【redis】缓存策略
随着应用程序变得越来越复杂,有效地管理缓存成为了提高性能和用户体验的关键。缓存不仅可以减少数据库的负载,还能显著提高数据访问速度。但是,选择合适的缓存策略可能是一个挑战,因为每种策略都有其独特的优势和适用场景。
Cache-Aside(旁路缓存)策略
Cache-Aside是最广泛使用的缓存模式之一,如果能正确使用Cache-Aside的话,能极大的提升应用性能,Cache-Aside可用来读或写操作。
Cache-Aside是由应用程序负责直接从缓存中读取和写入数据。如果缓存未命中,应用程序将从数据库加载数据,并将其存储在缓存中以供未来使用。
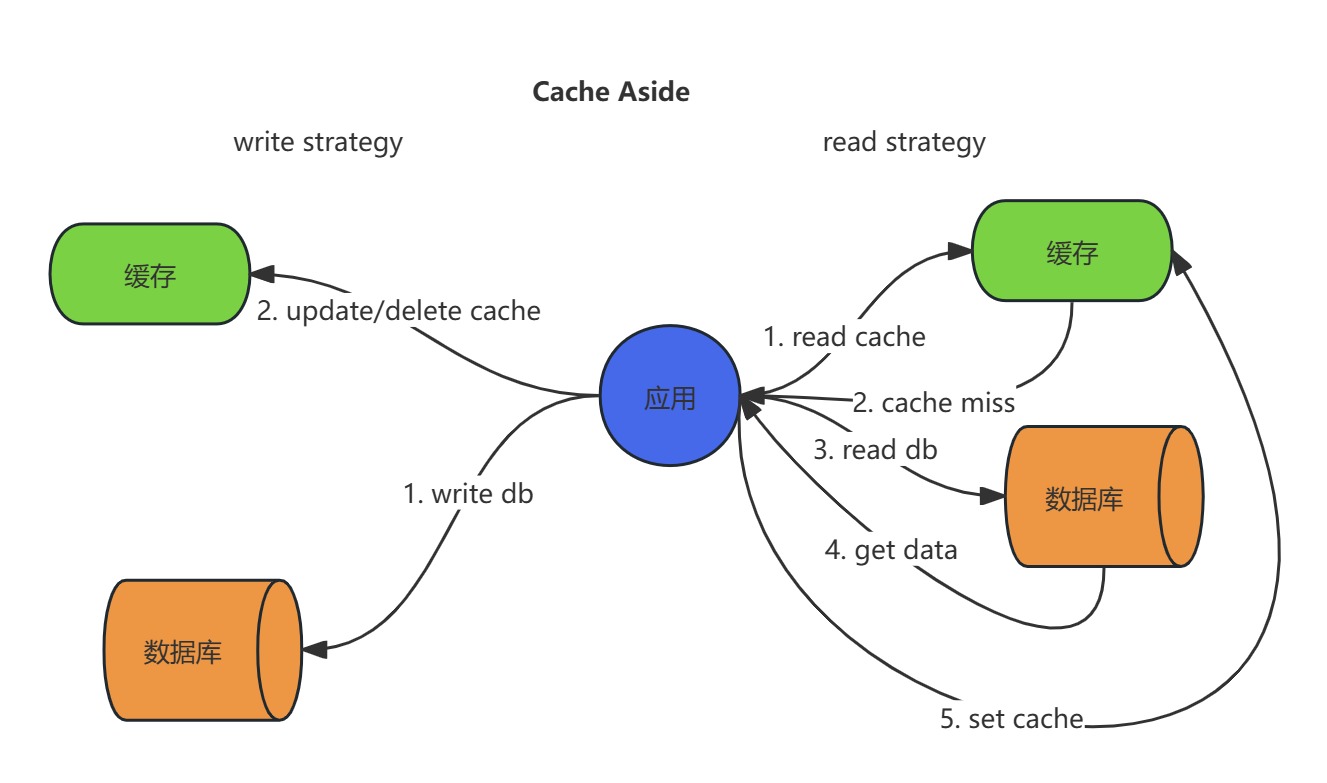
读操作流程:
- 查询缓存:应用首先尝试从缓存中获取数据。
- 缓存命中:若数据存在,直接返回结果。
- 缓存未命中:若数据不存在,从数据库加载数据,并回填缓存,再返回结果。
写操作流程:
- 更新数据库:应用直接修改数据库中的数据。
- 操作缓存:更新完成后,更新缓存中的数据或删除缓存中的数据
优点:
- 高读取性能:缓存命中时直接返回数据,减少数据库压力。
- 实现简单:逻辑清晰,无需依赖复杂缓存中间件。
- 灵活性高:可自定义缓存策略(如过期时间、淘汰算法)。
- 缓存利用率高:仅缓存热点数据,避免内存浪费。
- 按需加载:仅在缓存未命中时加载数据,减少冗余存储。
缺点:
- 短暂数据不一致:数据库更新与缓存删除之间存在时间窗口,可能返回旧数据。
- 写性能较低:每次写操作需同步更新数据库和缓存,增加延迟。
- 缓存击穿:高并发下缓存未命中,大量请求涌入数据库
- 缓存雪崩:批量缓存同时过期,导致数据库瞬时压力激增。
