Mysql索引优化
一、索引
1. 主键索引(Primary Index)
定义
主键索引是一种特殊的唯一索引,用于唯一标识表中的每一行数据。每个表最多有一个主键索引,且索引列不允许为 NULL,自动添加 UNIQUE 和 NOT NULL 约束。
特点:
- 数据唯一性:确保每行数据有唯一标识。
- 聚集索引(部分数据库):如 MySQL 的 InnoDB 引擎中,数据会按照主键顺序物理存储,查询效率极高。
创建方式
- 创建表时指定主键:
CREATE TABLE users (user_id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引name VARCHAR(50),age INT ); - 对已有表添加主键:
ALTER TABLE users ADD PRIMARY KEY (user_id);
例子
假设用户表 users 以 user_id 为主键,插入数据时重复的 user_id 会报错,且查询 WHERE user_id = 1 时会通过主键索引快速定位数据。
2. 唯一索引(Unique Index)
定义
唯一索引确保索引列的值唯一,但允许有一个 NULL 值(部分数据库,如 MySQL)。一个表可以有多个唯一索引。
特点:
- 允许单个
NULL(视数据库而定),但不允许重复值。 - 不强制为主键,可用于非主键的唯一约束场景(如邮箱、手机号)。
创建方式
- 创建表时指定唯一索引:
CREATE TABLE users (user_id INT PRIMARY KEY,email VARCHAR(50) UNIQUE, -- 唯一索引phone VARCHAR(20) UNIQUE -- 多个唯一索引 ); - 单独创建唯一索引:
CREATE UNIQUE INDEX idx_email ON users (email);
例子
若 users 表的 email 字段有唯一索引,插入重复邮箱时会报错,确保用户邮箱唯一。查询 WHERE email = 'test@example.com' 时通过唯一索引快速查询。
3. 普通索引(Normal Index)
定义
普通索引是最基本的索引类型,没有唯一性约束,用于加速对索引列的查询(如 SELECT、WHERE、ORDER BY 等)。
特点:
- 允许重复值和
NULL值。 - 适用于频繁查询但不要求唯一性的字段(如状态、分类、时间等)。
创建方式
- 创建表时添加普通索引:
CREATE TABLE orders (order_id INT PRIMARY KEY,order_status VARCHAR(20),create_time DATETIME,INDEX idx_status (order_status) -- 普通索引 ); - 对已有表添加普通索引:
CREATE INDEX idx_create_time ON orders (create_time);
例子
若经常查询状态为 'COMPLETED' 的订单,对 order_status 创建普通索引后,SELECT * FROM orders WHERE order_status = 'COMPLETED' 的查询效率会显著提升。
4. 组合索引(Composite Index)
定义
组合索引是基于表中多个字段创建的索引,遵循 最左匹配原则(即查询条件需从索引的第一个字段开始匹配)。
特点:
- 减少单字段索引的数量,提升多条件查询效率。
- 最左匹配:如索引为
(a, b, c),则a、a+b、a+b+c的查询可使用索引,单独查询b或c无法使用。
创建方式
- 创建表时添加组合索引:
CREATE TABLE users (user_id INT PRIMARY KEY,name VARCHAR(50),age INT,city VARCHAR(50),INDEX idx_name_age_city (name, age, city) -- 组合索引 ); - 对已有表添加组合索引:
CREATE INDEX idx_name_age ON users (name, age);
例子
若需查询 name = 'Alice' 且 age = 25 的用户,组合索引 (name, age) 可快速定位;若查询 age = 25 则无法使用该索引(不满足最左匹配)。
5. 全文索引(Full-Text Index)
定义
全文索引用于高效搜索文本字段(如文章内容、评论等),支持复杂的全文搜索(如关键词匹配、权重排序)。
