沐言智语开源Muyan-TTS模型,词错率、语音质量评分都处于开源模型的一线水平,推理速度相当快~
项目背景

Muyan-TTS 的开发背景源于对现有LLM-based TTS模型的局限性的认识。研究表明,这些模型通常缺乏开源的训练代码和高效的推理加速框架,限制了其可访问性和适应性。此外,播客作为一种高需求的语音交互应用,缺乏专门优化的TTS模型。为此,Muyan-TTS 团队在50,000美元的预算内开发了一个开源、可训练的TTS模型,特别针对播客场景设计。
开发目标
-
提供一个开源的TTS模型,支持社区访问和改进。
-
实现零样本TTS合成,即无需额外训练即可生成高质量语音。
-
支持说话人适应,仅需几十分钟目标语音数据即可微调模型,适合个性化需求。
-
优化播客场景下的语音自然度和表达力。
数据基础
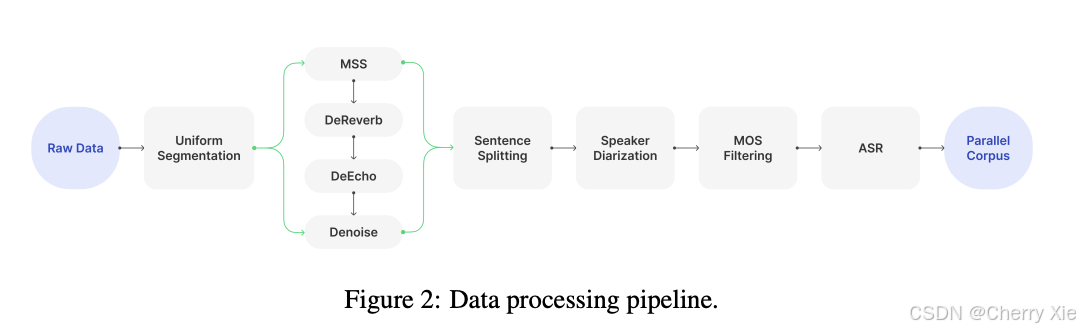
-
团队收集了超过150,000小时的多语言原始音频数据,通过多阶段数据处理流程筛选出超过100,000小时的高质量播客音频。
-
数据清洗包括使用Whisper和FunASR进行自动语音识别(ASR)转录,并通过MOS(Mean Opinion Score)和NISQA(Non-Intrusive Speech Quality Assessment)评分,确保数据质量(MOS > 3.8)。
-
数据处理耗费60,000 GPU小时,使用NVIDIA A10 GPU,成本约为30,000美元。
预算与成本

