Linux系统:虚拟文件系统与文件缓冲区(语言级内核级)
本节重点
- 初步理解一切皆文件
- 理解文件缓冲区的分类
- 用户级文件缓冲区与内核级文件缓冲区
- 用户级文件缓冲区的刷新机制
- 两级缓冲区的分层协作
一、虚拟文件系统
1.1 理解“一切皆文件”
我们都知道操作系统访问不同的外部设备(显示器、磁盘、键盘、鼠标、网卡)时都会通过相应的驱动程序,由于各种外设之间的差异在驱动程序中对每个外设的输入输出(如获取设备状态、属性)的相关方法的实现都不尽相同:
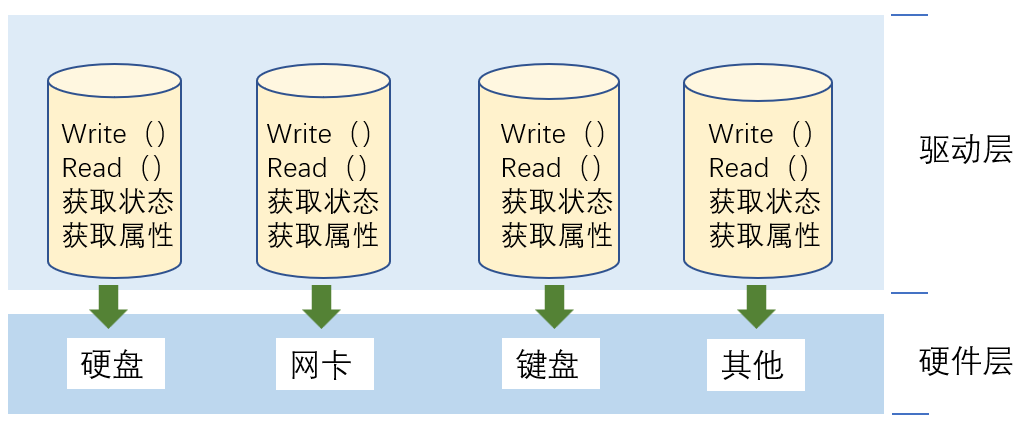
我们说操作系统是对软硬件资源进行管理的软件,在内核中要对硬件资源进行管理首先需要让操作系统看到硬件资源,也就是将硬件资源“先描述再组织”:
在操作系统内核中通过类似struct device的结构体来对每种外设进行描述,再通过链表的方式将硬件资源管理起来,此时这个数据结构就表示操作系统启动时默认看到的和打开的外设资源:
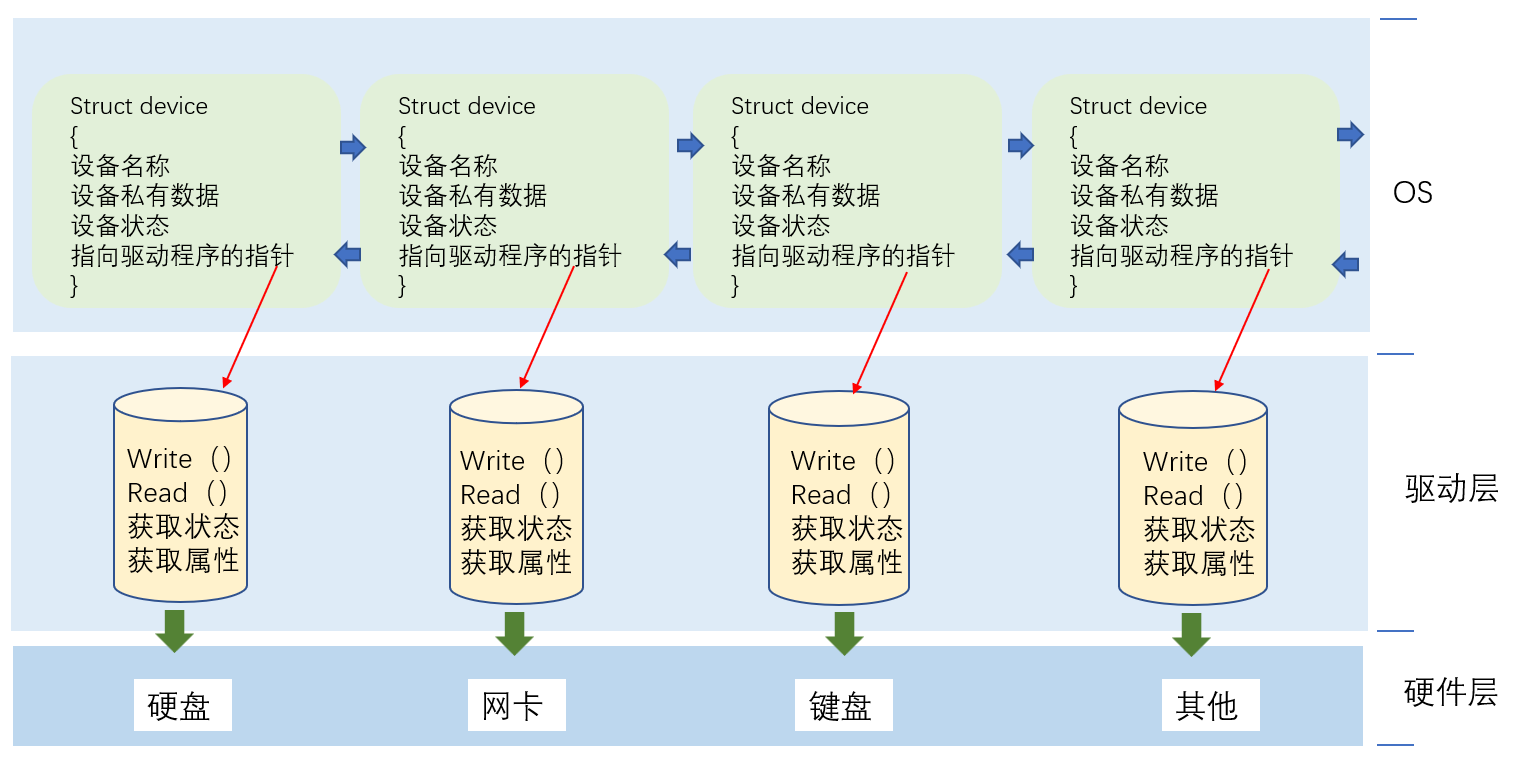 当用户运行自己的代码与数据时,操作系统就会在内核空间创建进程PCB,其中PCB中的struct files struct指针指向的文件描述符表则记录了该进程打开的文件的数量。而我们知道文件描述符表本质上是元素为struct file的一维数组,struct file中则详细记录了被打开文件的文件缓冲区和元数据,关键的是其中还记录了指向文件操作的各种方法的指针(函数指针),这样对文件的操作会通过函数指针跳转到不同的对应外设的驱动层。
当用户运行自己的代码与数据时,操作系统就会在内核空间创建进程PCB,其中PCB中的struct files struct指针指向的文件描述符表则记录了该进程打开的文件的数量。而我们知道文件描述符表本质上是元素为struct file的一维数组,struct file中则详细记录了被打开文件的文件缓冲区和元数据,关键的是其中还记录了指向文件操作的各种方法的指针(函数指针),这样对文件的操作会通过函数指针跳转到不同的对应外设的驱动层。
这样即使外设之间存在差异,驱动程序的设计大相径庭用户访问涉及到不同类型外设的文件时也能获得相似的方法,以为在内核通过函数指针已经帮用户完成了差异化的方法调用。

二、文件缓冲区
2.1 什么是缓冲区
