武汉大学无人机视角下的多目标指代理解新基准!RefDrone:无人机场景指代表达理解数据集

-
作者:Zhichao Sun, Yepeng Liu, Huachao Zhu, Yuliang Gu, Yuda Zou, Zelong Liu, Gui-Song Xia, Bo Du, Yongchao Xu
-
单位:武汉大学计算机学院
-
论文标题:RefDrone: A Challenging Benchmark for Drone Scene Referring Expression Comprehension
-
论文链接:https://arxiv.org/pdf/2502.00392
-
代码链接:https://github.com/sunzc-sunny/refdrone
主要贡献
-
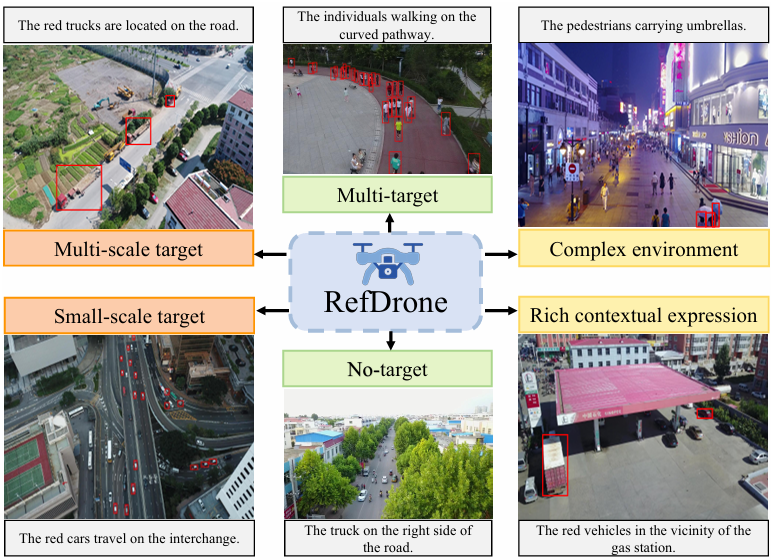
RefDrone基准数据集:提出了首个针对无人机场景中指代表达理解(REC)的综合性基准数据集RefDrone,它包含17900个指代表达,覆盖8536张图像,包含63679个目标实例。该数据集揭示了三个关键挑战:多尺度和小尺度目标检测、多目标和无目标样本、复杂环境中丰富的上下文表达。
-
RDAgent标注框架:开发了一种基于多智能体系统的半自动化标注工具RDAgent,用于REC任务。该框架通过将传统标注工作流程重构为多个智能体和人类标注者之间的交互系统,显著降低了标注成本,同时确保了高质量的复杂表达。
-
NGDINO方法:提出了一种名为Number GroundingDINO(NGDINO)的新方法,专门用于处理多目标和无目标样本。该方法通过引入数量预测头、可学习的数量查询编码以及数量交叉注意力模块,利用表达中提到的目标数量信息,显著提高了在多目标和无目标样本上的性能。
研究背景
-