适用场景:
- 读多写少:如商品详情页、用户资料查询,缓存命中率高。
- 数据更新频率低:减少缓存频繁失效带来的性能损耗。
- 允许最终一致性:如非实时统计、日志类业务。
- 资源需求不可预测:按需加载数据,无需预判热点
Read Through(透读)/Write Through(透写)策略
Cache Aside模式需要应用方维护缓存的读写,对数据和缓存的维护设计侵入代码,代码复杂性增加。
Read Through和Write Through是两种策略,经常结合在一起使用。
Read/Write through模式弥补了这一问题,调用方无需管理缓存和数据库调用,通过抽象缓存管理组件维护缓存和数据库的读写,解耦业务代码。
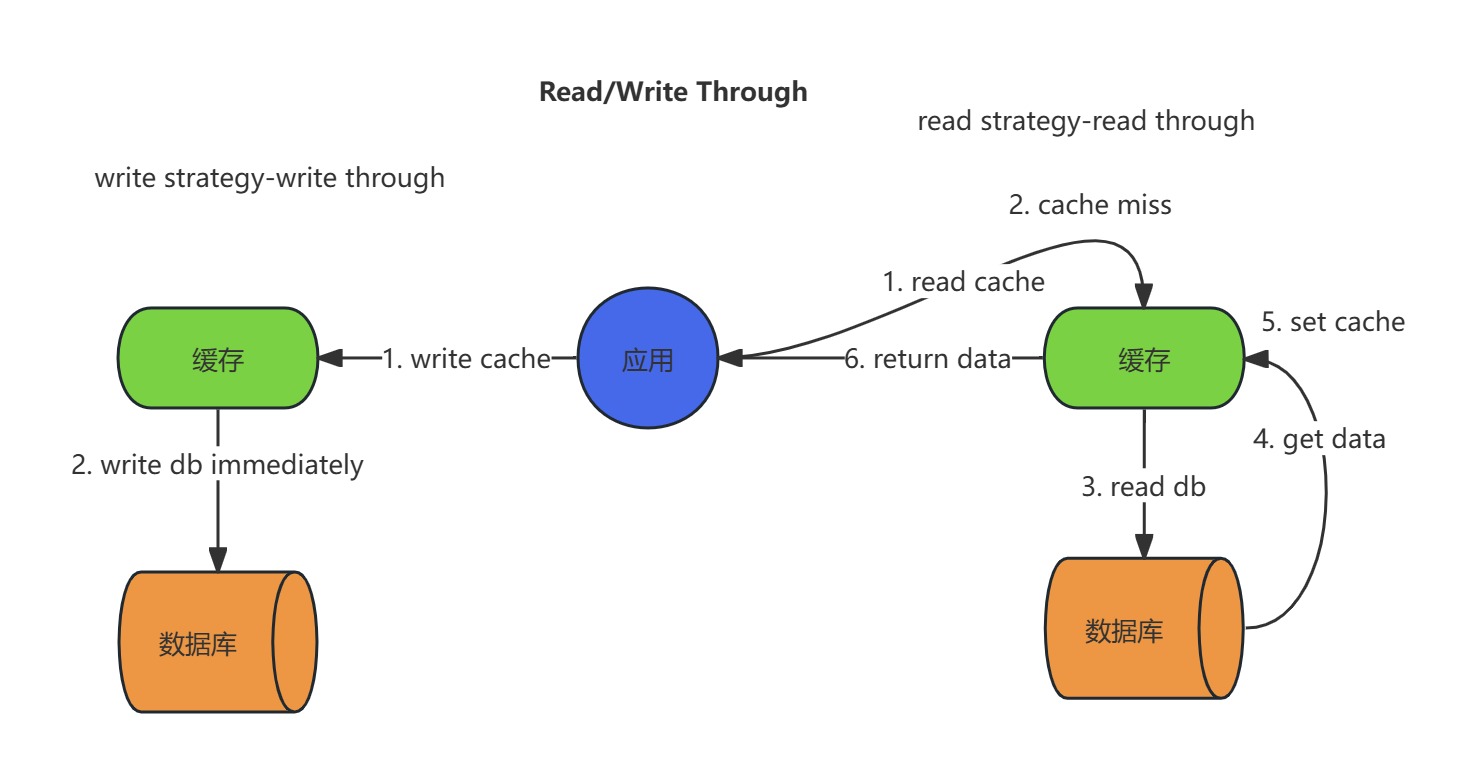
读操作流程(Read Through):
- 查询缓存:应用程序直接向缓存层发起读请求。
- 缓存命中:若数据存在,直接返回结果。
- 缓存未命中:缓存层自动从数据库加载数据,写入缓存后返回给应用。
写操作流程(Write Through):
- 更新缓存:应用程序直接向缓存层写入新数据。
- 同步数据库:缓存层立即将数据同步写入数据库(原子操作)。
优点:
- 强数据一致性:读写均通过缓存层,保证缓存与数据库实时同步,避免脏数据。
- 简化应用逻辑:应用仅需与缓存交互,无需直接操作数据库,降低代码复杂度,应用程序无需感知底层数据库的存在,缓存层全权管理数据加载。
- 自动数据加载:缓存未命中时自动加载数据,减少手动处理逻辑。
缺点:
- 写入性能较低:每次写操作需同步更新数据库,增加延迟(尤其高并发写入场景)。
- 依赖缓存服务稳定性:缓存层成为单点依赖,若缓存故障可能导致系统不可用。
