DeepSeek 引领AI新潮流:Janus-Pro 打破多模态理解与生成的边界
Janus-Pro:全面提升的多模态大模型
随着人工智能技术的快速发展,越来越多的多模态模型开始涌现,尤其是在视觉和语言的结合上。DeepSeek 的 Janus-Pro 就是其中的佼佼者,作为 Janus 的进阶版本,Janus-Pro 在模型架构、训练策略、数据集扩展和模型规模等方面做出了重要改进,使其在多模态理解和文本到图像生成的任务中表现更加优异。
Janus-Pro的核心技术创新
1. 视觉编码的解耦:多模态任务的灵活处理
Janus-Pro 在架构设计上进行了创新性的改进,特别是在视觉编码的处理方式上。传统的多模态模型通常使用相同的视觉编码器处理理解和生成任务,这可能导致两者之间的冲突,因为这两类任务所需的表示方式有所不同。为了解决这一问题,Janus-Pro 采用了 视觉编码解耦 的设计。
-
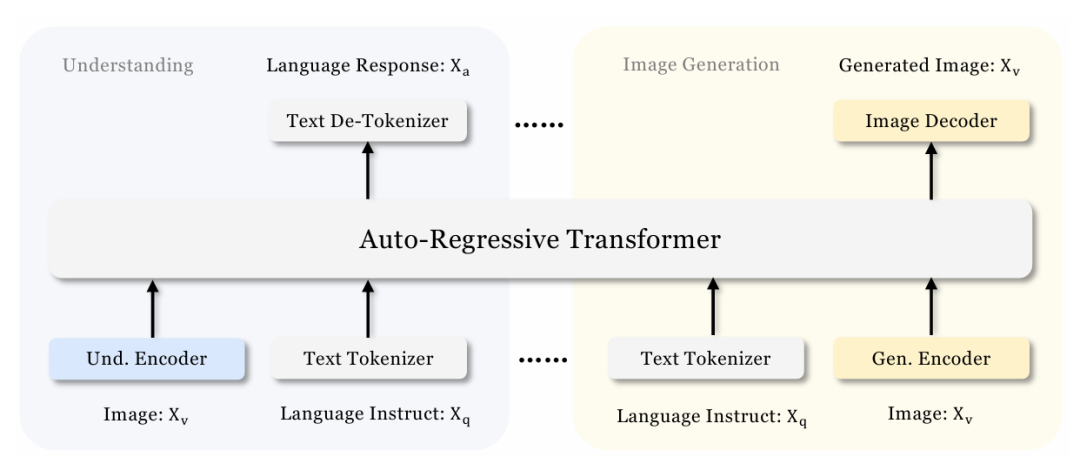
多模态理解任务 使用 SigLIP 编码器 提取高维的语义特征,能够准确捕捉图像中的物体、属性以及关系信息。这些特征随后会通过理解适配器映射到文本特征空间,供大语言模型(LLM)进行进一步处理。
-
视觉生成任务 则使用 VQ分词器 将图像转换为离散的 ID,然后通过生成适配器将这些 ID 映射到文本特征空间。最终,这些处理后的特征被统一输入到 LLM 中进行图像生成。
这种解耦策略极大提升了 Janus-Pro 处理多模态任务的灵活性和性能,使得视觉理解和生成任务能够独立优化,从而避免了传统方法中的冲突。
2. 优化的训练策略:高效学习与性能提升
