数据挖掘入门-二手车交易价格预测
一、二手车交易价格预测
1-1 项目背景
随着二手车市场的快速发展,二手车交易价格的预测成为了一个热门研究领域。精准的价格预测不仅能帮助买卖双方做出更明智的决策,还能促进市场的透明度和公平性。对于买家来说,了解合理的市场价格可以避免因信息不对称而支付过高的费用;对于卖家来说,合理的定价可以提高车辆的成交率和收益。
1-2 功能需求
1.数据处理与特征工程
- 数据读取与清洗:从CSV文件读取数据,处理缺失值、异常值。
- 特征选择与提取:选择数值和类别特征列,构造训练和测试样本。
- 特征降维:使用PCA、FastICA、FactorAnalysis等方法进行特征降维。
2.模型训练与预测
- 模型选择:使用多种模型进行训练,包括线性回归(sklearn.linear_model)、支持向量机回归(sklearn.svm.SVR)、随机森林回归(sklearn.ensemble.RandomForestRegressor)、梯度提升回归(sklearn.ensemble.GradientBoostingRegressor)以及XGBoost和LightGBM等。
- 模型训练:利用K折交叉验证(StratifiedKFold)训练模型,并评估模型性能(mean_absolute_error)。
- 模型优化:使用网格搜索(GridSearchCV)进行超参数调优。
3.模型评估
- 性能评估:使用平均绝对误差(mean_absolute_error)指标评估模型性能。
- 结果输出:输出并保存预测结果,查看预测值的统计信息。
4.结果融合
- 加权融合:通过加权平均方法融合多个模型的预测结果,提高预测准确性。
- 结果修正:对融合后的预测结果进行后处理,确保合理性。
5.可视化
- 数据可视化:使用Matplotlib和Seaborn进行数据可视化,展示数据分布及模型预测结果。
1-3 输入数据分析
1. 训练数据集(used_car_train_20200313.csv)
(1)数据规模:150,000条记录,31个特征。
(2)特征信息:
数值型特征:
-
-
- SaleID: 销售ID
- name: 车辆名称
- regDate: 注册日期
- model: 车型编号
- brand: 品牌编号
- bodyType: 车身类型
- fuelType: 燃料类型
- gearbox: 变速箱类型
- power: 功率
- kilometer: 行驶里程
- regionCode: 区域代码
- seller: 卖家类型
- offerType: 报价类型
- creatDate: 创建日期
- price: 价格(目标变量)
- v_0到v_14: 特征变量
-
类别型特征:
-
-
- notRepairedDamage: 是否有未修复的损坏
-
(3)缺失值信息:
-
-
- model: 缺失1条
- bodyType: 缺失4506条
- fuelType: 缺失8680条
- gearbox: 缺失5981条
- notRepairedDamage: 缺失值处理(需进一步处理)
-
2. 测试数据集(used_car_testB_20200421.csv)
(1)数据规模:50,000条记录,30个特征。
(2)特征信息:与训练数据集相同,但没有价格(目标变量)列。
(3)缺失值信息:
-
-
- model: 无缺失值
- bodyType: 缺失1585条
- fuelType: 缺失3011条
