第T11周:优化器对比实验
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
tf.config.list_physical_devices(“GPU”): 检查是否有可用的 GPU。
如果有 GPU:gpu0 = gpus[0]: 取第一个 GPU。
set_memory_growth: 允许 TensorFlow 按需分配显存,而不是一次性占满。
set_visible_devices: 指定只使用第一个 GPU,隐藏其他 GPU。
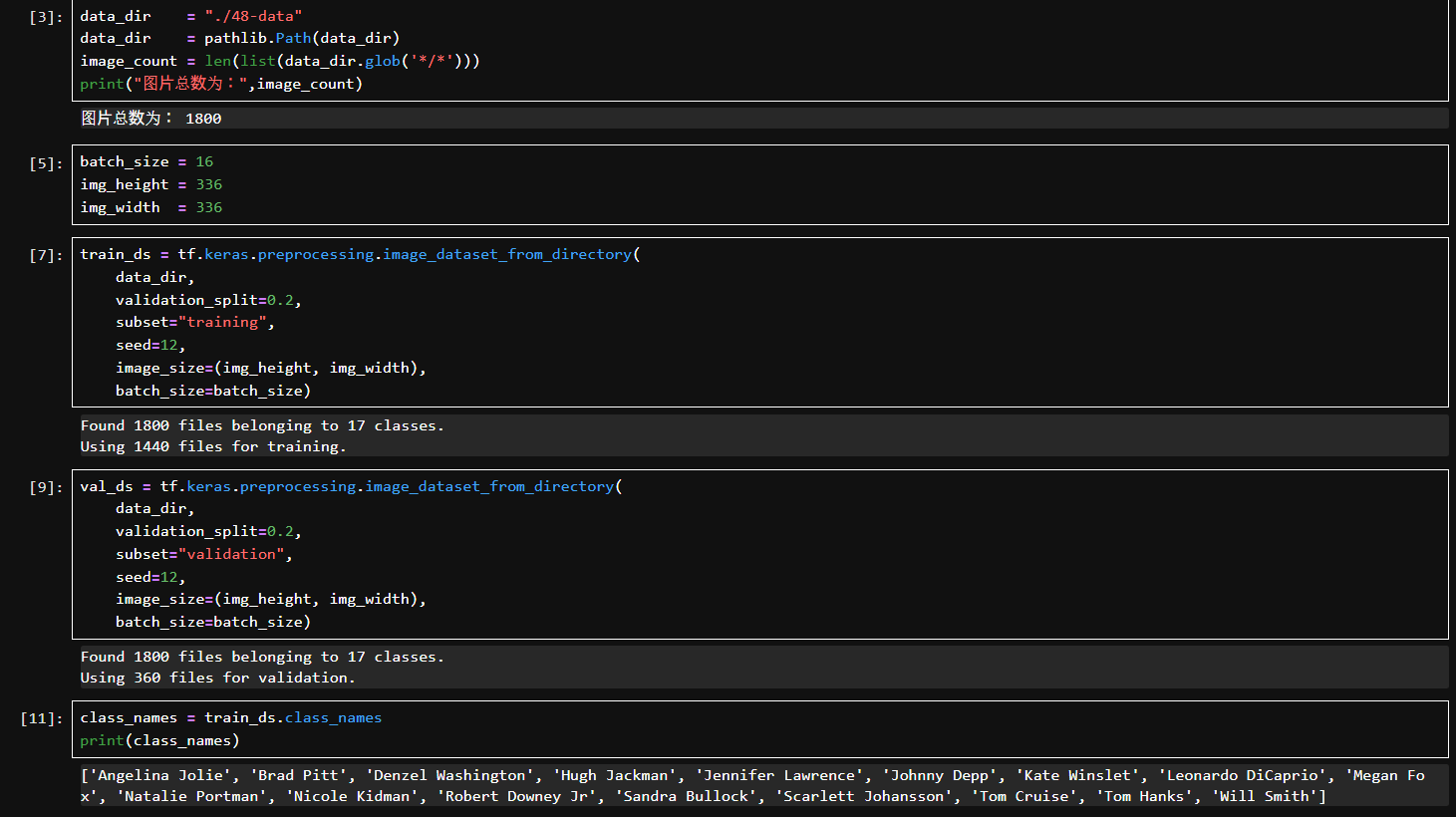
data_dir.glob(‘/’): 查找所有类别子文件夹下的图片路径。
image_count: 统计所有图像文件数量。输出结果表明有 1800 张图片。
设定模型输入图片大小为 336x336。
每次训练时的批量大小为 16。
