ConcurrentSkipListMap的深入学习
目录
1、介绍
1.1、线程安全
1.2、有序性
1.3、跳表数据结构
1.4、API 提供的功能
1.5、高效性
1.6、应用场景
2、数据结构
2.1、跳表(Skip List)
2.2、节点类型:
1.Node
2.Index
3.HeadIndex
2.3、特点
3、选择层级
3.1、随机化
3.2、期望高度
3.3、保持平衡性
3.4、简单性
3.5、性能分析
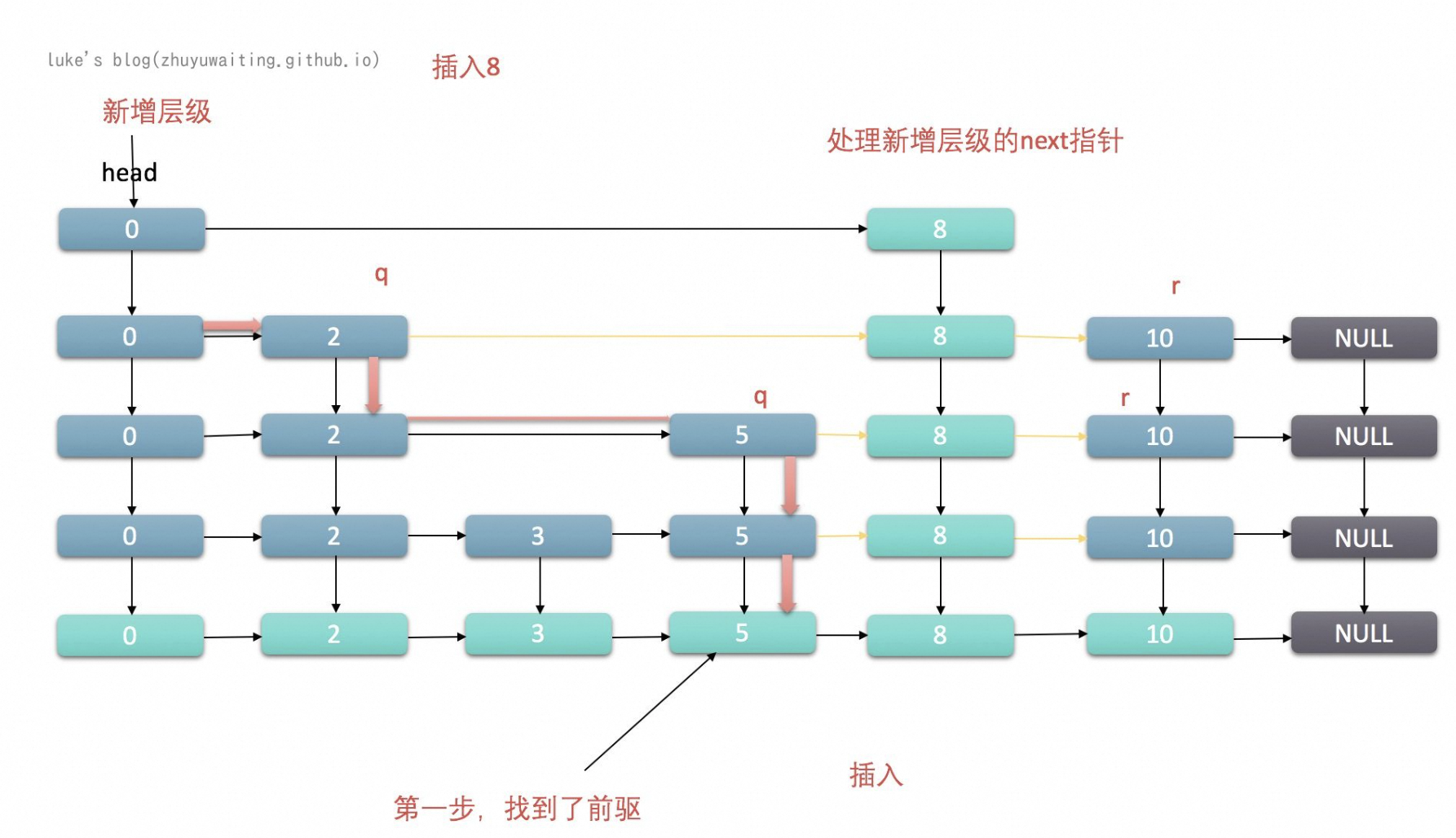
4、层级遍历
4.1、层级引用的结构
4.2、查找过程
5、线程安全的实现
5.1、分段锁机制
5.2、无锁读操作
5.3、随机化和跳表结构
5.4、操作的原子性
5.5、自然的排序和查找性能
6、排序目的
6.1、数据检索
6.2、导航操作
6.3、高效性
6.4、灵活性
7、并发控制机制
7.1、CAS(Compare-And-Swap)
7.2、版本标记
7.3、无阻塞设计
7.4、辅助删除
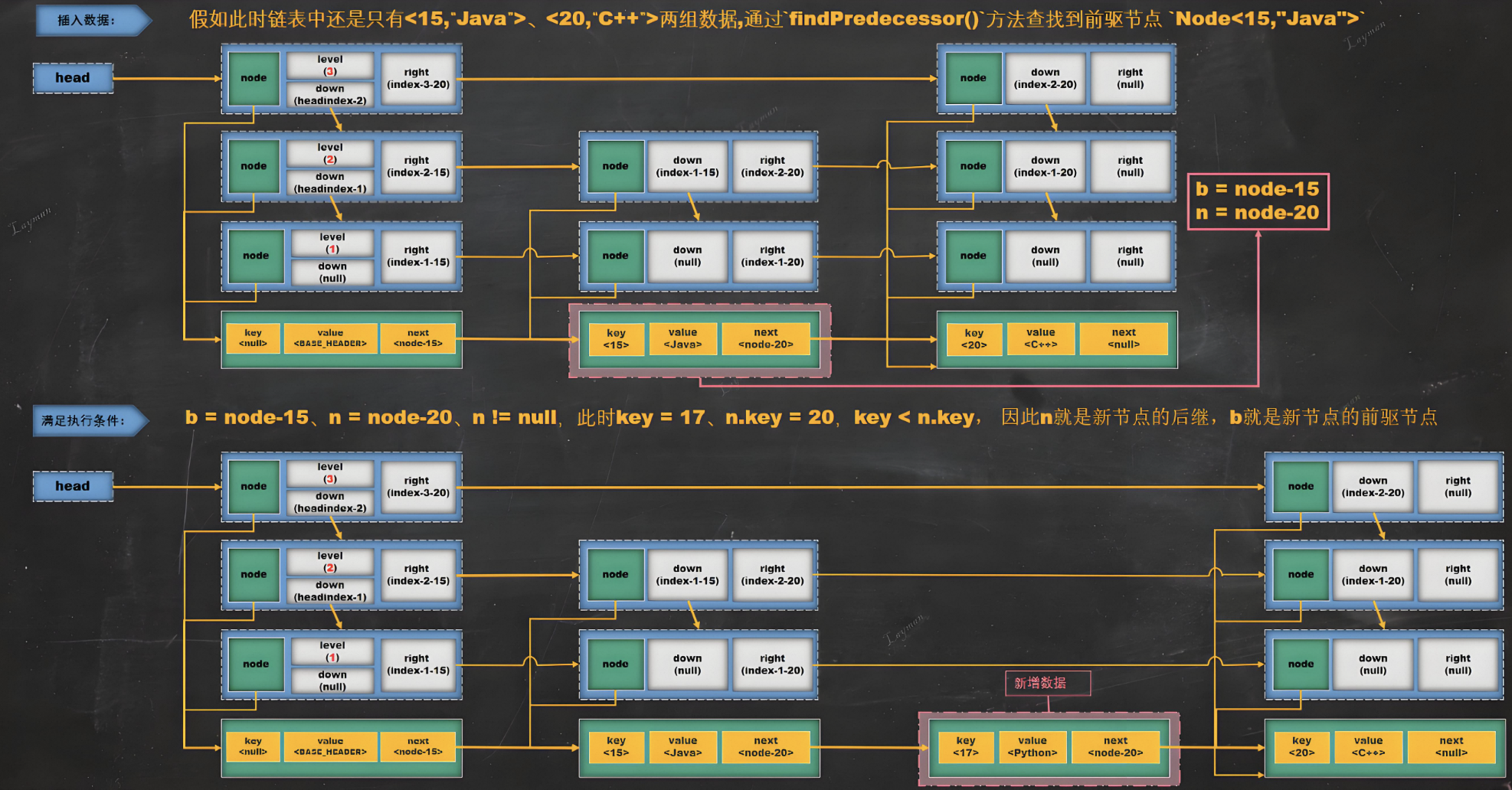
7.5、寻找前驱节点
7.6、弱一致性
8、常用方法
8.1、put方法
8.2、get操作
8.3、remove操作
8.4、迭代器实现
一种高效的线程安全有序映射,适合在高并发环境中使用。其结合了跳表的优点,提供了很好的查找、插入、删除性能,并且支持无锁读取,适合需要频繁读写的多线程应用场景。
与其他map相比如下图所示:
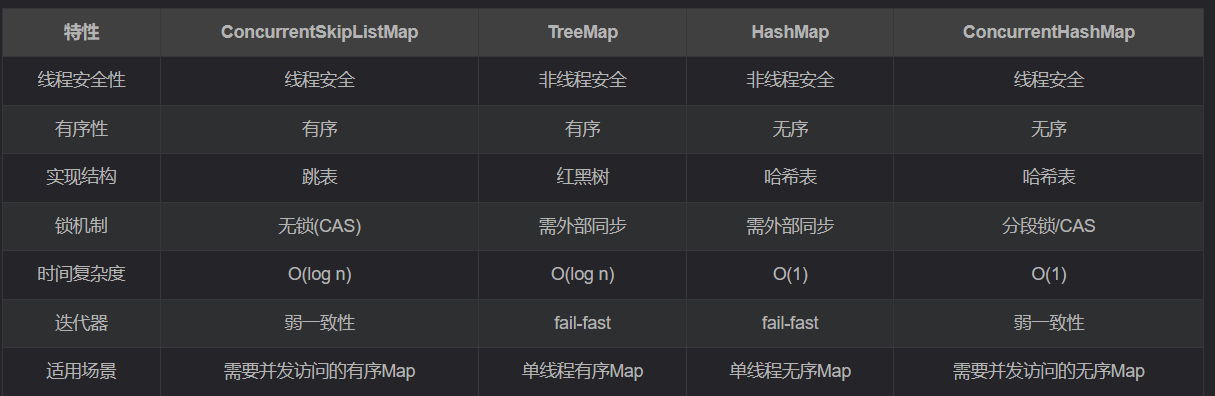
它是唯一一个同时提供线程安全和有序性的Map实现。
1、介绍
是 Java 提供的一个并发集合类,属于java.util.concurrent包。它实现了ConcurrentNavigableMap接口,并且是一个线程安全的、有序的、跳表(Skip List)数据结构。
如下图所示:
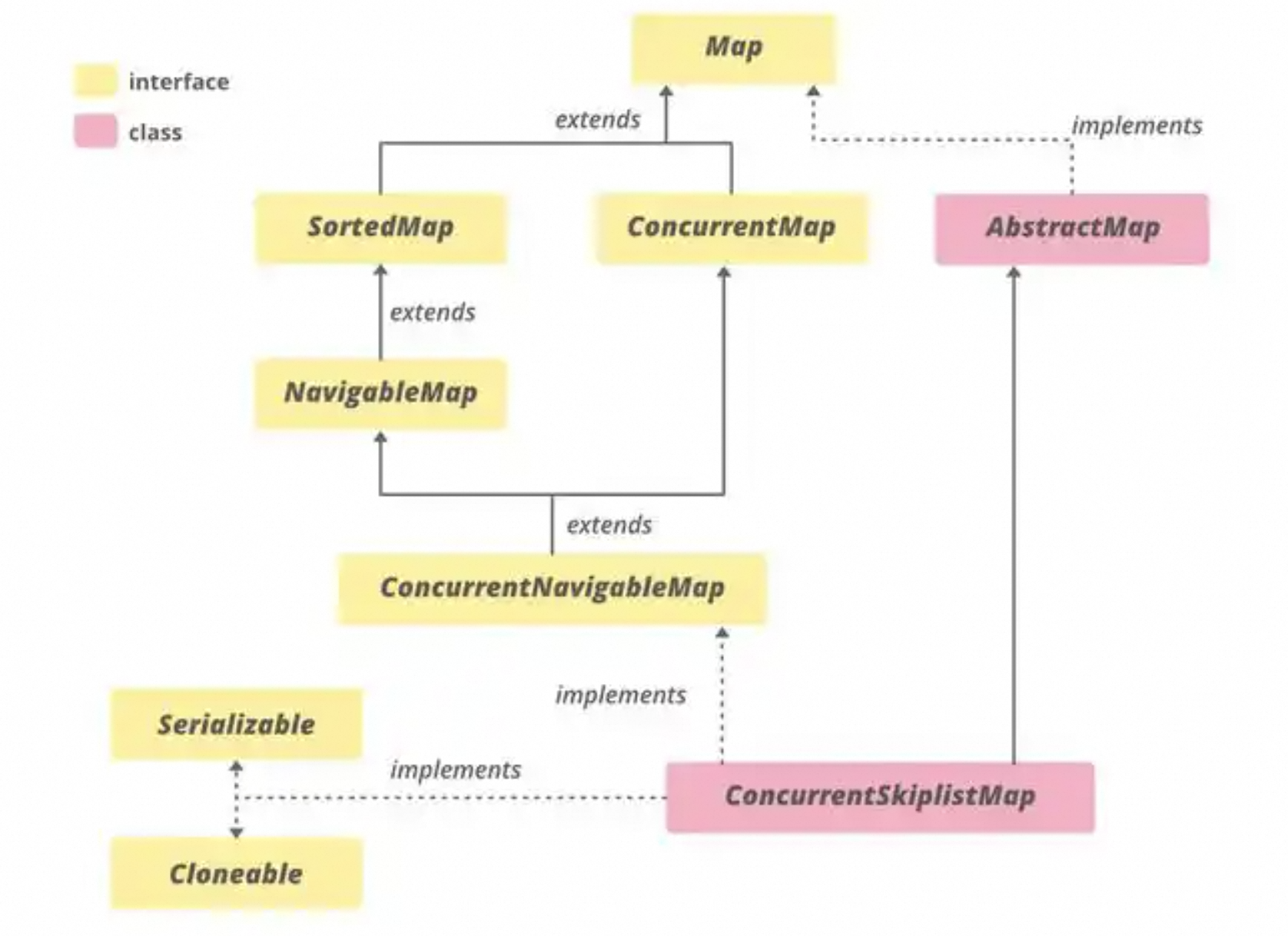
以下是 ConcurrentSkipListMap 的主要作用和特点:
1.1、线程安全
是一个支持并发访问的集合类,多个线程可以同时进行读和写操作,而不需要显式的同步。这就意味着,当多个线程同时访问这个映射时,不会导致数据不一致或抛出异常。
1.2、有序性
根据键的自然顺序或根据构造时提供的比较器(Comparator)来维护元素的顺序。它能有效地执行一些有序操作,如范围查询、排序等。
1.3、跳表数据结构
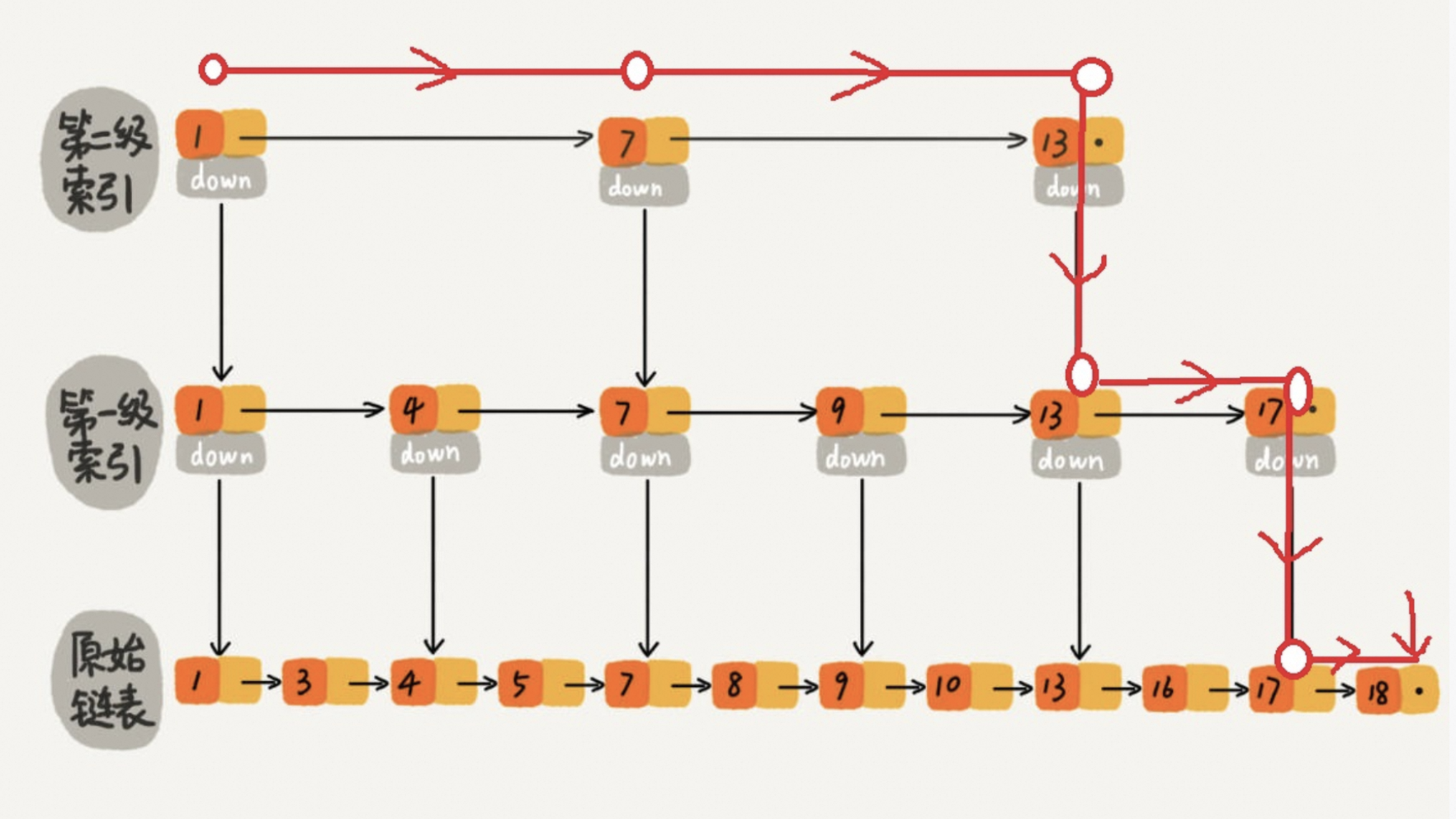
跳表是一种随机化的数据结构,具有多层级(linked lists)的有序列表。查找、插入和删除的时间复杂度平均为 O(log n),同时跳表在并行环境中表现良好。这使得 ConcurrentSkipListMap 在大规模并发访问的情况下迁移期间性能良好。
如下图所示:
1.4、API 提供的功能
- 由于实现了
NavigableMap接口,ConcurrentSkipListMap提供了一些有用的方法:- 导航方法:如
lowerKey(),higherKey(),floorKey(),ceilingKey()等,这些方法允许对键进行导航操作。 - 集合视图:可以获取键集、值集合和条目集的视图。
- 范围操作:支持范围查询,可以方便地获取某个范围内的元素。
- 导航方法:如
1.lowerKey(K key)
-
功能:返回严格小于给定键的最大键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.lowerKey(4); // 返回32.higherKey(K key)
-
功能:返回严格大于给定键的最小键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.higherKey(2); // 返回33.floorKey(K key)
-
功能:返回小于或等于给定键的最大键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.floorKey(3); // 返回34.ceilingKey(K key)
-
功能:返回大于或等于给定键的最小键
-
参数:要比较的键
-
返回值:如果存在这样的键则返回该键,否则返回
null
map.put(1, "A"); map.put(3, "B"); map.put(5, "C");
Integer key = map.ceilingKey(2); // 返回31.5、高效性
由于基于跳表,ConcurrentSkipListMap 在高并发情况下提供了优良的性能。此外,由于它采用了分段锁的机制,允许多个线程进行同时的插入和查询操作。
1.6、应用场景
根据ConcurrentSkipListMap的特性,以下场景特别适合使用它:
1、需要线程安全且有序的Map实现时:
如果应用需要在多线程环境下维护一个按键排序的映射。
2、需要高效的范围查询操作时:
支持高效的范围操作,如subMap、headMap、tailMap等,这在需要按范围获取数据的场景中非常有用。
3、需要按键的顺序进行并发迭代时:
迭代器按键的顺序遍历元素,这在需要有序处理数据的并发场景中很有价值。
4、需要线程安全但又不希望有锁带来的阻塞时:
ConcurrentSkipListMap的无锁设计避免了线程阻塞,提供了更好的并发性能。
5、读操作明显多于写操作,且需要有序性的场景:
虽然ConcurrentSkipListMap的写操作比ConcurrentHashMap慢,但在读多写少且需要有序性的场景中,它是最佳选择。