- gearbox: 缺失1743条
-
1-4 输出数据分析
1.输出与保存
- 加权平均预测结果。
- 查看预测值的统计信息。
- 保存最终预测结果。
2.模型评估
- 使用平均绝对误差(MAE)指标评估模型性能。
二、设计过程
2-1 数据准备
1.数据获取
提供的训练数据集(used_car_train_20200313.csv)和测试数据集(used_car_testB_20200421.csv)。
2.数据读取
使用Pandas读取CSV文件。
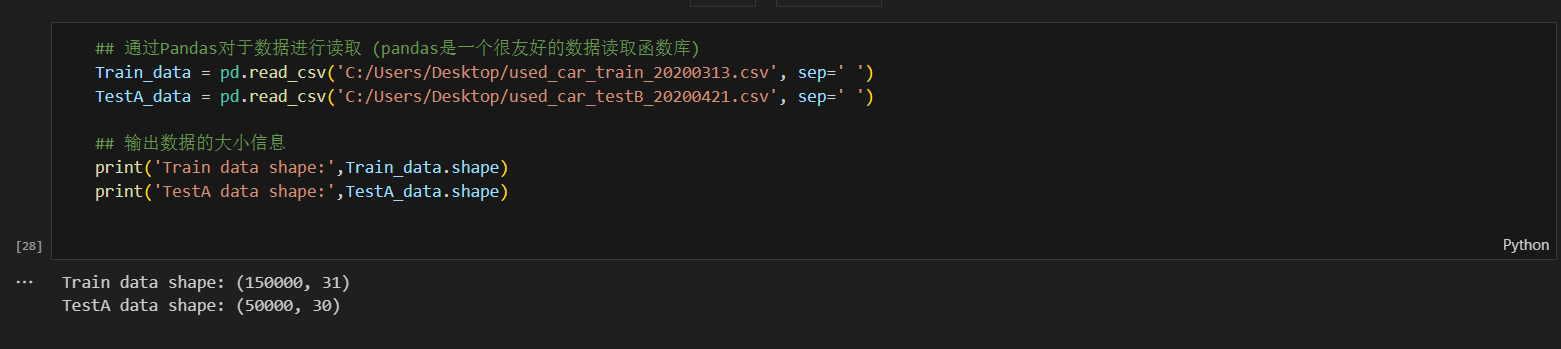
3.数据查看与分析
查看数据的基本信息、头部数据和缺失值情况。
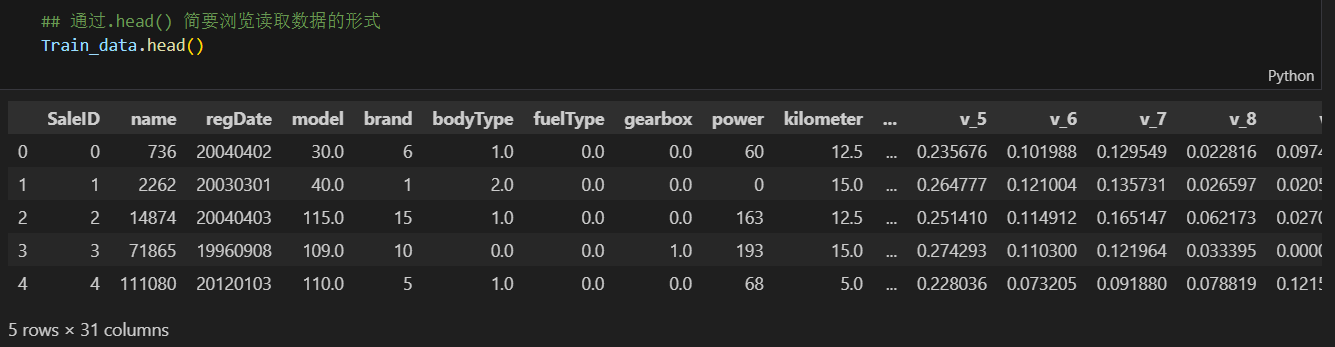
简要可以看到对应一些数据列名,以及NAN缺失信息。
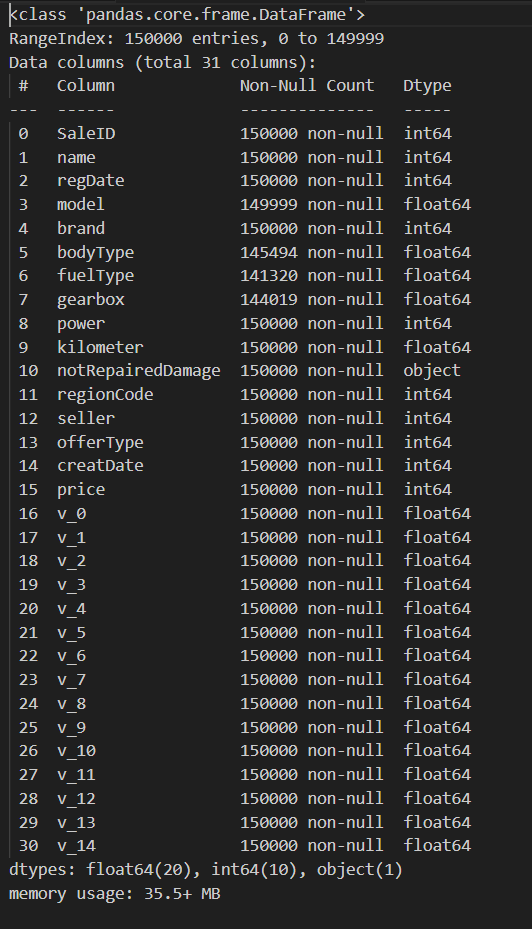
查看列名。

2-2 数据清洗与预处理
1.处理缺失值
- 对于数值型特征,使用均值、中位数或其他统计量填补缺失值。
- 对于类别型特征,使用众数或添加一个新类别表示缺失值。
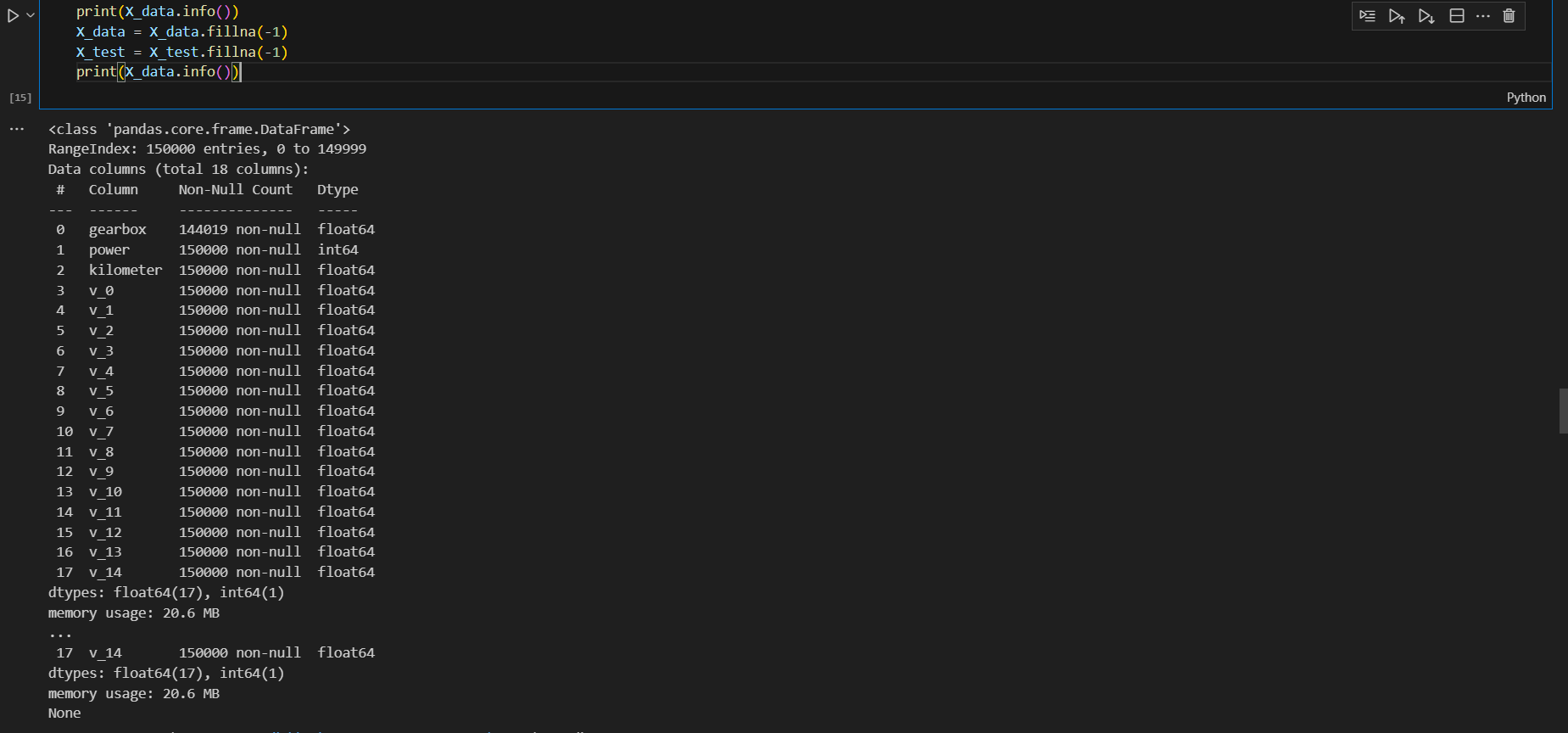
2.特征选择
选择与价格预测相关的特征,去除无关或重复的特征。
3.特征处理
对特征进行编码、标准化和归一化等处理。
2-3 特征工程
1.特征提取
从现有特征中提取新的特征,如日期特征、交互特征等。
2.特征降维
使用PCA、FastICA、FactorAnalysis等方法进行特征降维,减少特征维度,提升模型训练速度和性能。
2-4 模型选择与训练
1.模型选择
选择多种机器学习模型进行训练,这里用XGBoost、LightGBM。
LightGBM训练
XGboost训练
2.模型训练
使用K折交叉验证(StratifiedKFold)进行模型训练,并评估模型性能。
3.模型调优
使用网格搜索(GridSearchCV)进行超参数调优,选择最佳参数组合。
2-5 模型评估与优化
1.模型评估
使用平均绝对误差(MAE)指标评估模型性能。
2.模型融合
通过加权平均、堆叠等方法融合多个模型的预测结果,提高预测准确性。

3.结果修正
对模型预测结果进行后处理,确保合理性。
2-6 模型预测与结果保存
1.预测测试数据
使用训练好的模型对测试数据进行预测。
2.保存预测结果
将预测结果保存为CSV文件,并查看预测值的统计信息。
三、结果及分析
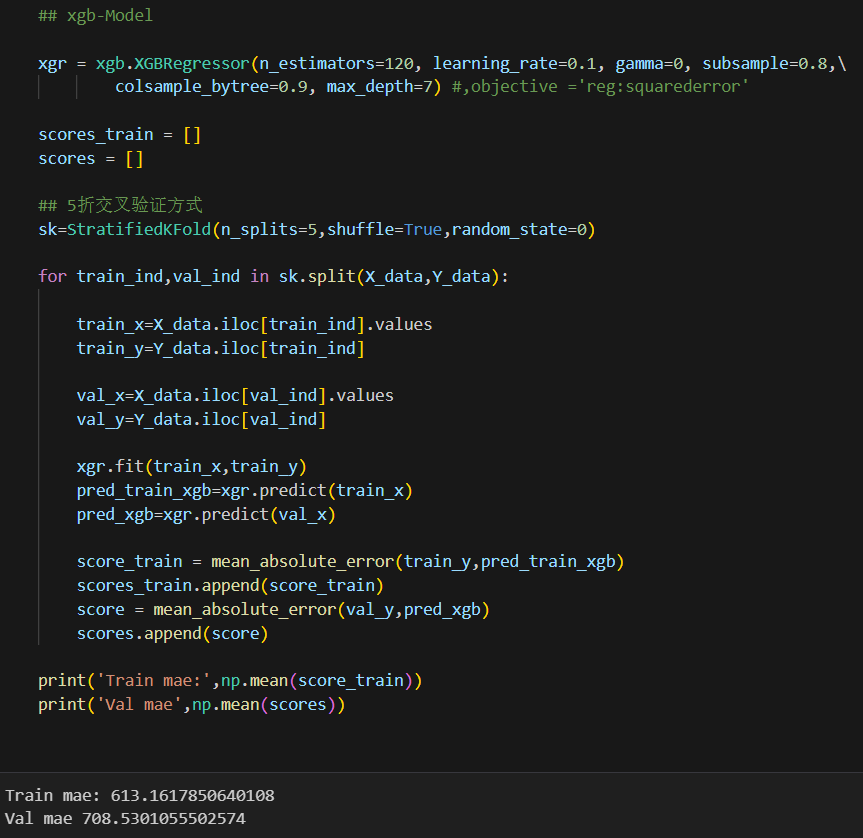
3-1 训练和评估 一个基于XGBoost回归的模型
训练和评估一个基于XGBoost回归(XGBRegressor)的模型,通过5折交叉验证方式来评估模型在训练集和验证集上的表现
结果:
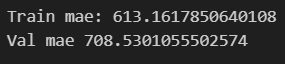
计算训练集上的平均MAE为613.1617850640108
计算验证集上的平均MAE为708.5301055502574
分析:
该数据用于评估XGBoost模型在数据集上的表现,确保模型具有较好的泛化能力,并选择最佳的模型超参数。数据来看模型基本符合要求。
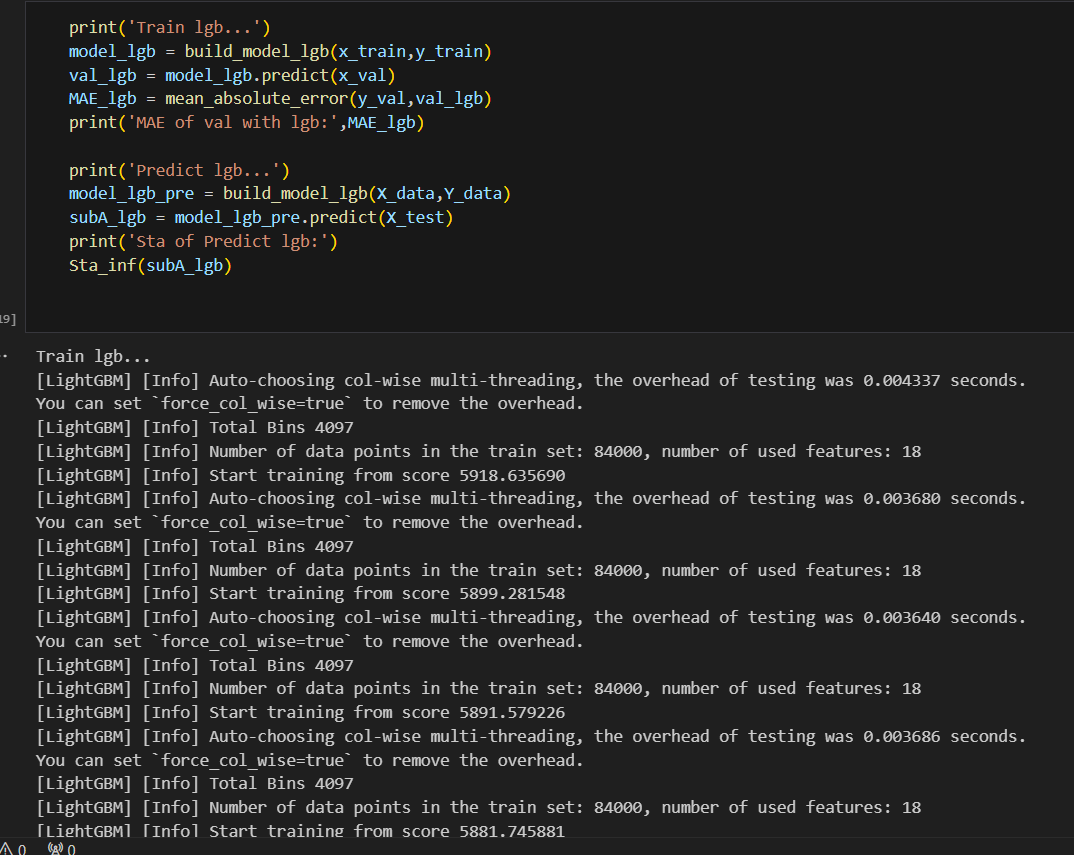
3-2 训练LightGBM模型
训练 LightGBM模型,并在验证集上评估模型性能,随后使用训练好的模型对测试数据进行预测。
LightGBM模型验证集上的平均MAE:
![]()
预测结果的统计信息:
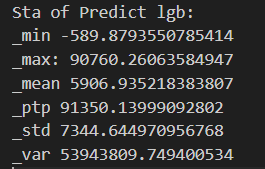
分析:
训练 LightGBM 模型,评估其性能,并对测试数据进行预测和统计分析。从结果来看模型基本符合要求。
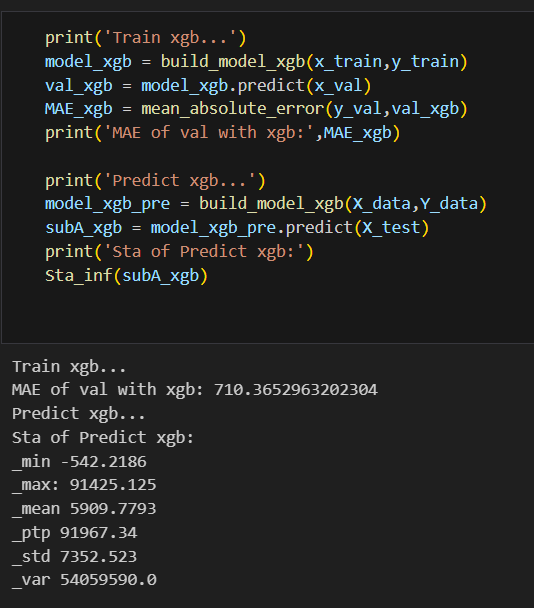
3-3训练XGBoost模型
训练XGBoost模型、评估其在验证集上的性能,以及使用该模型对测试集进行预测并进行统计分析。
XGBoost模型验证集上的平均MAE和预测结果的统计信息:
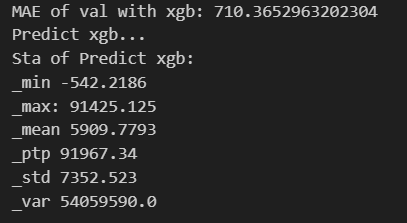
分析:
使用XGBoost模型进行训练和预测,并对预测结果进行评估和统计分析。从结果来看模型基本符合要求。
3-4加权融合
进行模型预测结果的加权融合,并计算加权融合后的预测结果的MAE。
结果:
![]()
分析:
通过简单的加权融合策略,结合两个不同的模型(LightGBM和XGBoost)的预测结果,来提升预测的准确性和稳定性。从结果来看加权融合使得平均绝对误差(MAE)减少。
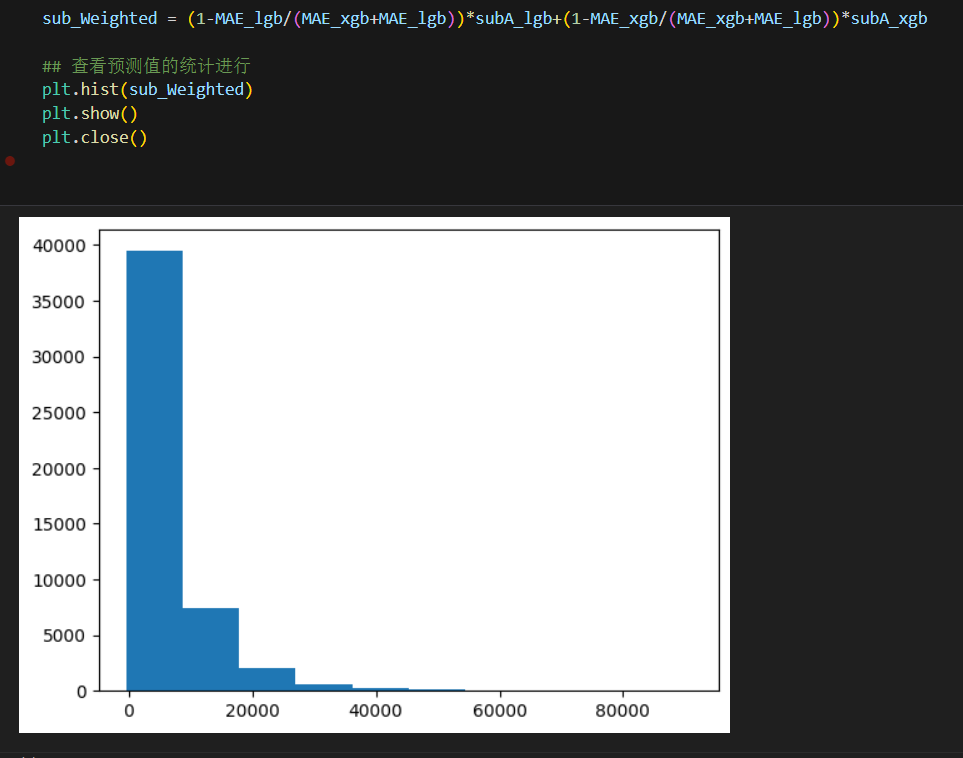
3-5查看预测值的统计结果
针对测试集进行加权融合预测,并且展示预测结果的统计信息
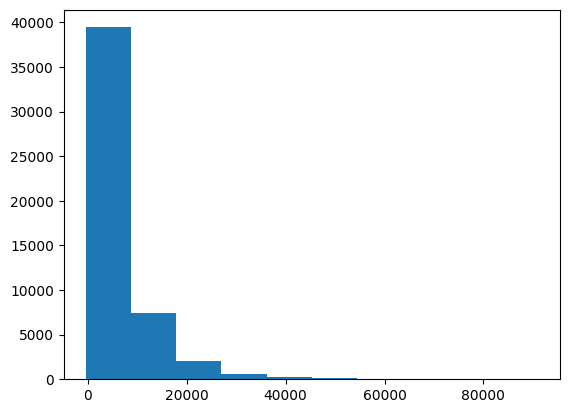
分析:
大部分二手车价格再0-20000之间
四、代码解析
4-1.导入要使用的包和库
1.一些基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import timewarnings.filterwarnings('ignore')
%matplotlib inline- numpy (np):用于数值计算和数组操作。
- pandas (pd):用于数据操作和分析,特别是DataFrame数据结构。
- warnings:用于控制警告信息的显示。
- matplotlib 和 matplotlib.pyplot (plt):用于数据可视化,绘制图表。
- seaborn (sns):基于matplotlib的高级数据可视化库。
- scipy.special.jn:用于计算n阶贝塞尔函数。
- IPython.display:用于在Jupyter Notebook中显示内容。
- time:用于时间相关的功能,比如暂停执行。
2.模型预测工具
from sklearn import linear_model
from sklearn import preprocessing
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor- sklearn.linear_model:线性模型,如线性回归。
- sklearn.preprocessing:数据预处理工具,如标准化、归一化。
- sklearn.svm.SVR:支持向量机回归模型。
- sklearn.ensemble.RandomForestRegressor:随机森林回归模型。
- sklearn.ensemble.GradientBoostingRegressor:梯度提升回归模型。
3.数据降维处理工具
from sklearn.decomposition import PCA, FastICA, FactorAnalysis, SparsePCA- PCA:主成分分析,用于降维。
- FastICA:快速独立成分分析,用于分离信号。
