GraspVLA:基于Billion-级合成动作数据预训练的抓取基础模型
25年5月来自银河通用(Galbot)、北大、港大和 BAAI 的论文“GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data”。
具身基础模型因其零样本泛化能力、可扩展性以及通过少量后训练即可适应新任务的优势,正日益受到关注。然而,现有模型严重依赖真实世界数据,而这些数据的收集成本高昂且耗费人力。合成数据提供了一种经济高效的替代方案,但其潜力仍未被充分开发。为了弥补这一不足,本文探索完全使用大规模合成动作数据训练“视觉-语言-动作”(VLA)模型的可行性。精选 SynGrasp-1B,一个十亿帧的机器人抓取数据集,采用照片级真实感渲染和广泛的域随机化技术,在模拟环境中生成。在此基础上,提出 GraspVLA 模型,这是一个基于大规模合成动作数据预训练的 VLA 模型,可作为抓取任务的基础模型。GraspVLA 将自回归感知任务和基于流匹配的动作生成集成到一个统一的“思维链”流程中,从而支持基于合成动作数据和互联网语义数据的联合训练。这种设计有助于弥补模拟与现实之间的差距,并促进将学习的动作迁移到更广泛的互联网覆盖目标,从而实现抓取的开放词汇泛化。在现实世界和模拟基准测试中开展的广泛评估证明 GraspVLA 先进的零样本泛化能力以及对特定人类偏好的少样本适应性。
GraspVLA 基础模型如图所示:
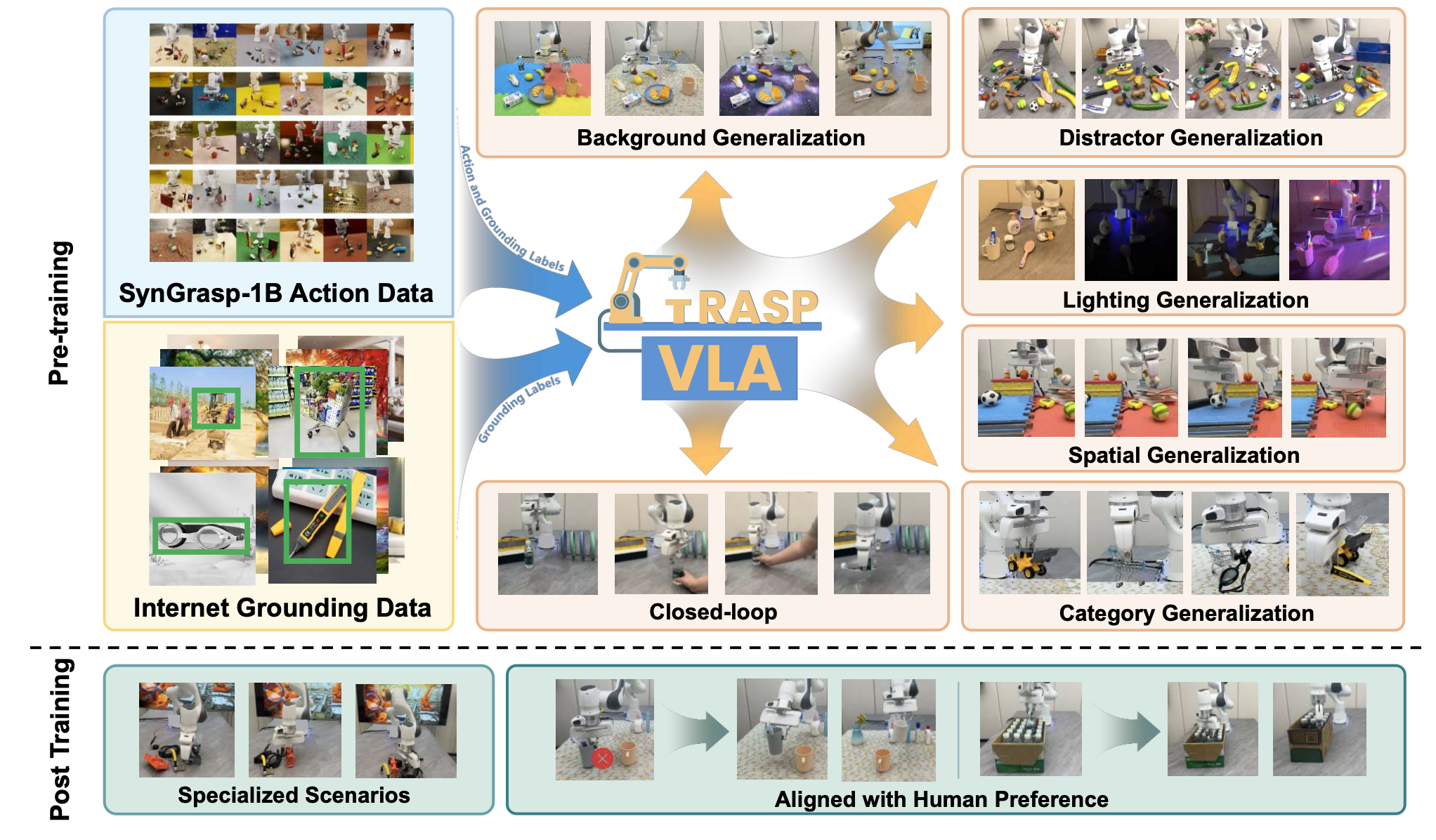
随着基础模型的出现,自然语言处理 (NLP) 和计算机视觉 (CV) 领域经历了范式转变。基于海量互联网数据预训练的大规模模型,展现出对未见过场景的零样本泛化能力 [1, 2, 3],以及与人类偏好相符的少样本自适应能力 [4]。受此成功的启发,用于物理世界动作的基础模型最近被引入视觉-语言-动作 (VLA) 模型 [5, 6, 7, 8]。这些模型处理机器人的视觉观察和人类指令,以直接生成机器人动作。然而,与视觉和语言模态不同,现有的互联网数据集中缺乏动作数据,因此需要一种新的数据收集范式。