Janus-Pro 在训练策略上做了多项优化,特别是针对原有模型中训练效率低下和计算冗余的问题。具体而言,Janus-Pro 主要通过以下两个方面的改进,显著提升了训练效率和模型性能:
-
第一阶段训练延长: Janus-Pro 延长了第一阶段的训练时间,尤其是在 ImageNet 数据集上的训练。这使得模型能够更好地学习像素级依赖关系,在图像类别生成任务中表现更加稳健。
-
第二阶段聚焦训练: 在第二阶段,Janus-Pro 放弃了 ImageNet 数据,直接利用常规文本到图像的数据进行训练。这一策略能够使模型更有效地学习复杂的文本描述和图像之间的关系,从而提升文本到图像生成能力。
-
数据比例调整: 在第三阶段的监督微调中,Janus-Pro 调整了多模态数据、纯文本数据和文本到图像数据的比例,从原来的 7:3:10 改为 5:1:4。这一调整平衡了多模态理解与图像生成的训练,进一步提高了多模态理解性能。
3. 数据扩展:丰富的多模态训练数据
Janus-Pro 在数据集的扩展上也做出了大胆的创新,特别是在 多模态理解 和 视觉生成 两个方面。通过引入更多、更高质量的数据,Janus-Pro 在多个任务中表现出色。
-
多模态理解数据的扩展: Janus-Pro 引入了约 9000 万 个样本,包括 YFCC 图像字幕数据集、表格和图表理解数据(如 Docmatix)以及 MEME 理解数据 和 中文对话数据。这些数据的加入极大地丰富了模型的多模态理解能力,使其能够更好地处理各种类型的输入,提升了对话和视觉理解的精确度。
-