无人机作为一种重要的机器人平台,在多种场景中发挥着重要作用,例如娱乐、包裹递送、交通监控和紧急救援等。在具身智能(Embodied AI)领域,无人机需要具备根据自然语言表达定位目标的能力,即指代表达理解(REC)。
-
然而,现有的REC数据集主要关注地面视角的场景,而无人机视角的场景具有独特的挑战,例如极端的视角变化、遮挡和目标尺寸变化等。因此,需要一个专门针对无人机场景的REC基准数据集,以推动相关技术的发展。

研究方法
数据集构建
-
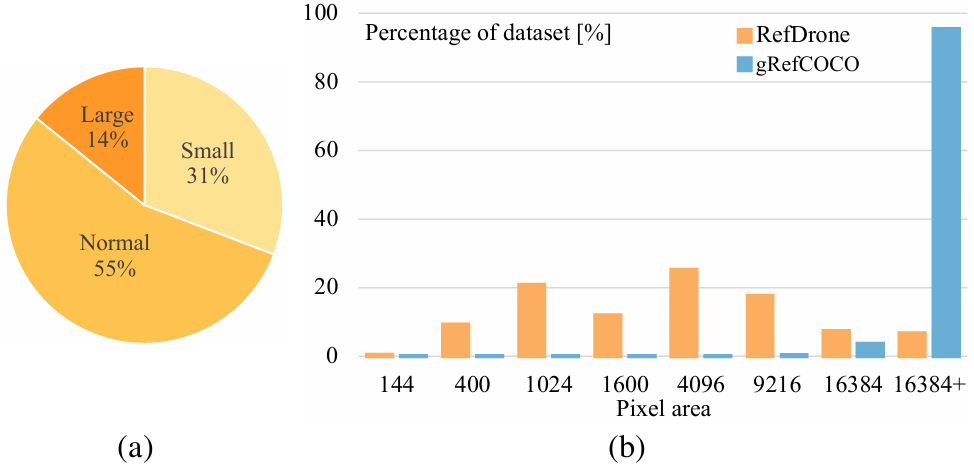
数据来源:RefDrone数据集基于VisDrone2019DET数据集构建,该数据集包含无人机拍摄的图像,涵盖了多种场景、光照条件和飞行高度。论文通过设定图像和目标级别的过滤标准,筛选出包含至少3个目标的图像,并排除面积小于64像素的目标。
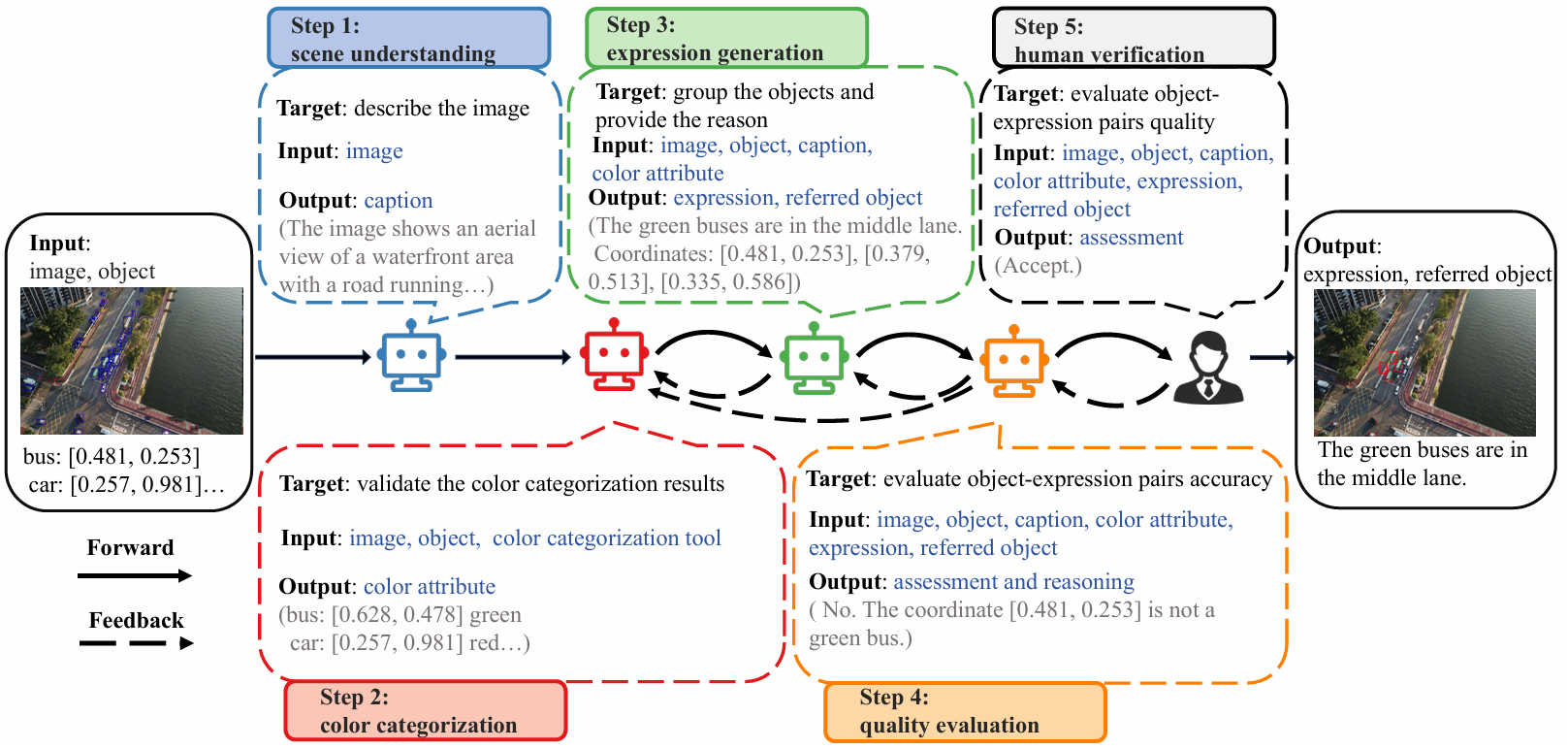
- RDAgent标注框架:该框架整合了大型语言模型(LLM)和人类标注者,通过五个结构化的步骤生成高质量的标注。具体步骤如下:
-
场景理解:基于GPT-4o的标题生成智能体为每张图像生成三个多样化的文本描述,为后续的指代表达生成提供上下文视角。
-
颜色分类:通过结合基于WideResNet-101模型的颜色属性提取和人工验证,确保颜色属性的准确性。
-
指代表达生成:将指代表达生成任务重新定义为对象分组问题,智能体的目标是将语义相关对象分组,并为每个组提供适当的理由(即指代表达)。如果检测到新的颜色,会触发动态反馈循环,返回颜色分类步骤。
-
质量评估:评估智能体对对象-表达对的语义准确性和指代唯一性进行评估,根据评估结果将标注分为“是”(准确且唯一)和“否”(不准确或不唯一)两类。对于“否”的标注,会根据问题类型返回到相应的步骤进行修正。
-