特点:
- 仅适用于文本类型(如
VARCHAR、TEXT)。 - 不同数据库支持不同:MySQL 的 MyISAM 引擎原生支持,InnoDB 自 5.6 版本开始支持。
创建方式
- 创建表时添加全文索引(MySQL 示例):
CREATE TABLE articles (article_id INT PRIMARY KEY,title VARCHAR(100),content TEXT,FULLTEXT INDEX ft_title_content (title, content) -- 全文索引 ); - 对已有表添加全文索引:
CREATE FULLTEXT INDEX ft_content ON articles (content);
例子
查询包含 “数据库索引” 的文章:
SELECT * FROM articles WHERE MATCH(title, content) AGAINST('数据库索引');
全文索引会比普通索引更高效地处理此类文本搜索。
总结
| 索引类型 | 唯一性 | 字段数量 | 典型场景 | 示例字段 |
|---|---|---|---|---|
| 主键索引 | 强制唯一 | 单个 | 表的唯一标识(如 user_id) | PRIMARY KEY |
| 唯一索引 | 唯一 | 单个 / 多个 | 唯一约束(如邮箱、手机号) | UNIQUE |
| 普通索引 | 不唯一 | 单个 | 加速查询(如状态、时间) | INDEX idx_status |
| 组合索引 | 不唯一 | 多个 | 多条件查询(如 name+age) | INDEX (name, age) |
| 全文索引 | 不唯一 | 文本 | 文本搜索(如文章内容) | FULLTEXT INDEX ft_text |
在关系型数据库(如 MySQL InnoDB)中,每个索引(包括主键索引、二级索引、组合索引)都会对应一个独立的 B+ 树结构。以下是具体解析和示例:
一、核心结论:每个索引对应一个 B+ 树
聚簇索引(主键索引):
- 一张表只有 1 个聚簇索引,其 B+ 树的叶子节点直接存储 完整的数据行(数据与主键索引绑定,因此也叫 “数据组织方式”)。
- 例:表
users的主键id是聚簇索引,其 B+ 树叶子节点存储(id, name, age)完整数据。二级索引(普通索引、唯一索引、组合索引):
- 每个二级索引对应 独立的 B+ 树,其叶子节点存储 索引键值 和对应的 主键值(而非完整数据行)。
- 例:若在
name列创建普通索引,其 B+ 树叶子节点存储(name, id);若创建组合索引(age, name),则叶子节点存储(age, name, id)。二、示例:表有多个索引时的 B+ 树结构
假设表结构如下:
CREATE TABLE users (id INT PRIMARY KEY, -- 聚簇索引(1个 B+ 树)name VARCHAR(20), -- 普通索引(idx_name,独立 B+ 树)age TINYINT, -- 普通索引(idx_age,独立 B+ 树)INDEX idx_name (name), -- 二级索引 1INDEX idx_age (age) -- 二级索引 2 );索引对应的 B+ 树数量:
- 3 个 B+ 树:1 个聚簇索引(主键
id)+ 2 个二级索引(idx_name、idx_age)。每个 B+ 树的叶子节点内容:
聚簇索引(id):
叶子节点存储完整数据行 →(id=1, name='张三', age=20),(id=2, name='Alice', age=30), ...(数据按主键排序)。二级索引 idx_name(name):
叶子节点存储(name, id)→('Alice', 2),('张三', 1), ...(name 按排序规则排列,id 是对应主键)。二级索引 idx_age(age):
叶子节点存储(age, id)→(20, 1),(30, 2), ...(age 按数值排序,id 是对应主键)。
二、约束
一、主键选择(Primary Key Selection)
1. 什么是主键?
主键是表中 唯一标识一条记录的字段(或字段组合),用于确保数据的唯一性和完整性。
核心特性:
- 唯一性:不能有重复值
- 非空性:不允许为
NULL- 永久性:主键值不应随时间变化(如用户 ID,而非手机号)
- 主键索引:数据库会自动为主键创建 聚簇索引(存储数据行)
2. 如何选择主键?