ConcurrentSkipListMap特别适合用在对性能和线程安全性有严格要求的应用场景中,例如:- 在线交易处理
- 实时数据监控
- 需要频繁插入、删除和查找操作的多线程环境
示例代码:
以下是 ConcurrentSkipListMap 的简单示例:
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapExample {public static void main(String[] args) {ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 添加元素map.put(3, "Three");map.put(1, "One");map.put(2, "Two");// 获取元素System.out.println(map.get(2)); // 输出: Two// 遍历元素map.forEach((key, value) -> {System.out.println(key + ": " + value);});// 使用导航方法System.out.println("Lowest key: " + map.firstKey()); // 输出: 1System.out.println("Highest key: " + map.lastKey()); // 输出: 3}
}
总结
ConcurrentSkipListMap 是一个高效、线程安全的有序映射实现, 适合在高并发环境下使用,支持快速的查找、插入、删除和有序访问操作。由于其优秀的性能特性,适用于多种需要处理并发数据的场景。
2、数据结构
基于 跳表(Skip List)数据结构实现的。核心思想是以空间换时间,通过构建多层索引,使得查找、插入和删除操作的平均时间复杂度降低到O(log n)。
没有初始化容量,和HashMap对比:

2.1、跳表(Skip List)
跳表是一种基于链表的分层的动态数据结构,旨在高效地实现有序映射和集合操作。它结合了链表和二分搜索的优点,使用多级索引来加速查找、插入和删除操作。
如图所示:
具体来讲,跳表由多个层级的有序链表组成,其中每一层都是底层链表的一个子集。
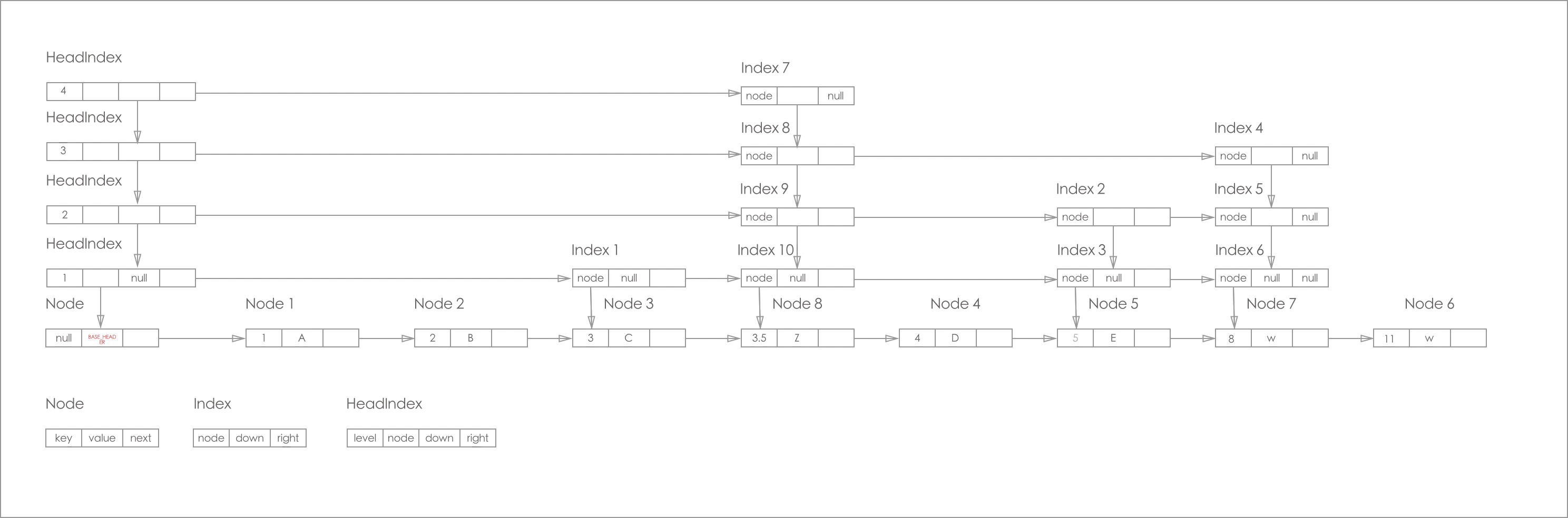
2.2、节点类型:
ConcurrentSkipListMap 的节点主要由 Node, Index, HeadIndex 构成。

如下图所示:
具体简化如下图所示:
head ---> Index ---> Index ---> null| | |v v v
head ---> Index ---> Index ---> null| | |v v v
head ---> Node ----> Node ----> Node ----> null
1.Node
基础节点,构成底层有序链表,包含key、value和next引用。
/*** 最上层链表的头指针head*/private transient volatile HeadIndex<K, V> head;/* ---------------- 普通结点Node定义 -------------- */static final class Node<K, V> {final K key;volatile Object value;volatile Node<K, V> next;// ...}
2.Index
索引节点,构成上层快速路径,包含node引用和right、down引用。
/* ---------------- 索引结点Index定义 -------------- */static class Index<K, V> {final Node<K, V> node; // node指向最底层链表的Node结点final Index<K, V> down; // down指向下层Index结点volatile Index<K, V> right; // right指向右边的Index结点// ...}
3.HeadIndex
头索引节点,是Index的特殊子类,维护索引层链接。
/* ---------------- 头索引结点HeadIndex -------------- */static final class HeadIndex<K, V> extends Index<K, V> {final int level; // 层级// ...}
}
VarHandle:JDK 9+使用VarHandle替代Unsafe进行CAS操作。
如下图所示:
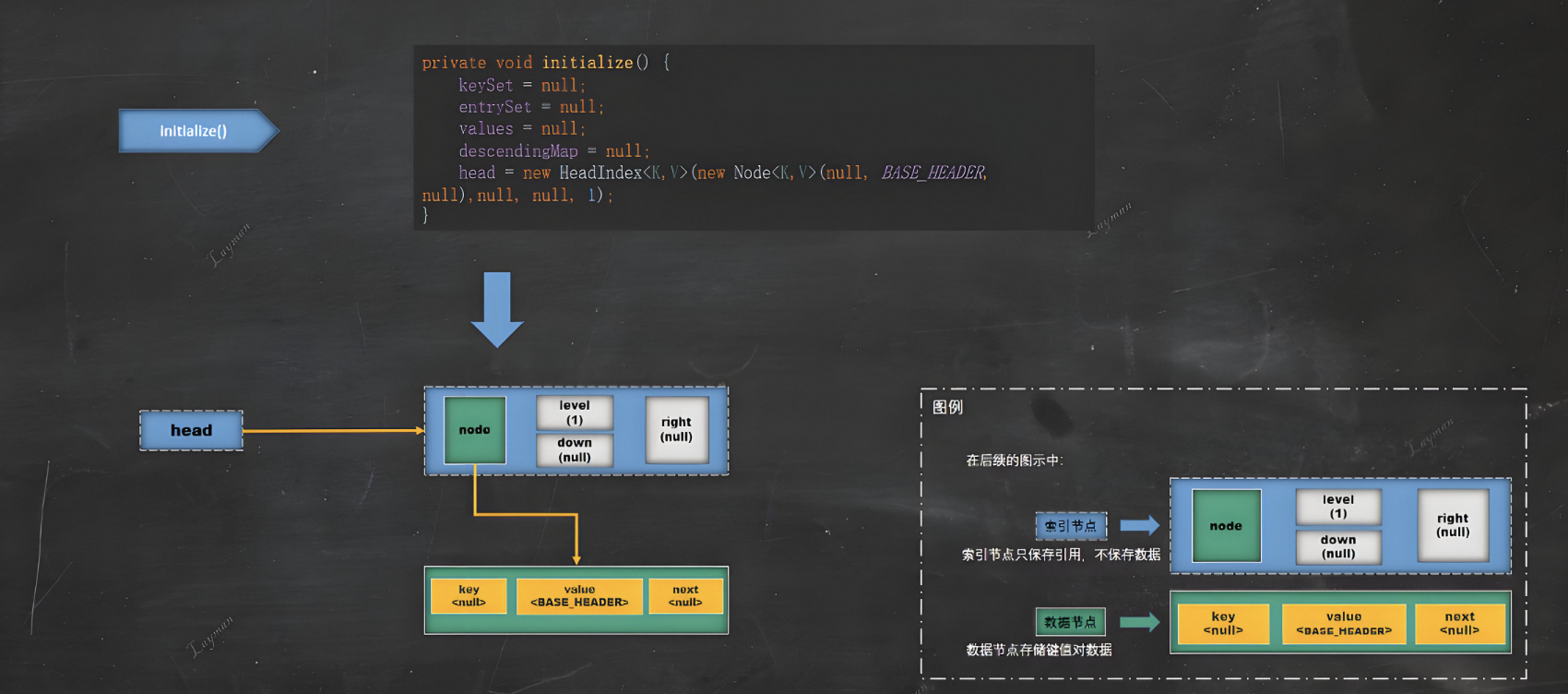
2.3、特点
1、层级结构:
跳表有多层,每层包含一些节点。最底层是包含所有元素的有序链表。每向上增加一层,节点的数量通常会减少。
最下面那层是Node层(数据节点)层, 上面几层都是Index(索引)层。
所有层的节点都有指向它们下层节点的引用,允许快速搜索。从纵向链表来看, 最左边的是 HeadIndex 层, 右边的都是Index 层, 且每层的最底端都是对应Node, 纵向上的索引都是指向最底端的Node。
2、随机化:
新插入的节点会随机选择层级。通常,选定层级的概率是
0.5,这意味着大约一半的节点会出现在上一层中。
这种随机化使跳表在平均情况下表现出 O(log n) 的查找、插入和删除时间复杂度。
3、有序性:
每一层链表都是有序的,因此从最上层开始,可以通过向前跳过多个节点(即 "跳")来快速找到目标节点。这样可以有效减少查找时间。
