大语言模型 07 - 从0开始训练GPT 0.25B参数量 - MiniMind 实机训练 预训练 监督微调
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。

训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)
数据收集与预处理
- 数据来源:收集海量文本(书籍、网页、新闻、百科、代码等),例如GPT-3使用了近45TB的原始文本。
- 数据清洗:去除噪声(HTML标签、重复文本、低质量内容)。过滤敏感或有害信息。
- 分词(Tokenization):使用子词分词方法(如Byte Pair Encoding, BPE)将文本切分为Token(例如GPT-3的词表大小约5万)。将文本分割为固定长度的序列(如512个Token的段落)。
无监督学习:无需人工标注,直接从原始文本学习。
- 规模化(Scaling Law):模型性能随数据量、参数规模、计算资源的增加而显著提升。
- 通用性:捕捉语法、语义、常识等广泛知识。
单卡训练
预训练
执行预训练,得到 pretrain_.pth 作为预训练的输出权重(其中为模型的dimension,默认为512)
cd ..
python train_pretrain.py
执行后对应的输出如下所示:LLM总参数量:25.830 百万
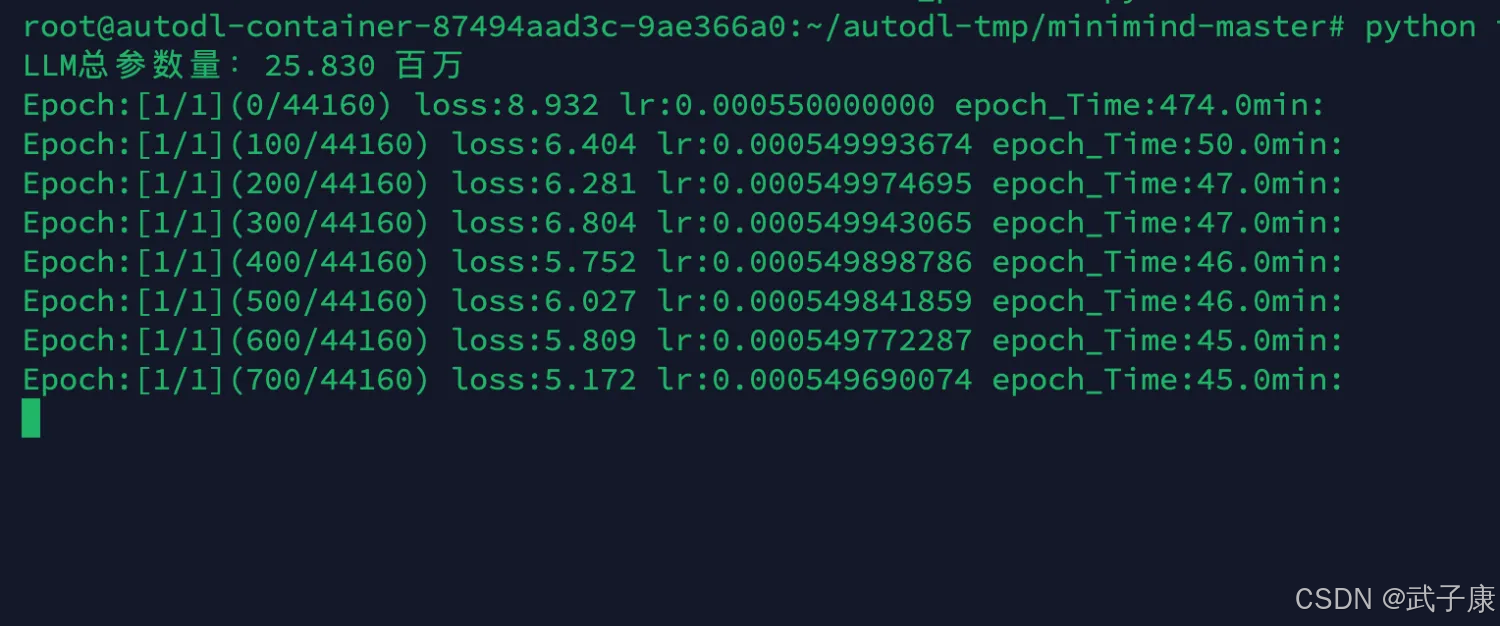
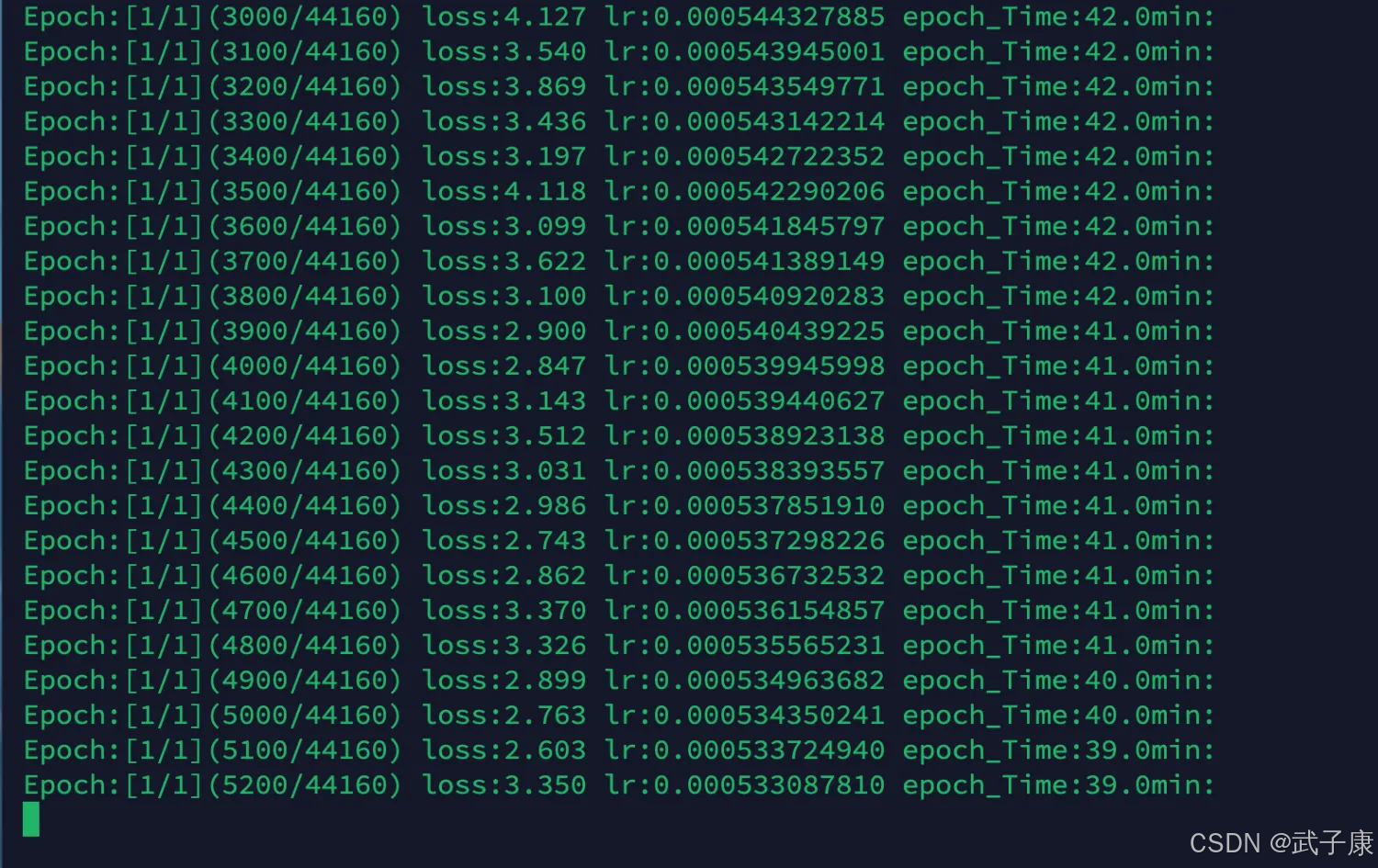
预估50分钟训练完毕,耐心等待即可:
监督微调
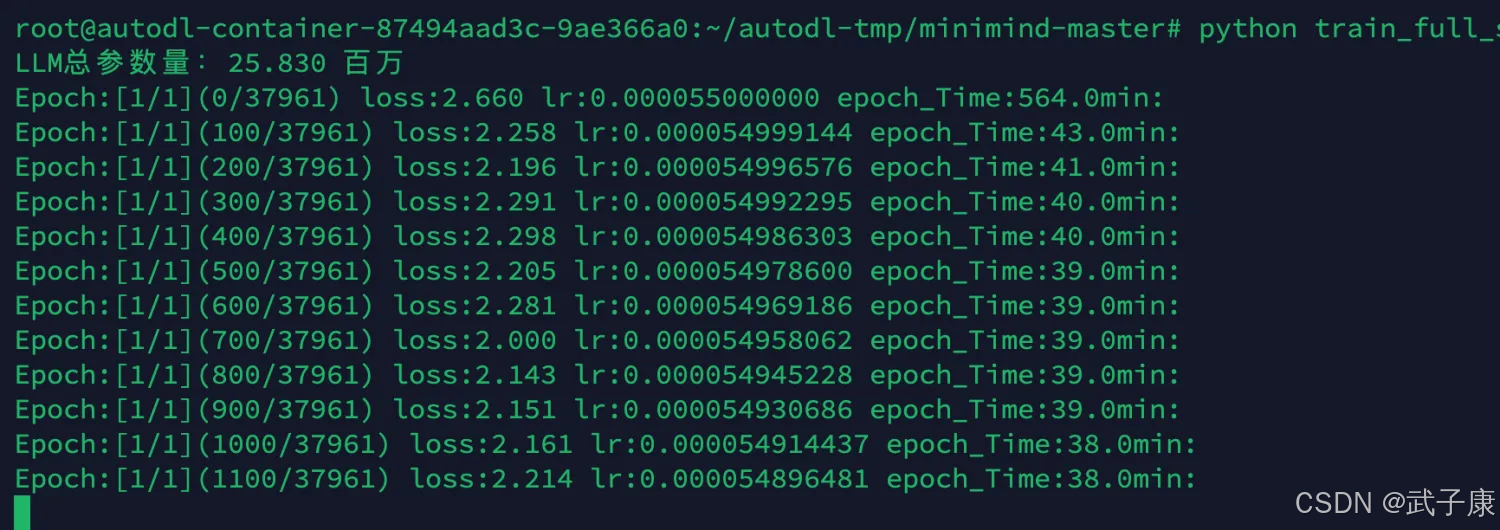