缓冲区是内存空间的一部分,用来暂时存储输入或者输出的数据内容,这部分预留的空间就叫做缓冲区。缓冲区根据其对接的是输入设备还是输出设备分为输入缓冲区与输出缓冲区。
2.2 为什么引入缓冲区
关键1:语言级文件操作都会调用系统调用
在介绍操作系统时我们了解到:操作系统为了不直接暴露内核,为上层用户提供了各类系统调用。在语言层面对文件操作的各类函数接口底层都封装了系统调用。
例如,以C语言为例fopen,fread,fwrite底层都分别封装了open,read,write系统调用。
所以本质上我们使用各类编程语言进行文件操作(如I/O操作)都会调用系统调用。
关键2:系统调用是有代价的
在之后的学习中我们会了解到,当程序执行系统调用时,CPU会从用户态切换到内核态这个过程涉及到保护用户程序的寄存器状态,切换页表,加载内核代码段等操作。当系统调用完成时,CPU会从内核态返回到用户态,此时CPU需要恢复用户程序的寄存器状态,整个操作会涉及到数百到数千个CPU周期。
关键3:缓冲区的引入可以减少系统调用次数
以向文件中写入数据为例,当我们引入缓冲区的概念后,对文件的输入操作意味着我们可以逐渐将数据块输入到缓冲区中,然后通过适当的缓冲机制调用系统调用将数据块整体写入到文件中,大大减少了系统调用的次数,大大提高了输入效率。
2.3 缓冲区的分类
2.3.1 用户级(C语言为例)
C标准库中的I/O函数(printf、fwrite、fgets)均围绕流的概念设计。每个流(stdout、stderr、stdin、用户自定义的文件流)都由一个FILE结构体来表示,该结构体包含一个缓冲区以及缓冲策略(行缓冲、全缓冲、无缓冲)。
在C标准库中对结构体FILE的描述如下:
//FILE本质上是定义的一个宏在/usr/include/stdio.h中typedef struct _IO_FILE FILE;//在/usr/include/libio.h
struct _IO_FILE
{
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. *//* The following fields are used to support backing up and undo. */char *_IO_save_base; /* Pointer to start of non-current get area. */char *_IO_backup_base; /* Pointer to first valid