利用 Keras 的 image_dataset_from_directory 从文件夹中读取图像并自动打上标签。
validation_split=0.2: 从所有图片中划出 20% 用作验证集。
subset=“training”: 表示提取的是训练集部分。
seed=12: 保证分割数据的随机性是可重复的。
返回的是一个包含 TensorFlow Dataset 的 train_ds 对象。
输出:使用了 1440 张图像作为训练集,共 17 个类别。
和训练集调用方式基本一致。使用了 360 张图片作为验证集。
获取数据集中所有类别的标签名。每个子文件夹的名字就会变成一个类别标签。打印出来的类名总数为 17,对应任务是17类人脸识别。
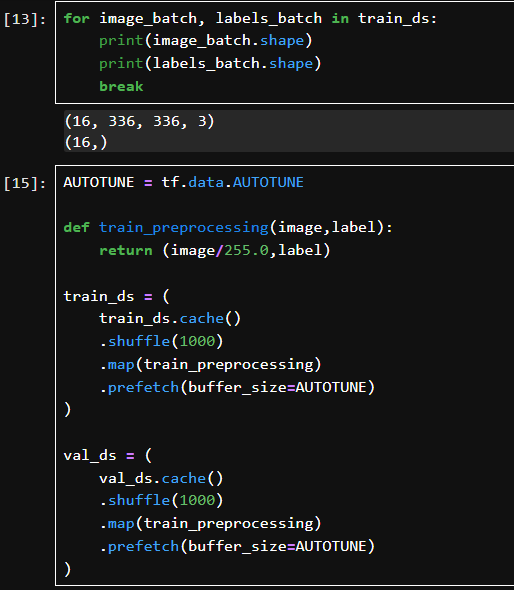
取出训练数据中的第一个 batch,共 16 张图像。
