DataWorks快速入门
文章目录
- 一、DataWorks简介
- 1、概念
- 2、功能
- 3、优势
- 二、DataWorks使用
- 1、创建工作空间
- 2、绑定计算资源
- 3、数据开发
- 三、DataWorks节点类型
- 1、MaxCompute SQL节点
- ①创建非分区表并插入数据
- ②创建分区表并插入数据
- ③查询表数据
- 2、离线同步节点
- 3、PYODPS 3节点
- ①判断表是否存在
- ②执行SQL语句
- ③添加运行参数
- ④输出SQL执行结果
- 4、MaxCompute Script节点
- ①适用场景
- ②简单示例
- 5、其他节点
一、DataWorks简介
1、概念
DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
2、功能
- 数据集成:全领域数据汇聚
- 数据开发与运维中心:数据加工
- 数据建模:智能数据建模
- 数据分析:即时快速分析
- 数据质量:全流程的质量监控
- 数据地图:统一管理,跟踪血缘
- 数据服务:低成本快速发布API
- 开放平台:能力全面开放
- 迁移助手与迁云服务
3、优势
全方位安全管控
成本低
功能齐全
运维方便
二、DataWorks使用
1、创建工作空间
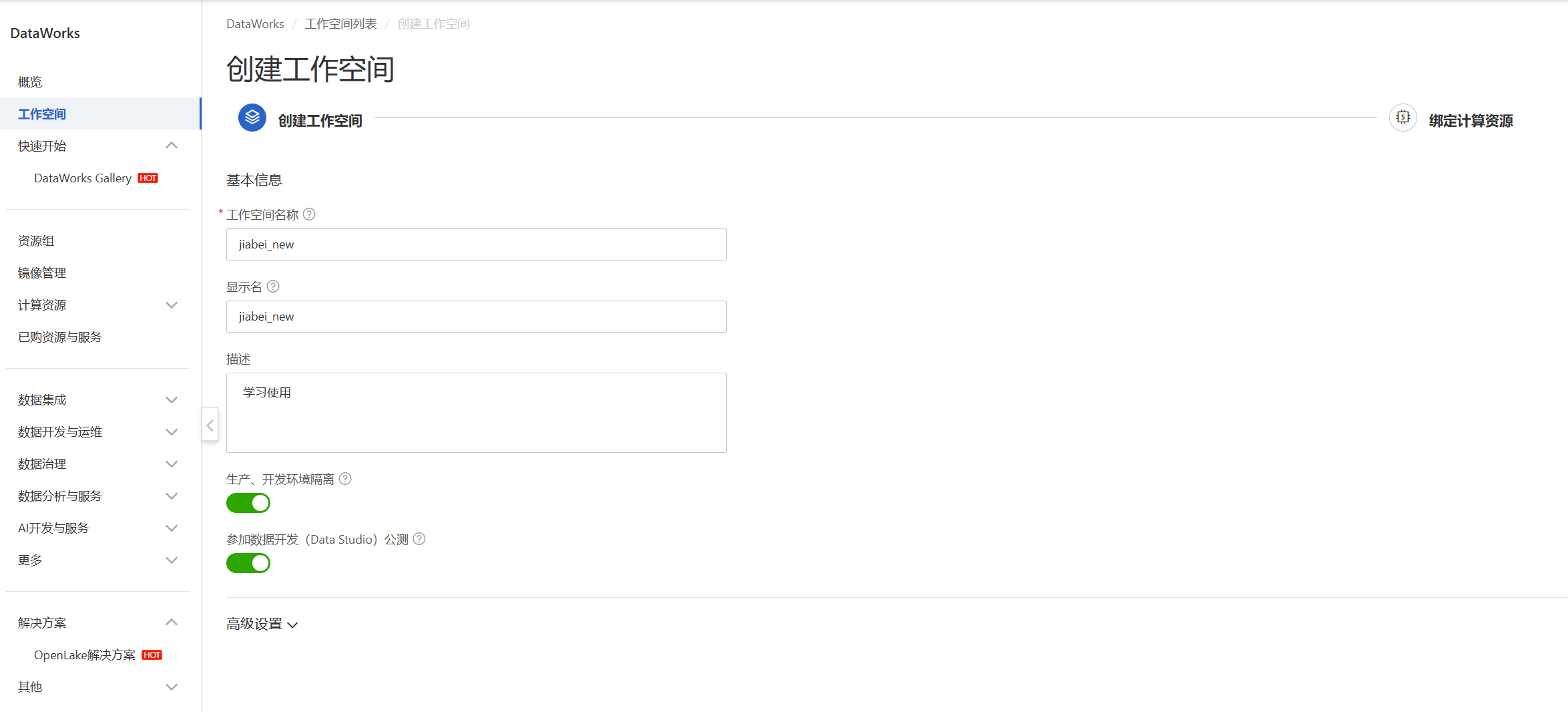
访问杭州地域的DataWorks控制台创建工作空间,选择标准模式(开发和生产环境隔离)
2、绑定计算资源