character of backup area */char *_IO_save_end; /* Pointer to end of non-current get area. */struct _IO_marker *_markers;struct _IO_FILE *_chain;int _fileno; //封装的⽂件描述符#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};缓冲机制
在C标准库(stdio.h)总共定义了三个缓冲机制,每个流(FILE结构体)在其生命周期中通常只配置一个缓冲机制。以下是对三个缓冲机制的介绍:

注意事项:
除了以上默认的刷新方式下列特殊清空也会引发缓冲区的刷新:
- 缓冲区被写满
- 显式刷新(如调用flush)
当缓冲区为行缓冲但是始终没有遇到换行符(\n)时,当缓冲区满时会自动提交。
当涉及磁盘文件操作时默认为全缓冲,当所操作的流涉及一个终端(显示器)时默认为行缓冲,stderr默认不带缓冲区即无缓冲。
这里举一个代码示例:
//code.c
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{const char* s1="hello printf\n";const char* s2="hello fwrite\n";printf("%s",s1);fwrite(s2,1,strlen(s2),stdout);fork();return 0;
}
运行结果:
 首先printf与fwrite将字符串写入stdout对应的缓冲区中,当涉及到对终端(显示器)的操作时为行缓冲,所以字符串会依次刷新提交。
首先printf与fwrite将字符串写入stdout对应的缓冲区中,当涉及到对终端(显示器)的操作时为行缓冲,所以字符串会依次刷新提交。
此时我们执行以下指令:将程序重定向到一个文本文件(text.txt)中
./code 1> text.txt运行结果:

此时我们发现同一份代码数据被打印了两次,原因是当我们进行重定向操作后就成为了用户对磁盘文件(text.txt)的文件操作,默认缓冲机制变成了全缓冲。
当我们创建子进程之前,父进程的两个数据(hello printf / hello fwrite)还在缓冲区中并没有被刷新提交,而我们知道子进程是父进程的副本,当创建子进程时缓冲区中的数据也一并拷贝给了子进程,当程序结束后会自动刷新text.txt文件流的缓冲区,导致数据被打印了两次。
