化
1、概念
2、序列化流程
3、序列化方法
三、Protobuf
1、什么是protobuf
2、protobuf的使用
2.1 protobuf标量数据类型
2.2 .proto文件
2.3 使用
2.3.1 正常使用
2.3.2 以面向对象的思想写protobuf类
2.3.3 其他用法
一、前言
最近在学习项目的时候需要用到protobuf进行序列与反序列化,由于是第一次接触protobuf,所以做个小总结 。
我们知道,当我们想要将内存中的对象状态保存到一个文件或者存到数据库的时候,或者在进行网络传输的时候,我们无法直接传输数据(因为接收方会无法分辨),所以我们就需要序列化与反序列化,将一个对象转换为字节序,再将字节序转换为一个完整的对象的过程。
二、序列化
1、概念
序列化(Serialization):是指将对象的状态转换为可以存储或传输的格式的过程。它使得对象能够以二进制或文本的形式被保存到文件中,或者通过网络发送到远程计算机上,稍后可以重新构造出来(称为反序列化deserialization)
在 C++ 中,序列化的目的是将内存中的对象转换成一种持久化的格式,以便它可以存储在文件中、发送到网络、或者存储在数据库中,并且之后能够恢复为原始对象。序列化不仅涉及数据本身,还包括对象的结构和状态。
2、序列化流程
- 将对象转换为存储格式(序列化):将对象的状态转换成一种标准格式,可以是 二进制、JSON、XML或者其他格式,适合传输或者存储
- 存储或传输:序列化后的数据可以存储在文件系统、数据库或者通过网络传输。
- 恢复对象(反序列化):序列化的逆过程,将存储格式的数据转换回对象。
3、序列化方法
C++标准库本身并没有直接支持序列化,因此开发者通常会依赖第三方库或手动实现序列化和反序列化的功能。
在手动实现的时候,开发者必须要编写代码来指定如何将对象的每个成员变量转换为字节流(存储格式),以及如何将字节流恢复为对象。就像在我们之前学习Linux网络编程的时候,在实现我们的网络计算器的时候,我们就自己实现过针对于自己的这个项目对象的序列化与反序列化,但是终究是简约版,无法扩展到现实的大部分情况。
还有一种方式就是使用第三方库了,手动序列化比较繁琐,想要简化序列化的过程我们可以直接使用第三方库。
当前也存在着许多的序列化和反序列化工具,其中主流的有 XML、JSON、Protobuf
先简单介绍一下这三种工具的区别
| 序列化协议 | 通用性 | 格式 | 可读性 | 序列化大小 | 序列化性能 | 适用场景 |
|---|---|---|---|---|---|---|
| JSON | 通用(json、xml 已成为多种行业标准的编写工具) | 文本格式 | 好 | 轻量(使用键值对方式,压缩了一定的数据空间) | 中 | web 项目。因为浏览器对于 json 数据支持非常好,有很多内建的函数支持。 |
| XML | 通用 | 文本格式 | 好 | 重量(数据冗余,因为需要成对的闭合标签) | 低 | XML 作为一种扩展标记语言,衍生出了 HTML、RDF/RDFS,它强调数据结构化的能力和可读性。 |
| ProtoBuf | 独立(Protobuf 只是 Google 公司内部的工具) | 二进制格式 | 差(只能反序列化后得到真正可读的数据) | 轻量(比 JSON 更轻量,传输起来带宽和速度会有优化) | 高 | 适合高性能,对响应速度有要求的数据传输场景。Protobuf 比 XML、JSON 更小、更快。 |