3、选择层级
在跳表(Skip List)中,新插入节点选择层级的概率是 0.5(即每次向上一层的概率是 50%)是基于特定的设计思想,目的是为了实现平衡性和高效性。
这个设计选择有以下几点原因和好处:
3.1、随机化
均匀分布:
通过使用 0.5 的概率,能够使得节点在各个层级之间的分布较为均匀。这种随机化过程中,较少的节点会在较高的层级上存储,从而有效地减少了第一个层级中节点的数量,使得每一层的链表都保持相对高效的空间利用和查询时间。
3.2、期望高度
1、跳表的高度:
跳表的平均高度(h)是对数级的。如果每个节点上升一层的概率是 0.5,那么插入 n 个节点后,跳表的高度是 O(logn)O(logn)。这意味着大部分的节点都在较低的层级,只有少数节点会在较高的层级出现,使得整个数据结构在平均情况下保持高效。
最早有31层,
-
Integer.numberOfTrailingZeros(random)返回random二进制表示中最低位1之前0的个数。 -
由于
int是 32 位,最多可能有 31 个连续的0(因为至少需要 1 个1),所以层级上限是31 + 1 = 32。但实际实现中会限制为31,避免极端情况。
// 伪代码:随机生成层级
int random = ThreadLocalRandom.current().nextInt();
int level = Integer.numberOfTrailingZeros(random) + 1;3.3、保持平衡性
自调整能力: 随机化算法特性提供了一种自适应的能力,无需对跳表进行显式的平衡调整。它通过随机选择的方式,减少了过多的链表在某个层级的集中程度,从而实现了良好的负载均衡,这在其他数据结构中通常需要额外的维护工作(例如 AVL 树或红黑树的旋转)。
3.4、简单性
使用固定的概率,如 0.5,使得跳表的实现简单且易于理解。在插入节点时,只需一段简单的代码来决定节点的层高。
具体计算:
假设有 n 个节点,如果每个节点都有 0.5 的概率在每层存在,那么期望一个节点在某一层的出现概率是 1/2^h,其中 h 是层数。
通过这种方式,可以保证跳表的高度不至于过高,从而确保了查找、插入和删除操作的对数时间复杂度。
跳表的查询、插入和删除操作的平均时间复杂度为 O(log n),这依赖于节点层级的随机分布。
-
概率 p = 0.5 时,跳表的层级分布最均衡:
-
第 1 层包含所有节点(100%)
-
第 2 层约 50% 的节点
-
第 3 层约 25% 的节点(即 0.5²)
-
第 k 层约 n/2^k 个节点
这种分布能保证 查询路径长度 ≈ log₂n,与平衡二叉树的性能相当。
-
过高(如 0.75)会导致高层级节点过多,增加并发冲突;过低(如 0.25)会减少跳跃性,退化成链表。
3.5、性能分析
由于这种概率分布,跳表能够以 O(logn)的时间复杂度进行查找、插入和删除,这使得它在高并发或需要动态修改集合的场景中表现优异。
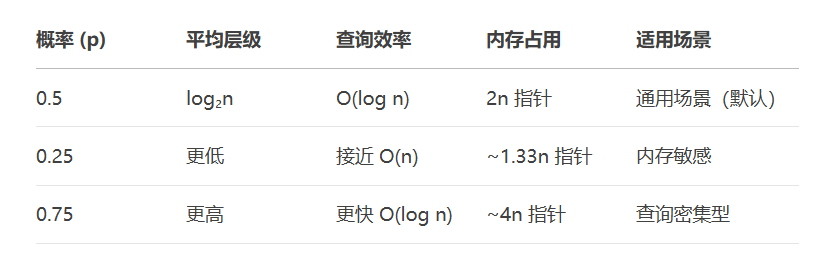
小结
将新插入节点选定层级的概率设为 0.5 是一种简化且有效的随机化策略,保证了跳表在保持有序性的同时,还能在高效性和均衡性之间取得良好的平衡。
4、层级遍历
在跳表 (Skip List) 的实现中,层级的引用通常是 单向的,并且在查找时,通常是 从高层遍历开始,逐层向下查找。
如下图所示:
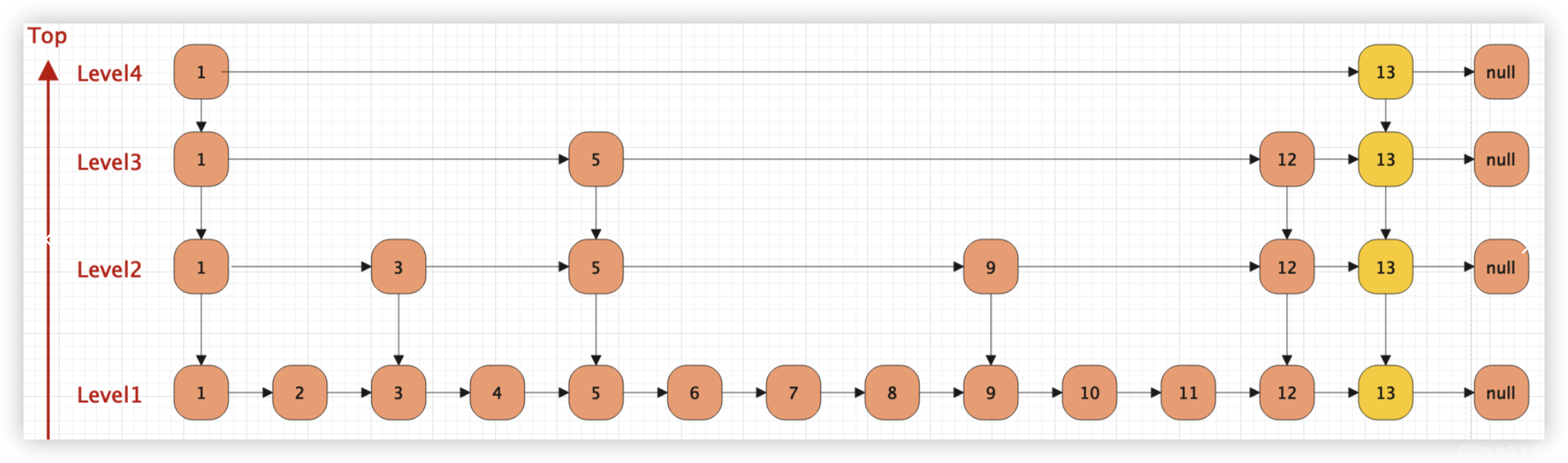
4.1、层级引用的结构
1、单向引用:
在跳表的每一层中,节点之间的指针仅指向下一层的节点。这意味着每个节点在同一层中只保持指向下一个节点的引用,因此它是单向的。在跳表中,尽管有多个层,但是节点在每层之间的访问是单向的,即只能向右查找,不能向左查找。
2、跨层引用:
每个节点不仅在其所在层中保持对下一个节点的引用,还可能在更高层级中保持对其他节点的引用。这样,节点在不同层之间的连接仍然是单向的,但可以在高层直接访问更远的节点。
4.2、查找过程
如下图所示:
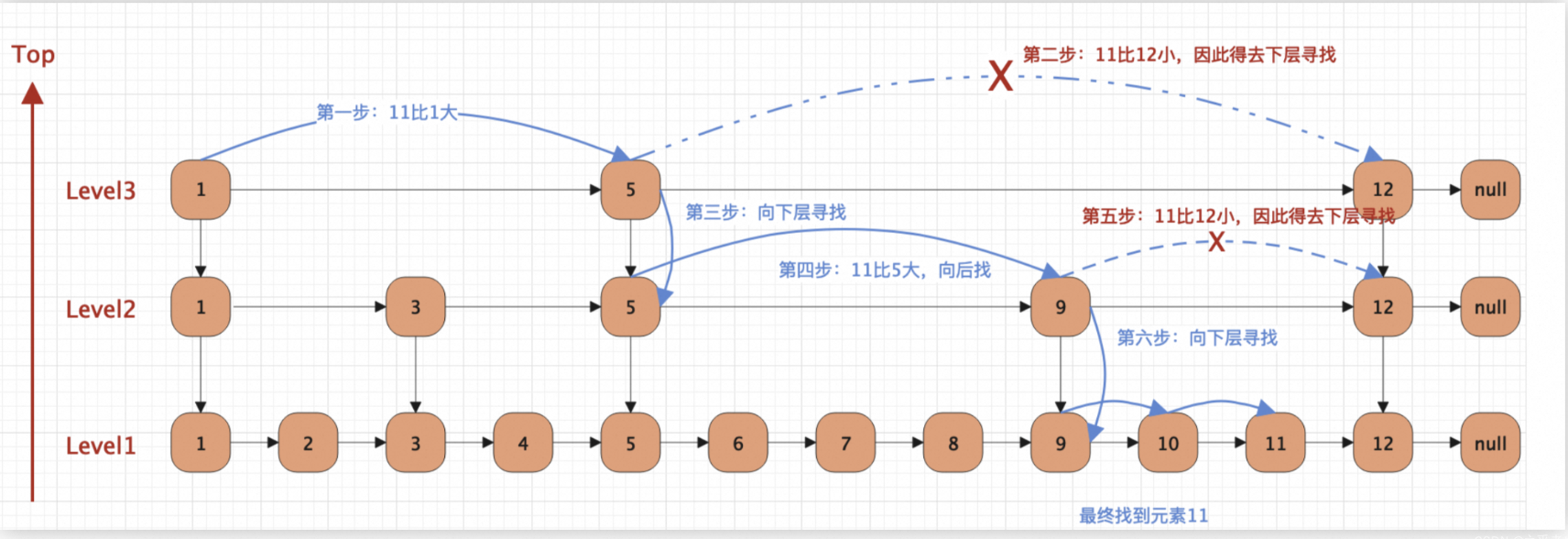
1、从高层开始查找:
查找操作通常从跳表的最高层开始。如果当前节点的下一个节点的值大于所需查找的值,则向下移动到下一层;如果下一个节点的值小于或等于所需查找的值,则向右移动到下一个节点。
这种方式利用了高层节点分布稀疏的特性,可以快速缩小查找范围。因为高层的节点数量相对较少,可以“跳过”较大的值范围。
2、逐层向下:
当在某一层遇到节点的值大于目标值时,就会向下层下降,继续此过程,直到找到目标节点或达到底层为止。在底层时,通常会完成最后的查找,因为底层包含所有的值。
总结
层级引用:
在跳表中,层级的引用是单向的。
查找顺序:
查找时是从高层开始,并逐层向下移动,这样可以加速查找过程,提升效率。通过利用高层的节点稀疏性,可以迅速导航到可能包含目标值的区域,从而实现均匀的查找时间。
5、线程安全的实现
5.1、分段锁机制
部分锁定:
采用了一种分段锁的机制,在对跳表中的某些部分进行操作时只会锁定相关节点,而不会锁定整个数据结构的所有部分。
这种方法提高了并发性,因为它允许多个线程同时访问不同部分的跳表。
节点锁:
跳表中的每个节点都维护一个锁,多个线程可以同时获取不同节点的锁来进行操作,而不必等待其他线程完成对不同节点的操作。这样,读操作与写操作之间不会发生严重的竞争。
5.2、无锁读操作
Optimistic Concurrency Control:
实现了一种无锁的读操作机制,读取操作通常无需加锁,这大大提高了读取的性能。
基础数据结构:
