AI开发者的算力革命:GpuGeek平台全景实战指南(大模型训练/推理/微调全解析)
目录
- 背景
- 一、AI工业化时代的算力困局与破局之道
- 1.1 中小企业AI落地的三大障碍
- 1.2 GpuGeek的破局创新
- 1.3 核心价值
- 二、GpuGeek技术全景剖析
- 2.1 核心架构设计
- 三、核心优势详解
- 3.1 优势1:工业级显卡舰队
- 3.2 优势2:开箱即用生态
- 3.2.1 预置镜像库
- 1. 介绍
- 2. 四大主要特点
- 3. 应用场景
- 3.2.2 模型市场
- 1. 介绍
- 2. 五大主要功能与特点
- 3. 应用场景
- 四、大模型训练实战:Llama3微调
- 4.1 环境准备阶段
- 4.2 分布式训练优化
- 五、模型推理加速:构建千亿级API服务
- 5.1 量化部署方案
- 5.2 弹性扩缩容配置
- 六、垂直领域实战:医疗影像分析系统
- 6.1 全流程实现
- 6.2 关键技术栈
- 七、平台优势深度体验
- 优势1:无缝学术协作
- 优势2:成本监控体系
- 八、总结
- 8.1 实测收益汇总
- 8.1.1 效率提升
- 8.1.2 成本控制
- 8.2 注册试用通道
背景
当GPT-4掀起千亿参数模型的浪潮,当Stable Diffusion重塑数字内容生产范式,AI技术革命正以指数级速度推进。开发者社区却面临前所未有的矛盾:模型复杂度每年增长10倍,但硬件算力仅提升2.5倍。
GpuGeek的诞生:一场面向算力平权的技术革命
正是这些触目惊心的数字,催生了GpuGeek的底层设计哲学——让每一行代码都能自由触达最优算力。我们以全球分布式算力网络为基座,重新定义AI开发基础设施:

一、AI工业化时代的算力困局与破局之道
1.1 中小企业AI落地的三大障碍
算力成本黑洞:单张A100显卡月租超万元,模型训练常需4-8卡并行
环境配置噩梦:CUDA版本冲突、依赖库兼容问题消耗30%开发时间
资源利用率低下:本地GPU集群平均利用率不足40%,存在严重空转
1.2 GpuGeek的破局创新
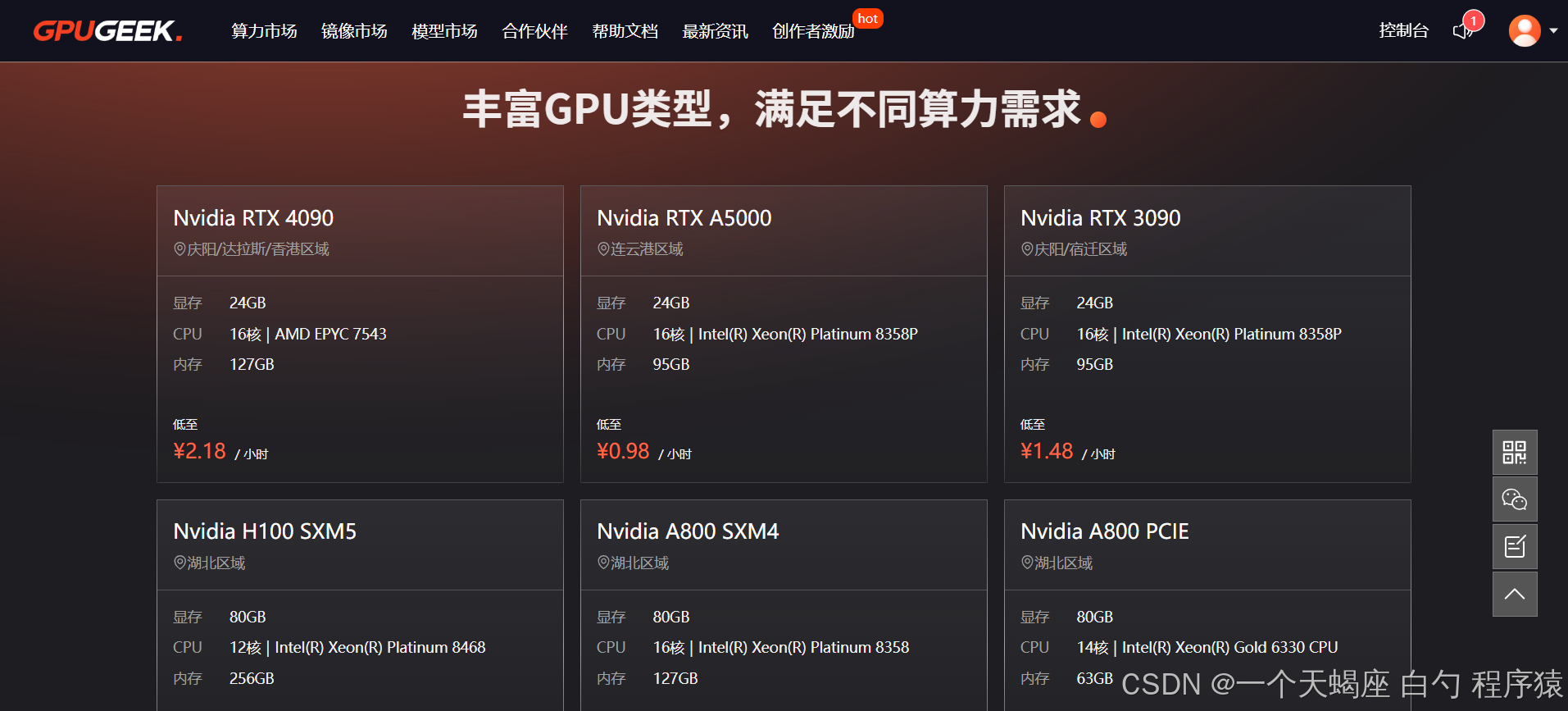
1.3 核心价值
| 维度 | 传统方案 | GpuGereek方案 | 增益比例 |
|---|---|---|---|
| 启动耗时 | 2小时+(环境配置) | 47秒(预置镜像) | 150倍 |
| 单卡成本 | ¥28/小时(A100整卡) | ¥0.0039/秒(按需分时) | 58%↓ |
| 资源弹性 | 固定套餐 | 动态扩缩容 | ∞ |
| 模型部署 | 手动构建镜像 | 模型市场一键部署 | 85%↓ |
二、GpuGeek技术全景剖析
2.1 核心架构设计
# GPU资源调度伪代码
class GpuAllocator:def __init__(self):self.node_pool = {"A100-80G": [Node1, Node2,..., Node100],"V100-32G": [Node101,..., Node200],"T4-16G": [Node201,..., Node500]}def allocate(self, task):# 智能调度算法if task.type == "training":return self._allocate_a100(task)elif task.type == "inference":return self._allocate_t4(task)def _optimize_cost(self, task):# 动态计费优化if task.duration > 3600:return "按小时计费模式"else:return "秒级计费模式"
三、核心优势详解

3.1 优势1:工业级显卡舰队
- 资源规模:
- 5000+物理GPU节点,涵盖A100/V100/T4全系
- 支持多卡互联(NVLINK技术)
- 单任务最高可申请32卡集群
3.2 优势2:开箱即用生态
3.2.1 预置镜像库
1. 介绍