最近的研究主要依赖于通过遥操作收集现实世界数据,例如 Open-X-Embodiment (OXE) [9] 和 DROID [10] 数据集等社区驱动的努力。然而,大规模收集现实世界数据既耗费人力又成本高昂,需要大量的机器人和人工操作,以及各种物理设置。相比之下,合成数据提供一种更易于获取且经济高效的替代方案,但其潜力仍然被大大低估。
为此,本文系统地探索合成数据在训练VLA模型方面的潜力。作为此方向的第一步,其专注于抓取——一项基本的机器人操作技能。首先基于先进的光线追踪渲染[11]和物理模拟[12],整理一个Billion-级帧数的抓取数据集 SynGrasp-1B,这是全球首个此规模的数据集。该数据集包含来自240个类别的10,000个独特目标,并涵盖广泛的域随机化,确保广泛覆盖几何和视觉变化。
为了高效地从该数据集中学习,提出 GraspVLA,这是一个端到端网络,它将自回归感知任务和基于流匹配的动作生成集成到一个统一的思维链 (CoT) 流程中,并命名为渐进式动作生成 (PAG)。PAG 将感知任务(即视觉基础和抓取姿势预测)视为动作生成的中间步骤,从而形成一个能够对动作进行因果推断的思维链流程。依托策划的 Billion-级合成抓取数据集和提出的 PAG 机制,GraspVLA 实现从模拟-到-真实的直接泛化,并展现出深刻的零样本性能。
训练一个可泛化的基础模型需要包含多样化物体和环境条件的大规模数据集。完全基于合成数据进行训练,而不是依赖昂贵、缓慢且有限的现实世界人工数据收集——这能以极低的时间和成本提供更大的多样性。
如图所示,合成数据生成流程的核心组件:布局生成、轨迹生成和渲染。
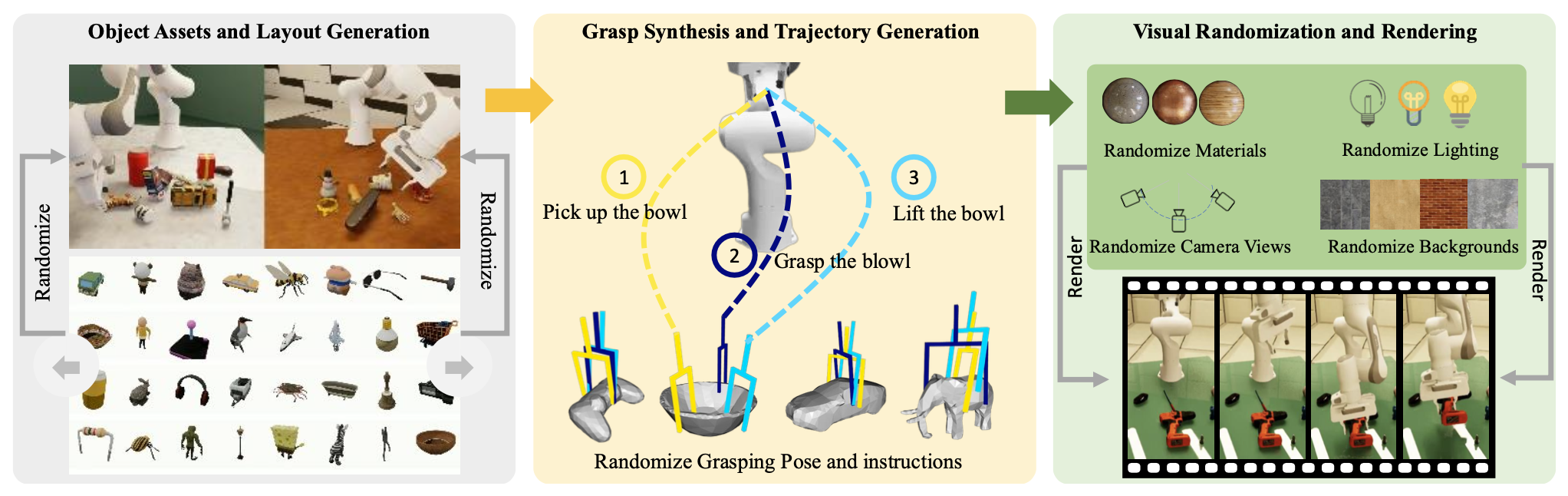
