NLTK进行文本分类和词性标注
《python ⾃然语⾔处理实战》学习笔记
NLTK
下载依赖
!pip install nltkimport nltk
nltk.download('punkt_tab')
分词(tokenize)
from nltk.tokenize import word_tokenize
from nltk.text import Text
input_str = """Twinkle, twinkle, little star,
How I wonder what you are!
Up above the world so high,
Like a diamond in the sky.When the blazing sun is gone,
When he nothing shines upon,
Then you show your little light,
Twinkle, twinkle, all the night.Then the traveler in the dark,
Thanks you for your tiny spark.
He could not see which way to go,
If you did not twinkle so.In the dark blue sky you keep,
And often through my curtains peep,
For you never shut your eye,
Till the sun is in the sky.As your bright and tiny spark,
Lights the traveler in the dark,
Though I know not what you are,
Twinkle, twinkle, little star."""
tokens = word_tokenize(input_str)
tokens[:20]
tokens = [word.lower() for word in tokens]
tokens[:20]
停用词(stopwords)
from nltk.corpus import stopwords
stopwords.readme().replace('\n','')
# help(stopwords)
stopwords.fileids()[:10] # 支持的语言
stopwords.raw('english').split('\n')[:10] # english -stopwords
过滤停用词
test_words = [word.lower() for word in tokens]
test_words_set = set(test_words)
test_words_set
test_words_set.intersection(set(stopwords.raw('english').split('\n'))) # 取出跟stop_words 的交集
filtered = [ w for w in test_words_set if w not in stopwords.raw('english').split('\n')]
filtered
探索性分析
获得词元数据后,常用的基本分析之一是对单词或词元及其在文档中的分布进行计数,从而更多地了解文档中的主要话题。
词频分布
vocabulary = [word.lower() for word in tokens]
frequency_dist = nltk.FreqDist(vocabulary)
sorted(frequency_dist,key=frequency_dist.__getitem__,reverse=True)[0:30]
frequency_dist.plot(10,cumulative=False)
#pip install wordcloud
>>> from wordcloud import WordCloud
wcloud = WordCloud().generate_from_frequencies(frequency_dist)
import matplotlib.pyplot as plt
plt.imshow(wcloud, interpolation='bilinear')
plt.axis("off")
Text
t = Text(tokens)
t.count('little')
t.index('little')
#!pip install matplotlibx
t.plot(10)
词性标注
词性标注定义
词性标注将句子中的单词以不同语义功能或语法功能进行分类。
在英语中,主要的词性为名词、代词、形容词、动词、副词、介词、限定词和连词,而词性标注正是为文本中的每个单词或词元附加这些类别之一。
- VERB:动词(所有时态和方式)
- NOUN:名词(普通名词、专有名词)
- PRON:代词
- ADJ:形容词
- ADV:副词
- ADP:介词(前置词、后置词)
- CONJ:连词
- DET:限定词
- NUM:基数
- PRT:小品词或其他功能词
- X-other:外来词、错别字、缩写
- .:标点符号
词性标注的应用
我们将在以下代码中查看单词歧义消除的示例。在句子
- “I left the room”
- “Left of the room”中,
Left 一词表达了不同的含义,而词性标注器将有助于区分其意义。
import nltk
nltk.download('averaged_perceptron_tagger_eng')
text1 = nltk.word_tokenize("I left the room")
nltk.pos_tag(text1,tagset='universal')
text2 = nltk.word_tokenize("Left of the room")
nltk.pos_tag(text2, tagset='universal')
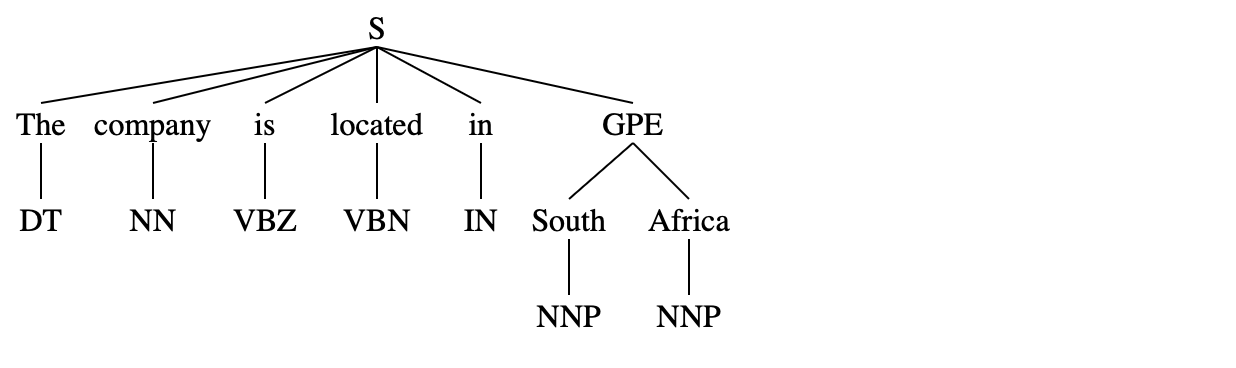
ne_chunk()-分块
nltk.ne_chunk() 是一个基于词性标注结果,做命名实体识别的小工具,适合英文文本中的人名、地点、机构等抽取,
不过现在工业级项目通常会用更强的库(比如 spacy、stanza、transformers)来做。
example_sent = nltk.word_tokenize("The company is located in South Africa")
example_senttagged_sent = nltk.pos_tag(example_sent)
#tagged_sent#!pip install svgling
nltk.download('maxent_ne_chunker_tab')nltk.ne_chunk(tagged_sent)
情感分类器教程
import nltk
import random
# 准备带情感标签的数据
train_data = [("I love this product", "pos"),("This is terrible", "neg"),("Fantastic experience", "pos"),("I hate it", "neg"),("Not bad, quite good", "pos"),("Worst service ever", "neg")
]# 定义特征提取方法
def extract_features(text):words = text.lower().split()return {word: True for word in words}# 构建特征集
featuresets = [(extract_features(text), label) for (text, label) in train_data]# NLTK 内置的朴素贝叶斯分类器
classifier = nltk.NaiveBayesClassifier.train(featuresets)# 查看模型特征贡献情况
classifier.show_most_informative_features()