原则:简短、不变、易查询(推荐使用 自增整数)。
示例:用户表(users)
- 为什么不用 UUID?:UUID 是 36 位字符串,比整数占用更多存储空间,索引查询效率低。
- 为什么不用业务字段(如 username)?:业务字段可能被修改(如用户改名),违反 “主键不变” 原则。
二、约束(Constraints)
约束用于 确保数据完整性,分为以下几类:
1. 主键约束(Primary Key)
- 作用:唯一标识记录,不允许重复和 NULL。
- 例子:
user_id作为主键,确保每个用户唯一。2. 唯一约束(Unique)
- 作用:字段值唯一,但允许有一个 NULL(主键不允许 NULL)。
- 例子:用户表的
CREATE TABLE users (user_id INT PRIMARY KEY,email VARCHAR(100) UNIQUE -- 唯一约束 );
插入重复邮箱时会报错:INSERT INTO users (user_id, email) VALUES (1, 'test@example.com'); -- 成功 INSERT INTO users (user_id, email) VALUES (2, 'test@example.com'); -- 报错(重复)3. 非空约束(Not Null)
- 作用:字段值不允许为 NULL。
- 例子:
username字段不允许为空:CREATE TABLE users (username VARCHAR(50) NOT NULL -- 非空约束 );
插入 NULL 会报错:INSERT INTO users (username) VALUES (NULL); -- 报错4. 检查约束(Check)
- 作用:限制字段值的范围或格式。
- 例子:
age字段必须大于 0:CREATE TABLE users (age INT CHECK (age > 0) -- 检查约束(MySQL 8.0+ 支持,旧版本需用触发器实现) );
插入age=-5会报错。5. 外键约束(Foreign Key)
- 单独讲解,见第三部分。
三、外键约束(Foreign Key)
1. 什么是外键?
外键用于 建立表之间的关联,确保数据的 引用完整性:
- 外键在 从表(子表) 中,引用 主表(父表) 的主键或唯一键。
- 从表的外键值必须存在于主表的被引用字段中,或为 NULL(若允许 NULL)。
2. 示例:用户表(主表)与订单表(从表)
主表(users)(主键:
user_id):CREATE TABLE users (user_id INT PRIMARY KEY );从表(orders)(外键:
user_id引用users.user_id):CREATE TABLE orders (order_id INT PRIMARY KEY,user_id INT,order_time DATE,FOREIGN KEY (user_id) REFERENCES users(user_id) -- 外键约束 );3. 外键的行为(级联操作)
通过
ON DELETE和ON UPDATE指定主表数据变化时从表的行为:-- 创建外键时指定级联删除和级联更新 CREATE TABLE orders (FOREIGN KEY (user_id) REFERENCES users(user_id)ON DELETE CASCADE -- 主表删除用户,从表自动删除对应订单ON UPDATE CASCADE -- 主表更新user_id,从表自动更新外键值 );
- 若未指定级联:删除主表用户时,若从表有对应订单,会报错(防止孤立数据)。
总而言之:创建主键约束或者唯一约束的时候同时创建了相应的索引;但是约束是逻辑上的概念;索引是一个数据结构既包含逻辑的概念也包含物理的存储方式。
三、索引的实现
1.索引存储
innodb 由段、区、页组成;段分为数据段、索引段、回滚段等;区大小为 1 MB(一个区由 64 个 连续页构成);页的默认值为 16k;页为逻辑页,磁盘物理页大小一般为 4K 或者 8K;为了保证区 中的页连续,存储引擎一般一次从磁盘中申请 4~5 个区。
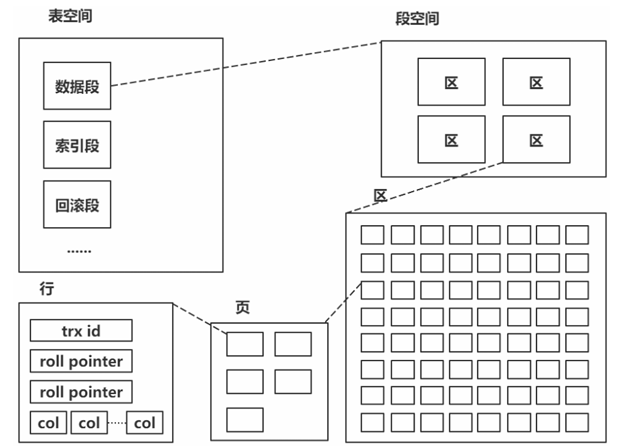
1. 逻辑结构:段(Segment)
- 定义:段是逻辑存储结构,用于分类管理数据。
- 分类:
- 数据段:存储表的实际数据。
- 索引段:存储索引相关数据。
- 回滚段:记录事务回滚信息,用于事务回滚和多版本并发控制(MVCC)。
2. 中等存储单元:区(Extent)
- 大小:每个区固定为 1MB,由 64 个连续的页组成(16KB×64=1MB)。
- 作用:保证页的物理连续性,提升磁盘 I/O 性能。存储引擎通常一次从磁盘申请 4 - 5 个区,确保区内地页连续,减少随机 I/O。
3. 最小管理单位:页(Page)
- 属性:
- 是 InnoDB 磁盘管理的最小逻辑单位,默认大小为 16KB(可配置)。
- 磁盘物理页大小一般为 4KB 或 8KB,逻辑页与物理页通过映射关联。
- B+ 树的一个节点对应一个页,节点的大小由页的大小决定,页中可存储多个键值对及指针,减少树的高度,提升查询效率。
- 内容:页内存储多行数据,每行包含:
- trx id:事务 ID,用于事务一致性和 MVCC。
- roll pointer:回滚指针,指向回滚段中的 undo 日志,用于事务回滚和数据版本追溯。
- col(列数据):实际的表列数据。
页:
页是 innodb 磁盘管理的最小单位;默认16K,可通过 B+ 树的一个节点的大小就是该页的值。
2.B+树
