llamafactory SFT 从断点恢复训练
背景
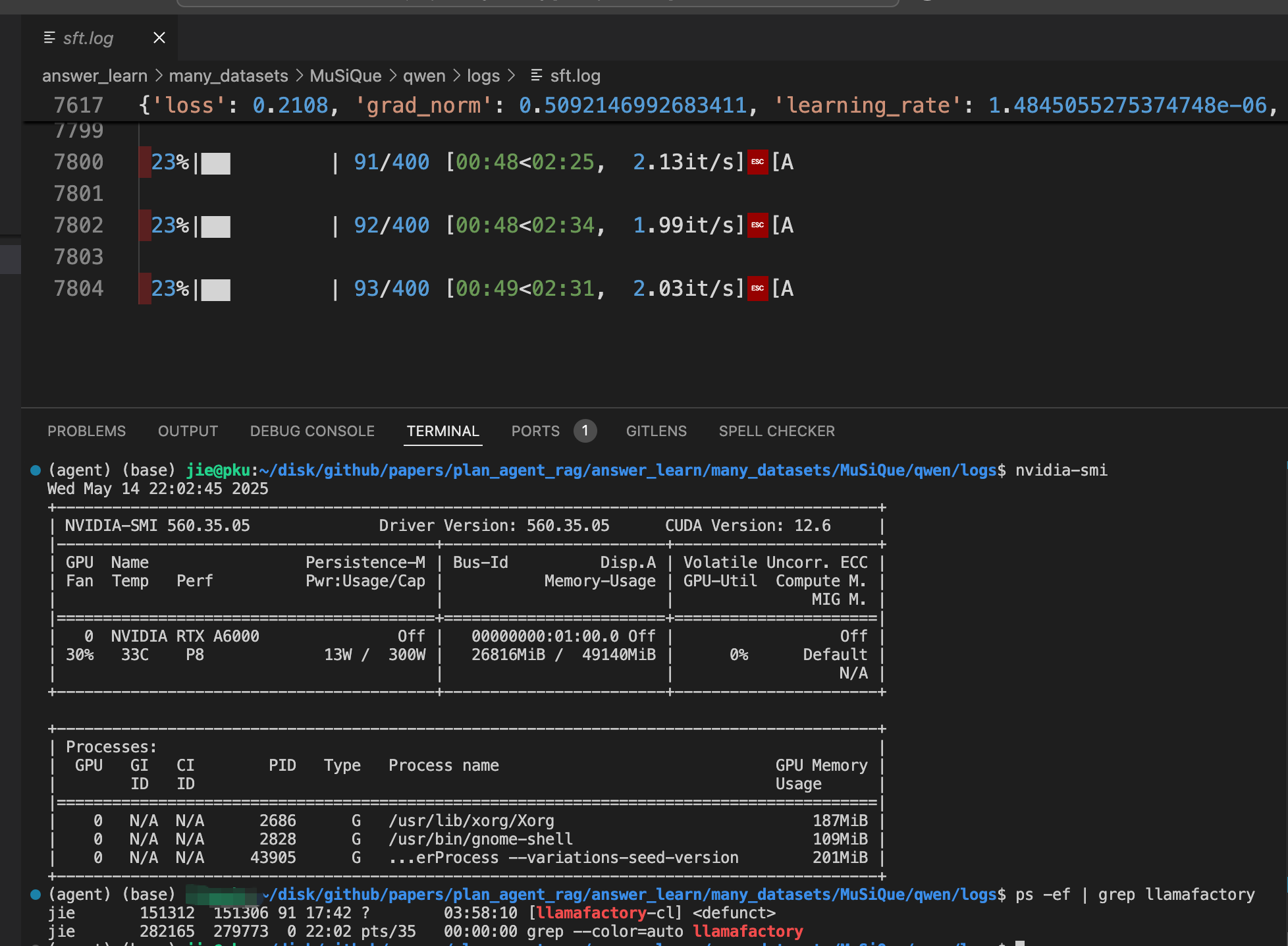
我使用llamafactory sft 微调模型的时候。gpu停止运行了。日志文件没有任何的报错信息。
显存还是占用状态。
查看llamafactory的进程是下述信息:
151312 151306 91 17:42 ? 03:58:10 [llamafactory-cl]
既然如此,那就只能从断点恢复训练了。
这里是 GitHub 仓库对应的 issues: https://github.com/hiyouga/LLaMA-Factory/issues/1713

断点重启
如果只是恢复一个模型的训练,手动修改 resume_from_checkpoint 参数:
llamafactory-cli train \--resume_from_checkpoint ${save_path}/${resume_from_checkpoint} \--stage sft \--do_train True \--model_name_or_path ${model_name_or_path} \--preprocessing_num_workers 16 \--finetuning_type lora \--template $template \--flash_attn auto \--dataset_dir $dataset_dir \--dataset $alpaca_dataset_name \--cutoff_len 2048 \--learning_rate 2e-05 \--num_train_epochs 2.0 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 100 \--packing False \--report_to none \--output_dir ${save_path} \--fp16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 16 \--lora_alpha 32 \--lora_dropout 0 \--lora_target all \--val_size 0.1 \--eval_strategy steps \--eval_steps 100 \--per_device_eval_batch_size 1 >${log_dir}/sft.log 2>&1
但我想使用 shell 脚本,自动地从断点恢复训练,减轻手动负担:
下述脚本可以找到当前文件夹,最大的checkpoint文件夹:
# 检查 all_results.json 是否不存在,同时 trainer_log.jsonl 是否存在
if [ ! -f "all_results.json" ] && [ -f "trainer_log.jsonl" ]; then# 找出所有 checkpoint-数字 的文件夹,并提取最大的编号max_folder=$(ls -d checkpoint-*/ 2>/dev/null | awk -F '-' '{print $2}' | sort -n | tail -1)if [ -n "$max_folder" ]; thenecho "最大的 checkpoint 文件夹是: checkpoint-$max_folder"elseecho "没有找到任何 checkpoint 文件夹"fi
elseecho "条件不满足:all_results.json 存在 或 trainer_log.jsonl 不存在"
fi
下述是一个自动加载checkpoint,恢复训练的shell脚本:
resume_from_checkpoint=None# 检查 all_results.json 不存在,同时 trainer_log.jsonl 存在,代表模型没有训练完成就退出了
if [ ! -f "${save_path}/all_results.json" ] && [ -f "${save_path}/trainer_log.jsonl" ]; then# 找出所有 checkpoint-数字 的文件夹,并提取最大的编号max_folder=$(ls -d ${save_path}/checkpoint-*/ 2>/dev/null | awk -F '-' '{print $2}' | sort -n | tail -1)if [ -n "${max_folder}" ]; thenecho "最大的 checkpoint 文件夹是: checkpoint-${max_folder}"resume_from_checkpoint=checkpoint-${max_folder}fi
elseecho "模型可能微调完成,退出微调"
fiecho "resume_from_checkpoint: ${resume_from_checkpoint}"if [ -f "${save_path}/all_results.json" ]; thenecho "${save_path}/trainer_log.jsonl, just skip sft"