三、Protobuf
1、什么是protobuf
Protocol Buffer( 简称 Protobuf) 是Google公司内部的混合语言数据标准,它是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,很适合做数据存储或RPC数据交换格式。
Protobuf是一个纯粹的展示层协议,可以和各种传输层协议一起使用,Protobuf的文档也非常完善。google 提供了多种语言的实现:java、c#、c++、go 和 python,每一种实现都包含了相应语言的编译器以及库文件。Protobuf支持的数据类型相对较少,不支持常量类型。由于其设计的理念是纯粹的展现层协议,目前并没有一个专门支持Protobuf的RPC框架。
2、protobuf的使用
2.1 protobuf标量数据类型
⼀个标量消息字段可以含有⼀个如下的类型——该表格展示了定义于.proto⽂件中的类型,以及与之对应 的、在⾃动⽣成的访问类中定义的类型:
| .proto Type | Notes | C++ Type | Java Type | Go Type |
|---|---|---|---|---|
| double | double | double | float64 | |
| float | float | float | float32 | |
| int32 | 使用变长编码,对于负值的效率很低,如果你的域 有可能有负值,请使用 sint64 替代 | int32 | int | int32 |
| uint32 | 使用变长编码 | uint32 | int | uint32 |
| uint64 | 使用变长编码 | uint64 | long | uint64 |
| sint32 | 使用变长编码,这些编码在负值时比 int32 高效的多 | int32 | int | int32 |
| sint64 | 使用变长编码,有符号的整型值。编码时比通常的 int64 高效。 | int64 | long | int64 |
| fixed32 | 总是 4 个字节,如果数值总是比总是比 228228 大的 话,这个类型会比 uint32 高效。 | uint32 | int | uint32 |
| fixed64 | 总是 8 个字节,如果数值总是比总是比 2^56 大的 话,这个类型会比 uint64 高效。 | uint64 | long | uint64 |
| sfixed32 | 总是 4 个字节 | int32 | int | int32 |
| sfixed64 | 总是 8 个字节 | int64 | long | int64 |
| bool | bool | boolean | bool | |
| string | 一个字符串必须是 UTF-8 编码或者 7-bit ASCII 编 码的文本。 | string | String | string |
| bytes | 可能包含任意顺序的字节数据。 | string | ByteString | []byte |
2.2 .proto文件
我们先需要编写一个proto文件,定义我们程序中需要处理的结构化数据,在Protobuf中,结构化的数据被称为Message。