image_batch.shape = (16, 336, 336, 3):表示 batch size 为 16,每张图片为 336x336,RGB 3通道。
labels_batch.shape = (16,):每张图像对应一个整数标签(共 17 类)。
AUTOTUNE: TensorFlow 会根据系统资源自动调整性能参数。
train_preprocessing: 简单地将图像像素值缩放到 [0,1] 区间。
.cache():缓存数据,避免每轮训练都重新加载硬盘上的图像。
.shuffle(1000):随机打乱数据顺序。这里的 1000 是 shuffle buffer size,一次最多混洗多少数据。
.map(train_preprocessing):对每张图片进行标准化。
.prefetch(buffer_size=AUTOTUNE):训练时预取下一批数据。
创建一个图像窗口,大小为 10×8 英寸。
train_ds.take(1):从数据集中取 1 个 batch,返回 16 张图片。
images 是一个形状为 (16, 336, 336, 3) 的张量,labels 是 (16,) 的标签数组。
for i in range(15):展示前 15 张图像。
把整个画布分成 4×5 的网格布局。plt.xticks([])、plt.yticks([]):不显示坐标轴刻度。
plt.grid(False):关闭网格线。
显示第 i 张图。显示图片下方的标签名(class_names 是之前提取的类别名列表)。
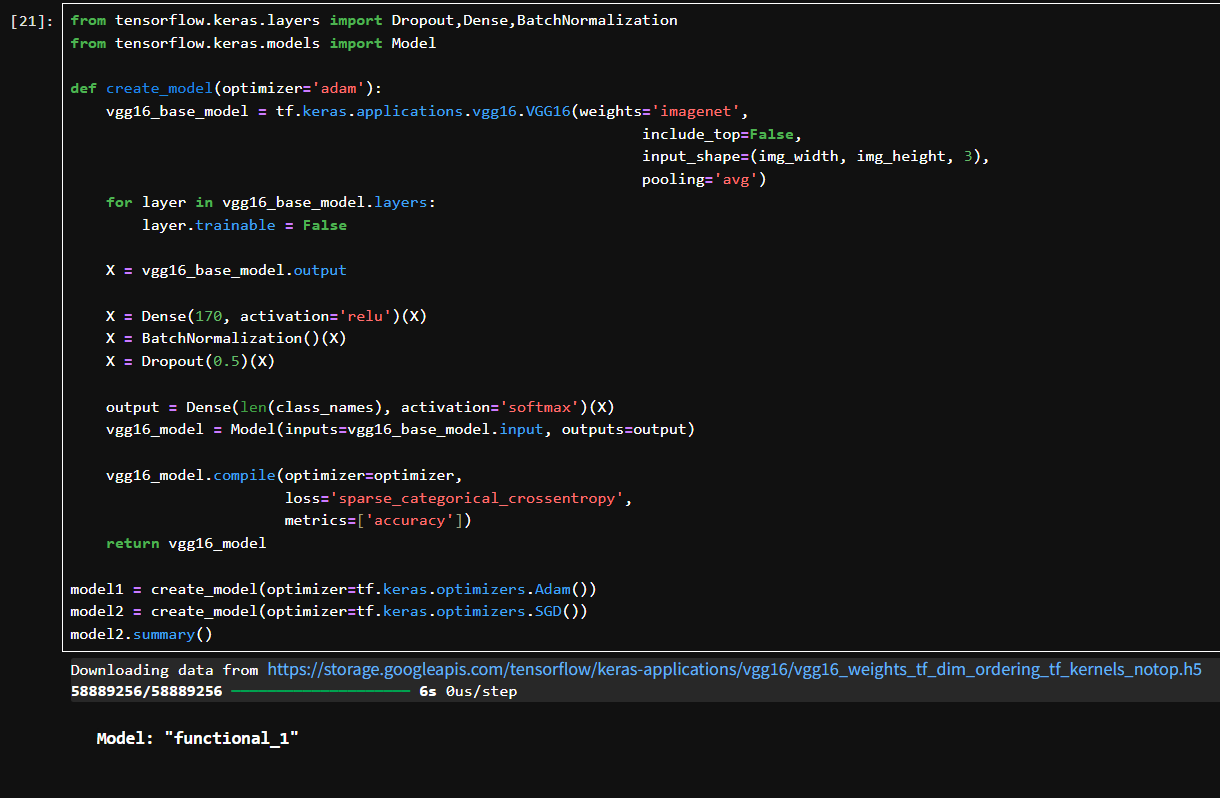
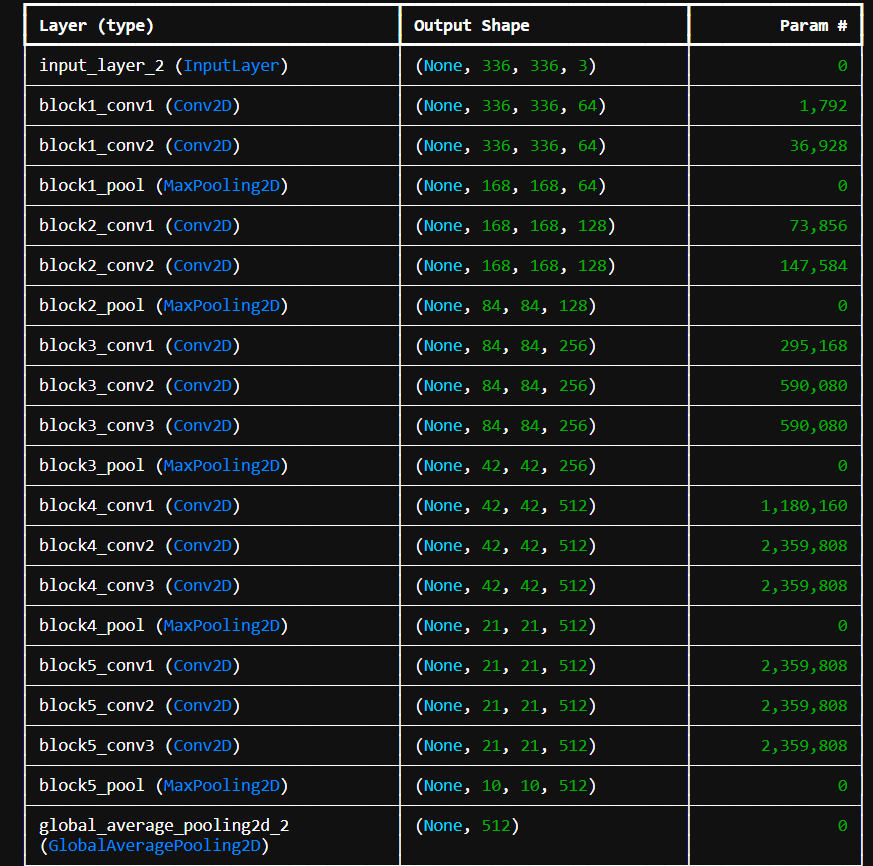
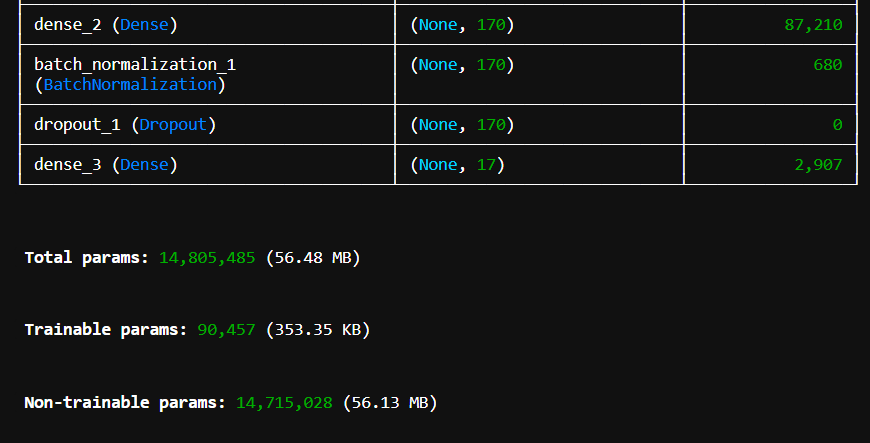
VGG16 的迁移学习分类模型
