leetcode-hot-100 (子串)
1. 和为 K 的子数组
题目链接:和为 K 的子数组
题目描述:给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
解答
方法一:暴力枚举法(Brute force)
看到这道题目,首先肯定想到的是暴力破解,也就是遍历所有的子数组,计算每个子数组的和,如果等于 k k k,就计数加一。
具体的思想如下:
- 枚举所有起点 i i i(从 0 0 0 到 n − 1 n-1 n−1)。
- 对于每个起点 i i i,枚举终点 j j j(从 i i i 到 n − 1 n-1 n−1)。
- 计算子数组 n u m s [ i . . j ] nums[i..j] nums[i..j] 的和。
- 如果和为 k k k,则计数器加一。
于是代码可以非常容易的写出来:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {int len = nums.size();int sum = 0;int ans = 0;for (int i = 0; i < len; i++) {for (int j = i; j < len; j++) {sum = 0;for (int l = i; l < j + 1; l++) {sum += nums[l];}if (sum == k)ans++;}}return ans;}
};
显然,上述代码的时间复杂度是很高的。肯定是过不了这道题目的,因此我们必须在原有代码的基础上进行优化。

显然,我们需要考虑的是能不能将 for 的次数减少,从而能够降低时间复杂度,于是我们回顾上述代码,发现最外层循环是不能够删除的,那么我们就看最里面的循环能不能消掉。实际上,我们在上述代码除了限定左边界(也就是开始位置)之外,还设定了右边界,这就导致需要在上一层循环,要是我不设定右边界,而是每来一个 j ,我都和给定的 k 进行比较,看是否匹配,要是匹配的话,说明成功,这样开始下一轮循环,这样就不需要最里面的这层循环了。
for (int l = i; l < j + 1; l++) {sum += nums[l];}
于是上述代码改进如下:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {int n = nums.size();int ans = 0;// 枚举所有可能的子数组起点 i 和终点 j(闭区间)for (int i = 0; i < n; ++i) {int sum = 0;for (int j = i; j < n; ++j) {sum += nums[j]; // 逐步累加,而不是每次都从头加if (sum == k) {++ans;// break; // 这里break不对,因为数组可以含有负数,要是都是正数的话,可以加上这个break,最好是不加,因为容易出现问题。}}}return ans;}
};
好的,提交,结果通过。
额,但是这个时间复杂度还是很高,不过欣慰的是空间复杂度比较的低。
方法二:前缀和 + 暴力查找
要是对算法有了解的,肯定是听说过前缀和的,也就是对于数组 n u m s [ 0... n ] nums[0...n] nums[0...n] 中的元素 n u m s [ j ] nums[j] nums[j] 中存储的不是原来 n u m s [ j ] nums[j] nums[j] 的值了,而是 从 n u m s [ 0 ] nums[0] nums[0] 到 n u m s [ j − 1 ] nums[j-1] nums[j−1] 的和.当然这只是大致的思想,具体编码可以根据题意稍稍变动。
于是我们的处理方法可以变成如下的步骤:
先预处理出数组的前缀和数组 prefix_sum,其中 prefix_sum[i] 表示从 nums[0] 到 nums[i-1] 的和。然后枚举任意两个位置 i < j,判断 prefix_sum[j] - prefix_sum[i] == k 是否成立。
根据上述思想,编码如下:
class Solution {
public:int subarraySum(vector<int>& nums, int k) {int n = nums.size();vector<int> prefix_sum(n + 1, 0);// 构造前缀和数组for (int i = 0; i < n; ++i) {prefix_sum[i + 1] = prefix_sum[i] + nums[i];}int count = 0;// 枚举所有 i < j 的组合for (int j = 1; j <= n; ++j) {for (int i = 0; i < j; ++i) {if (prefix_sum[j] - prefix_sum[i] == k) {++count;}}}return count;}
};
结果好点了,但是还是不尽如人意:
方法三:前缀和 + 哈希表优化
