从InfluxDB到StarRocks:Grab实现Spark监控平台10倍性能提升

Grab 是东南亚领先的超级应用,业务涵盖外卖配送、出行服务和数字金融,覆盖东南亚八个国家的 800 多个城市,每天为数百万用户提供一站式服务,包括点餐、购物、寄送包裹、打车、在线支付等。
为了优化 Spark 监控性能,Grab 将其 Spark 可观测平台 Iris 的核心存储迁移至 StarRocks,实现了显著的性能提升。新架构统一了原本分散在 Grafana 和 Superset 的实时与历史数据分析,减少了多平台切换的复杂性。得益于 StarRocks 的高性能查询引擎,复杂分析的响应速度提升 10 倍以上,物化视图和动态分区机制有效降低运维成本。此外,直接从 Kafka 摄取数据简化了数据管道架构,使资源使用效率提升 40%。
作者:
Huong Vuong, Senior Software Engineer, Grab
Hai Nam Cao, Data Platform Engineer, Grab
一、Iris——Grab 的 Spark 可观测性平台介绍
(一)Iris 的作用
Iris 是 Grab 开发的定制化 Spark 作业可观测性工具,在作业级别收集和分析指标与元数据,深入洞察 Spark 集群的资源使用、性能和查询模式,提供实时性能指标,解决了传统监控工具仅在 EC2 实例级别提供指标的局限,使用户能按需访问 Spark 性能数据,助力更快决策和更高效的资源管理。
(二)Iris 面临的挑战
随着业务发展,Iris 暴露出一些问题:
-
分散的用户体验与访问控制:可观测性数据分散在 Grafana(实时)和 Superset(历史),用户需切换平台获取完整视角,且 Grafana 对非技术用户不友好,权限控制粒度粗。
-
运营开销:离线分析数据管道复杂,涉及多次跳转和转换。
-
数据管理:管理 InfluxDB 中的实时数据与数据湖中的离线数据存在困难,处理字符串类型元数据时问题尤为突出。
二、系统架构概览
(一)架构调整
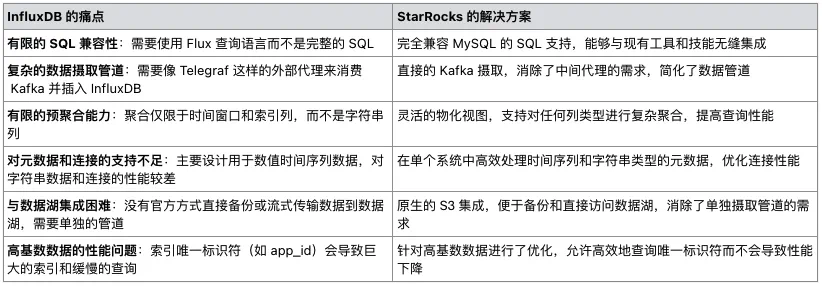
为解决上述问题,Grab 对架构进行重大调整,从 Telegraf/InfluxDB/Grafana(TIG)堆栈转向以 StarRocks 为核心的架构。新架构包括以下关键组件:
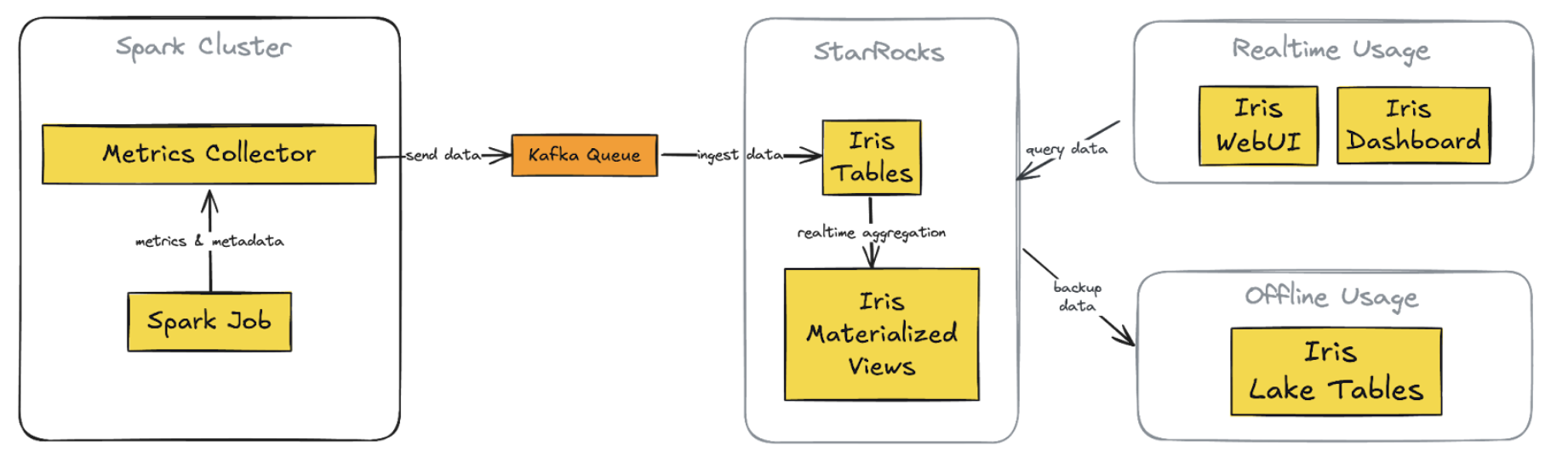
(图1. 集成了 StarRocks 的新 Iris 架构)
-