全称:多路平衡搜索树,减少磁盘访问次数;用来组织磁盘数据,以页为单位,物理磁盘页一般为 4K,innodb 默认页大小为 16K;对页的访问是一次磁盘 IO,缓存中会缓存常访问的页;
平衡二叉树(红黑树、AVL 树)
特征:非叶子节点只存储索引信息,叶子节点存储具体数据信息;叶子节点之间互相连接,方便范 围查询;
每个索引对应着一个 B+ 树;
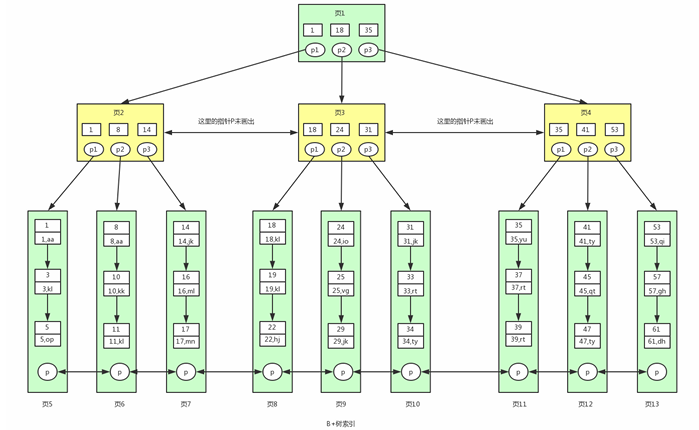
3.B+树的层高问题
B+ 树的一个节点对应一个数据页;B+ 树的层越高,那么要读取到内存的数据页越多,IO 次数越 多;innodb 一个节点 16KB
假设:
key 为 10 byte 且指针大小 6 byte,假设一行记录的大小为 1KB;
那么一个非叶子节点可存下 16 KB / 16 byte=1024 个(key+point);每个叶子节点可存储 1024 行数据;
结论:
2 层 B+ 树叶子节点 1024 个,可容纳最大记录数为: 1024 * 16 = 16384;
3 层 B+ 树叶子节点 1024 * 1024,可容纳最大记录数为:1024 * 1024 * 16 = 16777216;
4 层 B+ 数叶子节点 1024 * 1024 * 1024,可容纳最大记录数为:1024 * 1024 * 1024 * 16 = 17179869184;
4.关于自增 id
超过类型最大值会报错;类型 bigint 范围:(-2 ^ 63,2 ^ 63 - 1);
假设采用bigint 1 秒插入1亿条数据大概需要 5849 年才会用完索引;
5.聚集索引
按照主键构造的 B+ 树;叶子节点中存放数据页;数据也是索引的一部分;
# table id nameselect * from user where id >= 18 and id < 40;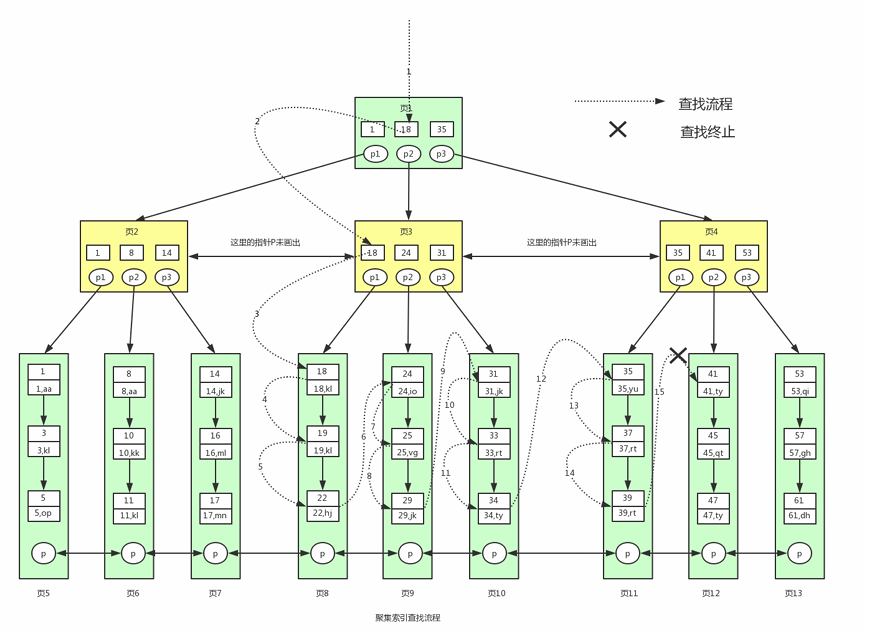
6.辅助索引
叶子节点不包含行记录的全部数据;辅助索引的叶子节点中,除了用来排序的 key 还包含一个 bookmark ;该书签存储了聚集索引的 key;
-- 某个表 包含 id name lockyNum; id是主键,lockyNum 辅助索引;-- KEY()select * from user where lockyNum = 33;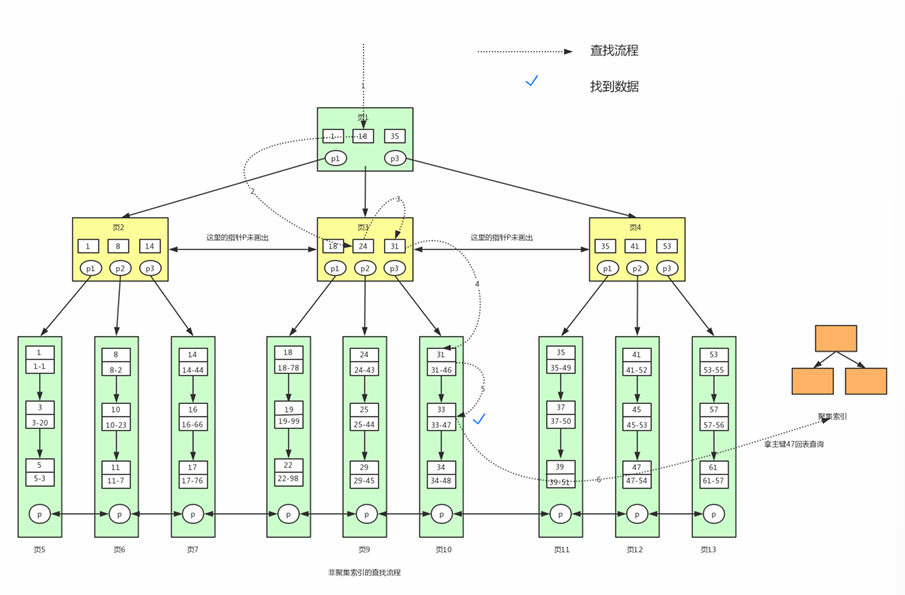
四、innode体系结构
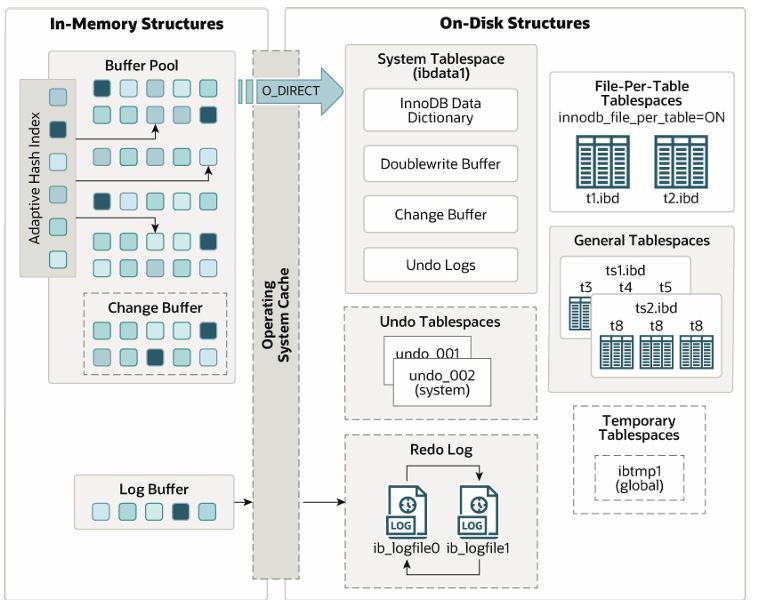
1.buffer pool
Buffer pool 缓存表和索引数据;采用 LRU 算法(原理如下图)让 Buffer pool 只缓存比较热的数 据 ;
buffer pool 中的数据修改没有刷到磁盘, 怎么确保内存中数据安全(mysql 关闭时,内存数据丢 失)?
