运行Spark程序-在Spark-shell——RDD
一、基本概念
RDD(弹性分布式数据集)是 Apache Spark 的核心抽象,是 Spark 提供的最基本的数据处理单元。理解 RDD 的概念对于掌握 Spark 编程至关重要。以下是 RDD 的核心概念和特性:
1. 什么是 RDD?
- 定义:RDD 是一个不可变、可分区、元素可并行计算的集合。
- 特点:
- 弹性:自动进行内存和磁盘的切换(内存不足时可溢写到磁盘),并支持容错恢复。
- 分布式:数据分散存储在集群的多个节点上,可并行处理。
- 不可变:创建后不能修改,但可以通过转换操作生成新的 RDD。
2. RDD 的核心特性
2.1 分区(Partitions)
- RDD 由多个分区组成,每个分区是数据的一个片段,分布在不同节点上。
- 分区数决定了并行计算的粒度,可通过
rdd.partitions.size查看。
2.2 依赖关系(Dependencies)
- RDD 之间通过依赖关系形成血缘(Lineage)。
- 窄依赖:每个父 RDD 的分区最多被一个子 RDD 的分区使用(如
map、filter)。 - 宽依赖:多个子 RDD 的分区依赖同一个父 RDD 的分区(如
groupByKey、reduceByKey),会触发 Shuffle。
- 窄依赖:每个父 RDD 的分区最多被一个子 RDD 的分区使用(如
2.3 计算函数(Compute)
- RDD 提供一个计算函数,用于从父 RDD 计算当前分区的数据。
2.4 分区器(Partitioner)
- 对键值对 RDD 有效,决定数据在分区间的分布(如 Hash 分区、Range 分区)。
2.5 首选位置(Preferred Locations)
- 数据本地性优化,计算任务优先调度到数据所在节点。
3. RDD 的创建方式
- 从集合创建:
sc.parallelize(seq)或sc.makeRDD(seq)。scala
val rdd = sc.parallelize(1 to 100) - 从外部数据源创建:
sc.textFile(path)、sc.hadoopFile()等。scala
val textRDD = sc.textFile("hdfs://path/to/file.txt") - 从现有 RDD 转换:通过
map、filter等转换操作生成新 RDD。scala
val squaredRDD = rdd.map(x => x * x)
4. RDD 的操作类型
RDD 操作分为两类:转换(Transformations) 和 行动(Actions)。
4.1 转换操作(Transformations)
- 特点:惰性执行,返回新的 RDD,不触发实际计算。
- 常见转换:
scala
map(func) // 对每个元素应用函数 filter(func) // 过滤符合条件的元素 flatMap(func) // 展开元素(如将一行拆分为多个单词) groupByKey() // 按键分组 reduceByKey(func)// 按键聚合(比 groupByKey 更高效) join(otherRDD) // 键值对 RDD 的连接操作
4.2 行动操作(Actions)
- 特点:触发实际计算,返回结果或写入外部存储。
- 常见行动:
scala
collect() // 将 RDD 元素收集到驱动程序 count() // 统计元素数量 reduce(func) // 聚合元素 saveAsTextFile() // 保存 RDD 到文件 foreach(func) // 对每个元素执行操作