StarRocks 数据库:替代 InfluxDB,存储实时和历史数据,支持复杂查询。
-
直接 Kafka 摄入:StarRocks 直接从 Kafka 获取数据,摆脱对 Telegraf 的依赖。
-
定制 web 应用(Iris UI):取代 Grafana 仪表板,提供集中、灵活的界面和自定义 API。
-
Superset 集成:继续保留并连接 StarRocks,提供实时数据访问,与自定义 Web 应用保持一致。
-
简化的离线数据处理:StarRocks 直接定期备份到 S3,简化了之前复杂的数据湖管道。
(二)关键改进
新架构带来诸多改进:
-
统一的数据存储:实时和历史数据统一存储,便于管理和查询。
-
简化的数据流:减少数据传输环节,降低延迟和故障点。
-
灵活的可视化:自定义 Web 应用提供符合用户角色需求的直观界面。
-
一致的实时访问:保证自定义应用和 Superset 之间数据一致性。
-
简化的备份和数据湖集成:支持直接备份至 S3,简化数据湖集成流程。
三、数据模型与数据摄取
(一)使用场景
Iris 可观测性系统主要针对 “集群观测” 场景,涵盖临时使用(团队用户共享预创建集群)和作业执行(每次提交作业创建新集群)两种情况。
(二)关键设计要点与表结构
针对每个集群,捕获元数据和指标,主要包含集群元数据、集群 Worker 指标、集群 Spark 指标三类表:
-
集群元数据:记录集群相关的各类元数据信息,如报告日期、平台、Worker UUID、集群 ID、作业 ID 等。
-
集群 Worker 指标:存储 Worker 的 CPU 核心数、内存、堆使用字节数等指标数据。
-
集群 Spark 指标:包含 Spark 应用的各种运行指标,如记录读写数量、字节读写量、任务数量等。
(三)从 Kafka 摄取数据至 StarRocks
利用 StarRocks 的 Routine Load 功能从 Kafka 导入数据,如为集群工作节点指标创建 routine load 作业,持续从指定 Kafka 主题摄取数据并进行 JSON 解析。StarRocks 提供内置工具监控例行加载任务,可通过特定查询查看加载状态。
四、统一系统处理实时与历史数据
新的 Iris 系统采用 StarRocks 高效管理实时和历史数据,并通过以下三个关键特性实现:
1.实时数据摄取
-
利用 StarRocks 的 Routine Load,实现从 Kafka 近乎实时的数据摄取。
-
多个加载任务并行消费不同分区的 topic,使数据在采集后的几秒内即可进入 Iris 表。