2.3.2 内核级
在Linux系统中,内核级缓冲区是用于在内核空间和用户空间之间传递数据的关键机制。它通常用于提高I/O操作的效率,减少系统调用的次数,并优化数据的传输。
内核级缓冲区的类型:
1> 页缓存
用于缓存文件数据,减少磁盘I/O操作。当文件被读取时,数据会被缓存在页缓存中,后续的读取操作可以直接从缓存中获取数据,而不需要再次访问磁盘。
2> 块设备缓冲区
用于缓存块设备的数据,如硬盘的块数据。它与页缓存类似,但更专注于块设备的I/O操作。
3> 套接字缓冲区
用于网络通信,管理网络数据包的传输。每个网络数据包都会被封装在sk_buff结构中,以便在内核中进行处理。
与用户级缓冲区类似,内核级缓冲区也有刷新机制但是在实现方面会复杂很多。以为在内核层面操作系统要考虑的因素会更多,比如刷新操作可能涉及大量的内存操作,不当的刷新策略可能导致系统资源耗尽或内存泄漏,还有在多核或多线程环境下,内核级缓冲区的刷新机制需要处理并发访问问题。这通常需要引入复杂的同步机制,如自旋锁或读写锁,以确保数据的一致性和完整性等等
以下是内核级缓冲区的刷新机制,可以来了解一下:
- 定期刷新:内核会定期将缓冲区中的数据写入存储设备。这种刷新通常由内核的守护进程负责,确保数据在一定时间间隔内被写入磁盘。
- 显式刷新:应用程序可以通过系统调用(如
fsync或fdatasync)显式请求将缓冲区中的数据刷新到存储设备。 - 缓冲区满时刷新:当内核缓冲区达到一定容量时,内核会自动将数据刷新到存储设备。
- 文件关闭时刷新:当应用程序关闭文件时,内核会自动将与该文件相关的缓冲区数据刷新到存储设备。
- 内存压力:当系统内存不足时,内核可能会主动刷新缓冲区以释放内存。这种机制确保系统在高内存压力下仍能正常运行。
2.3 两级缓冲区的联系
关键词:分层协作
当应户程序通过用户级缓冲区写入数据时,数据首先存储在用户空间的缓冲区中。当缓冲区满或显式调用刷新函数时,数据会被复制到内核级缓冲区。内核级缓冲区进一步管理数据的物理写入操作,确保数据最终被写入磁盘或发送到网络设备。
我们可以通过下图来理解:
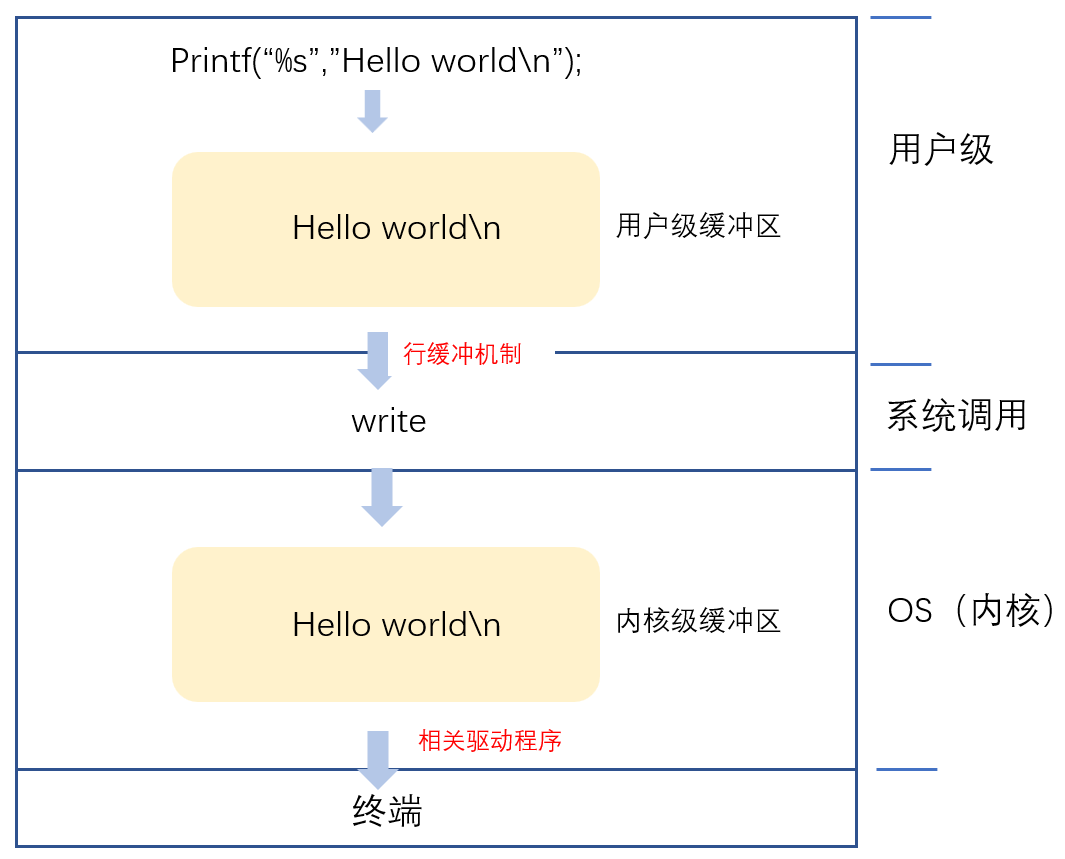
这种分层缓冲机制减少了频繁的系统调用,提高了数据处理的效率。同时,内核级缓冲区还可以利用更高级的优化技术,如延迟写入和批量处理,进一步提升系统性能。