1. Buffer Pool 的核心作用
Buffer Pool 是 InnoDB 存储引擎的一块内存区域,用于缓存表数据和索引数据。通过将频繁访问的数据驻留在内存中,减少磁盘 I/O,从而显著提升数据库的读写性能。
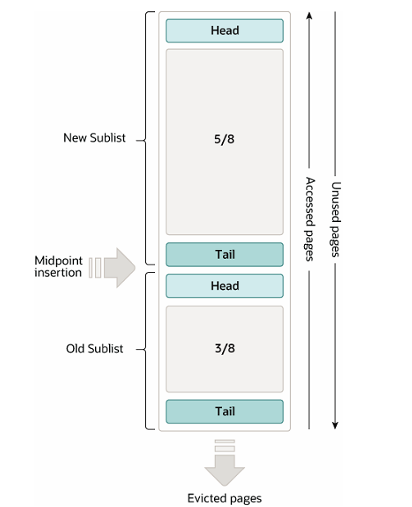
2. 改进的 LRU 算法(图示结构)
传统 LRU(最近最少使用)算法在数据库场景中存在缺陷(如全表扫描会污染缓存),因此 InnoDB 采用 优化的 LRU,将 Buffer Pool 划分为两个子列表:
- New Sublist(占比 5/8):存储频繁访问的 “热数据”。
- Old Sublist(占比 3/8):存储相对不常访问的数据。
- Midpoint Insertion(中间插入点):新数据或被访问的数据首次插入到 Old Sublist 的头部,而非直接进入 New Sublist。若后续未再次访问,该数据会从 Old Sublist 尾部淘汰,避免全表扫描等操作挤走真正的热数据。
3. 数据安全保障(未刷盘时)
当 Buffer Pool 中的数据被修改(成为 “脏页”)但未刷回磁盘时,MySQL 通过 重做日志(redo log) 保证数据安全:
- 修改数据时,先记录 redo log。即使 MySQL 异常关闭(内存数据丢失),重启后可通过回放 redo log 重新应用修改,恢复数据到一致性状态,确保持久性。
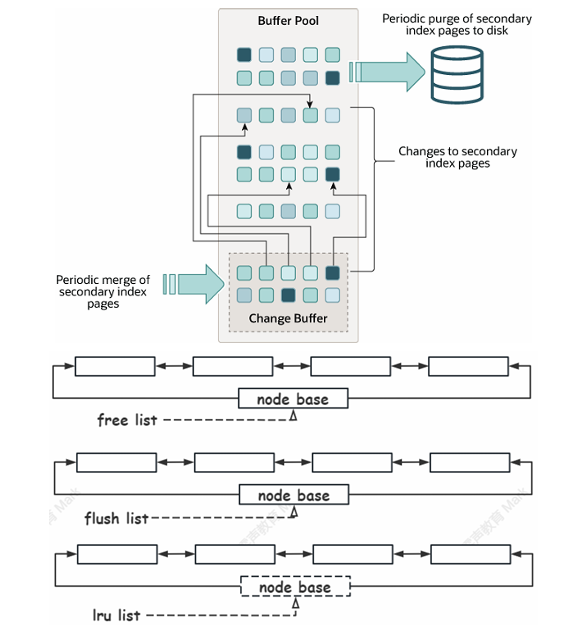
2.change buffer
Change buffer 缓存辅助(二级)索引的数据变更(DML 操作)这些数据并不在 buffer pool 中, Change buffer 中的数据将会异步 merge 到 buffer pool 中,当下次从磁盘当中读取非唯一索引的 数据;同时会定期合并到索引页中。
free list 组织 buffer pool 中未使用的缓存页;flush list 组织 buffer pool 中脏页,也就是待刷盘的 页;lru list 组织 buffer pool 中冷热数据,当 buffer pool 没有空闲页,将从 lru list 中最久未使用的 数据进行淘汰.