-
这一快速摄取能力确保监控信息的时效性,让用户能够随时掌握 Spark 作业的最新状态。
2.历史数据存储与分析
-
StarRocks 作为持久化存储,保存元数据和作业指标,并设置数据存活时间(TTL)超过 30 天。
-
这使我们能够直接在 StarRocks 中分析过去 30 天的作业运行情况,查询速度远超基于数据湖的离线分析。
3.物化视图优化查询性能
-
我们在 StarRocks 中创建了物化视图,用于预计算和聚合每次作业运行的数据。
-
这些视图整合元数据、工作节点指标和 Spark 指标,生成即用型的摘要数据。
-
这样,在 UI 中访问作业运行概览时,无需执行复杂的 Join 操作,提高 SQL 查询和 API 请求的响应速度。
这一架构相比以 InfluxDB 为基础的旧系统有显著提升:
-
作为时序数据库,InfluxDB 不擅长处理复杂查询和 Join 操作,导致查询性能受限。
-
InfluxDB 不支持物化视图,难以创建预计算的作业运行摘要 (job-run summary)。
-
过去,我们需要借助 Spark 和 Presto 在数据湖中查询过去 30 天的作业运行情况,速度远不及直接查询 StarRocks。
五、查询性能与优化
(一)物化视图
-
核心特性:StarRocks 支持同步(SYNC)和异步(ASYNC)物化视图,Grab 主要使用 ASYNC 视图,因其支持多表 Join,对作业运行摘要至关重要。可灵活配置视图刷新方式,如即时刷新或按时间间隔刷新。
-
分区 TTL:通过设置分区存活时间(Partition TTL),通常为 33 天,控制历史数据存储量,保证物化视图高性能,避免过多占用存储空间,同时确保快速访问近期历史数据。
-
选择性分区刷新:允许仅刷新物化视图特定分区,降低维护视图最新状态的计算开销,尤其适用于大型历史数据集。
(二)分区策略
表按日期分区,便于高效裁剪历史数据,查询近期作业或特定时间范围数据时,排除无关分区,减少扫描数据量,加快查询速度。
(三)动态分区策略
利用 StarRocks 的动态分区功能,新数据到达时自动创建分区,数据过期时自动删除旧分区,无需人工干预即可维持最佳查询性能。可通过特定 SQL 命令检查表的分区状态,对于超过 30 天的数据,使用每日定时任务备份至 Amazon S3,之后映射到数据湖表,不影响核心可观测性系统性能。
(四)数据副本机制