5. RDD 的容错机制
- 血统(Lineage):RDD 通过记录依赖关系(即血统)来实现容错。当某个分区丢失时,可根据依赖关系重新计算。
- 检查点(Checkpoint):将 RDD 写入可靠存储(如 HDFS),用于截断过长的血统链,提高容错效率。
scala
rdd.checkpoint() // 需要先设置 checkpoint 目录
6. RDD 的缓存与持久化
- 缓存(Cache):将 RDD 存储在内存中,加速重复使用。
scala
rdd.cache() // 等价于 rdd.persist(StorageLevel.MEMORY_ONLY) - 持久化(Persist):支持多种存储级别(内存、磁盘、堆外等)。
scala
rdd.persist(StorageLevel.MEMORY_AND_DISK) // 内存不足时溢写到磁盘
7. RDD 的局限性
- 低级别抽象:需要手动管理分区、依赖和容错,编程复杂度较高。
- 批处理优化:适合批量处理,不适合实时流处理(Spark Streaming 更适合)。
8. RDD vs. DataFrame/Dataset
| 特性 | RDD | DataFrame/Dataset |
|---|---|---|
| 类型安全 | 支持任意类型 | 需要结构化类型(如 case class) |
| 优化 | 无自动优化 | 支持 Catalyst 优化器 |
| 执行效率 | 较低(手动管理) | 较高(自动优化和代码生成) |
| API 级别 | 低级别(手动控制) | 高级别(声明式操作) |
总结
RDD 是 Spark 的基础抽象,提供了灵活的分布式数据处理能力。理解 RDD 的分区、依赖、转换和行动操作是掌握 Spark 编程的关键。在实际应用中,对于结构化数据推荐使用更高级的 DataFrame/Dataset API,但 RDD 仍然适用于需要细粒度控制的复杂场景。
二、RDD的创建
1.从集合内存中创建
可以通过将本地集合(如数组、列表等)传递给 SparkContext 的 parallelize 方法来创建 RDD。
// 创建 SparkConf 和 SparkContextval conf = new SparkConf().setAppName("RDDFromCollection").setMaster("local[*]")val sc = new SparkContext(conf)// 创建一个本地集合val data = Array(1, 2, 3, 4, 5)// 通过 parallelize 方法将本地集合转换为 RDDval distData = sc.parallelize(data, 2) // 第二个参数是分区数2.从外部存储中创建。
例如,读入外部的文件。
// 创建 SparkConf 和 SparkContextval conf = new SparkConf().setAppName("RDDFromHDFS").setMaster("local[*]")val sc = new SparkContext(conf)// 从 HDFS 加载文本文件val hdfsRDD = sc.textFile("hdfs://namenode:8020/path/to/your/file.txt")
// 获取并打印分区数val partitionCount = hdfsRDD.getNumPartitions