五、索引原则
一、最左匹配原则
概念:在联合索引中,MySQL 会从索引的最左列开始,依次向右匹配查询条件,直到遇到范围查询(如
>、<、BETWEEN等)或不满足条件的列为止。若跳过最左列,索引将失效。
示例:
表user有联合索引(name, age, gender):
SELECT * FROM user WHERE name = '张三' AND age = 20;(命中索引,从name开始匹配)。SELECT * FROM user WHERE age = 20 AND gender = 1;(索引失效,跳过了最左列name)。(但是如果是age在前name在后,优化器会自动重排走索引)。二、索引覆盖
概念:查询所需的所有字段都被索引包含,无需回表(即无需通过主键再查询数据行),直接从索引获取结果,提升查询效率。
示例:
表tb有索引(a, b),执行SELECT a, b FROM tb WHERE a = 1;
此时查询字段a、b都在索引中,直接通过索引返回数据,无需回表。三、索引下推(Index Condition Pushdown, ICP)
概念:MySQL 5.6 引入的优化,在使用二级索引时,将部分查询条件(如
AND连接的条件)下推到存储引擎层,在索引扫描阶段过滤掉不满足条件的记录,减少回表次数。
示例:
表有联合索引(a, b, c),执行SELECT * FROM tb WHERE a = 1 AND c = 3;
- 无 ICP:先通过
a = 1找到主键,回表后再判断c = 3。- 有 ICP:在索引层先判断
a = 1且c = 3,再回表,减少无效回表。四、索引失效
概念:因查询条件或操作不符合索引规则,导致索引无法被使用,转为全表扫描。
常见场景及示例:
- 最左列缺失:联合索引
(name, age),查询WHERE age = 20;(索引失效)。- 范围查询右侧列:联合索引
(a, b),查询WHERE a > 10 AND b = 2;(b列索引失效)。- 前模糊匹配(
%开头):索引(name),查询WHERE name LIKE '%张三';(索引失效)。- 索引列运算:索引
(age),查询WHERE age + 1 = 20;(对age运算,索引失效)。OR连接条件:索引(id)和(name),查询WHERE id = 1 OR name = '张三';(可能导致索引失效,全表扫描)。五、索引原则
1. 区分度优先:优先对区分度高(不重复值多)的列创建索引,如主键、唯一标识列。
2. 高频查询优先:将高频查询的列放在联合索引左侧。例如,常按(name, age)查询,索引顺序应为name在前。
3. 避免过多索引:每个索引都会占用磁盘空间,且写操作(增、删、改)会变慢。
4. 前缀索引优化:对长字符串,取部分前缀创建索引(如name(4)),减少索引大小。
5. 覆盖索引优化:尽量让查询字段被索引覆盖,避免SELECT *(可能触发回表)。
六、 优化器成本分析
MySQL 优化器主要针对 IO 和 CPU 会计算语句的成本;可能不会按照分析的原理来执行语句;
1.成本分析步骤
找出所有可能需要使用到的索引;
计算全表扫描的代价;
计算不同索引执行查询的代价;
对比找出代价最小的执行方案。
2.EXPLAIN
用来查看 SQL 语句的具体执行过程。
原理:模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理 SQL 语句的。
一、案例背景
假设我们有一张
orders表,存储订单数据,表结构和索引如下:CREATE TABLE orders (id BIGINT PRIMARY KEY, -- 主键(聚簇索引)user_id INT NOT NULL, -- 用户ID(辅助索引:idx_user_id)order_time DATETIME NOT NULL, -- 订单时间(辅助索引:idx_order_time)amount DECIMAL(10, 2) NOT NULL,status TINYINT DEFAULT 0 );-- 索引:用户ID + 订单时间(联合索引) ALTER TABLE orders ADD INDEX idx_user_time (user_id, order_time);表中数据量:100 万条,
user_id分布在 1-10 万(每个用户约 10 条订单)。二、优化器成本分析步骤示例
场景 1:全表扫描 vs 单索引扫描
查询语句
SELECT id, user_id, order_time FROM orders WHERE status = 1; -- status 无索引,可能全表扫描1. 找出可能的索引
- 无合适索引(