- 实现复杂度高:需缓存层支持事务和同步机制,开发维护成本较高
适用场景:
- 强一致性需求场景:金融交易系统中如账户余额更新、订单状态变更,需保证数据实时准确。配置管理中如全局参数、权限配置,要求所有节点数据一致。
- 读多写少场景:高频读取的低更新数据如新闻详情页、商品静态信息,缓存命中率高,减少数据库压力。实时性要求高的查询如股票行情、航班动态,需快速响应且数据准确。
- 多级存储架构:分布式系统缓存层作为数据代理,降低跨节点查询延迟。网络存储如文件服务器,通过缓存加速高频访问文件
Write Back(回写缓存)策略
Write-Back,又叫,是由应用程序首先将数据写入缓存,然后再批量异步地更新后端数据源(如数据库)。这种策略可以减少对数据源的即时写操作,从而提高应用程序的性能,提升系统的TPS。
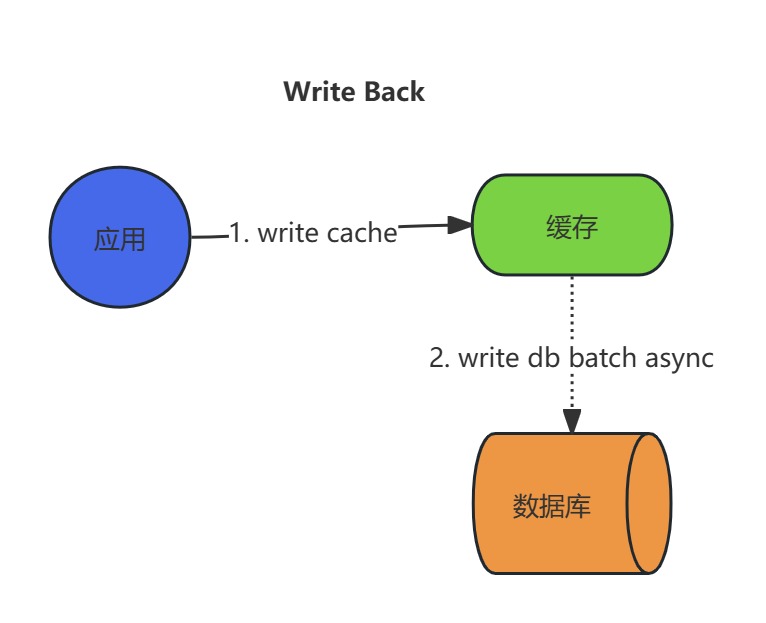
写操作流程:
- 应用程序直接更新缓存中的数据。更新操作完成后,立即返回成功响应。
- 缓存系统记录此次更新(如通过日志或队列),但不立即同步到数据库。
- 缓存系统通过后台进程或定时任务,批量将累积的更新操作异步写入数据库(例如合并多次写操作或定期刷新)。
优点:
- 超高写入性能:写操作仅需更新缓存,无需等待数据库I/O,响应延迟极低。支持批量合并写入,减少数据库操作次数(例如将多次更新合并为一次)。
- 容错性:即使数据库暂时不可用,系统仍可通过缓存继续服务。
- 降低数据库压力:异步批量写入避免了高并发下的数据库负载峰值。
缺点:
- 数据一致性风险:异步写入可能导致缓存与数据库短暂不一致(保证最终一致性)。若缓存故障且未持久化数据,可能导致数据丢失。