StarRocks 采用多节点数据复制策略,该设计在容错能力和查询性能两方面都至关重要。这一策略支持并行查询执行,从而加快数据检索速度。特别是在前端查询场景中,低延迟对用户体验至关重要。这种方法与其他分布式数据库系统(如 Cassandra、DynamoDB 以及 MySQL 的主从架构)中的最佳实践一致。
六、统一的 Web 应用程序
(一)后端
使用 Golang 构建,连接 StarRocks 数据库,查询原始表和物化视图数据,负责身份验证和权限管理,保障用户数据访问权限。
(二)前端
提供多个关键界面,如任务运行列表、任务状态、任务元数据等,任务概览页面展示关键摘要信息,帮助用户快速了解 Spark 任务运行和资源利用情况。
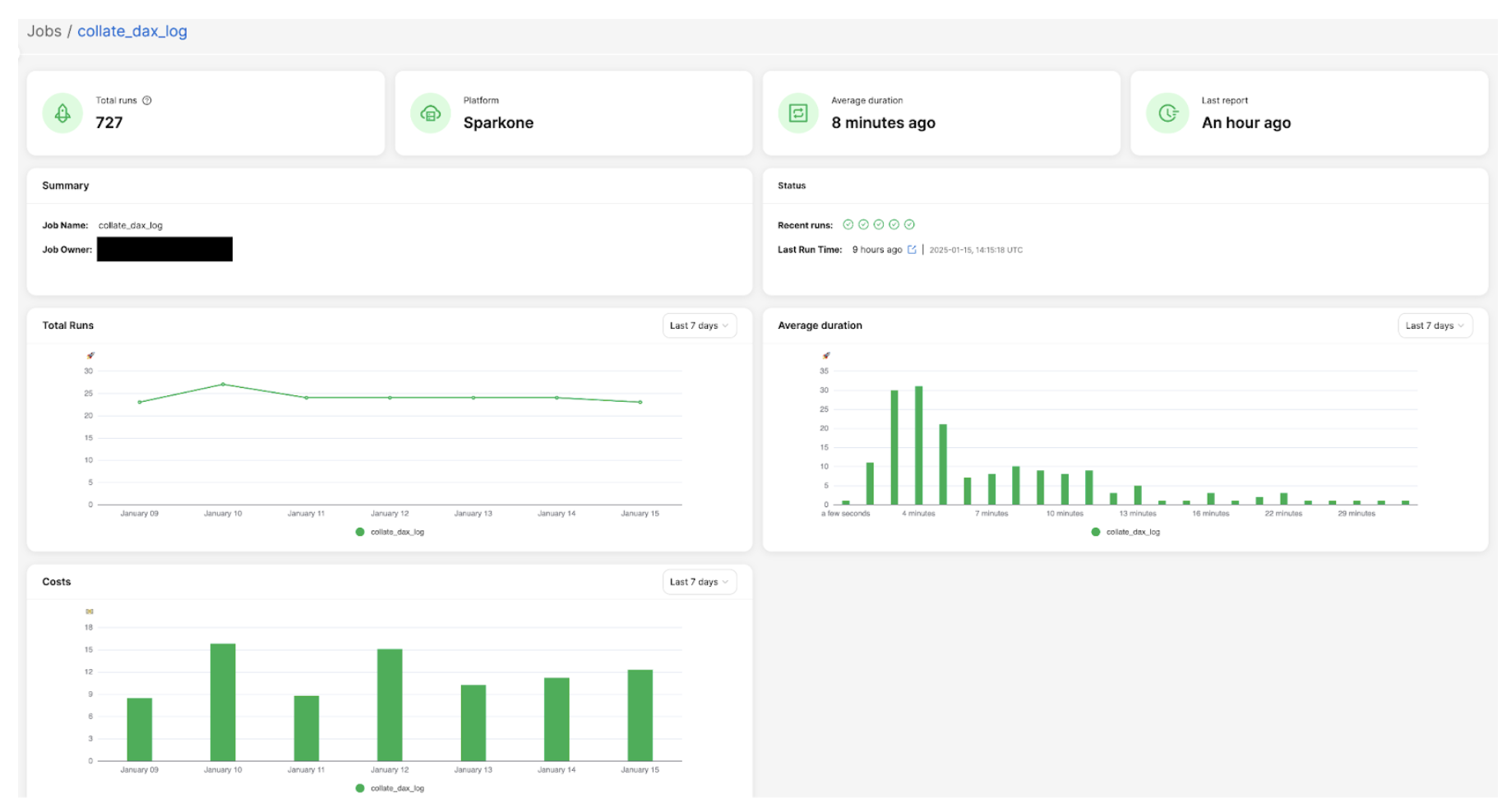
(图2:作业总览界面示例)
七、高级分析与洞察
(一)历史运行分析
创建物化视图聚合过去 30 天任务运行数据,包含运行次数、各类资源使用的 p95 值等指标,为分析任务趋势提供数据支持。以下为示例:
CREATE MATERIALIZED VIEW job_run_summaries_001REFRESH ASYNC EVERY(INTERVAL 1 DAY)ASselect platform,job_id,count(distinct run_id) as count_run,ceil(percentile_approx(total_instances, 0.95)) as p95_total_instances,ceil(percentile_approx(worker_instances, 0.95)) as p95_worker_instances,percentile_approx(job_hour, 0.95) as p95_job_hour,percentile_approx(machine_hour, 0.95) as p95_machine_hour,percentile_approx(cpu_hour, 0.95) as p95_cpu_hour,percentile_approx(worker_gc_hour, 0.95) as p95_worker_gc_hour,ceil(percentile_approx(driver_cpus, 0.95)) as p95_driver_cpus,ceil(percentile_approx(worker_cpus, 0.95)) as p95_worker_cpus,ceil(percentile_approx(driver_memory_gb, 0.95)) as