核心思想:
利用前缀和的性质 + 哈希表记录出现次数,实现一次遍历解决问题。
关键公式:
prefix_sum[j] - prefix_sum[i] = k
=>prefix_sum[j] - k = prefix_sum[i]
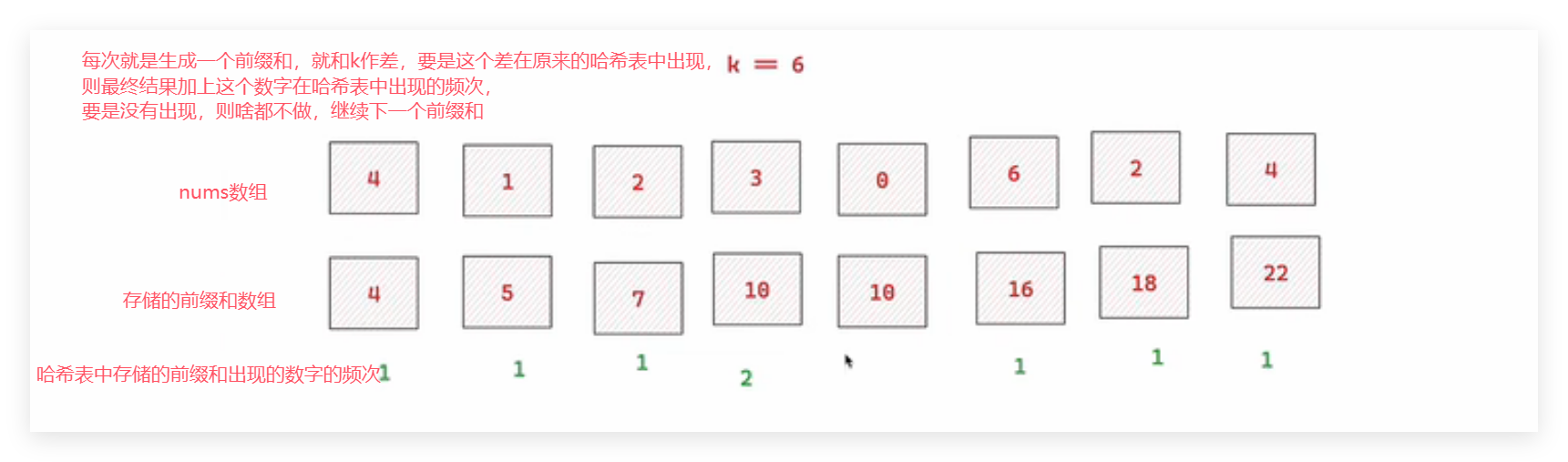
也就是说,在遍历到j时,只要我们知道前面有多少个prefix_sum[i]等于prefix_sum[j] - k,就能知道有多少个子数组以j结尾且和为k。
实现步骤:
- 初始化一个哈希表
count_map,用来记录某个前缀和出现的次数。 - 设置初始条件:
prefix_sum = 0出现了 1 次(表示空子数组)。 - 遍历数组,逐步累加前缀和
current_sum。 - 每次计算
current_sum - k,查看哈希表中是否有这个值:- 要是有,则加上它的出现次数到结果中。
- 将当前
current_sum的值加入哈希表中,继续下一轮。
class Solution {
public:int subarraySum(vector<int>& nums, int k) {unordered_map<int, int> count_map;count_map[0] = 1; // 表示前缀和为 0 出现了一次(空子数组)int current_sum = 0;int count = 0;for (int num : nums) {current_sum += num;// 查找是否有 current_sum - k 出现过if (count_map.find(current_sum - k) != count_map.end()) {count += count_map[current_sum - k];}// 将当前前缀和加入 map 中count_map[current_sum]++;}return count;}
};
结果还不错:
官方答案和上述差不多。
2. 滑动窗口最大值
题目链接:滑动窗口最大值
题目描述:
给你一个整数数组 n u m s nums nums,有一个大小为 k k k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k k k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
解答
看到这道题目,觉得有点类似于卷积中的最大池化,最大池化是在二维数组中找寻一个最大值,这个是在一维中,感觉思路应该差不多(只是我的看法)。
方法一:暴力破解(超时)
还是一样,肯定最简单也是最好想到的方法就是暴力破解法。
也就是对于每个滑动窗口的位置,直接遍历窗口中的 k k k 个元素,找出最大值。
class Solution {
public:vector<int> maxSlidingWindow(vector<int>& nums, int k) {vector<int> result;int n = nums.size();// 防止无效输入if (n == 0 || k == 0) return result;// 遍历所有滑动窗口的位置for (int i = 0; i <= n - k; ++i) {int max_val = nums[i];// 找当前窗口的最大值for (int j = i + 1; j < i + k; ++j) {max_val = max(max_val, nums[j]);}result.push_back(max_val);}return result;}
};
不用说,包超时的,要不然这道题目就不会标记为难题了。
仔细读题,可以发现,相邻的滑动窗口,实际上共用 k − 1 k-1 k−1 个元素,只有一个元素使变化的,因此上述暴力破解的方法有很多都是没有必要的,下面就需要根据这个点来进行代码优化。
方法二: 优先队列
这个方法借鉴的是官方的题解(点此进行详细查看官方题解)。
我想不到,只能对官方题解做出一些说明:
- 使用一个 大根堆(优先队列) 来维护当前窗口中元素的 (值, 索引) 对。
- 初始时,将前
k个元素全部加入堆中。 - 每次窗口右移一位时:
- 将当前新元素
(nums[i], i)加入堆。 - 弹出堆顶元素(最大值),如果该元素的索引 不在当前窗口范围内,继续弹出直到堆顶元素在窗口内。
- 将当前新元素
- 堆顶元素即为当前窗口的最大值。
- 时间复杂度:
O(n log k),因为每个元素最多进堆、出堆一次。
class Solution {