- 实现复杂度高:需维护异步队列、日志或脏位标记(Dirty Bit)以跟踪待更新数据。需处理异常场景(如异步写入失败时的重试机制)
适用场景:
- 写密集型场景:如日志记录、社交动态流、用户行为追踪,写入频率高但对实时一致性要求低。
- 容忍最终一致性的业务:如页面浏览量统计、点赞数更新等,允许数据短暂延迟同步。
- 高吞吐需求系统:需要最大化写入吞吐量的场景,如秒杀时将订单数据写入缓存后异步写入数据库。
Write-Through-Back(透写后缓存)策略
Write-Through-Back是结合了Write-Through和Write-Back模式的缓存方法。在这种模式下,数据首先被写入缓存,然后立即异步地更新到数据库。这种模式旨在平衡写操作的即时性和减少对数据源的直接压力。
注:Write-Back通常再写入缓存与数据库存在较大一段时间间隔,Write-Through-Back通常立即执行异步操作,能较大程度减少最终一致性时长。
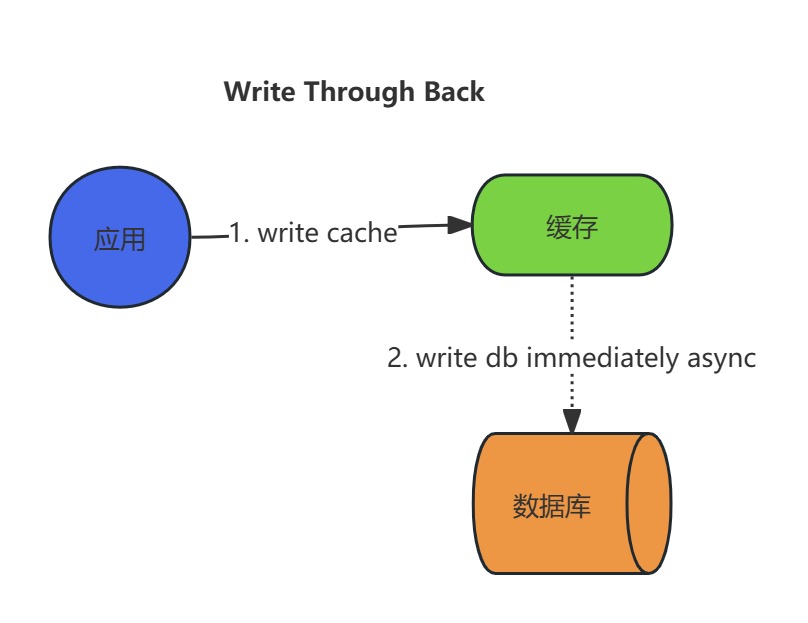
写操作流程:
- 应用首先将数据写入缓存,并立即触发异步操作将数据同步到数据库。
- 与纯Write-Back不同,其异步延迟极短(通常毫秒级),以缩短数据最终一致性的时间窗口。
优点:
- 高性能写入:写入操作仅需操作缓存,无需等待数据库响应,极大降低延迟。异步批量更新数据库,减少数据库负载压力。
- 平衡一致性:相比纯Write-Back,缩短了缓存与数据库的同步延迟,降低数据丢失风险。
- 容错性提升:若数据库暂时不可用,异步队列可缓存待更新操作,重试直至成功。
缺点:
- 短暂不一致性:异步同步仍存在时间窗口,可能导致缓存与数据库数据短暂不一致。