读操作可以仅通过检查节点的引用和数据来完成,不需要进行复杂的锁定,从而降低了延迟。
5.3、随机化和跳表结构
跳表的设计:
跳表本身通过概率方法(例如 0.5 的概率选择层级)使得结构在某种程度上是随机化的,减少了集中的竞争风险。随即的层级产生了自然的分布,减少了热点。
5.4、操作的原子性
原子更新:
对于插入、删除和查找操作,在内部使用原子性的方法来保证这些操作的原子特性。此操作包括对于节点的添加和删除确保数据结构的一致性。
Compare-And-Swap (CAS):
在某些实现细节中,ConcurrentSkipListMap 可能使用底层的 Compare-And-Swap 操作来确保对节点的更改是安全的,这种操作是原子性的,并能够有效防止数据竞争。
5.5、自然的排序和查找性能
排序:
由于 ConcurrentSkipListMap 维护了节点的顺序结构以及通过跳表保证了高效的查找操作,使得在多线程场景中,正好可以利用这些性能,减少了潜在的锁竞争带来的影响。
示例:
以下示例演示了如何使用 ConcurrentSkipListMap 在多线程环境中安全地操作有序映射,特别是执行插入、删除和遍历操作。
import java.util.concurrent.ConcurrentSkipListMap;public class ConcurrentSkipListMapExample {public static void main(String[] args) {// 创建一个并发跳表ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();// 启动多个线程,同时对跳表进行插入操作Thread writer1 = new Thread(() -> {for (int i = 1; i <= 5; i++) {map.put(i, "Value " + i);System.out.println("Writer 1: Inserted (" + i + ", Value " + i + ")");}});Thread writer2 = new Thread(() -> {for (int i = 6; i <= 10; i++) {map.put(i, "Value " + i);System.out.println("Writer 2: Inserted (" + i + ", Value " + i + ")");}});// 启动多个线程,同时对跳表进行读取操作Thread reader = new Thread(() -> {for (int i = 1; i <= 10; i++) {String value = map.get(i);System.out.println("Reader: Retrieved (" + i + ", " + value + ")");}});// 启动线程writer1.start();writer2.start();reader.start();// 等待线程完成try {writer1.join();writer2.join();reader.join();} catch (InterruptedException e) {e.printStackTrace();}// 最后展示跳表的内容System.out.println("Final map contents: " + map);}
}
6、排序目的
ConcurrentSkipListMap 之所以实现有序性,主要有以下几点原因:
6.1、数据检索
有序数据结构支持高效地访问元素。可以快速找到最大、最小值,或者某个范围内的所有元素。
6.2、导航操作
有序集合支持各种导航操作,如查找小于某个值的最大元素、查找大于某个值的最小元素、获取指定范围内的所有元素等。
6.3、高效性
跳表在保持有序性的同时,可以支持快速的插入和删除,以及在并发环境中的高效访问。
6.4、灵活性
允许用户自定义排序策略(通过提供比较器),使得可以根据应用的需求选择不同的排序逻辑。
代码如下所示:
import java.util.Comparator;
import java.util.concurrent.ConcurrentSkipListMap;public class CustomSortingExample {public static void main(String[] args) {// 创建一个自定义比较器的ConcurrentSkipListMapComparator<String> customComparator = (s1, s2) -> {// 按字符串长度排序,长度相同则按字母顺序int lengthCompare = Integer.compare(s1.length(), s2.length());return lengthCompare != 0 ? lengthCompare : s1.compareTo(s2);};ConcurrentSkipListMap<String, Integer> map = new ConcurrentSkipListMap<>(customComparator);// 添加元素map.put("apple", 1);map.put("banana", 2);map.put("pear", 3);map.put("orange", 4);map.put("kiwi", 5);// 输出结果将按自定义顺序排列System.out.println("Sorted map: " + map);// 输出: Sorted map: {kiwi=5, pear=3, apple=1, banana=2, orange=4}}