public:vector<int> maxSlidingWindow(vector<int>& nums, int k) {int n = nums.size();vector<int> result;// 大根堆,存储 (元素值, 索引)priority_queue<pair<int, int>> max_heap;// 初始化:先把前 k 个元素放入堆中for (int i = 0; i < k; ++i) {max_heap.push({nums[i], i});}// 第一个窗口的最大值result.push_back(max_heap.top().first);// 滑动窗口移动for (int i = k; i < n; ++i) {// 当前新元素入堆max_heap.push({nums[i], i});// 移除堆顶不在窗口内的元素while (!max_heap.empty() && max_heap.top().second <= i - k) {max_heap.pop();}// 此时堆顶是当前窗口最大值result.push_back(max_heap.top().first);}return result;}
};

简要说一下代码的原理,就是这个队列中,每次存储的值我其实不在乎,只需要堆顶的元素是进入堆中所有的元素中最大的那一个即可。同时引入 pair 是为了判断这个堆顶元素,要是其索引小于 i - k + 1,则说明它已经不在当前窗口内了,应该从堆中移除。
简单模拟一下过程:
假设输入数组为 nums = [1, 3, -1, -3, 5, 3, 6, 7],窗口大小 k = 3。
初始化阶段
- 将前
k=3个元素[1, 3, -1]加入优先队列(大根堆)中。 - 初始时的优先队列为:
[(3, 1), (1, 0), (-1, 2)]
当前优先队列状态:
[(3, 1), (1, 0), (-1, 2)]
结果列表: [3]
第一次滑动 (i=3)
- 新元素
-3及其索引(i=3)加入优先队列。 - 加入新元素后优先队列:
[(3, 1), (1, 0), (-1, 2), (-3, 3)] - 移除不在窗口范围内的堆顶元素(如果有的话)。此时不需要移除任何元素,因为
(3, 1)在窗口范围内。
当前优先队列状态:
[(3, 1), (1, 0), (-1, 2), (-3, 3)]
结果列表: [3, 3]
第二次滑动 (i=4)
- 新元素
5及其索引(i=4)加入优先队列。 - 加入新元素后优先队列:
[(5, 4), (3, 1), (-1, 2), (-3, 3)] - 移除不在窗口范围内的堆顶元素(如果有的话)。此时不需要移除任何元素,因为
(5, 4)在窗口范围内。
当前优先队列状态:
[(5, 4), (3, 1), (-1, 2), (-3, 3)]
结果列表: [3, 3, 5]
第三次滑动 (i=5)
- 新元素
3及其索引(i=5)加入优先队列。 - 加入新元素后优先队列:
[(5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)] - 移除不在窗口范围内的堆顶元素(如果有的话)。此时不需要移除任何元素,因为
(5, 4)在窗口范围内。
当前优先队列状态:
[(5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)]
结果列表: [3, 3, 5, 5]
第四次滑动 (i=6)
- 新元素
6及其索引(i=6)加入优先队列。 - 加入新元素后优先队列:
[(6, 6), (5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)] - 移除不在窗口范围内的堆顶元素(如果有的话)。此时不需要移除任何元素,因为
(6, 6)在窗口范围内。
当前优先队列状态:
[(6, 6), (5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)]
结果列表: [3, 3, 5, 5, 6]
第五次滑动 (i=7)
- 新元素
7及其索引(i=7)加入优先队列。 - 加入新元素后优先队列:
[(7, 7), (6, 6), (5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)] - 移除不在窗口范围内的堆顶元素(如果有的话)。此时不需要移除任何元素,因为
(7, 7)在窗口范围内。
当前优先队列状态:
[(7, 7), (6, 6), (5, 4), (3, 5), (3, 1), (-1, 2), (-3, 3)]
结果列表: [3, 3, 5, 5, 6, 7]
方法三: 单调队列
核心思想:
- 初始化:
- 将前 k 个元素对应的下标加入双端队列,并确保队列中元素按值递减排列。
- 处理后续元素:
每次向右移动滑动窗口时,将新元素的下标加入队列,并保持队列的单调性(即移除所有比新 - 元素小或相等的元素)。- 移除队列头部不在当前窗口范围内的元素。
- 获取最大值:
- 队列头部元素始终是当前窗口的最大值。
- 关键操作:
- 入队:每次添加新元素时,移除队尾所有小于等于新元素的元素。
- 出队:移除队头不在窗口范围内的元素。
代码如下:
class Solution {