目标素材和布局生成。用 Objaverse 数据集 [63] 的 LVIS 子集,并仔细筛选出不合适的类别(例如武器),最终生成总共 240 个类别和 10,680 个实例。随机缩放这些目标,并将它们以各种姿势放置在桌面上,从而生成多样化且物理上合理的场景。
抓取合成和轨迹生成。给定初始布局,利用先进的模块化系统建立专家策略,以生成用于抓取和举起目标物体的高质量轨迹。对于每个目标实例,利用抓取合成算法 [64] 生成稳定的对映(antipodal)抓取。然后,使用运动规划算法 CuRobo [65] 规划无碰撞轨迹,以达到开环抓取姿势并举起目标。在 MuJoCo 物理模拟器 [12] 中验证所有候选轨迹,以确保成功举起目标。
视觉随机化与渲染。给定不同的布局和相应的轨迹,用 Isaac Sim [66] 渲染具有随机光照、背景和相机设置的高质量 RGB 图像,该引擎可提供高效的照片级真实感光线追踪渲染。采用各种光源,并进行广泛的随机化处理,包括点光源、定向光源和圆顶光源。图像从两个不同的视角渲染,以提供场景的全面视图,并围绕预定中心随机化外部参数。
进一步强调数据生成流程设计中的两个主要考虑因素:
高效的数据生成。开发三种关键策略来提升效率。高质量网格通常很大,导致加载时间过长且内存占用量巨大。实现缓存机制,以避免冗余加载,同时确保数据多样性。其次,实现异步数据写入,允许并行保存图像和标签,从而提高数据生成的整体效率。最后,采用并行物理模拟和渲染来进一步提高效率。
为模仿学习定制数据。为了降低模仿学习的难度,引入两项改进。首先,虽然开环抓取 [14] 采用两步流程(预抓取定位,然后执行抓取)来避免碰撞,但这种分段式方法会产生停顿。基于此类数据训练的模仿策略通常会出现犹豫 [6, 67]。因此,本文实现单步运动规划,优先考虑轨迹平滑度而不是规划成功率。其次引入了随机化的初始机器人姿态,以改善专家演示中的工作空间探索和观察多样性,从而增强模型的鲁棒性 [68]。
基于此流程,用 160 块 NVIDIA 4090 GPU,历时 10 天,生成十亿帧的数据集 SynGrasp-1B。