- FactorAnalysis:因子分析,用于降维。
- SparsePCA:稀疏主成分分析,用于降维。
4.LightGBM和XGBoost
import lightgbm as lgb
import xgboost as xgb- LightGBM: LightGBM是一个高效的梯度提升框架,专门用于快速处理大规模数据。它由Microsoft开源,支持分类、回归、排序等任务。LightGBM的主要特点包括高效的并行训练、低内存消耗和处理大规模数据的能力。
- XGBoost: XGBoost(eXtreme Gradient Boosting)是一个优化的梯度提升库,具有高效、灵活和可移植的特点,广泛应用于机器学习竞赛和工业实践中。它能够处理缺失值,支持并行处理和分布式计算,具有强大的性能和高效的内存使用。
5.参数搜索和评价工具
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error- GridSearchCV:网格搜索,用于超参数调优。
- cross_val_score:交叉验证评分。
- StratifiedKFold:分层K折交叉验证。
- train_test_split:将数据集划分为训练集和测试集。
- mean_squared_error:均方误差,用于评价模型。
- mean_absolute_error:平均绝对误差,用于评价模型。
4-2.选择特征列,构造训练和测试样本以及填补缺失值
进行了数据读取、查看、处理和基本统计分析的过程,为后续的机器学习模型训练和预测打下了基础。
1.读取数据
Train_data = pd.read_csv('./数据集/used_car_train_20200313.csv', sep=' ')
TestA_data = pd.read_csv('./数据集/used_car_testB_20200421.csv', sep=' ')读取训练数据和测试数据,并指定分隔符为空格
2.输出数据的大小信息
print('Train data shape:', Train_data.shape)
print('TestA data shape:', TestA_data.shape)输出训练数据和测试数据的行数和列数
3.查看数据
Train_data.head #简要浏览数据 Train_data.info() #查看数据列名及缺失信息
TestA_data.info()Train_data.columns #查看数值特征列的统计信息
查看训练数据的前五行,了解数据的大致结构,查看训练数据的所有列名,查看训练数据和测试数据中数值型特征列的统计信息,如均值、标准差、最小值、最大值等。
4.选择数值和类别特征列
numerical_cols = Train_data.select_dtypes(exclude='object').columns
print(numerical_cols)categorical_cols = Train_data.select_dtypes(include='object').columns
print(categorical_cols)选择训练数据中的数值型列和类别型列。
5.选择特征列
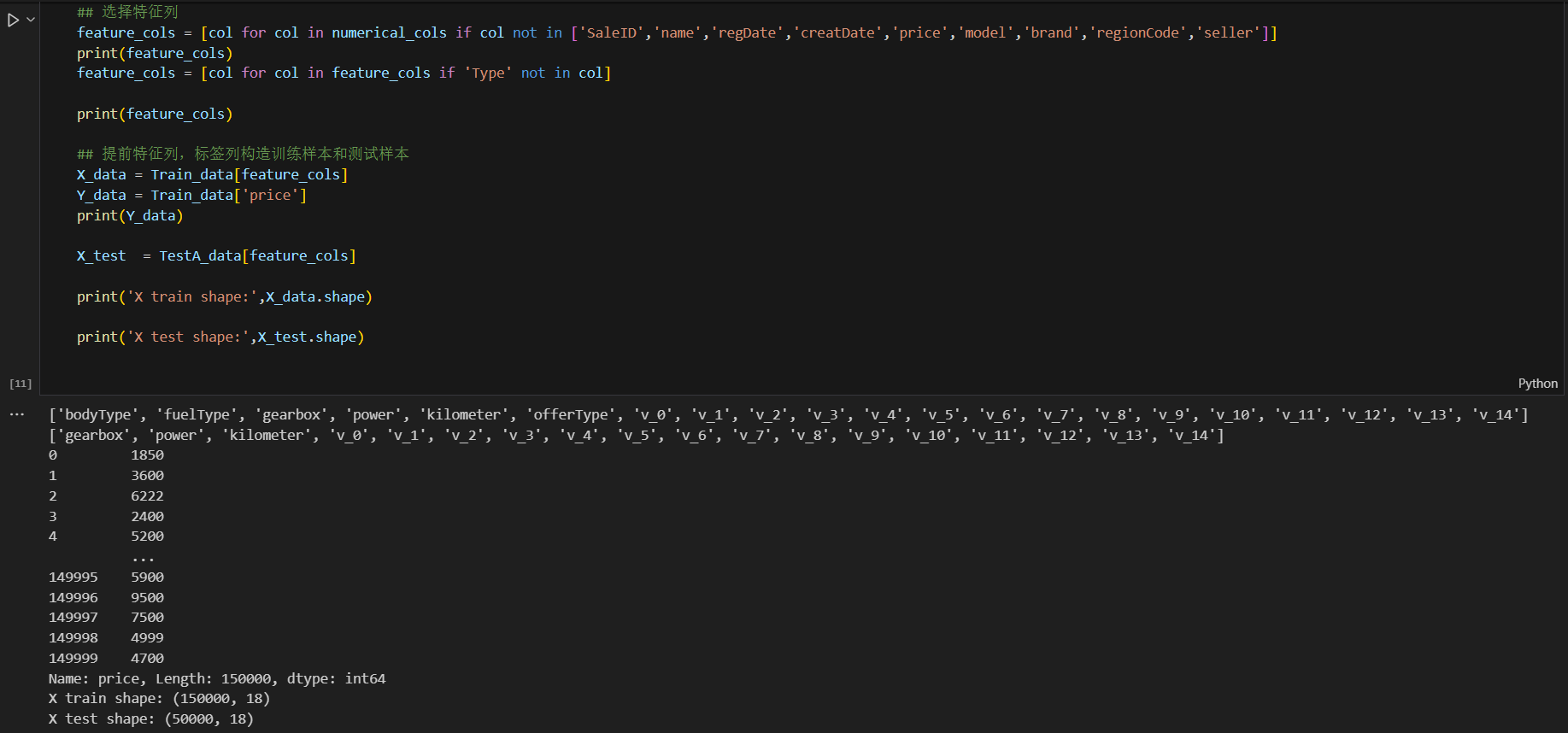
feature_cols = [col for col in numerical_cols if col not in ['SaleID', 'name', 'regDate', 'creatDate', 'price', 'model', 'brand', 'regionCode', 'seller']]