public:vector<int> maxSlidingWindow(vector<int>& nums, int k) {vector<int> result;deque<int> deq; // 存储下标for (int i = 0; i < nums.size(); ++i) {// 移除队列头部不在窗口范围内的元素if (!deq.empty() && deq.front() == i - k) {deq.pop_front();}// 移除所有比当前元素小的元素(保持队列单调递减)while (!deq.empty() && nums[deq.back()] <= nums[i]) {deq.pop_back();}// 添加当前元素下标到队列deq.push_back(i);// 当窗口形成后,记录最大值if (i >= k - 1) {result.push_back(nums[deq.front()]);}}return result;}
};

简单举一个例子:
给定数组 nums = [1, 3, -1, -3, 5, 3, 6, 7] 和窗口大小 k = 3,我们使用单调双端队列来求出每个滑动窗口中的最大值。
📌 步骤分解
✅ 初始状态:窗口 [1, 3, -1]
- 加入索引
0(值为1)→ 队列为[0] - 加入索引
1(值为3),弹出0→ 队列为[1] - 加入索引
2(值为-1)→ 队列为[1, 2] - 当前窗口最大值为
nums[1] = 3
✅ 结果列表:[3]
➡️ 第一次滑动:窗口 [3, -1, -3]
- 新元素索引
3(值为-3) - 由于
-3 <= nums[2],直接加入 → 队列为[1, 2, 3] - 队首
1在窗口内
✅ 结果列表:[3, 3]
➡️ 第二次滑动:窗口 [-1, -3, 5]
- 新元素索引
4(值为5) - 弹出
3(-3 < 5),弹出2(-1 < 5),弹出1(3 < 5)→ 队列为空 - 加入
4→ 队列为[4] - 队首
4在窗口内
✅ 结果列表:[3, 3, 5]
➡️ 第三次滑动:窗口 [-3, 5, 3]
- 新元素索引
5(值为3) 3 <= nums[4] = 5,所以保留4,加入5→ 队列为[4, 5]- 队首
4在窗口内
✅ 结果列表:[3, 3, 5, 5]
➡️ 第四次滑动:窗口 [5, 3, 6]
- 新元素索引
6(值为6) - 弹出
5(3 < 6),弹出4(5 < 6)→ 队列为空 - 加入
6→ 队列为[6] - 队首
6在窗口内
✅ 结果列表:[3, 3, 5, 5, 6]
➡️ 第五次滑动:窗口 [3, 6, 7]
- 新元素索引
7(值为7) - 弹出
6(6 < 7)→ 队列为空 - 加入
7→ 队列为[7] - 队首
7在窗口内
✅ 结果列表:[3, 3, 5, 5, 6, 7]
✅ 最终结果
输入: nums = [1, 3, -1, -3, 5, 3, 6, 7], k = 3
输出: [3, 3, 5, 5, 6, 7]
| 步骤 | 窗口内容 | 最大值 |
|---|---|---|
| 1 | [1, 3, -1] | 3 |
| 2 | [3, -1, -3] | 3 |
| 3 | [-1, -3, 5] | 5 |
| 4 | [-3, 5, 3] | 5 |
| 5 | [5, 3, 6] | 6 |
| 6 | [3, 6, 7] | 7 |
方法四: 分块 + 预处理
首先将数组按每 k 个元素一组进行划分,预处理出两个辅助数组:
prefix_max[i]:表示从当前块的开头到位置 i 的最大值(即前缀最大值)。
suffix_max[i]:表示从位置 i 到当前块结尾的最大值(即后缀最大值)。
这样在查询任意长度为 k 的滑动窗口时:
如果窗口刚好是一个完整的块(i 是 k 的倍数),直接取该块的 prefix_max 或 suffix_max 即可;
否则,这个窗口会跨越两个块,我们只需要比较:
当前块的 suffix_max[i]
下一块的 prefix_max[i + k - 1]
最终答案就是这两个值中的最大值。
class Solution {
public:vector<int> maxSlidingWindow(vector<int>& nums, int k) {int n = nums.size();vector<int> prefix_max(n);vector<int> suffix_max(n);vector<int> result;// Step 1: 填充 prefix_maxfor (int i = 0; i < n; ++i) {if (i % k == 0) {prefix_max[i] = nums[i];} else {prefix_max[i] = max(prefix_max[i - 1], nums[i]);}}// Step 2: 填充 suffix_maxsuffix_max[n - 1] = nums[n - 1];for (int i = n - 2; i >= 0; --i) {if ((i + 1) % k == 0) {suffix_max[i] = nums[i];} else {suffix_max[i] = max(suffix_max[i + 1], nums[i]);}}// Step 3: 枚举每个窗口起点 ifor (int i = 0; i <= n - k; ++i) {int j = i + k - 1;result.push_back(max(suffix_max[i], prefix_max[j]));}return result;}