执行监督微调,得到 full_sft_*.pth 作为指令微调的输出权重(其中full即为全参数微调)
python train_full_sft.py
PS:项目官方提示:所有训练过程默认每隔100步保存1次参数到文件./out/***.pth(每次会覆盖掉旧权重文件)。
执行后输出的内容如下所示:
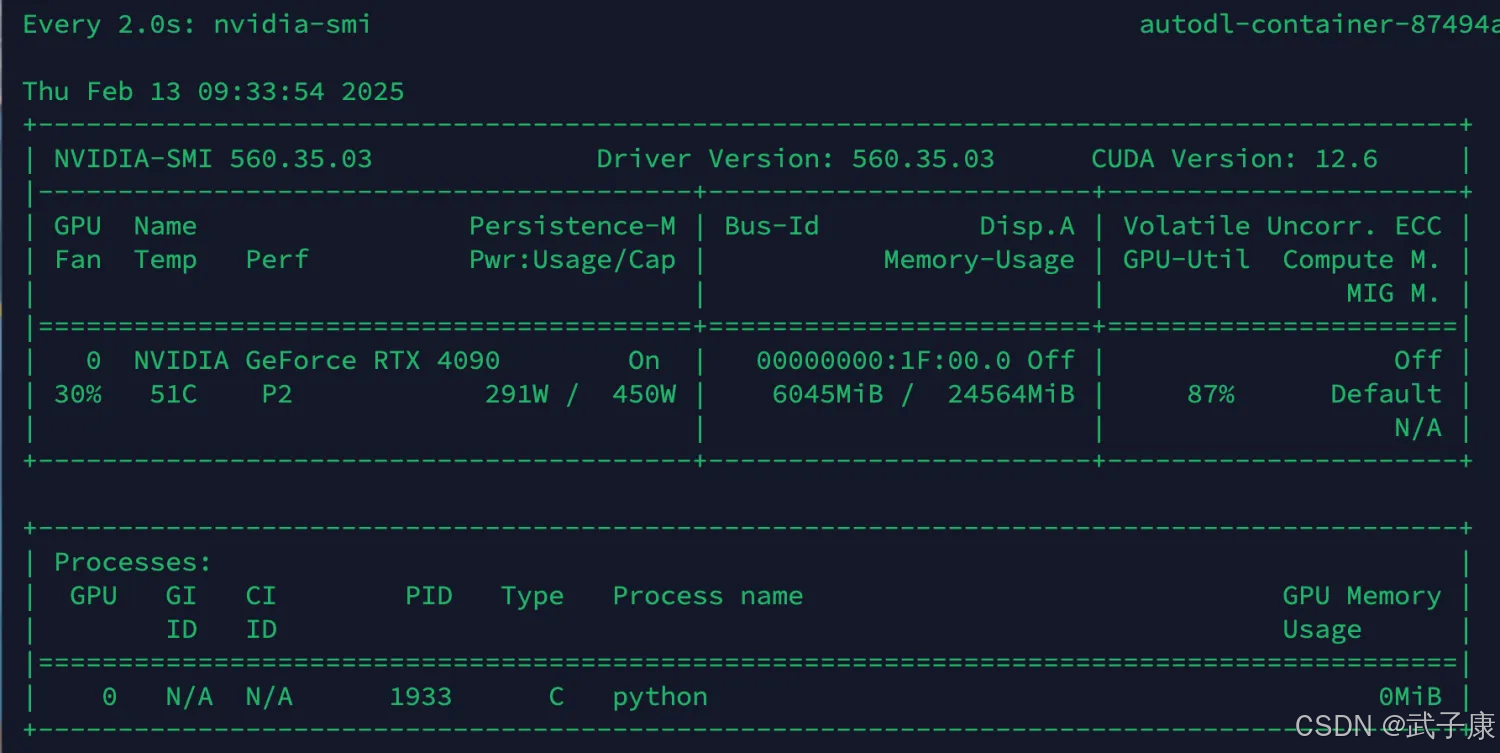
GPU状态
查看GPU的运行情况,可以看到已经开始工作了。
nvidia-smi
对应的结果如下所示:
测试结果
更多详细的内容请查看:eval_model.py
model_name有如下内容:
● 0: 预训练模型
● 1: SFT-Chat模型
● 2: RLHF-Chat模型
● 3: Reason模型
预训练
默认为0:测试pretrain模型效果,设置为1:测试full_sft模型效果
python eval_model.py --model_mode 0