我们可以通过在 .proto 文件中定义 protocol buffer message类型来指定我们想如何对序列化信息进行结构化。每一个 protocol buffer message 是一个信息的小逻辑记录,包含了一系列的 name-value 对。以下是一个基础的 .proto 文件样例模板
// protobuf的版本
syntax = "proto3"; //告诉protobuf编译器使用哪个版本的Protobuf来解析这个文件package lm;//声明用于定义消息类型的命名空间,避免不同包或者不同文件之间类型名称的冲突
// 组织Persion结构体
// 语法格式
message xxx {// 字段规则:required -> 字段只能也必须出现 1 次// 字段规则:optional -> 字段可出现 0 次或1次// 字段规则:repeated -> 字段可出现任意多次(包括 0)// 类型:int32、int64、sint32、sint64、string、32-bit ....// 字段编号:0 ~ 536870911(除去 19000 到 19999 之间的数字)字段规则 类型 名称 = 字段编号;
}// .proto文件 生成 c++ 类的命令
protoc proto文件名 --cpp_out=生成目录字段规则定义了字段在消息中的存在方式和频率,帮助确定如何进行序列化和反序列化数据。
- required(必需字段):该字段必须出现且只能出现一次。如果一个 required字段没有被设置值,在序列化时将会失败或导致错误。从 Protobuf 版本 3 开始,required已经不再推荐使用。
- optional(可选字段):该字段可以出现零次或一次,如果未设置,则会使用默认值(如果没有指定,默认值根据类型而定:数字类型为0,字符串为空字符串等),在 Protobuf 3 中,所有字段默认都是 optional 的,因此无需显式声明。
- repeated(重复字段):该字段可以出现任意多次(包括零次),重复值的顺序将保留在 protocol buffer 中。可以将 repeated 字段视为动态大小的数组。
例1使用required
message Person {required string name = 1;required int32 id = 2;optional string email = 3;
}说明:
- 这里
name和id是必需的字段,意味着每次创建Person消息实例时都必须提供这两个字段的值。 email是可选的,可以不设置。
例2使用optional
message Address {optional string street = 1;optional string city = 2;optional string zip_code = 3;
}说明:
- 所有字段均为可选,这意味着可以只填写部分信息或者完全不填写任何信息。
例3使用repeated
message Order {repeated string items = 1;required double total_cost = 2;
}说明:
items字段是一个重复字段,表示订单中可能包含多个商品名称。total_cost是必需的字段,表示订单的总费用。
如我们要序列化的数据是如下这种的话:
struct Person
{int id;string name;string sex; // man womanint age;
};我们自己创建的.proto文件就应该是这样的
syntax = "proto3";
message Person