视觉生成数据的扩展: Janus-Pro 还引入了约 7200 万 个合成美学数据样本,以改进文本到图像生成的稳定性和美学质量。通过将真实数据与合成数据的比例设定为 1:1,Janus-Pro 在训练过程中能够快速收敛,同时生成更加精美且稳定的图像。
4. 模型规模扩展:强大的性能提升
Janus-Pro 在模型规模上也做出了显著的突破。从 1.5B 参数扩展到 7B 参数,Janus-Pro 的规模扩展使得模型在处理更大规模的任务时,能够获得更好的性能。
-
更大规模的 LLM:随着参数规模的提升,Janus-Pro 在多模态理解和视觉生成任务中的表现也得到了显著提高。尤其是在处理复杂任务和生成高质量图像时,7B 参数的模型能够更快地收敛,并且能够捕捉到更复杂的语义信息和细节。
-
提升收敛速度:通过增加模型的规模,Janus-Pro 的收敛速度得到了显著提升,使得训练效率和生成能力得到了进一步增强。
5. 精细的图像生成:细节更丰富
Janus-Pro 在 文本到图像生成 任务中取得了令人瞩目的成绩,尤其是在图像的细节表现方面。尽管 Janus-Pro 的生成分辨率为 384x384,它仍然能够生成高质量且细节丰富的图像。通过优化的训练策略和高质量的训练数据,Janus-Pro 能够在生成过程中捕捉到更多细节和语义信息。

6. 解决短提示问题:更稳定的图像生成
相比于前作 Janus,Janus-Pro 在生成短提示图像时表现更加稳定,图像质量明显提升。通过改进的模型架构和训练方法,Janus-Pro 能够处理更多种类的文本提示并生成细节丰富、语义一致的图像。
Janus-Pro的性能评估
Janus-Pro 在多个标准的基准测试中展现出了卓越的性能。以下是对该模型在 多模态理解 和 文本到图像生成 任务中的详细性能评估,展示了其相对于前作 Janus 和其他最先进模型的优势。