}总结
一个有序的多级链表结构,通过随机化技术来高效地实现元素查找、插入和删除操作。它支持对数据的快速检索和有序访问,因此广泛应用于需要维护和操作有序集合的多线程环境。这使得成为 Java 中一个非常强大的并发映射实现。
7、并发控制机制
ConcurrentSkipListMap采用了无锁并发控制机制,主要包括以下几个方面:
7.1、CAS(Compare-And-Swap)
使用UNSAFE.compareAndSwapObject()/VarHandle.compareAndSet()原子更新引用,主要用于节点链接、断开和值更新,确保在多线程环境下对共享引用的安全更新。
CAS是无锁算法的核心,它是一种原子操作,比较内存位置的当前值与预期值,只有当它们相同时才将该位置更新为新值。
代码示例如下:
// 使用Unsafe类的CAS操作
boolean casNext(Node<K,V> cmp, Node<K,V> val) {return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}// JDK 9+使用VarHandle
private static final VarHandle NEXT;
static {try {NEXT = MethodHandles.lookup().findVarHandle(Node.class, "next", Node.class);} catch (ReflectiveOperationException e) {throw new ExceptionInInitializerError(e);}
}boolean casNext(Node<K,V> cmp, Node<K,V> val) {return NEXT.compareAndSet(this, cmp, val);
}
7.2、版本标记
使用节点引用的低位比特作为标记(marked bit),节点删除时先标记引用,再实际删除,防止并发问题,这种两阶段删除确保了并发安全。
代码示例:
// 标记节点已删除
static <K,V> Node<K,V> markNode(Node<K,V> n) {return (n == null) ? null : new Node<K,V>(n.key, n.value, n, null);
}// 检查节点是否已标记删除
static <K,V> boolean isMarker(Node<K,V> n) {return (n != null && n.next == n);
}
7.3、无阻塞设计
所有操作均不使用阻塞锁,冲突时使用重试而非阻塞等待,确保系统整体进展,防止死锁和优先级倒置。
读取-复制-写入模式:
修改操作不直接修改现有结构,而是创建新节点,通过CAS操作将新节点链接到正确位置。
// 添加新节点的简化示例
Node<K,V> newNode = new Node<K,V>(key, value, null);
for (;;) {Node<K,V> next = pred.next;if (next != null && next.key.compareTo(key) < 0) {pred = next;continue;}newNode.next = next;if (pred.casNext(next, newNode))break;
}
7.4、辅助删除
线程在发现已标记为删除的节点时会帮助完成物理删除,保证即使标记节点的线程失败,节点最终也会被删除,分摊了删除工作,防止删除节点堆积。
// 帮助删除已标记节点的简化示例
if (n != null && n.isMarked()) {pred.casNext(n, n.next); // 尝试物理删除continue; // 重试
}
7.5、寻找前驱节点
findPredecessor方法是核心操作,用于定位操作点,从最高层开始,通过索引层快速接近目标位置,处理并跳过已标记删除的节点。
7.6、弱一致性
迭代器反映创建时的部分快照状态,不抛出ConcurrentModificationException,size()方法可能不准确,返回估计值。
这些机制共同作用,确保了ConcurrentSkipListMap在高并发环境下的安全性和高性能。
8、常用方法
8.1、put方法
put方法是ConcurrentSkipListMap的核心写操作,它的实现体现了跳表的并发插入算法:
public V put(K key, V value) {if (value == null)throw new NullPointerException();return doPut(key, value, false);