p95_driver_memory_gb,ceil(percentile_approx(worker_memory_gb, 0.95)) as p95_worker_memory_gb,percentile_approx(driver_cpu_utilization, 0.95) as p95_driver_cpu_utilization,percentile_approx(worker_cpu_utilization, 0.95) as p95_worker_cpu_utilization,percentile_approx(driver_memory_utilization, 0.95) as p95_driver_memory_utilization,percentile_approx(worker_memory_utilization, 0.95) as p95_worker_memory_utilization,percentile_approx(total_gb_read, 0.95) as p95_gb_read,percentile_approx(total_gb_written, 0.95) as p95_gb_written,percentile_approx(total_memory_gb_spilled, 0.95) as p95_memory_gb_spilled,percentile_approx(disk_spilled_rate, 0.95) as p95_disk_spilled_ratefrom iris.job_runswhere report_date >= current_date - interval 30 daygroup by platform, job_id;(二)推荐 API
基于趋势分析结果构建推荐 API,提供优化建议,如调整资源分配、识别潜在瓶颈或修改调度策略,以优化成本和性能。
(三)前端集成
我们的 API 生成的推荐结果已集成到 Iris 前端。用户可以在任务概览或详情页面直接查看这些建议,从而获得可执行的优化指导,提升 Spark 任务的效率。
以下是一个示例:如果某个任务的资源利用率长期低于 25%,系统会建议将工作节点的规模缩小一半,以降低成本。
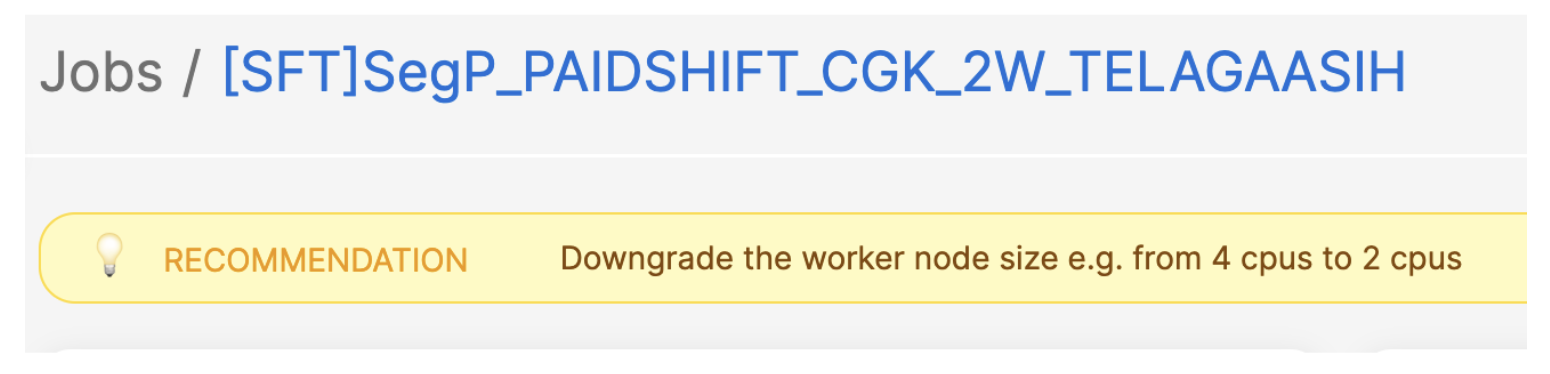
(图3:资源利用率较低的作业示例)
(四)Slackbot 集成
为了让这些洞察更加便捷可用,我们将推荐系统集成到了 SpellVault(Grab 的生成式 AI 平台)应用中。这样,用户可以直接在 Slack 上与推荐系统交互,无需频繁访问 Iris Web 界面,也能随时获取任务性能信息和优化建议。