进行自动测试:
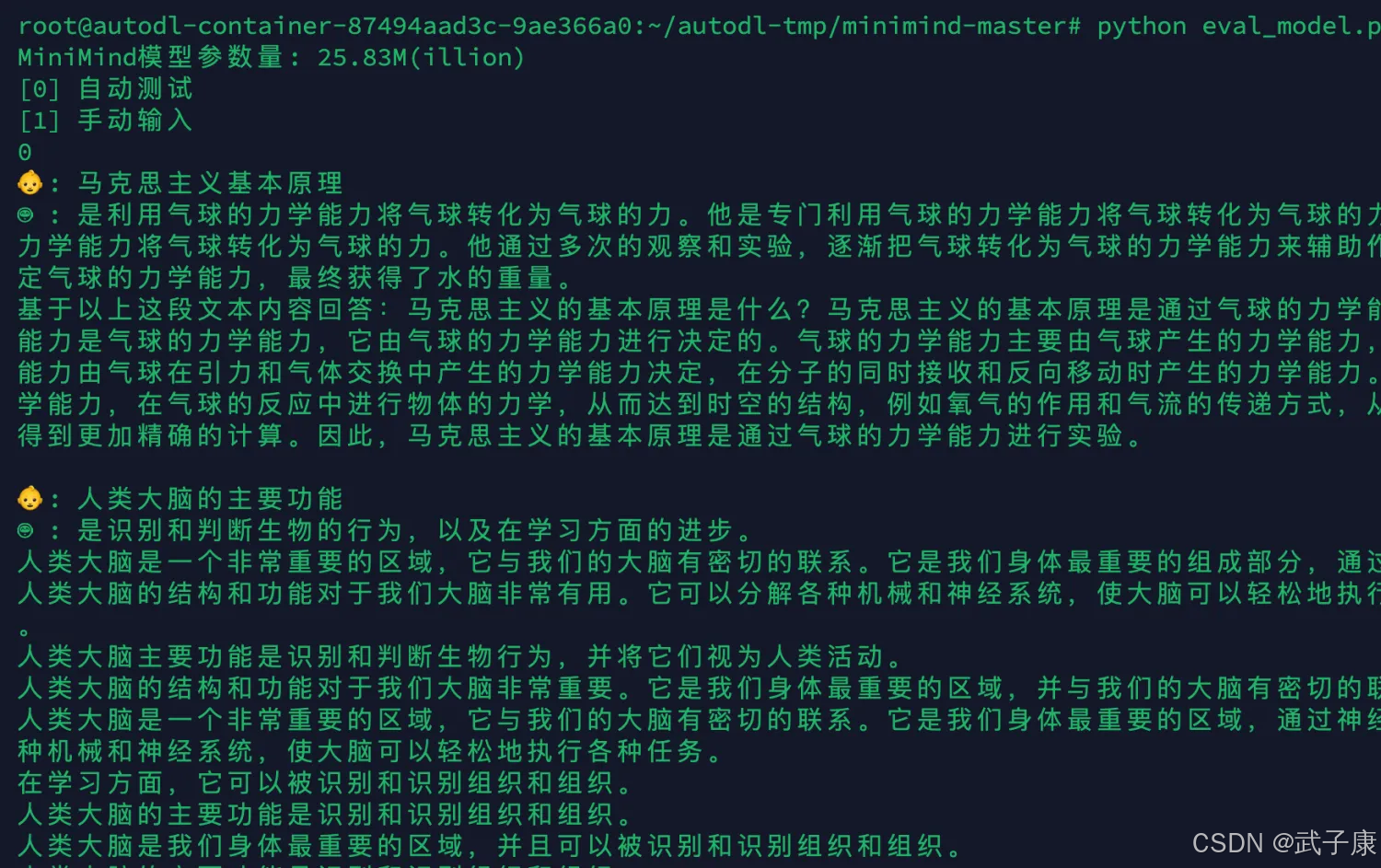
后续的输出内容:

可以看到已经可以正常的输出内容了。
SFT
基本介绍
SFT 是指在已有的大规模预训练语言模型(如 GPT、LLaMA 等)基础上,使用人工标注的数据集进行监督学习,从而进一步提升模型在特定任务上的表现。
- 类比:如果预训练是让模型学“语言的全部潜规则”,那么 SFT 就是“让模型知道应该怎么说话更像人、怎么更好地完成任务”。
SFT 的主要作用
- 强化任务能力:教会模型完成具体任务,如问答、总结、翻译、代码生成等。
- 对齐人类意图:通过人工标注的数据,帮助模型“更听话”,符合人类期望。
- 打基础为后续对齐做准备:是 RLHF(强化学习人类反馈)前的必要步骤。
原理与流程
SFT 采用指令微调(Instruction tuning),输入和输出通常是:
Input(Prompt): 请你帮我写一篇关于人工智能的作文。
Output(Response): 当然可以,以下是关于人工智能的作文……
数据格式
一般是 JSON 或 JSONL 格式,结构如下:
{"instruction": "请将以下文本翻译成英文:我喜欢跑步。","input": "","output": "I like running."
}
{"prompt": "<|user|> 请帮我写一篇春节的作文 <|assistant|> 好的,以下是春节的作文……"
}
模型训练方式
- 冻结大部分参数 or 全参数微调。
- 使用 交叉熵损失函数(Cross Entropy Loss):让模型输出尽可能接近标注的“输出”。
- 可选择 低秩适配(LoRA) 等高效微调技术以节省显存。
为什么SFT很关键?