{int32 id = 1; // 编号从1开始bytes name = 2;string sex = 3;int32 age = 4;
}2.3 使用
2.3.1 正常使用
使用 protoc test.proto --cpp_out=./ 命令后,可以看到生成了两个 protobuf类的文件如下
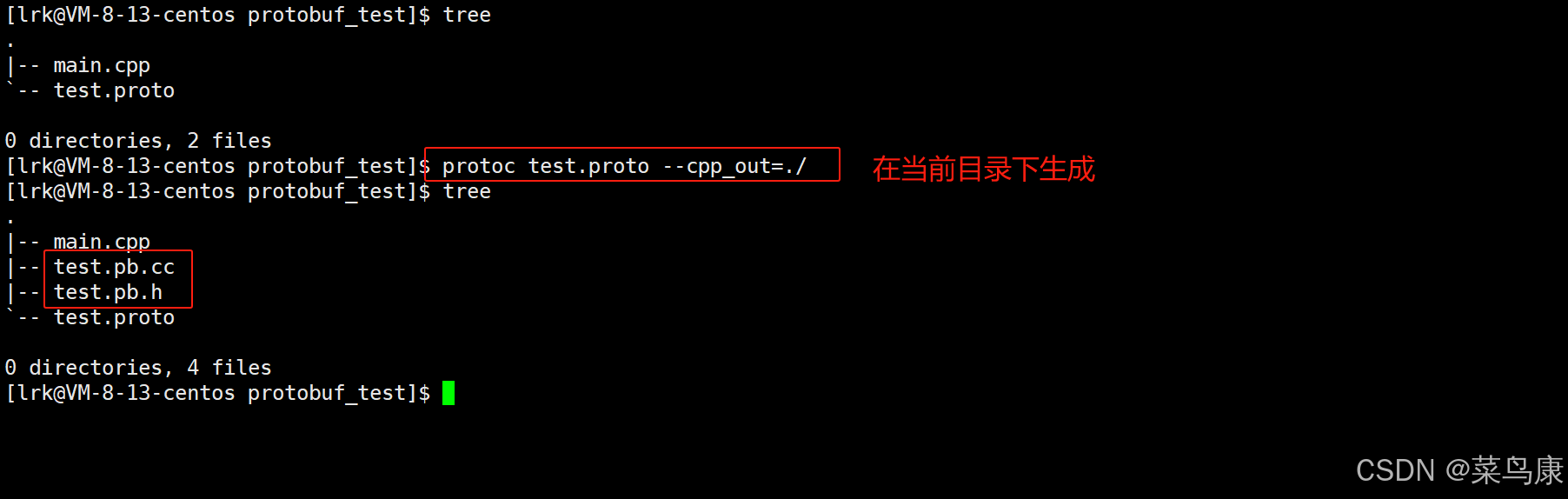
我们使用这两个类就可以对数据进行操作。本质上就是protobuf根据我们在 .proto 文件中所定义的数据化结构 message Person 帮我们自动生成了一个Person类,并且该类里面有着很多接口以供我们对结构化中的数据进行设置、序列化、反序列化等,我们就可以跟使用类一样调出它的接口进行各种操作。
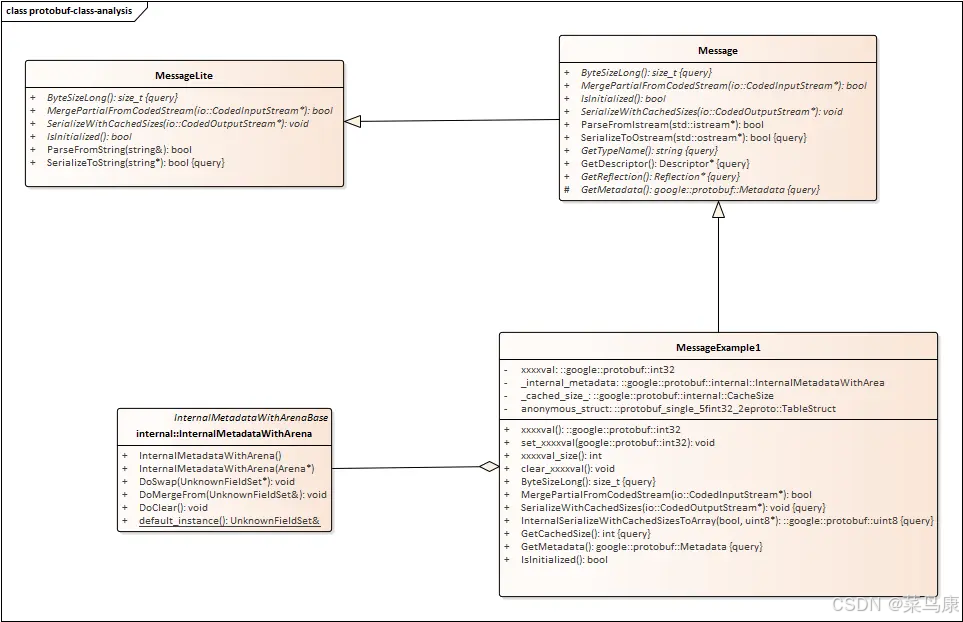
思考一下,它是怎么做到的呢?它是如何根据我们的数据化结构生成一个包含着很多接口的类的。这其实就用到了C++中的继承和多态方面的知识。
每一个在 .proto 文件中定义的 message 字段都会在代码中构造成一个类,且这些 message 消息类继承于 ::google::protobuf::Message,而 ::google::protobuf::Message 继承于一个更为轻量的 MessageLite 类。如下
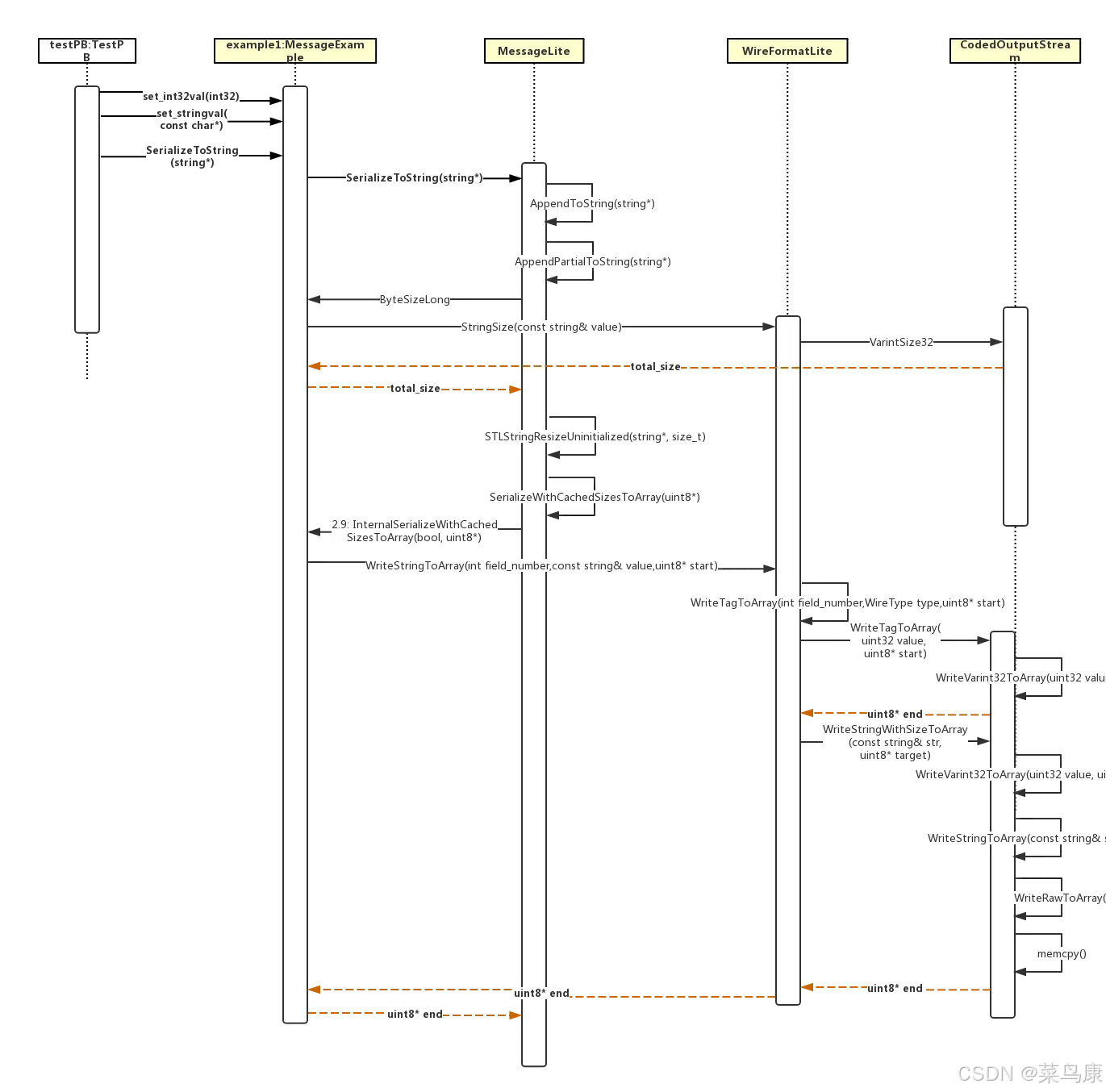
我们经常调用的序列化函数 SerializeToString 并定义在基类 MessageLite 中。
当某个 Message 调用 SerializeToString 时,经过一层层调用最终会调用底层的关键编码函数 WriteVarint32ToArray 或 WriteVarint64ToArray,整个过程如下图所示:
#include <iostream>
#include "test.pb.h"//要包含所生成的头文件
using namespace std;
int main()
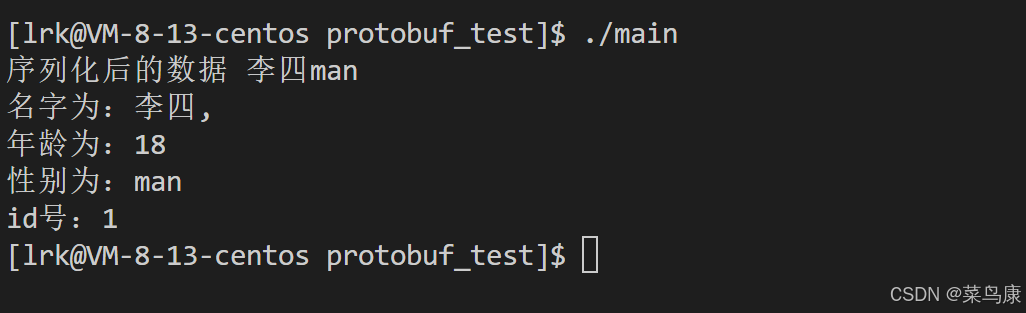
{//1.创建对象并且初始化Person p;p.set_age(18);p.set_name( "李四");p.set_sex("man");p.set_id(1);//2.将person数据进行序列号string output;p.SerializeToString(&output);cout << "序列化后的数据:" << output << endl;//3.数据传输// 网络传输,设置监听等等然后send数据,此处忽略//4.接收数据,解析->解码->原始数据Person pp;pp.ParseFromString(output);//5.处理原始数据 ->打印cout << "名字为:" << pp.name() << ","<<endl;cout << "年龄为:" << pp.age() << endl;cout << "性别为:" << pp.sex() << endl;cout << "id号:" << pp.id() << endl;return 0;
}- set_xxx:类中的接口,可以对我们结构中的数据进行赋值操作
- 调用protobuf类为我们提供的 SerializeToString()将我们指定的数据进行序列化,括号内是一个输出型参数,即为序列化后的参数
- 序列化后就可以进行网络发送,此处省略