elsellamafactory-cli train \--resume_from_checkpoint ${save_path}/${resume_from_checkpoint} \--stage sft \--do_train True \--model_name_or_path ${model_name_or_path} \--preprocessing_num_workers 16 \--finetuning_type lora \--template $template \--flash_attn auto \--dataset_dir $dataset_dir \--dataset $alpaca_dataset_name \--cutoff_len 2048 \--learning_rate 2e-05 \--num_train_epochs 2.0 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 100 \--packing False \--report_to none \--output_dir ${save_path} \--fp16 True \--plot_loss True \--trust_remote_code True \--ddp_timeout 180000000 \--include_num_input_tokens_seen True \--optim adamw_torch \--lora_rank 16 \--lora_alpha 32 \--lora_dropout 0 \--lora_target all \--val_size 0.1 \--eval_strategy steps \--eval_steps 100 \--per_device_eval_batch_size 1 >${log_dir}/sft.log 2>&1echo "lora finish save at ${save_path}"
fi
运行脚本后恢复训练,日志文件信息如下:
[INFO|trainer.py:748] 2025-05-16 21:51:23,017 >> Using auto half precision backend
[INFO|trainer.py:2813] 2025-05-16 21:51:23,018 >> Loading model from /mnt/mydisk/github/papers/plan_agent_rag/answer_learn/many_datasets/wiki_mqa/llama3/output/saves/lora//checkpoint-300/.
[INFO|trainer.py:2414] 2025-05-16 21:51:28,423 >> ***** Running training *****
[INFO|trainer.py:2415] 2025-05-16 21:51:28,423 >> Num examples = 3,591
[INFO|trainer.py:2416] 2025-05-16 21:51:28,423 >> Num Epochs = 2
[INFO|trainer.py:2417] 2025-05-16 21:51:28,423 >> Instantaneous batch size per device = 2
[INFO|trainer.py:2420] 2025-05-16 21:51:28,423 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:2421] 2025-05-16 21:51:28,423 >> Gradient Accumulation steps = 4
[INFO|trainer.py:2422] 2025-05-16 21:51:28,423 >> Total optimization steps = 898
[INFO|trainer.py:2423] 2025-05-16 21:51:28,425 >> Number of trainable parameters = 41,943,040
[INFO|trainer.py:2445] 2025-05-16 21:51:28,425 >> Continuing training from checkpoint, will skip to saved global_step
[INFO|trainer.py:2446] 2025-05-16 21:51:28,425 >> Continuing training from epoch 0
[INFO|trainer.py:2447] 2025-05-16 21:51:28,425 >> Continuing training from global step 300
[INFO|trainer.py:2449] 2025-05-16 21:51:28,425 >> Will skip the first 0 epochs then the first 1200 batches in the first epoch.0%| | 0/898 [00:00<?, ?it/s]34%|███▎ | 301/898 [00:08<00:17, 34.10it/s]34%|███▎ | 302/898 [00:22<00:17, 34.10it/s]34%|███▎ | 303/898 [00:24<01:00, 9.90it/s]34%|███▍ | 304/898 [00:31<01:28, 6.69it/s]
脚本中可能有一些本地文件、日志保存的变量,请大家忽略掉!