- 实现复杂度高:需维护异步队列、重试机制及脏数据标记(Dirty Bit)。
- 资源消耗:后台线程持续运行可能占用额外 CPU 和内存资源。
适用场景:
- 高吞吐写入场景:如日志系统、用户行为追踪(每秒数千次写入),需快速响应但允许短暂延迟同步。
- 实时统计类应用:如页面浏览量、点赞数统计,容忍最终一致性但需高并发写入能力。
- 资源受限的分布式系统:当数据库成为性能瓶颈时,通过异步批量写入缓解压力。
Write-Around(绕写缓存)策略
Write-Around是一种写入时绕过缓存的缓存策略,其核心思想是直接更新持久化存储(如数据库)而不操作缓存,仅在读取数据时按需加载到缓存。这种策略旨在减少缓存污染并优化存储资源使用,尤其适合写多读少或仅需缓存部分热点数据的场景。
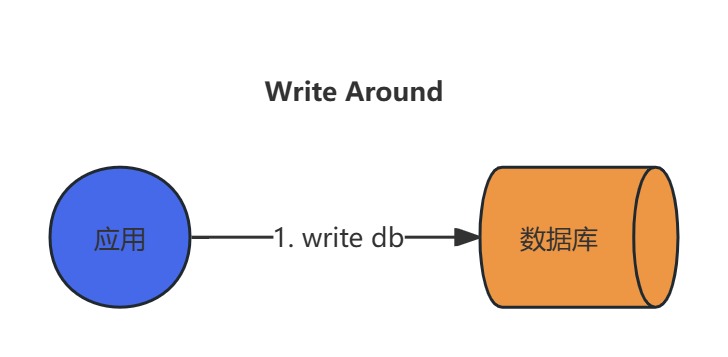
写操作流程:
- 应用直接将数据写入数据库,不更新缓存,避免缓存被低频访问的写入数据占用。
读操作流程:
- 需结合Cache-Aside或Read-Through策略,确保读取时能正确加载数据到缓存。
优点:
- 节省缓存空间:避免低频数据占用缓存资源,提升缓存利用率。
- 降低缓存污染风险:减少无效缓存更新操作。
缺点:
- 读性能下降:首次或低频读取需穿透到数据库,增加延迟。
- 数据一致性风险:写入后缓存可能长期持有旧数据。
- 额外I/O开销:写操作需直接操作数据库,可能增加磁盘压力
适用场景:
- 高频写入低频读取:如日志记录、IoT 设备数据上报,数据写入后极少被访问,无需缓存。
- 仅缓存热点数据:如电商平台仅缓存热门商品信息,冷门商品数据通过Write-Around直接写入数据库。