总体架构。GraspVLA 将视觉-语言模型 (VLM) 与动作专家 [7] 集成,并通过渐进式动作生成 (PAG) 机制连接,如图所示。VLM 获取观察图像和文本指令,用于视觉-语言联合感知。它包含一个可训练的大语言模型 (InternLM2 1.8B [69])、一个融合 Freeze DINO-v2 [70] 和受 OpenVLA [6] 启发 SigLIP [71] 特征的视觉编码器,以及一个从视觉空间到语言空间的可训练投影器。用条件流匹配动作专家 [72] 进行细粒度的末端执行器动作生成。进一步引入 PAG,以便将从互联网基础数据集中学习的知识有效地迁移到抓取技能。
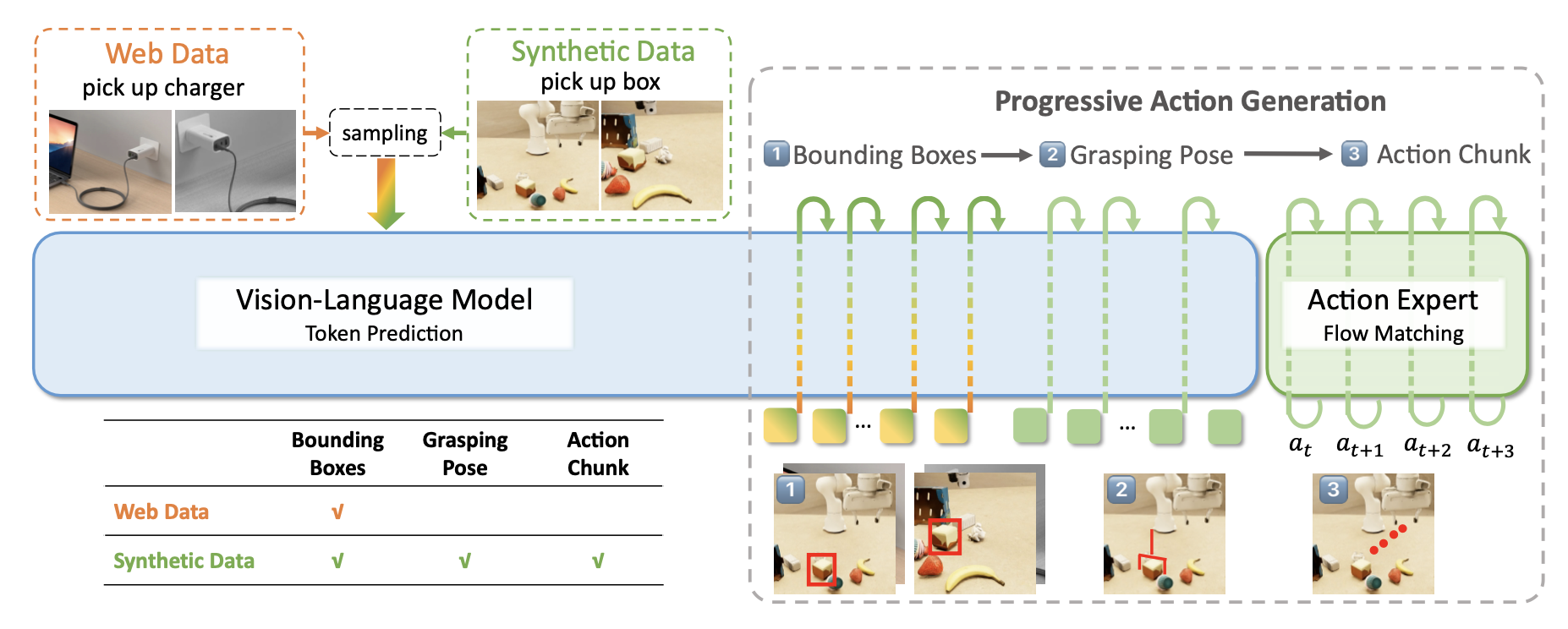
渐进式动作生成。虽然 GraspVLA 可以从 SynGrasp-1B 数据集中学习可泛化的抓取技能,但它受到合成数据集中现有类别集的限制。为了将抓取策略扩展到新的类别,一种直接的方法是将其与互联网基础数据集作为单独的任务进行联合训练,并依靠模型隐式地泛化到从落地数据集中学习的目标类别。
或者,将图像落地数据集和抓取姿势预测作为生成动作的中间步骤。具体而言,对互联网落地数据集和合成动作数据,训练 VLM 以统一的格式生成目标边框。然后,对于合成数据集,VLM 进一步预测机器人基准框架下的目标抓取姿势。最后,动作专家根据 VLM 的输入和中间推理 token 的键-值(K-V)缓存生成动作块。为了实现精确的 3D 感知,在生成抓取姿势之前,将最近两个时间步的本体感觉token化并插入。为了使互联网数据集与 SynGrasp-1B 的双摄像头设置保持一致,输入图像会被复制以匹配视图数量,并通过随机调整大小、裁剪、水平翻转和颜色抖动进行独立增强。两个数据集共享相同的文本提示模板,首先生成边框 tokens。这种统一的训练策略充分利用了互联网基础数据集和合成数据集之间的协同作用,类似于经过广泛研究并被证明是处理大语言模型中高度复杂任务的有效方法的“思维链”推理机制 [73]。