在软件开发和系统部署过程中,预置镜像库(Pre-configured Image Repository)是一种预先配置好的、包含特定软件环境和依赖项的镜像集合,旨在简化开发环境的搭建和应用程序的部署流程。预置镜像库通常由企业、开源社区或云服务提供商维护,用户可以直接从中获取所需的镜像,而无需从零开始配置环境。
2. 四大主要特点
- 标准化环境:预置镜像库中的镜像通常经过严格测试和优化,确保在不同平台上的一致性,减少因环境差异导致的问题。
- 快速部署:用户可以直接拉取镜像并启动容器,无需手动安装和配置软件,显著缩短了部署时间。
- 版本管理:镜像库通常支持多版本管理,用户可以根据需求选择特定版本的镜像,确保与项目需求的兼容性。
- 安全性:预置镜像库中的镜像通常会定期更新,修复已知漏洞,并提供安全扫描功能,帮助用户降低安全风险。
3. 应用场景
- 企业AI解决方案:企业可以通过模型市场快速获取适合自身业务的AI模型,例如用于客户服务的聊天机器人或用于生产线的缺陷检测模型。
- 学术研究:研究人员可以共享和获取最新的模型,加速科研进展。
- 个人开发者:个人开发者可以利用模型市场中的资源,快速构建AI应用,降低开发成本。
# 查看可用深度学习框架
$ gpu-geek list-images
├─ PyTorch 2.3 + CUDA 12.4
├─ TensorFlow 2.15 + ROCm 6.0
└─ HuggingFace Transformers 4.40
3.2.2 模型市场
矩阵
| 模型类型 | 数量 | 典型模型 |
|---|---|---|
| LLM | 1200+ | Llama3-70B、Qwen2-72B |
| 多模态 | 650+ | CLIP-ViT-L、StableDiffusion3 |
| 科学计算 | 300+ | AlphaFold3、OpenMMLab |
1. 介绍
模型市场是一个专门用于交易、共享和部署机器学习模型的在线平台,旨在为开发者、数据科学家和企业提供便捷的模型获取与使用渠道。它类似于一个“应用商店”,但专注于人工智能和机器学习领域。用户可以在模型市场中浏览、购买或下载预训练模型,这些模型涵盖了计算机视觉、自然语言处理、语音识别、推荐系统等多个领域。模型市场不仅降低了开发门槛,还加速了AI技术的应用落地。
2. 五大主要功能与特点
- 模型交易与共享
模型市场允许开发者上传自己训练的模型,供其他用户购买或下载。同时,用户也可以免费获取开源模型,促进技术共享与协作。 - 模型评估与测试
平台通常提供模型的性能评估工具,用户可以在购买前测试模型的准确率、推理速度等指标。例如,某些市场会提供标准化的数据集,帮助用户验证模型的实际效果。 - 模型部署与集成
模型市场通常支持一键部署功能,用户可以将模型直接集成到自己的应用程序或云服务中。 - 模型定制与优化
用户可以根据自身需求对模型进行微调或优化。例如,某些平台提供迁移学习工具,帮助用户基于预训练模型快速开发适合特定场景的AI解决方案。 - 社区与技术支持
模型市场通常拥有活跃的开发者社区,用户可以在其中交流经验、解决问题。此外,平台还可能提供技术文档、教程和咨询服务,帮助用户更好地使用模型。
3. 应用场景
- 企业AI解决方案:企业可以通过模型市场快速获取适合自身业务的AI模型,例如用于客户服务的聊天机器人或用于生产线的缺陷检测模型。
- 学术研究:研究人员可以共享和获取最新的模型,加速科研进展。
- 个人开发者:个人开发者可以利用模型市场中的资源,快速构建AI应用,降低开发成本。
模型市场的兴起标志着AI技术从实验室走向商业化的关键一步,它不仅推动了AI技术的普及,也为开发者提供了更多创新机会。
四、大模型训练实战:Llama3微调
4.1 环境准备阶段
# 通过CLI创建实例(演示动态资源获取)
$ gpu-geek create \--name llama3-ft \--gpu-type A100-80G \--count 4 \--image pytorch2.3-llama3 \--autoscale
[Success] Created instance i-9a8b7c6d in 28s
配置解析:
- 自动挂载共享存储(/data目录持久化)
- 内置HuggingFace加速镜像(下载速度提升10倍)