}private V doPut(K key, V value, boolean onlyIfAbsent) {Node<K,V> z; // 新增节点if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 外层循环,处理重试outer: for (;;) {// 查找插入位置的前驱节点Node<K,V> b = findPredecessor(key, cmp);Node<K,V> n = b.next;// 内层循环,处理同一位置的冲突for (;;) {if (n != null) {Node<K,V> f = n.next;// 如果b不再是n的前驱,说明有并发修改,重试if (n != b.next)continue outer;// 如果n已被标记删除,帮助删除并重试if (f != null && f.value == n)continue outer;// 比较键,决定是继续查找还是更新现有节点int c = cpr(cmp, key, n.key);if (c > 0) {b = n;n = f;continue;}// 找到相同的键,更新值if (c == 0) {if (onlyIfAbsent || n.casValue(n.value, value))return n.value;continue outer; // CAS失败,重试}}// 准备插入新节点z = new Node<K,V>(key, value, n);if (!b.casNext(n, z))continue outer; // CAS失败,重试break;}// 成功插入节点后,随机决定是否需要增加索引层int rnd = ThreadLocalRandom.nextSecondarySeed();if ((rnd & 0x80000001) == 0) { // 大约有1/4的概率需要建索引int level = 1, max;while (((rnd >>>= 1) & 1) != 0)++level;// 创建并链接索引节点Index<K,V> idx = null;HeadIndex<K,V> h = head;if (level <= (max = h.level)) {for (int i = 1; i <= level; ++i)idx = new Index<K,V>(z, idx, null);}else { // 需要增加层级level = max + 1;Index<K,V>[] idxs = new Index[level+1];for (int i = 1; i <= level; ++i)idxs[i] = idx = new Index<K,V>(z, idx, null);// 尝试增加层级,可能会失败并重试for (;;) {h = head;int oldLevel = h.level;if (level <= oldLevel)break;HeadIndex<K,V> newh = new HeadIndex<K,V>(h.node, h, null, level);if (casHead(h, newh)) {// 成功增加层级,设置新层的链接h = newh;idx = idxs[level];for (int i = level; i > oldLevel; --i) {Index<K,V> ni = idxs[i];Index<K,V> pi = h;// 设置每层的右侧链接for (;;) {Index<K,V> r = pi.right;if (r != null && r.node.key != null &&cpr(cmp, r.node.key, key) < 0) {pi = r;continue;}ni.right = r;if (pi.casRight(r, ni))break;}}break;}}}// 设置现有层级的索引链接for (int i = 1; i <= max && i <= level; ++i) {Index<K,V> ni = idxs[i];for (;;) {Index<K,V> pi = findPredecessorIndex(key, i, cmp);Index<K,V> r = pi.right;if (r != null && r.node.key != null &&cpr(cmp, r.node.key, key) < 0)continue; // 右侧节点小于key,继续查找ni.right = r;if (pi.casRight(r, ni))break; // 成功链接}}}return null; // 新增节点,返回null}
}
源码分析:
1、put操作首先调用doPut方法,该方法同时处理put和putIfAbsent操作。
2、查找过程从findPredecessor开始,该方法从最高索引层开始,逐层下降,最终定位到底层链表的合适位置。
3、在找到位置后,检查是否已存在相同键的节点:
如果存在,则尝试更新值。
如果不存在,则创建新节点并插入。
4、插入新节点后,随机决定是否需要为该节点创建索引层。
5、如果需要创建索引,会根据随机数决定索引的层数,并将索引节点链接到对应层。
6、如果新索引的层数超过当前最高层,则增加整个跳表的高度。
整个过程不使用锁,而是通过CAS操作和重试机制保证线程安全。
8.2、get操作
get方法是ConcurrentSkipListMap的核心读操作,它利用跳表的多层索引结构快速定位元素:
public V get(Object key) {return doGet(key);