- 资源受限环境:缓存空间有限时,通过绕过写入避免缓存溢出,结合TTL策略管理冷数据
Refresh-Ahead (预刷新缓存)策略
Refresh-Ahead通过时间预判与异步加载,在缓存失效前完成数据更新,是平衡性能与实时性的有效方案。其成功依赖于精准的TTL管理、资源控制及异常处理,适用于数据访问模式稳定且对延迟敏感的场景。
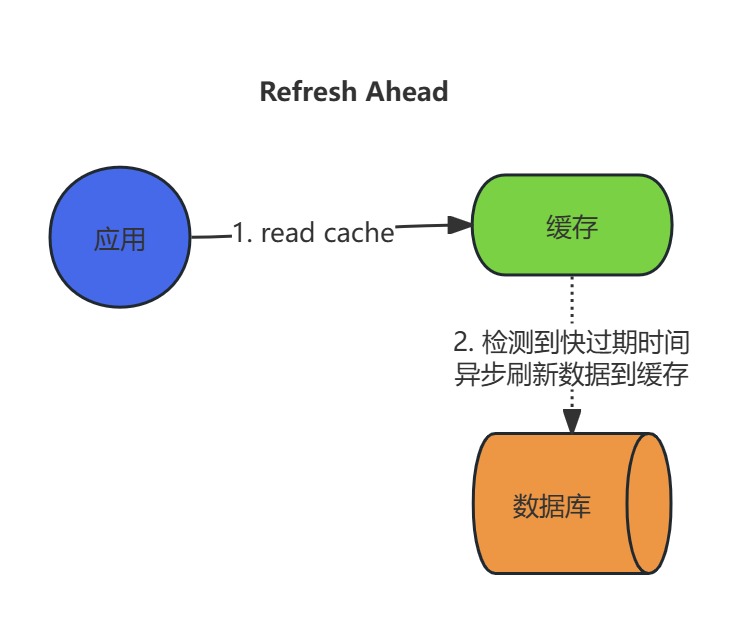
读操作流程(Read Through):
- 直接查询缓存:应用程序直接从缓存中读取数据。
写操作流程(Write Through):
- 预判与主动刷新:系统监测缓存项的TTL(生存时间),在数据即将过期时(如TTL剩余10%时),异步触发数据预加载,从数据源(如数据库)拉取最新数据并更新缓存。
优点:
- 降低延迟:避免缓存失效时用户需等待数据库查询,提升响应速度(实验显示可减少30%以上的延迟)。
- 缓解数据库压力:分散回源请求,防止缓存集中失效导致的数据库负载激增。
- 数据实时性提升:适用于新闻、活动页面等高时效性场景,确保用户获取较新数据。
缺点:
- 资源消耗增加:频繁预刷新可能占用额外计算和网络资源,尤其在预测不准时导致无效刷新。
- 实现复杂度高:需精准设计TTL监测、异步任务调度及错误处理机制。
- 短期不一致风险:若预刷新期间源数据再次变更,可能导致缓存与数据库短暂不一致。
适用场景:
-高频访问的热点数据:如电商平台的商品详情页、社交媒体的热门内容。
- 数据更新可预测的场景:例如定期更新的配置信息、天气预报等。
- 对响应速度敏感的应用:实时推荐系统、金融行情展示等需快速响应的领域。
- 分布式系统缓存同步:结合消息队列(如Redis Pub/Sub)实现多节点缓存的协同刷新