InternVL3: 利用AI处理文本、图像、视频、OCR和数据分析
InternVL3推动了视觉-语言理解、推理和感知的边界。
在其前身InternVL 2.5的基础上,这个新版本引入了工具使用、GUI代理操作、3D视觉和工业图像分析方面的突破性能力。
让我们来分析一下是什么让InternVL3成为游戏规则的改变者 — 以及今天你如何开始尝试使用它。
InternVL3的突出特点是什么?
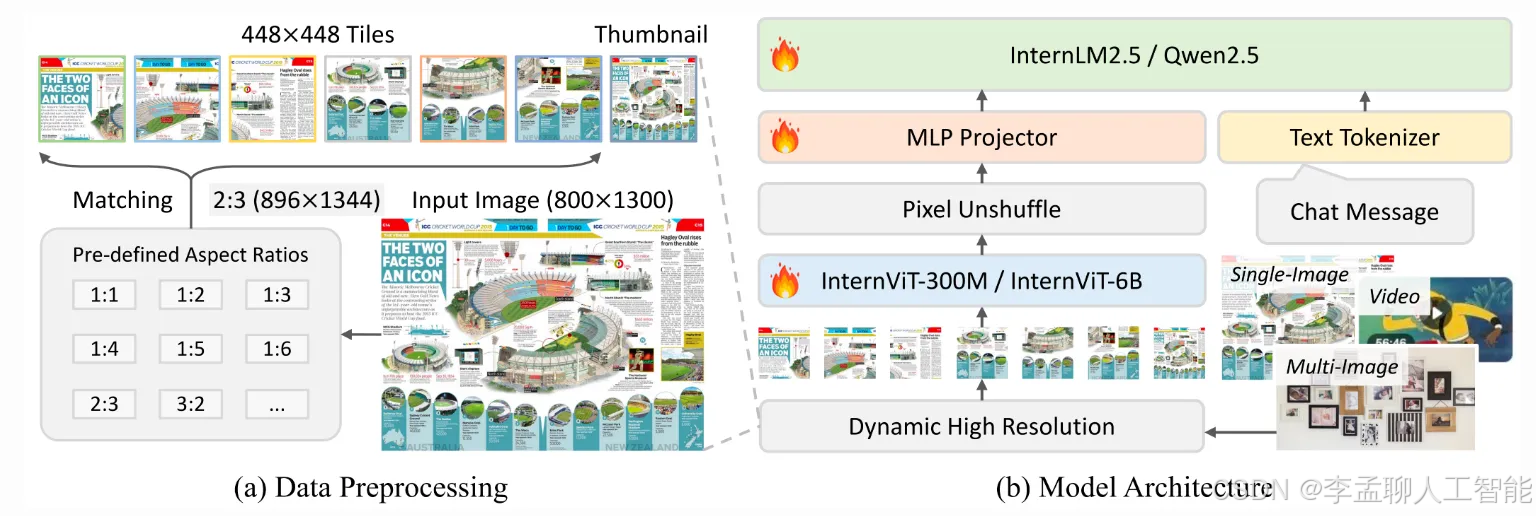
InternVL3不仅仅是一个渐进式更新 — 它是一个飞跃。原因如下:
-
扩展的多模态能力 与传统模型将视觉和语言处理分隔开不同,InternVL3从根本上无缝集成了两者。它在单一框架中处理图像-文本、视频-文本和纯文本数据,实现了更丰富的跨模态推理。无论你是在分析图表、从图像中提取文本,还是描述视频内容,InternVL3都能提供连贯的见解。
-
可变视觉位置编码(V2PE) V2PE为视觉标记使用更小、更灵活的位置增量。这种修改促进了处理更长的多模态上下文,而不会过度扩展位置窗口,使OCR和工业图像分析等任务更快速、更准确。
-
原生多模态预训练