- 获得数据后同样传出对象后调用protobuf类为我们提供的ParseFromString()方法,将序列化好的数据进行发序列化,就可以得到原始数据
接着编译 g++ -std=c++11 main.cpp test.pb.cc -o main -lprotobuf
运行后
2.3.2 以面向对象的思想写protobuf类
// 该结构体主要是方便参数传入
struct Info
{int id;string name;string sex; //int age;
};class My_Protobuf
{
public:// 空构造My_Protobuf();// 构造出的对象用于 解码 的场景My_Protobuf(string enstr) {InitMyProto(enstr);}// 构造出的对象用于 编码 场景My_Protobuf(Info* info){InitMyProto(info);}~My_Protobuf();// 编码时候使用void InitMyProto(Info* info){m_person.set_id(info->id);m_person.set_name(info->name);m_person.set_sex(info->sex);m_person.set_age(info->age); }// 解码使用void InitMyProto(string enstr){m_enstr = enstr;}// 编码string encodeMsg(){string output;m_person.SerializeToString(&output);return output;}// 解码void* decodeMsg(){m_person.ParseFromString(m_enstr);retrun &m_person;}
private://Person这个类由protobuf产生Person* m_person;string m_enstr;
}2.3.3 其他用法
//enum枚举
enum Color
{Red = 0; // protbuf中第一个枚举值必须为0Green = 6;Blue = 9;
}假设在一个 .proto 文件中有以下的信息,通过命令行会生成6个对应的类,我们下来将其进行封装
syntax="proto3";
package pb;
message SyncPid
{int32 Pid = 1;string Username = 2;
}message Player
{int32 Pid = 1;Position P=2;string Username = 3;
}message SyncPlayers
{/*嵌套多个子消息类型的Player消息*/repeated Player ps = 1;
}message Position
{float X=1;float Y=2;float Z=3;float V=4;
}
message BroadCast
{int32 Pid=1;int32 Tp=2;/*根据Tp不同会选择一下其中一个content 消息内容Position 位置*/oneof data{string content=3;Position P=4;/*预留*/int32 ActionData=5;}string Username=6;
}message Talk
{string Content = 1;