print(feature_cols)
feature_cols = [col for col in feature_cols if 'Type' not in col]
print(feature_cols)
从数值型列中去除不需要的列,并选择最终的特征列。
6.构造训练样本和测试样本
X_data = Train_data[feature_cols]
Y_data = Train_data['price']
print(Y_data)X_test = TestA_data[feature_cols]
print('X train shape:', X_data.shape)
print('X test shape:', X_test.shape)- 从训练数据中提取特征列和目标列(价格price)。
- 从测试数据中提取特征列。
- 输出训练特征数据和测试特征数据的形状
7.填补缺失值
def Sta_inf(data): # 定义统计函数print('_min', np.min(data))print('_max:', np.max(data))print('_mean', np.mean(data))print('_ptp', np.ptp(data))print('_std', np.std(data))print('_var', np.var(data))print('Sta of label:') # 查看标签统计信息
Sta_inf(Y_data)plt.hist(Y_data)# 绘制标签分布图
plt.show()
plt.close()print(X_data.info()) #填补缺失值
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
print(X_data.info())1.定义统计函数:定义一个函数,用于统计数据的基本信息,包括最小值、最大值、均值、极差、标准差和方差。
2.查看标签统计信息 : 使用定义的统计函数查看目标列price的统计信息。
3.绘制标签分布图 :绘制目标列price的直方图,查看其分布情况。
4.填补缺失值 :
- 查看特征数据的信息,包括缺失值情况。
- 将训练特征数据和测试特征数据中的缺失值填补为-1。
- 再次查看特征数据的信息,确认缺失值已填补。
4-3.XGboost
## xgb-Modelxgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'scores_train = []
scores = []## 5折交叉验证方式
sk=StratifiedKFold(n_splits=5,shuffle=True,random_state=0)for train_ind,val_ind in sk.split(X_data,Y_data):train_x=X_data.iloc[train_ind].valuestrain_y=Y_data.iloc[train_ind]val_x=X_data.iloc[val_ind].valuesval_y=Y_data.iloc[val_ind]xgr.fit(train_x,train_y)pred_train_xgb=xgr.predict(train_x)pred_xgb=xgr.predict(val_x)score_train = mean_absolute_error(train_y,pred_train_xgb)scores_train.append(score_train)score = mean_absolute_error(val_y,pred_xgb)scores.append(score)print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