人工验证:人类标注者对标注输出进行三层次的审查,包括直接接受、需要修正和存在重大问题。对于存在重大问题的标注,会进入反馈循环,返回到质量评估步骤。
-

NGDINO方法
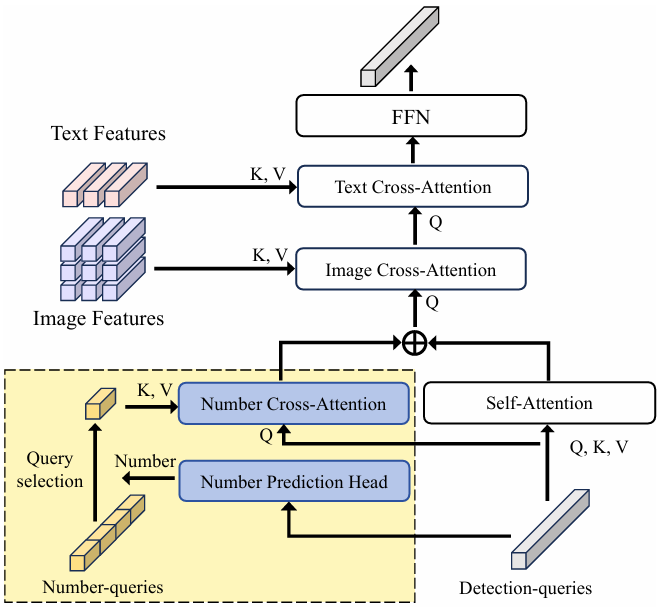
- 模型架构:NGDINO基于GroundingDINO(GDINO)的双编码器-单解码器架构,在解码器部分进行了改进。具体改进包括引入了数量预测头、可学习的数量查询编码以及数量交叉注意力模块。
-
数量预测头:通过前馈神经网络(FFN)层预测检测查询中提到的目标数量。
-
数量查询:这些查询是可学习的嵌入,用于捕获不同数量模式。通过预测的数量引导选择数量查询。
-
数量交叉注意力模块:将选定的数量查询与检测查询进行交叉注意力操作,将数量信息整合到检测查询中。
-
-
损失函数:对于边界框监督,采用GDINO中的损失函数。对于数量预测,使用L2损失。论文将数量预测空间量化为五个类别:{0, 1, 2, 3, 4+},其中4+表示所有大于等于4的数量。
实验
实验设置
-
RDAgent:通过将RDAgent适应于REC任务,用Faster R-CNN作为目标检测器,替换了人工验证步骤,以实现自动化。
-
NGDINO:采用两阶段过程进行训练。首先,在RefDrone数据集上预训练数量预测头,同时初始化其他组件的参数为GDINO的参数。然后,对整个模型进行微调。
-
基准模型:论文选择了13个具有代表性的模型作为基准,包括3个专家模型(MDETR、GLIP和GDINO)和10个大型多模态模型(LMMs)。
-
零样本评估:使用模型在原始论文中提供的检查点进行评估。
-
微调评估:保持原始学习策略一致,排除随机裁剪增强,对于LMMs采用LoRA微调策略。
实验结果
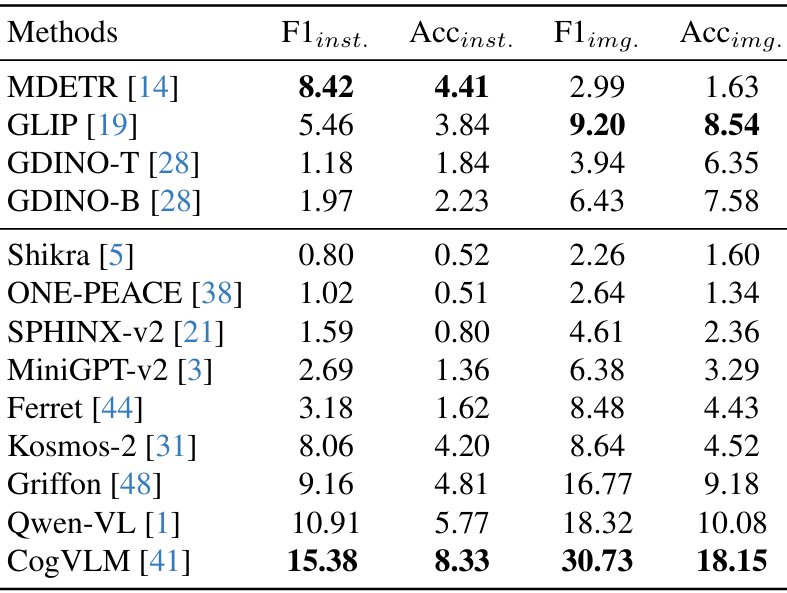
-