}- 这里生成的6个类对应的不同的消息类型,所以我们构造的时候需要通过某些标志位构造不同的消息
- 在protobuf的所有消息中都有一个共同的父类 google::protobuf::Message 类,因此我们可以通过这个父类指针去获得上面6个类中的任意数据
class MyMsg{
public:enum MyMsgType {MY_MSG_LOGON_SYNCPID = 1,MY_MSG_TALK_CONTENT = 2,MY_MSG_NEW_POSTION = 3,MY_MSG_BROADCAST = 200,MY_MSG_LOGOFF_SYNCPID = 201,MY_MSG_SUR_PLAYER = 202,} m_MsgType;google::protobuf::Message *m_poMsg = NULL;MyMsg(MyMsgType _Type, google::protobuf::Message * _msg);MyMsg(MyMsgType _Type, std::string _szInputData);~MyMsg();std::string Serialize();
};通过一个枚举值规定不同的数据类型,根据不同数据类型构造不同的消息
m_poMsg:类的成员,维护一个所有protobuf类的父类指针
构造函数
- 构造函数1:通过传进来的类型和子类对象参数,直接初始化m_MsgType和m_poMsg就可以直接获得对应消息
- 构造函数2:根据Type不同new出不同的protobuf对象,然后用创建出来的对象调用ParseFromString方法将参2的string解析获得对应消息
MyMsg::MyMsg(MSG_TYPE _type, google::protobuf::Message* _msg):m_MsgType(_type),m_poMsg (_msg)
{}MyMsg::MyMsg(MSG_TYPE type, string str): m_MsgType(type)
{switch (type){case GameMsg::MSG_TYPE_LOGIN_ID_NAME:m_Msg = new pb::SyncPid();break;case GameMsg::MSG_TYPE_CHAT_CONTENT:m_Msg = new pb::Talk();break;case GameMsg::MSG_TYPE_NEW_POSITION:m_Msg = new pb::Position();break;case GameMsg::MSG_TYPE_BROADCAST:m_Msg = new pb::BroadCast();break;case GameMsg::MSG_TYPE_LOGOFF_ID_NAME:m_Msg = new pb::SyncPid();break;case GameMsg::MSG_TYPE_SRD_POSTION:m_Msg = new pb::SyncPlayers();break;default:break;}m_Msg->ParseFromString(str);
}string MyMsg::Serialize()
{string pret;m_Msg->SerializeToString(&pret);return pret;
}MyMsg::~MyMsg()
{if (m_Msg != nullptr){delete m_Msg;m_Msg = nullptr;}
}感谢阅读!