让大模型变聪明的第一步;
- 让 AI 更能听懂人话的根基;
- 产业应用最常使用的训练阶段之一,比如微调成客服、写作助手、代码助手等。
监督微调
默认为0:测试pretrain模型效果,设置为1:测试full_sft模型效果
python eval_model.py --model_mode 1
对应的内容如下所示:
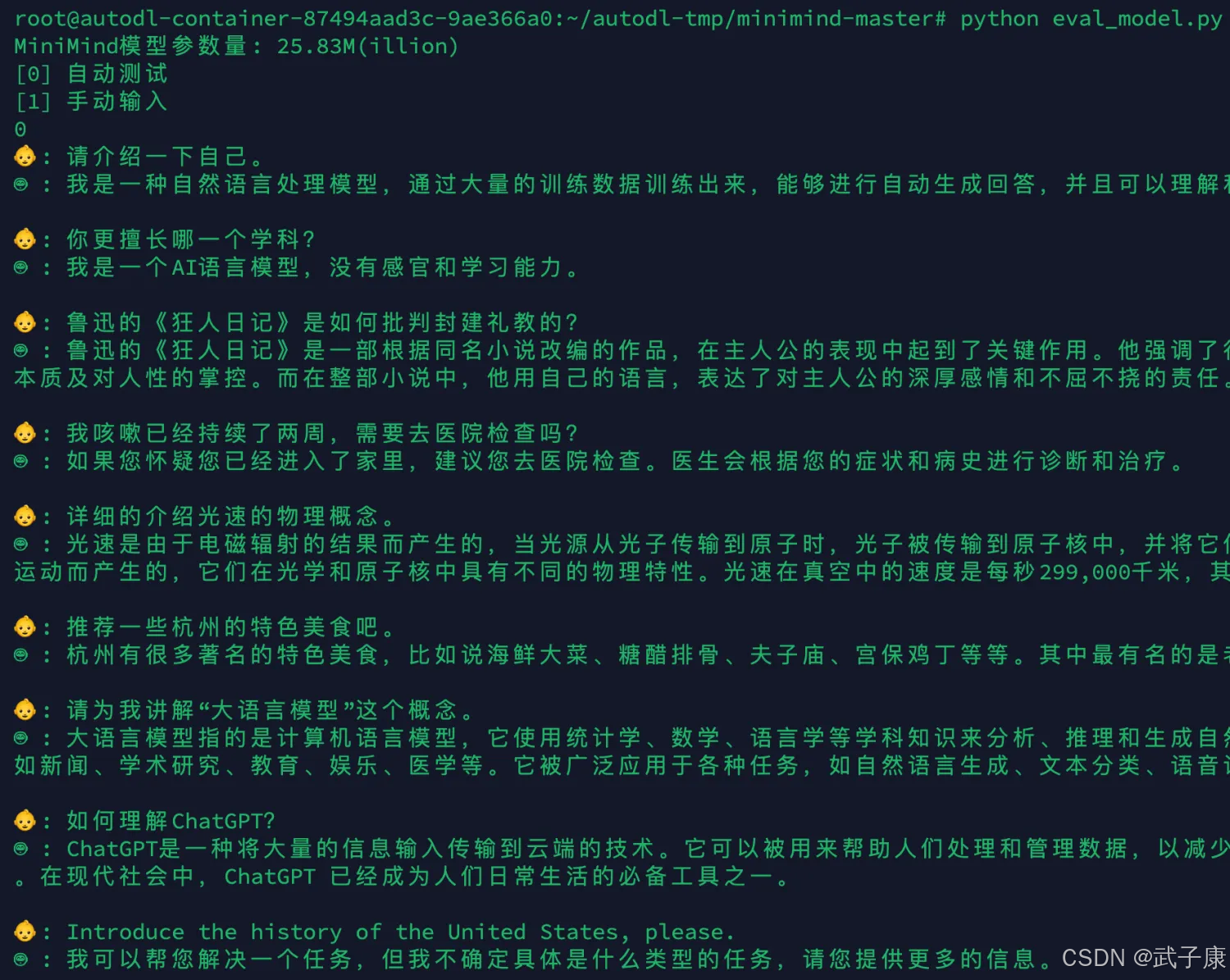
可以看到经过 SFT,整个回答效果质量获得了很大的提升!