这段代码实现了一个XGBoost回归模型(xgb.XGBRegressor)的交叉验证训练过程,使用了5折Stratified K-Fold交叉验证。
逐步解释:
1.导入必要的库
import xgboost as xgb
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import mean_absolute_error代码开始时导入了必要的库,包括XGBoost用于梯度提升、StratifiedKFold用于交叉验证,以及mean_absolute_error用于评估模型性能。
2.定义XGBoost模型
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0,
subsample=0.8, colsample_bytree=0.9, max_depth=7)在这里,定义了一个XGBoost回归模型,使用了特定的超参数:
1.n_estimators:集成中的提升轮数或决策树数量(本例中有120棵树)。
2.learning_rate:防止过拟合的步长缩减。
3.gamma:需要进一步划分叶子节点的最小损失减小量。
4.subsample:用于拟合决策树的样本比例。
5.colsample_bytree:用于拟合决策树的特征比例。
6.max_depth:每棵树的最大深度。
3.初始化用于存储训练和验证得分的列表:
scores_train = [] # 存储训练集的平均绝对误差
scores = [] # 存储验证集的平均绝对误差创建空列表用于存储训练和验证的平均绝对值误差(MAE)
4. 5折交叉验证
sk=StratifiedKFold(n_splits=5, shuffle=True, random_state=0)使用StratifiedKFold进行5折交叉验证,确保每一折中目标变量的分布与整个数据集一致。
5.交叉验证过程
for train_ind, val_ind in sk.split(X_data, Y_data):train_x = X_data.iloc[train_ind].valuestrain_y = Y_data.iloc[train_ind]val_x = X_data.iloc[val_ind].valuesval_y = Y_data.iloc[val_ind]xgr.fit(train_x, train_y)pred_train_xgb = xgr.predict(train_x)pred_xgb = xgr.predict(val_x)score_train = mean_absolute_error(train_y, pred_train_xgb)scores_train.append(score_train)score = mean_absolute_error(val_y, pred_xgb)scores.append(score)- 对于每一折,将数据分为训练集和验证集。