零样本结果:CogVLM在多个指标上表现出色,但一些先进的模型由于预训练数据或输出策略的限制,只能输出单个边界框,在多目标场景中表现受限。
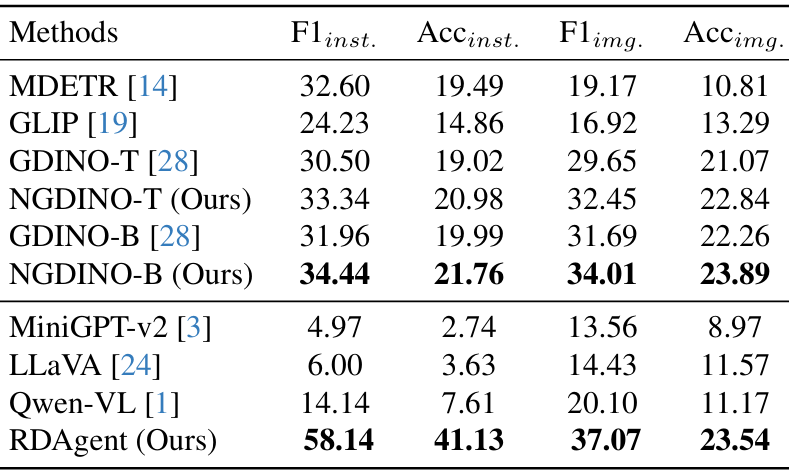
- 微调结果:
-
专家模型MDETR在实例级指标上表现出色,但图像级理解能力较弱。LMMs如Qwen-VL在图像级理解上表现较好,但在实例级任务上表现较差。
-
RDAgent在实例级指标上取得了优于现有方法的结果,与GDINO-B相比,F1inst.提高了26.18%,Accinst.提高了21.14%。NGDINO在两个骨干架构上均优于基线GDINO。
-
-
在gRefCOCO数据集上的验证:NGDINO-T在gRefCOCO数据集上也优于基线方法GDINO-T,尤其是在N-acc.指标上,分别在test A和test B上提高了4.15%和1.39%。
- 消融研究:
-
NGDINO组件的有效性:数量预测头单独使用时对引用任务的影响较小,而引入数量交叉注意力时,Accinst.从19.02%提高到19.51%。结合数量预测任务和数量交叉注意力组件后,Accinst.进一步提高到20.98%。
-
查询长度的影响:通过实验发现,查询长度为10时提供了最佳的权衡。
-
RDAgent的有效性:RDAgent在所有指标上均优于GPT4-o和ReCLIP,但其性能部分受到Faster-RCNN目标检测器的限制。
-
结论与未来工作
- 结论:
-
论文提出了RefDrone基准数据集,专门用于无人机场景中的指代表达理解任务,并开发了RDAgent半自动化标注框架和NGDINO方法。
-
- 未来工作:
-
尽管NGDINO在多目标和无目标样本上取得了较好的性能,但在处理复杂背景、丰富上下文表达和小尺度目标检测时仍存在挑战。
-
在未来的工作中,论文计划进一步改进NGDINO以应对这些挑战,并扩展基准数据集以包含指代表达分割和指代表达跟踪任务。
-