}private V doGet(Object key) {if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 从最高层开始查找outer: for (;;) {// 获取当前最高层的头索引HeadIndex<K,V> h = head;Index<K,V> q = h;Index<K,V> r;// 从最高层开始,逐层向下查找for (;;) {// 在当前层向右查找while ((r = q.right) != null) {Node<K,V> n = r.node;K k = n.key;if (n.value == null) { // 节点已被删除if (!q.unlink(r))break; // 帮助删除失败,重新开始continue;}// 比较键,决定是继续向右还是向下int c = cpr(cmp, key, k);if (c > 0) {q = r; // 继续向右continue;}else if (c == 0) {return n.value; // 找到匹配的键,返回值}else // c < 0,当前位置的键大于目标键,停止向右break;}// 到达当前层的尽头或找到大于目标键的位置// 如果有下一层,继续向下查找Index<K,V> d = q.down;if (d != null) {q = d;continue;}// 已到达最底层,开始在链表中查找break;}// 在底层链表中查找Node<K,V> b = q.node;Node<K,V> n = b.next;while (n != null) {K k = n.key;if (n.value == null) { // 节点已被删除n = n.next;continue;}// 比较键,决定是继续查找还是返回结果int c = cpr(cmp, key, k);if (c > 0) {b = n;n = n.next;}else if (c == 0) {return n.value; // 找到匹配的键,返回值}else // c < 0,未找到匹配的键break;}return null; // 未找到匹配的键,返回null}
}
源码分析:
get操作首先调用doGet方法
1、从最高索引层开始,利用索引结构快速定位到目标位置附近。
2、在每一层中,向右查找直到找到大于或等于目标键的位置。
3、如果找到等于目标键的节点,直接返回其值,否则,继续向下一层查找,直到到达底层链表。4、在底层链表中线性查找目标键,如果找到匹配的键,返回其值;否则返回null。
整个过程不需要加锁,是一个纯读操作。
get操作充分利用了跳表的多层索引结构,使得查找操作的平均时间复杂度为O(log n),这与红黑树等平衡树结构相当。由于不需要加锁,多个线程可以同时进行读操作,提供了极高的并发读取性能。
8.3、remove操作
remove方法是ConcurrentSkipListMap的核心删除操作,它实现了无锁的并发删除算法:
public V remove(Object key) {return doRemove(key, null);
}final V doRemove(Object key, Object value) {if (key == null)throw new NullPointerException();Comparator<? super K> cmp = comparator;// 外层循环,处理重试outer: for (;;) {// 查找要删除节点的前驱节点Node<K,V> b = findPredecessor(key, cmp);Node<K,V> n = b.next;// 内层循环,处理同一位置的冲突for (;;) {if (n == null)return null; // 未找到要删除的节点Node<K,V> f = n.next;// 如果b不再是n的前驱,说明有并发修改,重试if (n != b.next)continue outer;// 如果n已被标记删除,帮助删除并重试if (f != null && f.value == n)continue outer;// 比较键,决定是继续查找还是删除当前节点int c = cpr(cmp, key, n.key);if (c < 0)return null; // 未找到要删除的节点if (c > 0) {b = n;n = f;continue; // 继续查找}// 找到匹配的键,检查值是否也匹配(用于removeValue操作)if (value != null && !value.equals(n.value))return null;// 尝试将节点的值设为null,标记为已删除if (!n.casValue(n.value, null))continue outer; // CAS失败,重试// 尝试物理删除节点(更新前驱节点的next引用)if (!n.casNext(f, new Node<K,V>(n.key, null, f, n)))findNode(n.key); // 帮助完成删除// 物理删除成功,可能需要删除索引节点findPredecessor(key, cmp); // 清理索引// 如果没有其他线程在使用索引,可能需要降低跳表高度if (head.right == null && head.down != null) {HeadIndex<K,V> d = head.down;if (d.right == null && d.down != null)casHead(head, d); // 尝试降低高度}return (V)n.value; // 返回被删除的值}}
}
源码分析:
remove操作首先调用doRemove方法,该方法同时处理remove和removeValue操作
1、查找过程从findPredecessor开始,定位到要删除节点的前驱节点
2、找到要删除的节点后,执行两阶段删除:
3、首先使用CAS操作将节点的值设为null,标记为逻辑删除
4、然后尝试物理删除节点,更新前驱节点的next引用
5、如果物理删除成功,还需要清理索引节点
6、如果跳表的高度过高(顶层索引为空),可能需要降低跳表高度
整个过程不使用锁,而是通过CAS操作和重试机制保证线程安全