加载 VGG16 模型,使用 ImageNet 权重。不包含原始的输出层(include_top=False)。使用 GlobalAveragePooling2D (pooling=‘avg’) 替代 Flatten。
所有卷积层参数冻结,不参与训练。
X = vgg16_base_model.output
X = Dense(170, activation=‘relu’)(X)
X = BatchNormalization()(X)
X = Dropout(0.5)(X)
output = Dense(len(class_names), activation=‘softmax’)(X)
一个小型全连接网络:
Dense(170):学习高层抽象特征。
BatchNormalization:提高稳定性、加快收敛。
Dropout(0.5):防止过拟合。
最后一层 Dense:输出节点数 = 类别数量(17),使用 softmax 作为多分类输出。
vgg16_model = Model(inputs=vgg16_base_model.input, outputs=output)
vgg16_model.compile(optimizer=optimizer, loss=‘sparse_categorical_crossentropy’, metrics=[‘accuracy’])
用 Model API 将整个结构组装起来。损失函数是 sparse_categorical_crossentropy:适用于标签为整数的分类任务。
model1 = create_model(optimizer=tf.keras.optimizers.Adam())
model2 = create_model(optimizer=tf.keras.optimizers.SGD())
创建两个模型,分别使用 Adam 和 SGD 优化器,作对比实验。
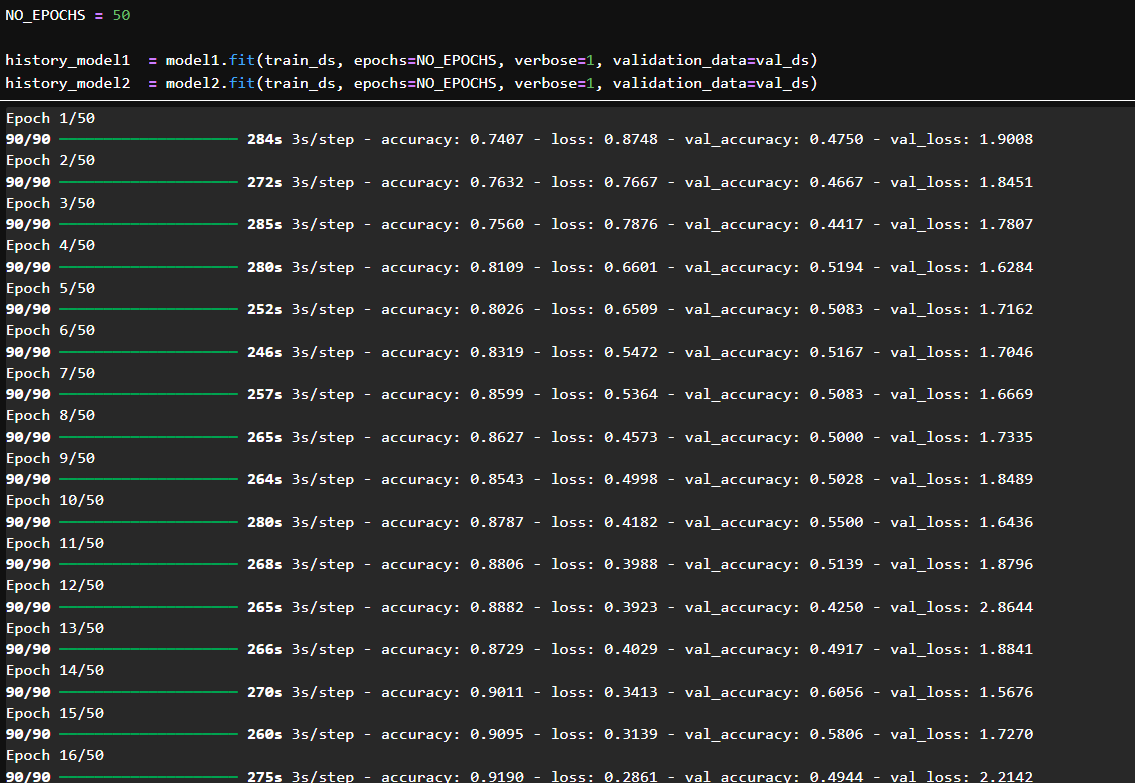