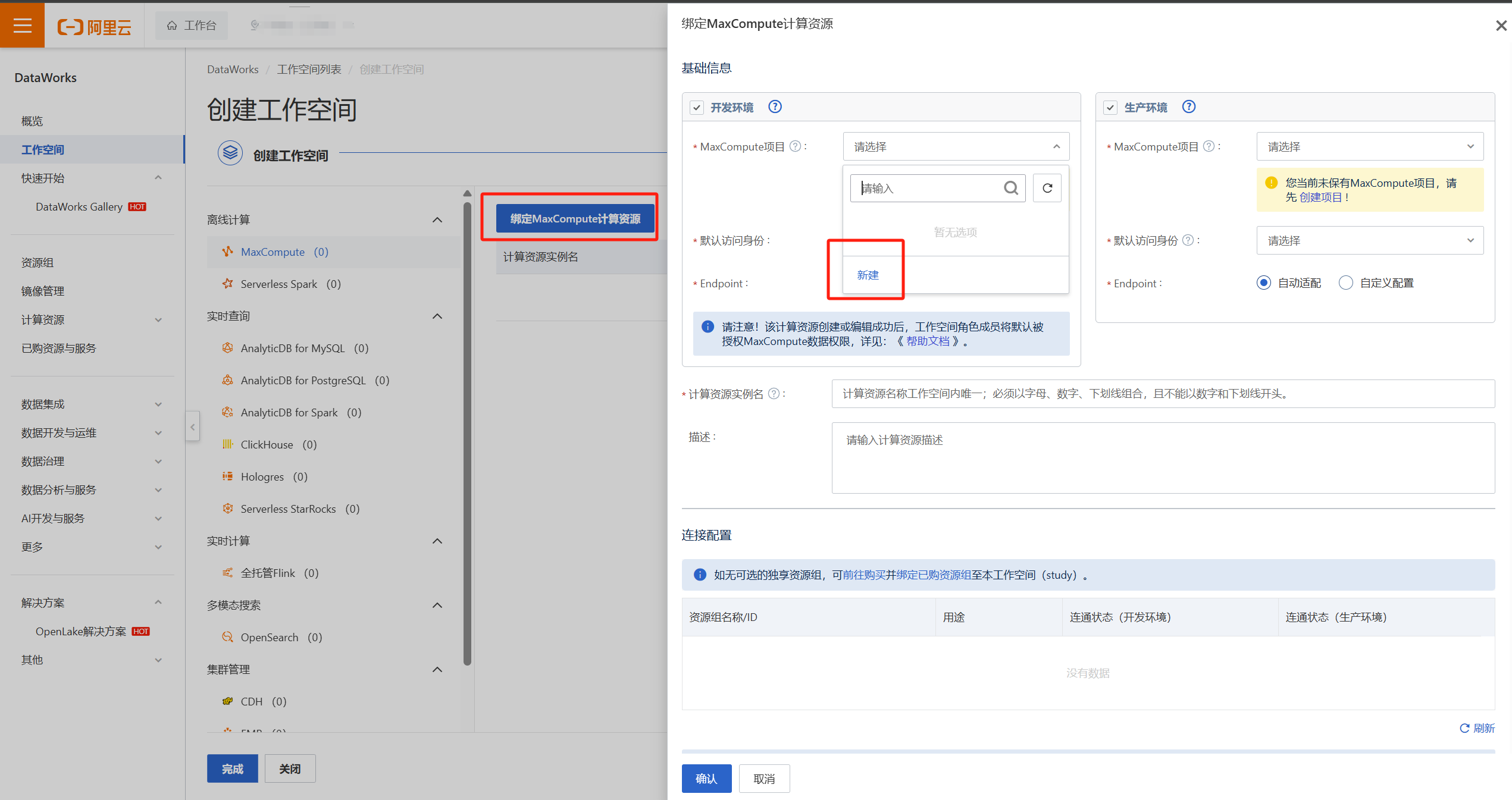
绑定计算资源, 以MaxCompute为例,要新建两个MaxCompute项目分别绑定到开发环境和生产环境(jiabei_new_dev和jiabei_new_prod)
3、数据开发
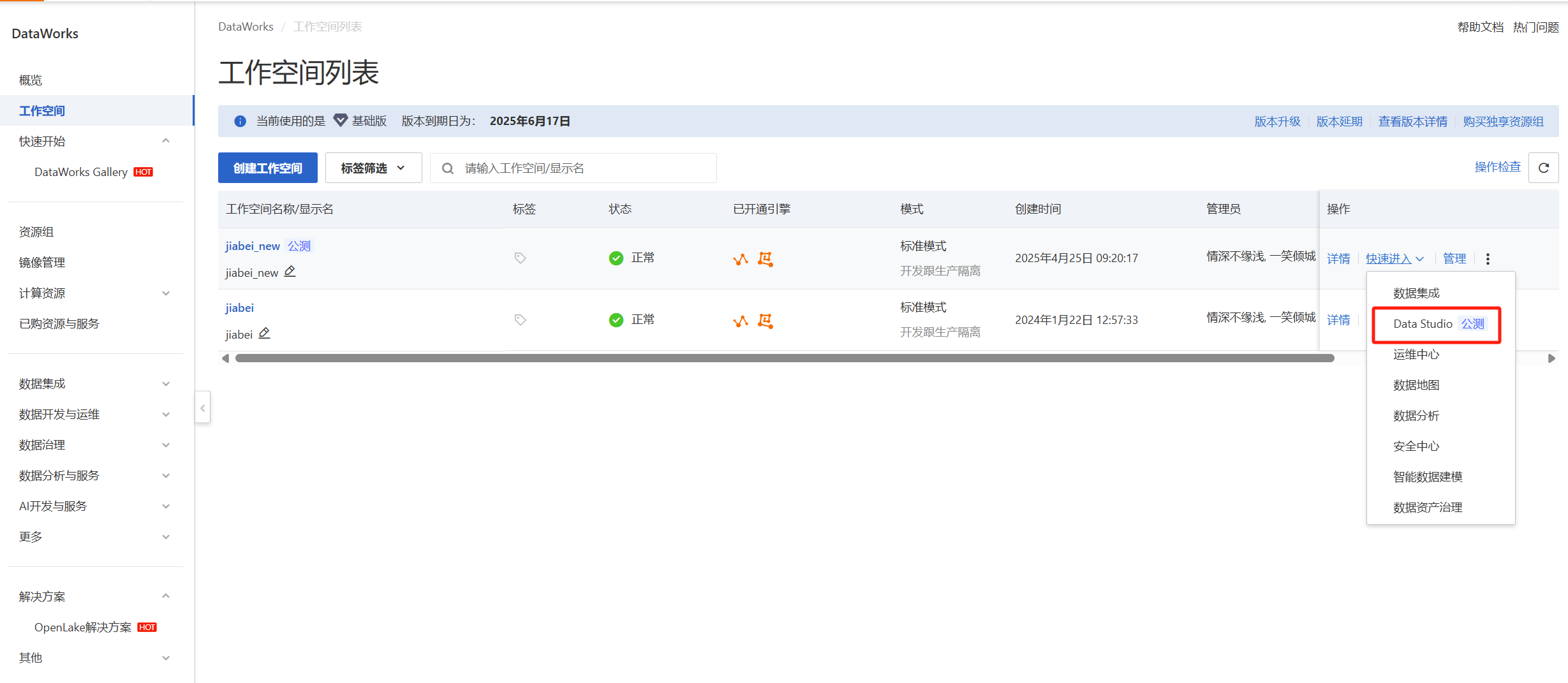
上面绑定之后可以进入数据开发页面
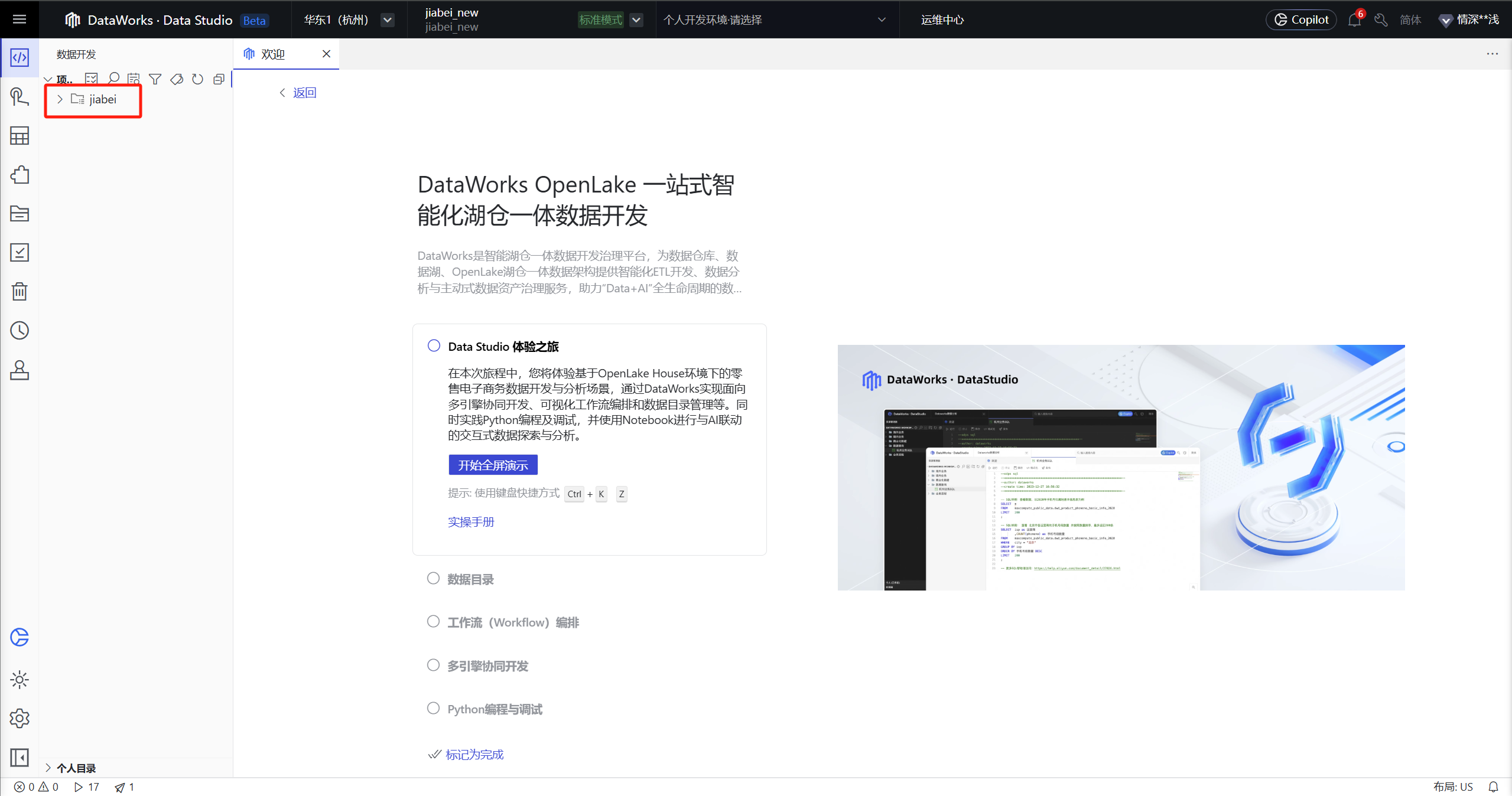
首次进入,可以在这里创建一个项目目录
三、DataWorks节点类型
1、MaxCompute SQL节点
创建一个MaxCompute SQL节点执行SQL
①创建非分区表并插入数据
CREATE TABLE IF NOT EXISTS jiabei_new_dev.student
(id BIGINT NOT NULL COMMENT '主键id信息',name STRING COMMENT '学生姓名',age INT COMMENT '学生年龄',create_time DATETIME COMMENT '创建时间'
)
STORED AS ALIORC
TBLPROPERTIES ('columnar.nested.type' = 'true','comment' = '学生表测试使用(非分区表)')
LIFECYCLE 1000
;use jiabei_new_dev;
setproject odps.sql.type.system.odps2=true; --打开MaxCompute 2.0数据类型。