VLM 与动作专家的联合训练。在每个批次中,从互联网数据集 (GRIT [74]) 和合成动作数据集中随机抽样。前者仅用于以自回归方式监督 VLM 的边框预测。后者监督边框、抓取姿势和基于光流匹配的动作预测。
动作专家在分块末端执行器增量动作上采用光流匹配损失进行监督。
与多个基线进行比较,包括 VLA 通才模型和模仿学习专家模型。对于通才模型,用 π0 [7]、OpenVLA [6] 和 Octo [26],这三个基于 Transformer 的策略均在大规模真实数据集上进行预训练。为确保比较公平,在 SynGrasp-1B 数据集上对这三个模型进行微调。此外,为了评估在 SynGrasp-1B 上进行预训练的有效性,报告直接从其 VLM 权重 [77] 微调 π0 的结果,而无需进行跨具身机器人预训练。对于专家模型,用扩散策略 [75],这是一个用于视觉条件模仿学习的强扩散基线。由于它缺乏语言条件,仅使用一个大象类别对其进行训练和测试。
LIBERO [13] 是广泛使用的机器人操作模拟基准,涵盖各种任务和目标类别。评估三个 LIBERO 套件(长、目标、物体),但不包括空间推理,因为其侧重于空间推理,不在评估范围内。为了专注于抓握能力,省略非抓握任务(例如“打开炉子”),并将任务标题重新表述为“拾取{物体}”,每个套件选择 7-10 个任务。根据标准评估方案,每个任务都经过 50 个随机初始配置的严格测试,每个套件共进行 350-500 次试验。
将 GraspVLA 与 AnyGrasp [14] 进行对比,AnyGrasp 是一款最先进的抓取检测模型,专门用于抓取。对于基于语言条件的抓取,将 AnyGrasp 与 Grounding DINO [78](一款流行的开放词汇目标检测器)相结合,以筛选抓取候选目标。使用相同的两个基本测试集,指标包括总体成功率(任务完成率)和抓取成功率(抓取任何物体)。为了区分抓取性能,设计两个额外的测试集(每个 30 次试验):一个包含常见的家用物品,另一个包含透明物体,机器人可以抓取场景中的任何物体。