-
总预算为50,000美元,但实际总成本约为50,540美元,包括数据处理、LLM预训练和解码器训练的费用。
-
训练总计耗费约80,540个GPU小时,展示了在有限资源下开发高性能TTS模型的可能性。
模型结构
Muyan-TTS 的模型结构基于GPT-SoVITS框架,但进行了关键改进,以适应播客场景的需求。
总体框架
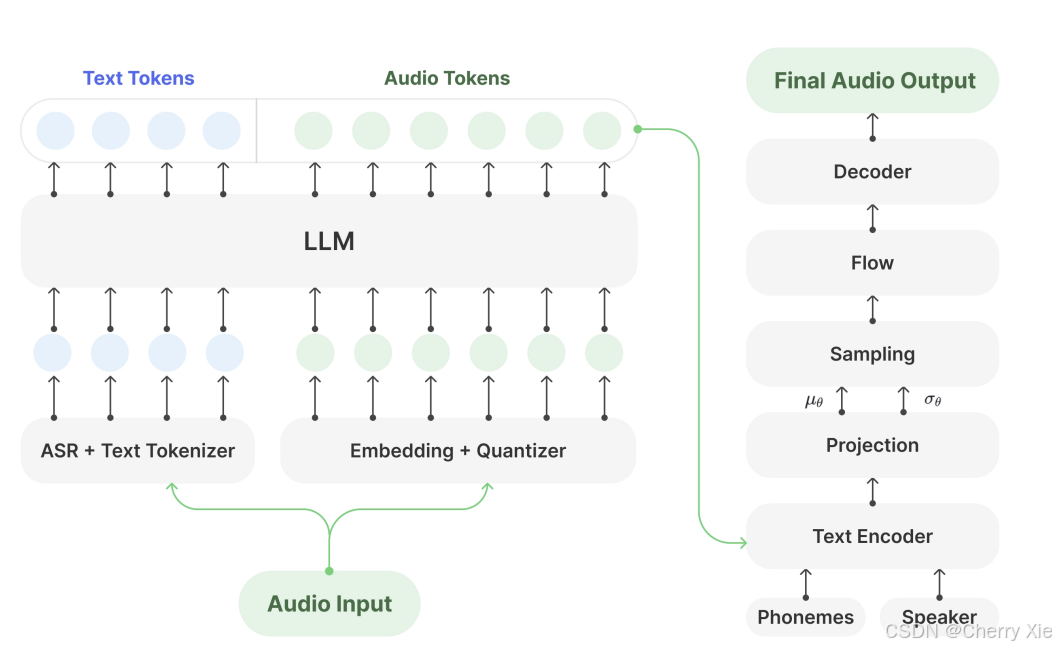
-
Muyan-TTS 整合了大型语言模型(LLM)和语音合成解码器,分为语义建模和音素建模两个部分。
-
LLM组件:使用预训练的Llama-3.2-3B,替换了传统的自回归(AR)模型,负责文本的语义理解和上下文建模。
-
音频令牌化:音频通过GPT-SoVITS的音频令牌化技术量化,文本使用LLM的令牌化器处理,确保文本和音频表示的对齐。
-
解码器:采用基于VITS(Variational Inference for Text-to-Speech)的解码器,而不是流匹配模型。VITS解码器具有图形到音素(G2P)的特性,提供结构化的音素建模,减少幻觉并提高发音准确性。
训练流程
LLM预训练
-
在扩展后的词汇表上对Llama-3.2-3B进行无监督预训练,词汇表包括1024个音频令牌和一个特殊结束令牌。
-
训练持续15个epoch,学习率为1e-4,耗时10天,使用80个NVIDIA A100(80GB,NVLink)GPU,成本约为19,200美元。
LLM监督微调(说话人适应)
-
使用几十分钟到几个小时的单一说话人数据进行监督微调,持续10个epoch,学习率为1e-5。
-
每个小时的语音数据需要15分钟的训练时间,使用8个NVIDIA A100(40G,PCIe)GPU。
解码器训练
-
对SoVITS解码器在10,000小时的高质量播客音频(MOS > 4.5)上进行微调,持续8个epoch,耗时1周。
-
使用8个NVIDIA A100(80GB,NVLink)GPU,成本约为1,340美元。
推理优化
-
Muyan-TTS 使用vLLM(一个高效的LLM推理框架)进行内存管理,实现了快速的语音合成。
-
模型的合成速度比率(r)为0.33,是比较模型中最快的,确保高效的推理性能。
训练成本明细

性能对比

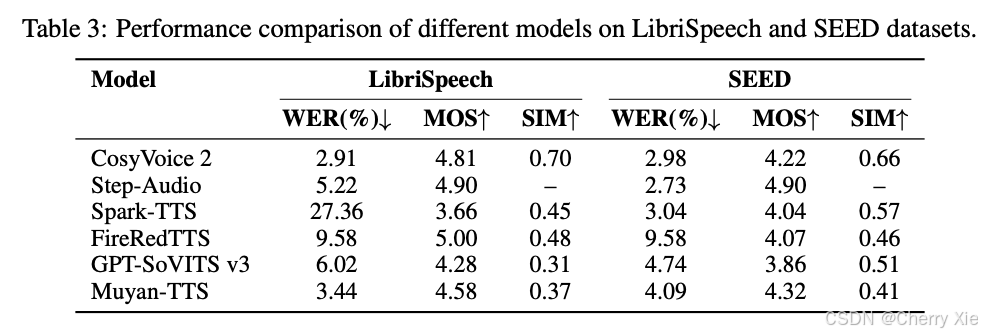
看看效果
相关文献
github地址:https://github.com/MYZY-AI/Muyan-TTS
技术报告:https://arxiv.org/pdf/2504.19146v1
官方地址:https://sankar1535.substack.com/p/muyan-tts-open-source-llm-based-tts
相关效果视频地址:https://www.youtube.com/watch?v=QEztjeZxEfg