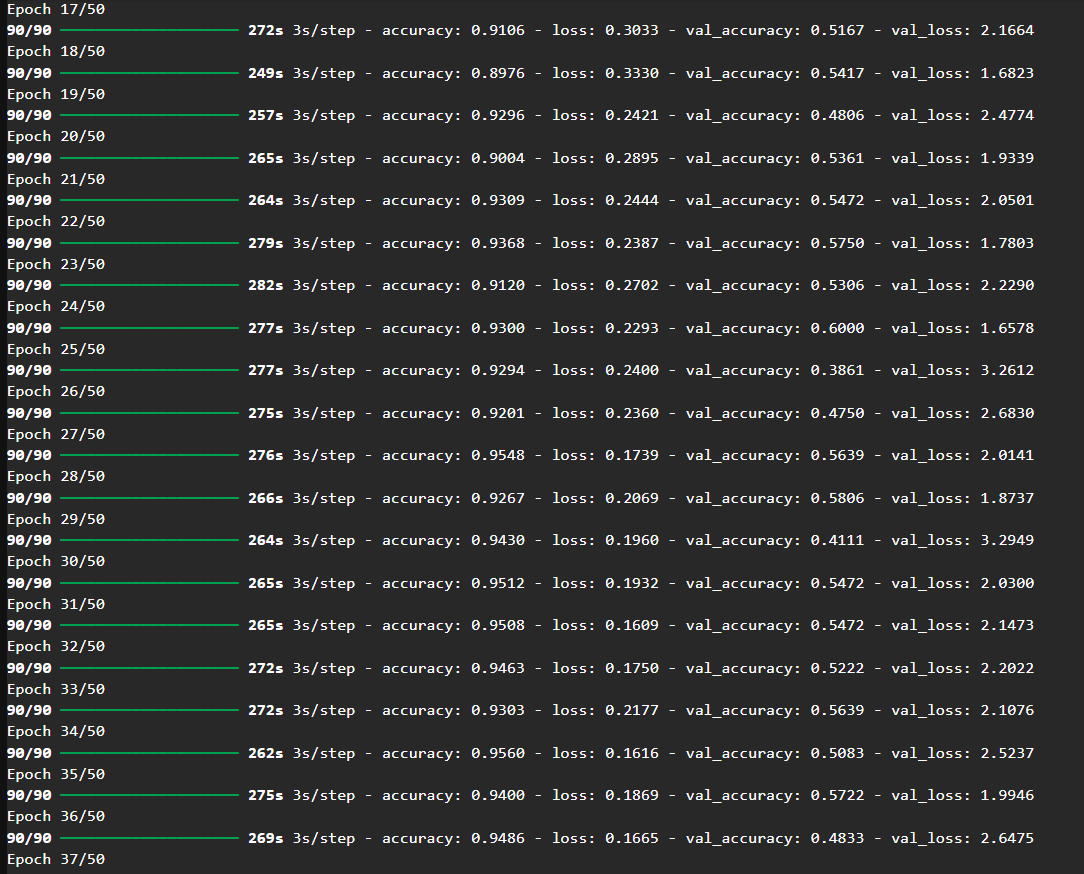
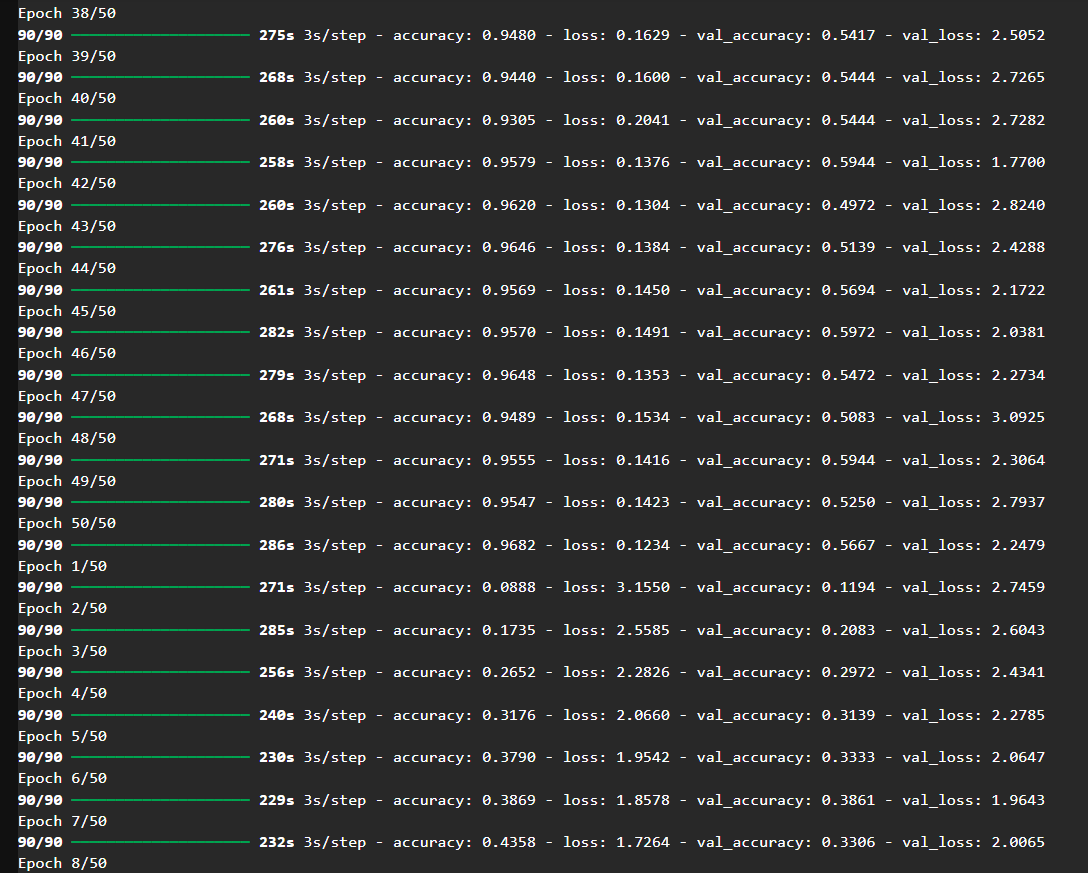
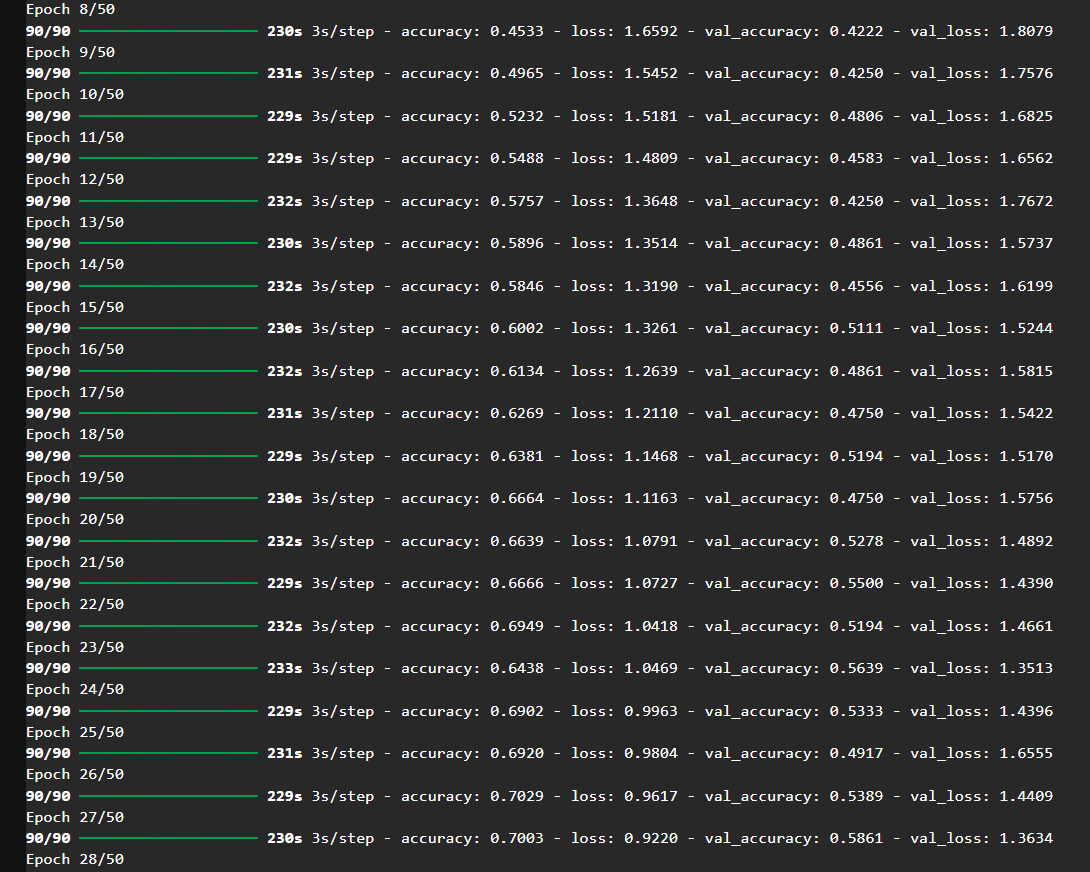
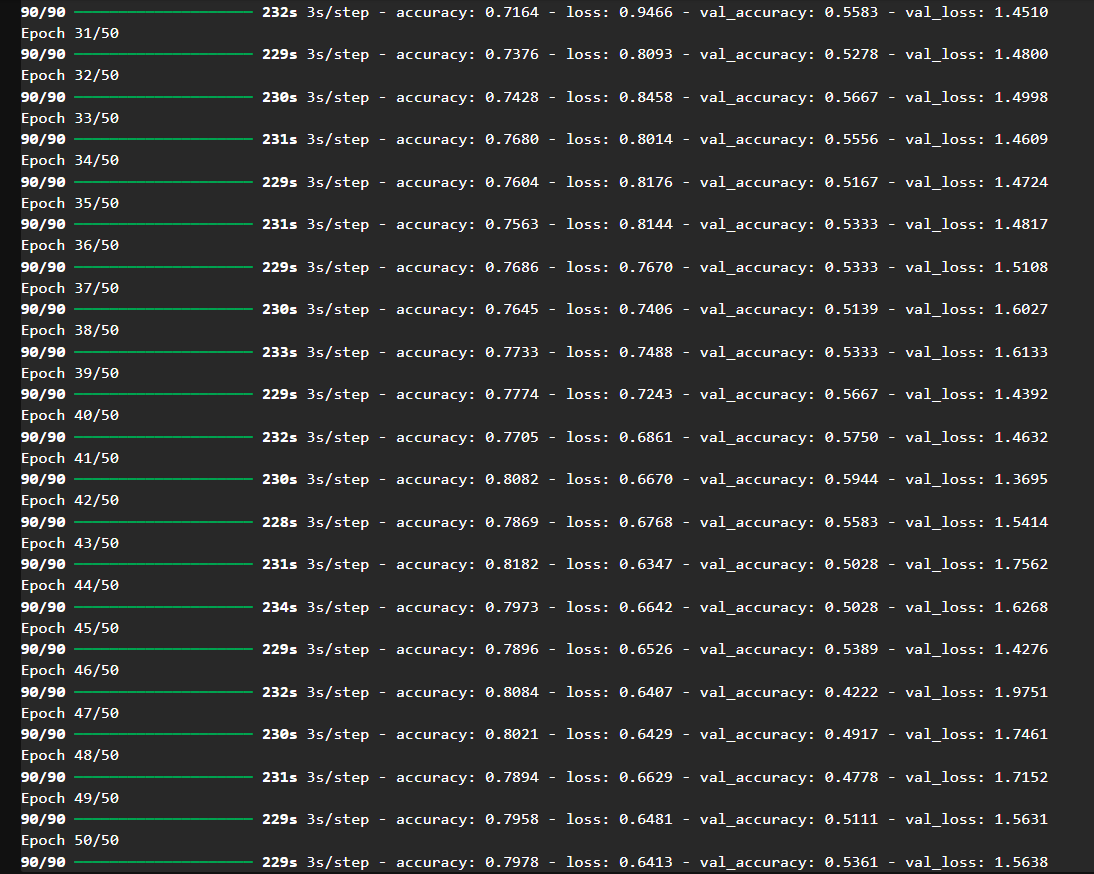
模型训练轮数为 50 轮。
分别训练使用 Adam 和 SGD 优化器的模型。都使用相同的数据集 train_ds 和验证集 val_ds。
训练准确率持续提升:说明模型能成功学习训练数据特征。
训练 loss 稳步下降:学习过程有效,Adam 表现较稳定。
Adam 模型表现图示:
训练集:96.8% 准确率,损失接近 0.1
验证集:在 Epoch 14 达到峰值后波动大,val loss 持续走高
SGD 模型表现图示:
收敛缓慢,但更加平稳,验证 loss 没有明显震荡或暴涨。