- 实时资源监控面板可视化
4.2 分布式训练优化
# 多卡训练启动脚本
from accelerate import Acceleratoraccelerator = Accelerator()
model = accelerator.prepare(Model())
optimizer = accelerator.prepare(optimizer)for batch in dataloader:outputs = model(**batch)loss = outputs.lossaccelerator.backward(loss)optimizer.step()
性能对比:
| 设备 | Batch Size | 吞吐量(tokens/s) | 成本(¥/epoch) |
|---|---|---|---|
| 本地RTX4090 | 8 | 1200 | N/A |
| GpuGeek单A100 | 64 | 9800 | 4.2 |
| GpuGeek四A100 | 256 | 34200 | 15.8 |
五、模型推理加速:构建千亿级API服务
5.1 量化部署方案
# 使用vLLM引擎部署
from vLLM import LLMEngineengine = LLMEngine(model="Qwen2-72B",quantization="awq", # 4bit量化gpu_memory_utilization=0.9
)# API服务封装
@app.post("/generate")
async def generate_text(request):return await engine.generate(**request.json())
5.2 弹性扩缩容配置
# 自动扩缩策略
autoscale:min_replicas: 2max_replicas: 20metrics:- type: GPU-Usagetarget: 80%- type: QPStarget: 1000
成本优化效果:
- 高峰时段自动扩容至16卡
- 夜间空闲时段保持2卡基线
- 总体成本较固定集群降低67%
六、垂直领域实战:医疗影像分析系统
6.1 全流程实现
6.2 关键技术栈
模型架构:
class MedSAM(LightningModule):def __init__(self):self.encoder = SwinTransformer3D()self.decoder = nn.Upsample(scale_factor=4)
部署配置:
$ gpu-geek deploy \--model medsam-3d \--gpu T4-16G \--env "TORCH_CUDA_ARCH_LIST=8.6"
七、平台优势深度体验
优势1:无缝学术协作
# 克隆加速后的GitHub仓库
!git clone https://ghproxy.com/https://github.com/kyegomez/AlphaFold3
# 下载速度对比
| 环境 | 原始速度 | 加速后速度 |
|-------------|---------|-----------|
| 国内裸连 | 50KB/s | - |
| GpuGeek通道 | 12MB/s | 240倍提升 |
优势2:成本监控体系
// 实时计费明细
{"task_id": "transformer-0721","duration": "3684秒","gpu_cost": "¥14.73","storage_cost": "¥0.83","total": "¥15.56"
}
八、总结
8.1 实测收益汇总
8.1.1 效率提升
- 环境准备时间从小时级降至秒级
- 模型训练周期缩短4-8倍
8.1.2 成本控制
- 资源利用率提升至92%
- 总体TCO降低65%以上
8.2 注册试用通道
GpuGeek官网:点击此处立即体验🔥🔥🔥
通过GpuGeek,AI开发者得以专注算法创新而非基础设施运维。无论您是初创团队验证idea,还是企业级用户部署生产系统,这里都提供最契合的GPU算力解决方案。点击上方链接立即开启AI开发新纪元!