Most Informative Featuresbad, = None neg : pos = 1.4 : 1.0ever = None pos : neg = 1.4 : 1.0experience = None neg : pos = 1.4 : 1.0fantastic = None neg : pos = 1.4 : 1.0good = None neg : pos = 1.4 : 1.0hate = None pos : neg = 1.4 : 1.0is = None pos : neg = 1.4 : 1.0it = None pos : neg = 1.4 : 1.0love = None neg : pos = 1.4 : 1.0not = None neg : pos = 1.4 : 1.0
# 预测新句子的情感
test_sentence = "This product is amazing"
features = extract_features(test_sentence)
print(classifier.classify(features)) # 输出 pos
pos
# 计算准确率(如果有测试集)
test_data = [("I really love this!", "pos"),("Terrible experience", "neg")
]test_featuresets = [(extract_features(text), label) for (text, label) in test_data]accuracy = nltk.classify.accuracy(classifier, test_featuresets)
print("Accuracy:", accuracy) # 0.5
Accuracy: 0.5
中文情感分类器(配 jieba)
#!pip install nltk jieba
import nltk
import jieba# 准备中文情感数据
train_data = [("我 喜欢 这个 产品", "pos"),("太 差 了", "neg"),("非常 棒 的 体验", "pos"),("我 讨厌 它", "neg"),("还 不错,挺 喜欢", "pos"),("糟糕 的 服务", "neg")
]# 特征提取函数(用 jieba 分词)
def extract_features(text):words = jieba.lcut(text)return {word: True for word in words}# 构建特征集
featuresets = [(extract_features(text), label) for (text, label) in train_data]# 训练情感分类器
classifier = nltk.NaiveBayesClassifier.train(featuresets)# 预测新句子的情感
test_sentence = "这个 产品 真棒"
features = extract_features(test_sentence)
print(classifier.classify(features)) # 输出 pos# 查看重要特征词
classifier.show_most_informative_features()
pos
Most Informative Features喜欢 = None neg : pos = 2.3 : 1.0不错 = None neg : pos = 1.4 : 1.0了 = None pos : neg = 1.4 : 1.0产品 = None neg : pos = 1.4 : 1.0体验 = None neg : pos = 1.4 : 1.0太 = None pos : neg = 1.4 : 1.0它 = None pos : neg = 1.4 : 1.0差 = None pos : neg = 1.4 : 1.0挺 = None neg : pos = 1.4 : 1.0服务 = None pos : neg = 1.4 : 1.0
# 如果有测试集,计算准确率
test_data = [("我 非常 喜欢 它", "pos"),("服务 太 差", "neg")
]test_featuresets = [(extract_features(text), label) for (text, label) in test_data]
accuracy = nltk.classify.accuracy(classifier, test_featuresets)
print("Accuracy:", accuracy) # 1.0
Accuracy: 1.0
词袋分类器(Bag of Words,BoW)
词袋分类器的核心就是:
- 把一段文本里的词汇提取出来
- 每个词作为一个特征
- 统计是否出现(True/False 或 1/0)
不考虑词序、句法、上下文,仅仅看词有没有。
适用于文本分类任务(比如:体育 / 娱乐 / 科技分类)
# 准备分类数据(非情感,是类别)
train_data = [("The football match was exciting", "sports"),("This new AI chip is amazing", "tech"),("The latest movie was fantastic", "entertainment"),("Basketball player scores again", "sports"),("Breakthrough in quantum computing", "tech"),("Great concert last night", "entertainment")
]# 定义词袋特征提取方法
def bag_of_words(text):words = text.lower().split()return {word: True for word in words}# 构建特征集
featuresets = [(bag_of_words(text), label) for (text, label) in train_data]# 训练分类器(朴素贝叶斯)
classifier = nltk.NaiveBayesClassifier.train(featuresets)# 预测新文本的分类
test_sentence = "New AI model released"
features = bag_of_words(test_sentence)
print(classifier.classify(features)) # 输出 tech# 查看最有用的特征词
classifier.show_most_informative_features()
tech
Most Informative Featuresagain = None entert : sports = 1.7 : 1.0ai = None entert : tech = 1.7 : 1.0amazing = None entert : tech = 1.7 : 1.0basketball = None entert : sports = 1.7 : 1.0breakthrough = None entert : tech = 1.7 : 1.0chip = None entert : tech = 1.7 : 1.0computing = None entert : tech = 1.7 : 1.0concert = None sports : entert = 1.7 : 1.0exciting = None entert : sports = 1.7 : 1.0fantastic = None sports : entert = 1.7 : 1.0
# 评估准确率(如果有测试集)
test_data = [("Tennis match today", "sports"),("New music album released", "entertainment")
]test_featuresets = [(bag_of_words(text), label) for (text, label) in test_data]
accuracy = nltk.classify.accuracy(classifier, test_featuresets)
print("Accuracy:", accuracy) #0.5
Accuracy: 0.5