- 使用训练集训练XGBoost模型。
- 在训练集和验证集上进行预测。
- 计算并存储训练集和验证集的平均绝对误差(MAE)。
6.输出结果
print('Train mae:', np.mean(score_train))
print('Val mae', np.mean(scores))输出训练集和验证集的平均MAE。
7.训练
def build_model_xgb(x_train,y_train):model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'model.fit(x_train, y_train)return modeldef build_model_lgb(x_train,y_train):estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)param_grid = {'learning_rate': [0.01, 0.05, 0.1, 0.2],}gbm = GridSearchCV(estimator, param_grid)gbm.fit(x_train, y_train)return gbm
这段代码定义了两函数 build_model_xgb 和 build_model_lgb,这些函数用于构建和训练基于XGBoost(xgb.XGBRegressor)和LightGBM(lgb.LGBMRegressor)的回归模型,分别返回已训练的模型对象。
一、build_model_xgb(x_train, y_train) 函数:
1.这个函数用于构建和训练基于XGBoost的回归模型。
2.在函数内部,首先创建了一个XGBoost回归模型对象 model,并指定了一些超参数,如树的数量(n_estimators)、学习率(learning_rate)、最大深度(max_depth)等。
3.然后,使用 x_train(特征数据)和 y_train(标签数据)对模型进行训练,通过model.fit(x_train,y_train) 完成。
4.最后,已训练的模型对象 model 被返回。
二、build_model_lgb(x_train, y_train) 函数:
1.这个函数用于构建和训练基于LightGBM的回归模型。
2.在函数内部,首先创建了一个LightGBM回归模型对象 estimator,并指定了一些超参数,如叶子节点数(num_leaves)和树的数量(n_estimators)等。
3.接着,定义了一个参数网格 param_grid,包括学习率(learning_rate)的不同取值,以便进行超参数调优。
4.使用 GridSearchCV 对象 gbm,通过交叉验证来寻找最佳超参数组合。
5.最后,使用 x_train(特征数据)和 y_train(标签数据)对模型进行训练,通过 gbm.fit(x_train, y_train) 完成。
6.已训练的模型对象 gbm 被返回。
这两个函数允许你分别构建和训练XGBoost和LightGBM回归模型,并返回这些模型对象,以便进一步用于预测或评估。这对于比较不同的回归算法或进行超参数调优非常有用。
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)这部分代码用于训练、预测和评估LightGBM回归模型,并输出相关的结果
一、训练LightGBM模型和验证集上的MAE
print('Train lgb...')