remove操作的关键在于它的两阶段删除设计:先逻辑删除(标记节点),再物理删除(移除链接)。这种设计确保了在并发环境下的安全删除,即使有其他线程同时访问被删除的节点,也不会导致不一致状态。
8.4、迭代器实现
ConcurrentSkipListMap的迭代器实现提供了弱一致性的保证,不会抛出ConcurrentModificationException:
public Set<K> keySet() {KeySet<K> ks = keySet;return (ks != null) ? ks : (keySet = new KeySet<K>(this));
}public Collection<V> values() {Values<V> vs = values;return (vs != null) ? vs : (values = new Values<V>(this));
}public Set<Map.Entry<K,V>> entrySet() {EntrySet<K,V> es = entrySet;return (es != null) ? es : (entrySet = new EntrySet<K,V>(this));
}// KeySet迭代器
static final class KeyIterator<K,V> extends Iter<K,V> implements Iterator<K> {public K next() {Node<K,V> n = advance();return n.key;}
}// Values迭代器
static final class ValueIterator<K,V> extends Iter<K,V> implements Iterator<V> {public V next() {Node<K,V> n = advance();return n.value;}
}// EntrySet迭代器
static final class EntryIterator<K,V> extends Iter<K,V> implements Iterator<Map.Entry<K,V>> {public Map.Entry<K,V> next() {Node<K,V> n = advance();return new AbstractMap.SimpleImmutableEntry<K,V>(n.key, n.value);}
}// 基础迭代器类
abstract static class Iter<K,V> {Node<K,V> next; // 下一个要返回的节点Node<K,V> lastReturned; // 最后一个返回的节点V nextValue; // 缓存的下一个值Iter(ConcurrentSkipListMap<K,V> map) {// 初始化,找到第一个有效节点Node<K,V> n = map.findFirst();next = n;nextValue = (n == null) ? null : n.value;}public final boolean hasNext() {return next != null;}// 获取下一个有效节点final Node<K,V> advance() {Node<K,V> n = next;if (n == null)throw new NoSuchElementException();lastReturned = n;// 查找下一个有效节点Node<K,V> f = n.next;for (;;) {if (f == null) {next = null;nextValue = null;break;}V v = f.value;if (v != null) { // 找到有效节点next = f;nextValue = v;break;}// 跳过已删除的节点f = f.next;}return n;}public final void remove() {Node<K,V> l = lastReturned;if (l == null)throw new IllegalStateException();map.remove(l.key);lastReturned = null;}
}
源码分析:
1、ConcurrentSkipListMap提供了三种视图:keySet、values和entrySet,每种视图都有对应的迭代器。
2、所有迭代器都继承自基础迭代器类Iter,共享核心逻辑。
3、迭代器在创建时会找到第一个有效节点作为起点。
4、advance()方法负责查找下一个有效节点,跳过已删除的节点。
5、迭代器支持remove操作,但实际上是调用map的remove方法,而不是直接修改结构。
6、迭代器提供弱一致性保证,可能看不到迭代过程中的并发修改。
不会抛出ConcurrentModificationException,即使在迭代过程中有其他线程修改了map。
ConcurrentSkipListMap的迭代器设计体现了并发集合的一个重要特性:弱一致性。这种设计在保证安全性的同时,提供了更好的并发性能,但使用者需要了解其语义,不能期望看到所有的最新修改。
小结
通过分段锁、无锁读取、内部节点锁、跳表的设计和原子操作等机制,有效确保了在高并发环境下的线程安全。
参考文章:
1、JUC并发集合-ConcurrentSkipListMap_concurrentskiplistmap在微服务中的用法-CSDN博客
2、ConcurrentSkipListMap 图解_concurrentskiplistmap.headmap-CSDN博客