println(s"The number of partitions is: $partitionCount")要先确保这个外部的文件是存在的。可以通过getNumPartitions来获取分区的数量。
三、SparkConf 和 SparkContext
上面的代码中,我们用到了两个特殊的类来创建spark上下文,分别是SparkConf,SparkContext。
SparkConf 类用于配置 Spark 应用程序的各种参数。通过 SparkConf 类,你可以设置应用程序的名称、运行模式(如本地模式、集群模式)、资源分配(如内存、CPU 核心数)等。主要作用配置应用程序参数:可以设置 Spark 应用程序的各种属性,如应用程序名称、主节点地址等。
SparkContext 是 Spark 应用程序的入口点,它代表了与 Spark 集群的连接。通过 SparkContext,你可以创建 RDD(弹性分布式数据集)、累加器、广播变量等,还可以与外部数据源进行交互。
四、在shell中运行RDD程序
准备工作:启动hdfs集群,打开hadoop100:9870,在wcinput目录下上传一个包含很多个单词的文本文件。
写交互式代码:启动之后在spark-shell中写代码。
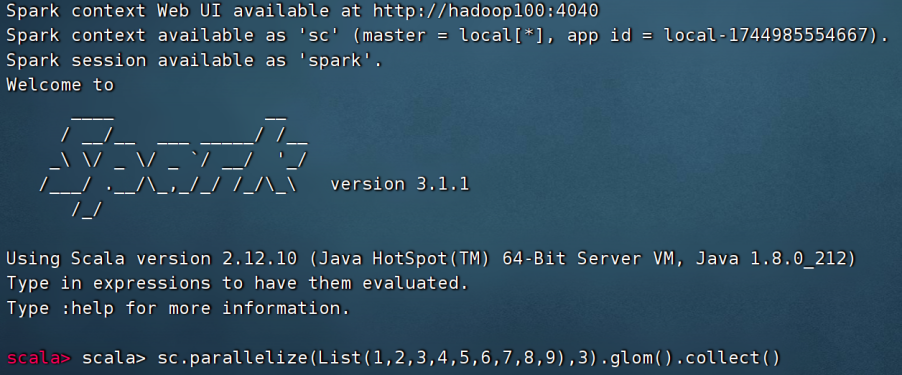
进入环境:spark-shell --master yarn
逐句写代码:
// 读取文件,得到RDDval rdd1 = sc.textFile("hdfs://hadoop100:8020/wcinput/words.txt")// 将单词进行切割,得到一个存储全部单词的RDDval rdd2= fileRDD.flatMap(line => line.split(" "))// 将单词转换为元组对象,key是单词,value是数字1val rdd3= wordsRDD.map(word => (word, 1))// 将元组的value按照key来分组,对所有的value执行聚合操作(相加)val rdd4= wordsWithOneRDD.reduceByKey((a, b) => a + b)// 收集RDD的数据并打印输出结果rdd4.collect().foreach(println)五、RDD的执行过程
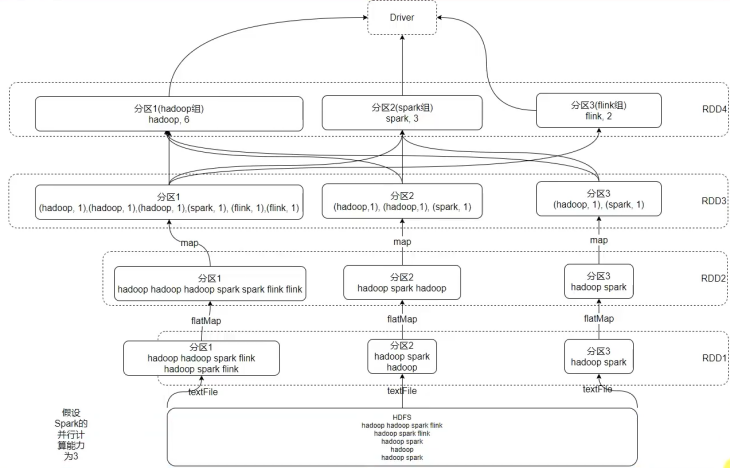
六、RDD 的五大特征
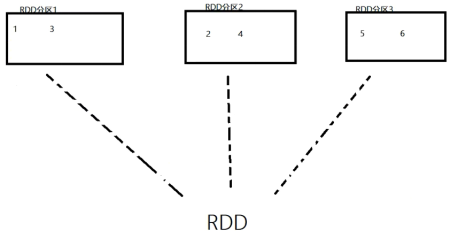
1.RDD是有分区的。
RDD的分区是RDD数据存储的最小单位。一份数据本质是分隔了多个分区。 如下图示,假如1个RDD有3个分区,RDD内存储了123456,那么数据本质上分散在三个分区内进行存储。
2.计算函数会作用于每个分区
RDD的方法会作用在所有的分区上。
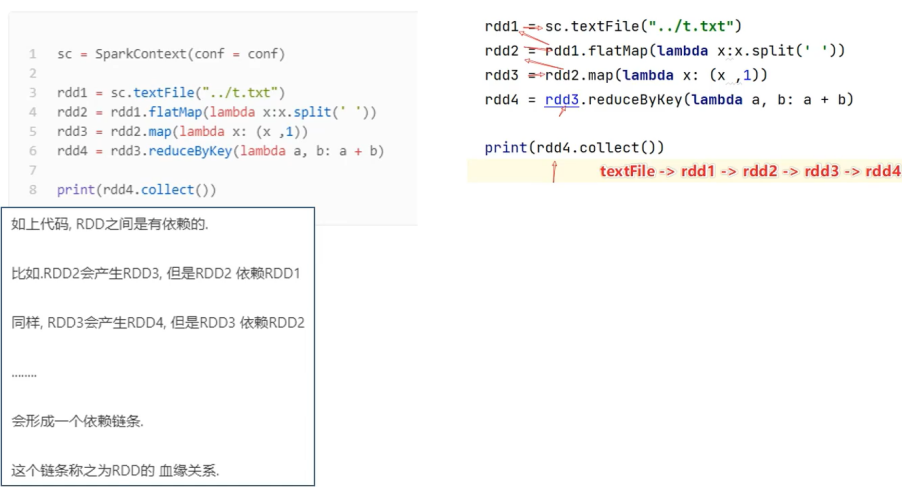
3.每个RDD之间是有依赖关系(RDD有血缘关系)
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4.Key-Value型的RDD可以有分区器
数据默认分区器:Hash分区规则,可以手动设置一个分区器(rdd.partitionBy的方式来设置)
5.每一个分区都有一个优先位置列表
优先位置列表会存储每个Partition的优先位置,对于一个HDFS文件来说,就是每个Partition块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度时,会尽可能地将任务分配到其所要处理数据块的存储位置。