setproject odps.sql.decimal.odps2=true; --打开Decimal 2.0数据类型。
INSERT INTO jiabei_new_dev.student VALUES(1,'张三',18,CAST('2020-03-12 15:12:00' AS DATETIME)),(2,'李四',19,CAST('2020-03-12 15:12:00' AS DATETIME)),(3,'王五',20,CAST('2020-03-12 15:12:00' AS DATETIME))
;
②创建分区表并插入数据
CREATE TABLE IF NOT EXISTS jiabei_new_dev.student_fenqu
(id BIGINT NOT NULL COMMENT '主键id信息',name STRING COMMENT '学生姓名',age INT COMMENT '学生年龄',create_time DATETIME COMMENT '创建时间'
)
PARTITIONED BY
(dt STRING COMMENT '统计每日出勤'
)
STORED AS ALIORC
TBLPROPERTIES ('columnar.nested.type' = 'true','comment' = '学生表测试使用(分区表)')
LIFECYCLE 1000
;INSERT INTO jiabei_new_dev.student_fenqu PARTITION(dt='20251030') VALUES(1,'张三',18,CAST('2020-03-12 15:12:00' AS DATETIME)),(2,'李四',19,CAST('2020-03-12 15:12:00' AS DATETIME)),(3,'王五',20,CAST('2020-03-12 15:12:00' AS DATETIME))
;③查询表数据
SELECT id, -- 主键id信息name, -- 学生姓名age, -- 学生年龄create_time -- 创建时间
FROM jiabei_new_prod.student
LIMIT 200;
注意: 如果查询分区表没有指定分区条件,需要加一下参数允许全表扫描,否则会报错
会话级别: SET odps.sql.allow.fullscan=true;
项目级别: SETPROJECT odps.sql.allow.fullscan=true;
2、离线同步节点
创建离线同步数据节点之前需要先创建对应的数据源,如下是想非分区表的数据 每天同步一次写入到分区表(无实际意义,仅供学习参考)
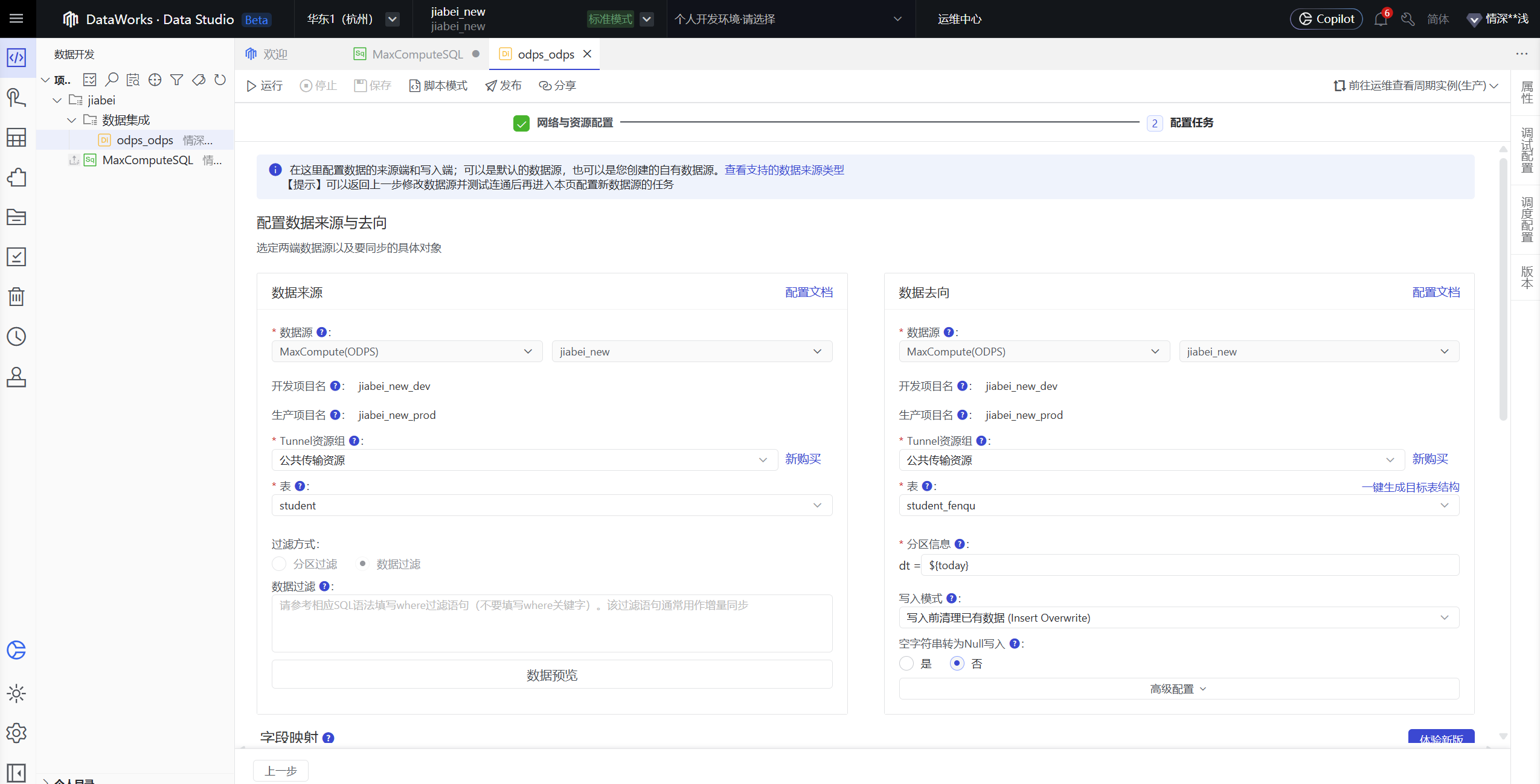 配置完整后点击发布即可在生产环境每天定时调度执行
配置完整后点击发布即可在生产环境每天定时调度执行
3、PYODPS 3节点
①判断表是否存在
print(odps.exist_table('student'))
②执行SQL语句
#同步的方式执行,会阻塞直到SQL语句执行完成。同时可以配置运行参数