model_lgb = build_model_lgb(x_train, y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val, val_lgb)
print('MAE of val with lgb:', MAE_lgb)1.通过 build_model_lgb 函数构建LightGBM模型,使用 x_train 和 y_train 进行训练。
2.使用已训练的模型 model_lgb 对验证集 x_val 进行预测,得到预测结果 val_lgb。
3.计算验证集上的平均绝对误差(MAE),并将其存储在 MAE_lgb 变量中。
4.打印出验证集上使用LightGBM模型的MAE。
二、预测测试数据集:
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data, Y_data)
subA_lgb = model_lgb_pre.predict(X_test)1.再次使用 build_model_lgb 函数构建LightGBM模型,这次使用完整的训练数据集 X_data 和 Y_data 进行训练。
2.使用已训练的模型 model_lgb_pre 对测试数据集 X_test 进行预测,得到预测结果 subA_lgb。
三、输出预测结果的统计信息:
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)打印出 “Sta of Predict lgb:”,然后调用 Sta_inf 函数来展示预测结果 subA_lgb 的统计信息。这部分代码可能是一个自定义的函数,用于显示预测结果的一些统计摘要,例如均值、标准差等。
这段代码主要用于训练和评估LightGBM回归模型,然后使用该模型对测试数据集进行预测,并输出预测结果的统计信息。这可以帮助你了解模型在验证集上的性能以及对测试集的预测结果。
4-4.加权融合(Weighted Ensemble)方法
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of Predict xgb:')
Sta_inf(subA_xgb)## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<0]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))这段代码实现了一个简单的加权融合(Weighted Ensemble)方法,将两个模型的预测结果进行加权组合,并计算最终的验证集平均绝对误差(MAE)。
1.计算加权融合后的验证集预测结果:
val_Weighted = (1 - MAE_lgb / (MAE_xgb + MAE_lgb)) * val_lgb + (1 - MAE_xgb / (MAE_xgb + MAE_lgb)) * val_xgb1.MAE_lgb 是使用LightGBM模型在验证集上计算得到的平均绝对误差。
2.MAE_xgb 是使用XGBoost模型在验证集上计算得到的平均绝对误差。
3.val_lgb 是LightGBM模型在验证集上的预测结果。
4.val_xgb 是XGBoost模型在验证集上的预测结果。
这段代码首先计算了两个模型的MAE之比,然后使用该比例将两个模型的预测结果进行加权平均。具体来说,LightGBM的预测结果被乘以 1 - MAE_lgb / (MAE_xgb + MAE_lgb),而XGBoost的预测结果被乘以 1 - MAE_xgb / (MAE_xgb + MAE_lgb)。这种加权方法将更高性能(MAE更低)的模型分配更高的权重。
2.进行后修正:
val_Weighted[val_Weighted < 0] = 10这部分代码用于进行后修正,将预测结果中小于0的值(负数)设置为10。这是因为在真实情况下,价格(预测值)不应该为负数,所以将小于0的预测值调整为10。
3.计算加权融合后的验证集平均绝对误差:
print('MAE of val with Weighted ensemble:', mean_absolute_error(y_val, val_Weighted))这段代码计算了使用加权融合后的模型 val_Weighted 对验证集的平均绝对误差(MAE)。它衡量了加权融合模型在验证集上的性能。
这个加权融合方法的目的是结合两个模型的优势,根据它们在验证集上的表现,为每个模型分配权重,从而获得更好的综合性能。最后,通过计算融合后模型的MAE来评估性能。
4-5.输出与保存
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb## 查看预测值的统计进行
plt.hist(sub_Weighted)
plt.show()
plt.close()sub = pd.DataFrame()
sub['SaleID'] = TestA_data.SaleID
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv',index=False)
sub.head()使用加权平均方法来结合两个模型(LightGBM和XGBoost)的预测结果,并保存最终的预测结果到CSV文件。
1.加权平均预测结果
使用LightGBM和XGBoost的预测结果进行加权平均,其中权重由各自模型的MAE(平均绝对误差)决定:
- MAE_lgb 是LightGBM模型的MAE。
- MAE_xgb 是XGBoost模型的MAE。
- 权重的计算方式确保误差较小的模型权重更大。
2.查看预测值的统计信息
plt.hist(sub_Weighted)
plt.show()
plt.close()使用直方图查看加权平均后的预测值分布情况。
3.保存最终预测结果
sub = pd.DataFrame()
sub['SaleID'] = TestA_data.SaleID
sub['price'] = sub_Weighted
sub.to_csv('./sub_Weighted.csv', index=False)
sub.head()- 创建一个新的DataFrame sub。
- 将测试数据集中的SaleID列赋值给sub的SaleID列。
- 将加权平均后的预测值赋值给sub的price列。
- 将sub DataFrame保存为CSV文件sub_Weighted.csv,不包含索引。
- 使用head()方法查看sub DataFrame的前五行,确保数据保存正确。
五、总结
5-1项目背景与目的
本次设计旨在通过实践,探索二手车交易价格预测的相关技术和方法。随着二手车市场的迅速扩展,准确预测二手车的交易价格对买卖双方至关重要,能够提高市场的透明度和效率。通过本项目,我们希望学习并实践数据处理、特征工程、机器学习模型的应用与评估等技能,为未来类似问题的解决提供基础与经验。
5-2项目内容与实施过程
1.数据收集与处理:
我们从开放数据源中获取了二手车交易记录的数据集,进行了数据清洗与预处理,包括处理缺失值、异常值等。
2.特征工程:
在数据准备阶段,我们进行了特征选择和提取,选取了对二手车价格预测有影响的数值特征和类别特征,并利用主成分分析(PCA)等方法进行了特征降维处理。
3.模型选择与训练:
我们选择了XGBoost和LightGBM模型。通过K折交叉验证,优化了各模型的性能。
4.模型评估与优化:
我们使用了平均绝对误差(MAE)指标对模型进行了评估,通过调整超参数和模型结构,进一步优化了模型的预测能力。
5.结果融合与输出:
为提高预测准确性,我们采用了模型结果的加权平均方法进行融合,并对融合后的结果进行了修正和调整,确保预测结果的合理性和可靠性。
6.可视化:
最后,我们利用Matplotlib工具对数据分析结果进行可视化展示。
5-3成果与总结
掌握了二手车交易价格预测的基本流程和关键技术,还提升了数据处理、特征工程、机器学习模型选择与优化的实践能力。在项目实施过程中,我们遇到了数据质量问题、模型调优困难等挑战,通过探索与研究,最终取得了令人满意的预测结果。未来,我们将进一步深化对更复杂数据集和模型的应用,不断完善和扩展模型。