};
下面的这个大佬可视化不错,可以看看:可视化分块解法
3. 最小覆盖子串
题目链接:最小覆盖子串
题目描述:
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。
解答
只能依照官方的思路了,官方的题解链接:官方题解
🧠 核心思路
1. 使用哈希表或数组来统计字符频率
- 我们用两个哈希表(或者数组):
need[c]:记录子串t中每个字符所需的数量。window[c]:记录当前滑动窗口中每个字符的数量。
2. 滑动窗口框架
使用双指针技巧,维护一个左右开闭区间 [left, right) 表示当前窗口。
- 右指针
right不断向右扩展窗口,直到窗口满足条件。 - 一旦窗口满足条件,尝试收缩左指针
left,以寻找更小的有效窗口。 - 在这个过程中不断更新最小有效窗口的起始位置和长度。
3. 引入计数变量优化判断
- 使用一个变量
valid来记录当前窗口中满足need[c]数量要求的字符种类数。- 当某个字符在窗口中的数量达到了
need[c],就增加valid。 - 如果该字符数量又不满足了,则减少
valid。
- 当某个字符在窗口中的数量达到了
- 当
valid == need.size()时,说明当前窗口涵盖了t中所有字符并满足数量要求。
📐 伪代码逻辑
function minWindow(s, t):# 哈希表记录需要的字符和当前窗口的字符数量need = defaultdict(int)window = defaultdict(int)# 初始化 need 字典for char in t:need[char] += 1left = 0right = 0valid = 0 # 记录满足 need 条件的字符个数start = 0 # 最小窗口起始索引length = ∞ # 最小窗口长度while right < len(s):c = s[right]right += 1if c is in need:window[c] += 1if window[c] == need[c]:valid += 1# 当窗口满足条件时,尝试缩小左边界while valid == len(need):# 更新最小窗口结果if right - left < length:start = leftlength = right - leftd = s[left]left += 1if d is in need:if window[d] == need[d]:valid -= 1window[d] -= 1if length == ∞:return ""else:return s[start : start + length]
✅ 时间复杂度分析
- 整个算法中,每个字符最多被左右指针各访问一次,因此时间复杂度是 O(N),其中 N 是字符串
s的长度。
C++实现代码
class Solution {
public:string minWindow(string s, string t) {// 哈希表记录目标字符需求和当前窗口中的字符数量unordered_map<char, int> need, window;// 初始化目标字符需求for (char c : t) {need[c]++;}int left = 0, right = 0; // 滑动窗口双指针int valid = 0; // 当前窗口满足条件的字符种类数int start = 0; // 最小窗口起始位置int len = INT_MAX; // 最小窗口长度(初始化为最大值)while (right < s.size()) {char c = s[right]; // 即将加入窗口的字符right++;if (need.count(c)) {window[c]++;if (window[c] == need[c]) {valid++; // 该字符满足要求,更新 valid}}// 判断是否满足覆盖 t 的条件while (valid == need.size()) {// 更新当前找到的最小窗口if (right - left < len) {start = left;len = right - left;}char d = s[left]; // 即将移出窗口的字符left++;if (need.count(d)) {if (window[d] == need[d]) {valid--; // 移除后不满足条件了,减少 valid}window[d]--;}}}return (len == INT_MAX) ? "" : s.substr(start, len);}
};