instance = o.execute_sql('select * from student')
#异步的方式执行。
# instance = o.run_sql('select * from student')
print(instance.get_logview_address()) # 获取Logview地址。
instance.wait_for_success() # 阻塞直到完成。
③添加运行参数
方式一
o.execute_sql('select * from student', hints={'odps.stage.mapper.split.size': 16})
方式二
from odps import options
options.sql.settings = {'odps.stage.mapper.split.size': 16}
o.execute_sql('select * from student') # 会根据全局配置添加hints。
④输出SQL执行结果
获取表数据
with o.execute_sql('select * from student').open_reader() as reader:for record in reader: # 处理每一个record。print(record)
指定PyODPS调用Instance Tunnel。避免超时和数据受限
with o.execute_sql('select * from student').open_reader(tunnel=True) as reader:for record in reader:print(record)
获取表信息
with o.execute_sql('desc student').open_reader() as reader:print(reader.raw)
4、MaxCompute Script节点
①适用场景
脚本模式适合用来改写需要层层嵌套子查询的单个语句,或者因为脚本复杂性而不得不拆成多个语句的脚本。
如果多个输入的数据源数据准备完成的时间间隔很长(例如一个01:00可以准备好,一个07:00可以准备好),则不适合通过table variable衔接拼装为一个大的脚本模式SQL。
脚本模式下,您可以对一个变量赋常量值,然后执行SELECT * FROM 变量语句转化为标量与其它列进行计算。常量值也可以存放在一个单行的表中,命令示例如下。转化语法请参见子查询(SUBQUERY)。
详情点击参考
②简单示例
@a := SELECT 10; --对@a赋值常量10,或者赋值存在一个单行表t1中,SELECT col1 FROM t1。
@b := SELECT key,value+(SELECT * FROM @a) FROM t2 WHERE key >10000; --t2表中value值与@a中的值进行计算。
SELECT * FROM @b;
5、其他节点
https://help.aliyun.com/zh/dataworks/user-guide/dataworks-nodes/?spm=a2c4g.11186623.0.i33