status未建立索引),只能选择全表扫描或尝试其他索引(但条件不匹配,实际会全表扫描)。2. 计算全表扫描代价
- IO 成本:假设每个数据页 16KB,表占用 1000 个数据页(100 万行 / 约 1000 行 / 页),全表扫描需读取 1000 个页。
- CPU 成本:每行判断
status=1,共 100 万次判断。- 总成本:
IO成本(1000) + CPU成本(100万)。3. 执行计划
通过
EXPLAIN查看EXPLAIN SELECT id, user_id, order_time FROM orders WHERE status = 1;输出关键信息:
id select_type table type rows cost 1 SIMPLE orders ALL 1000000 12345 -- 全表扫描(type=ALL),估计扫描 100 万行 场景 2:联合索引 vs 单索引
查询语句
SELECT id, order_time, amount FROM orders WHERE user_id = 100 AND order_time >= '2023-01-01';1. 找出可能的索引
idx_user_time(联合索引,最左匹配user_id=100后范围匹配order_time)idx_user_id(单索引,仅匹配user_id=100,需回表)2. 计算不同索引的代价
使用
idx_user_time(覆盖索引?否,需回表吗?)
- 索引扫描:通过
user_id=100定位,再扫描order_time >= '2023-01-01'的索引条目,假设匹配 100 条。- 回表成本:需根据主键
id回表获取amount(因amount不在索引中),100 次随机 IO。- 总成本:
索引扫描IO(少量) + 回表IO(100次) + CPU成本。使用
idx_user_id
- 单索引扫描
user_id=100,匹配 10 条(假设每个用户 10 条订单,实际可能更多,优化器估计错误)。- 回表后再过滤
order_time >= '2023-01-01',需扫描 10 条数据行。- 总成本:
单索引扫描IO + 回表IO(10次) + CPU过滤成本。3. 优化器选择
假设优化器估计
idx_user_time扫描 100 行,idx_user_id扫描 10 行(实际可能因统计信息不准确而误判),最终选择成本更低的idx_user_time。4. EXPLAIN 输出
EXPLAIN SELECT id, order_time, amount FROM orders WHERE user_id = 100 AND order_time >= '2023-01-01';关键信息:
type key key_len ref rows Extra range idx_user_time 8+5 const 100 Using index condition pushdown; Using where
type=range:使用联合索引范围查询。rows=100:优化器估计扫描 100 条索引记录。Extra=Using index condition pushdown:启用索引下推,在索引层过滤order_time。
七、慢日志查询
一、慢日志开启操作
1. 查看慢日志相关变量
通过两条 SQL 命令查看系统变量:
SHOW GLOBAL VARIABLES LIKE 'slow_query%';SHOW GLOBAL VARIABLES LIKE 'long_query%';2. 设置慢日志(临时生效)
使用
SET GLOBAL命令:
SET GLOBAL slow_query_log = ON;(ON开启,OFF关闭)。SET GLOBAL long_query_time = 4;(单位:秒,默认 10s,此处设置为 4s)。3. 修改配置(永久生效)
在配置文件中添加或修改以下内容:
slow_query_log = ON long_query_time = 4 slow_query_log_file = D:/mysql/mysql57-slow.log -- 指定慢日志文件路径二、
mysqldumpslow工具使用查找最近 10 条慢查询日志,示例命令:
mysqldumpslow -s t -t 10 -g 'select' D:/mysql/mysql57 -slow.log
-s t:按查询时间排序。-t 10:取前 10 条记录。-g 'select':筛选包含select关键字的日志(可替换为其他关键字)。D:/mysql/mysql57 -slow.log:慢日志文件路径。
0voice · GitHub