1. 多模态理解性能评估
为了评估 Janus-Pro 在多模态理解任务中的表现,模型在多个广泛认可的视觉语言基准测试中进行了评估,包括 POPE、MME、GQA 和 MMMU 等。
-
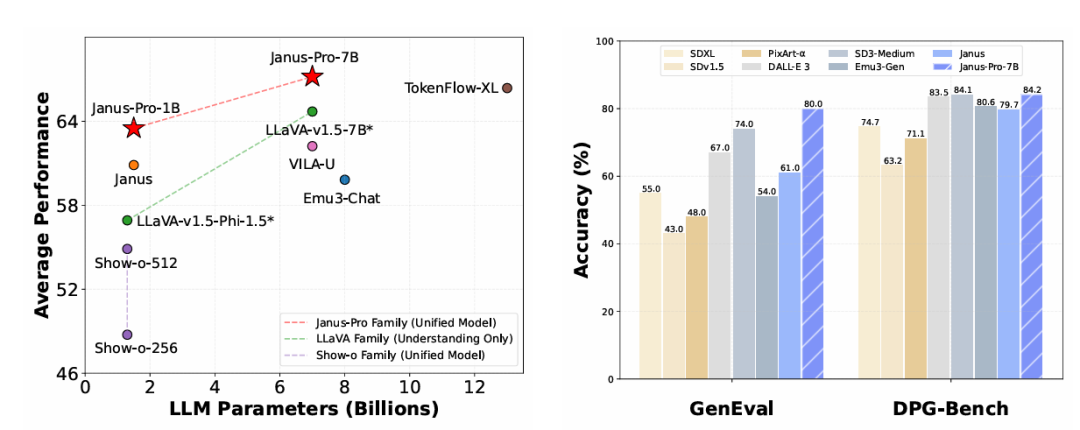
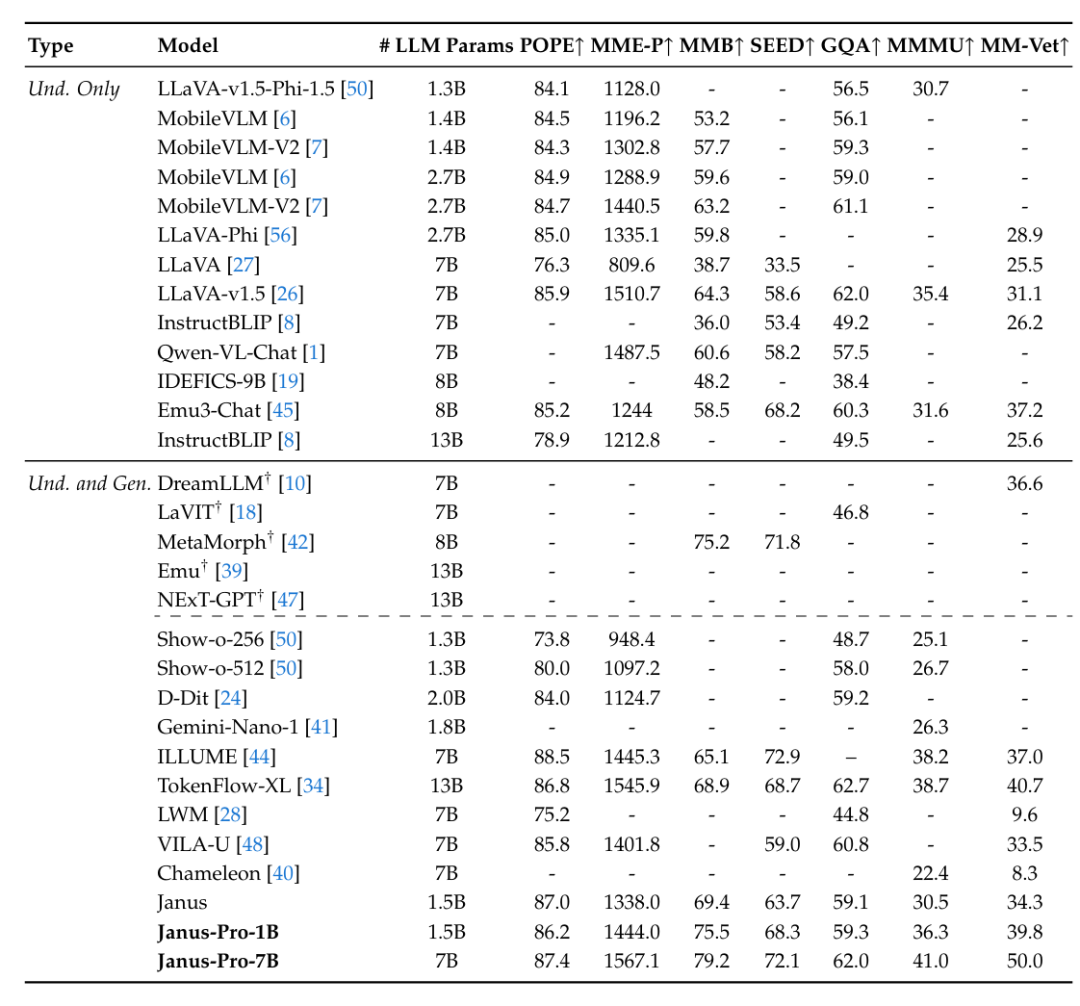
Janus-Pro-7B 在多模态理解任务中的表现超越了多种先进的模型。例如,在 MMBench 基准测试中,Janus-Pro-7B 达到了 79.2 分,显著超过了 Janus(69.4分)、TokenFlow(68.9分)和 MetaMorph(75.2分)等其他统一多模态模型。通过视觉编码解耦,Janus-Pro 避免了理解和生成任务间的冲突,进一步提升了理解能力。
2. 文本到图像生成性能评估
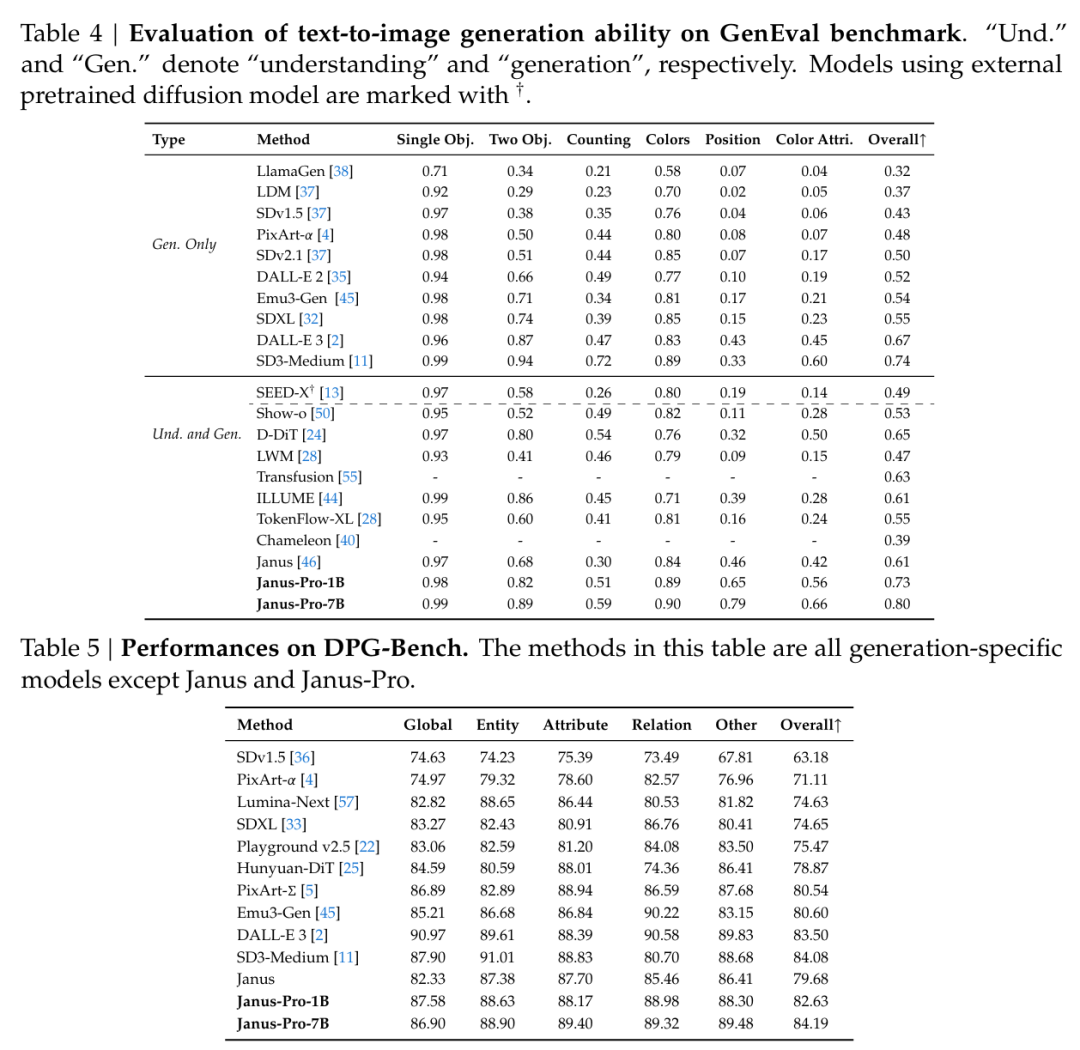
Janus-Pro 在文本到图像生成任务中也展示了强大的能力,尤其在 GenEval 和 DPG-Bench 等基准测试中,表现出色。
-
在 GenEval 基准测试中,Janus-Pro-7B 以 80% 的总体准确率领先于所有其他模型,包括 DALL-E 3(67%)、SD3-Medium(74%)和 Transfusion(63%)。这些结果显示,Janus-Pro 在指令遵循能力和生成图像的准确性方面具有显著优势。
模型下载
OpenCSG社区:
https://opencsg.com/models/deepseek-ai/Janus-Pro-7B