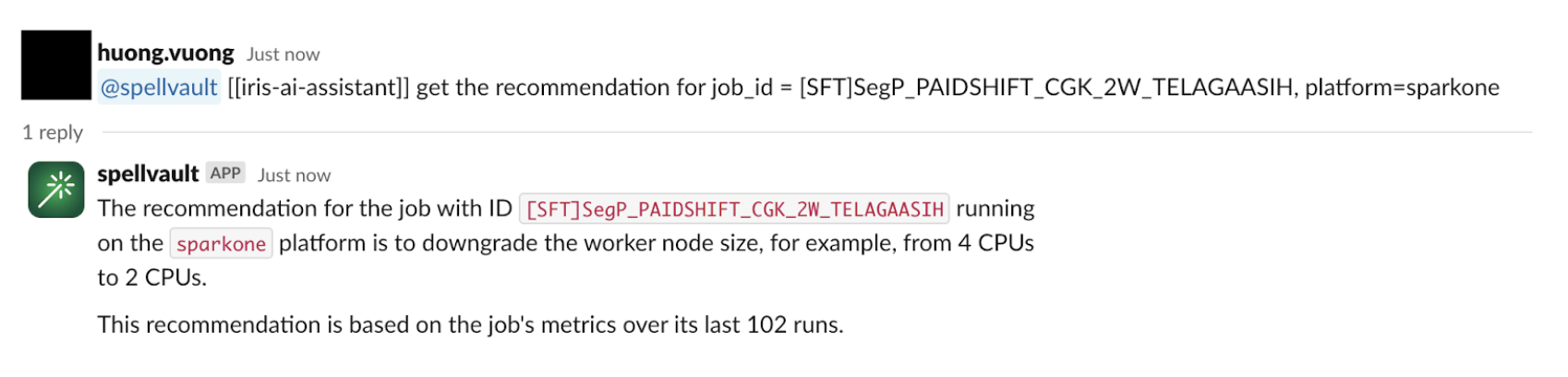
(图 4. SpellVault 集成示例)
八、迁移与推广
(一)迁移策略
-
将实时 CPU/内存监控图表从 Grafana 完全迁移到新的 Iris UI。
-
迁移完成后,将弃用 Grafana 仪表盘。
-
继续保留 Superset 以支持平台指标和特定的 BI 需求。
(二)用户引导与反馈
-
Iris 已部署在 One DE 应用中,集中化管理数据工程工具的访问。
-
UI 中的反馈按钮使用户可以轻松提交意见和建议。
九、经验总结与未来规划
以 StarRocks 为核心开发的 Iris Web 应用,为 Grab 的 Spark 观测能力带来革命性提升,实现作业级别的成本分摊机制。未来,Grab 期待在高级分析和机器学习驱动的洞察方面取得突破,推动数据工程发展。
(一)经验总结
-
统一数据存储:使用 StarRocks 作为实时和历史数据的单一数据源,显著提升了查询性能并优化了系统架构。
-
物化视图:利用 StarRocks 的物化视图进行预聚合,大幅加快了 UI 端的查询响应速度。
-
动态分区:实施动态分区机制,随着数据量增长自动管理数据保留,保持最佳性能。
-
直接 Kafka 摄取:StarRocks 直接从 Kafka 获取数据,简化了数据管道,降低了延迟和复杂性。
-
灵活的数据模型:相比之前基于时间序列的 InfluxDB,StarRocks 的关系型数据模型支持更复杂的查询,同时简化了元数据管理。
(二)未来规划
-
增强推荐系统:扩展推荐功能,提供更深入的优化建议,例如识别潜在瓶颈,并推荐 Spark 任务的最佳配置,以提升运行效率并降低成本。
-
高级分析:利用完整的 Spark 任务指标数据,深入分析任务性能和资源使用情况。
-
集成扩展:加强 Iris 与其他内部工具和平台的集成,提高用户采用率,确保数据工程生态系统的无缝体验。
-
机器学习集成:探索将机器学习模型应用于 Spark 任务的预测性分析,以优化性能。
-
可扩展性优化:持续优化系统,以支持不断增长的数据量和用户负载。
-
用户体验提升:基于用户反馈持续改进 Iris UI/UX,使其更加直观和信息丰富。
为提升可读性,本文对技术细节进行了精简,如需查看完整 SQL 示例及实现细节,请参阅原文:https://engineering.grab.com/building-a-spark-observability