最终验证准确率接近 Adam,且泛化能力略优。
acc1/acc2是 训练准确率(Adam/SGD)。val_acc1/val_acc2是 验证准确率。
loss1/loss2为训练损失。val_loss1/val_loss2为验证损失。
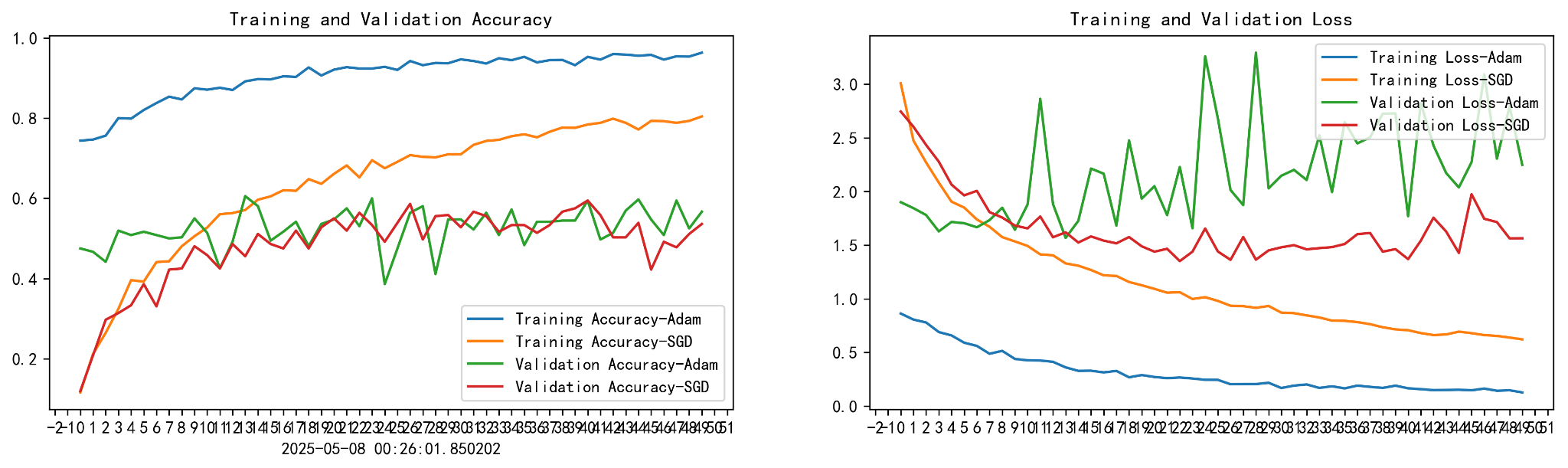
Training and Validation Accuracy
Adam:训练准确率很快逼近 96%;但验证准确率在 50~60% 附近震荡,过拟合。
SGD:收敛慢但稳定;训练准确率逐步上升到 80%,验证准确率保持在 55~60% 左右,泛化略优于 Adam。
Training and Validation Loss
Adam:训练 loss 非常低,但验证 loss 波动剧烈,过拟合。
SGD:loss 曲线更平滑、震荡小;验证 loss 维持在 1.3~1.8 之间,稳定反映模型性能。
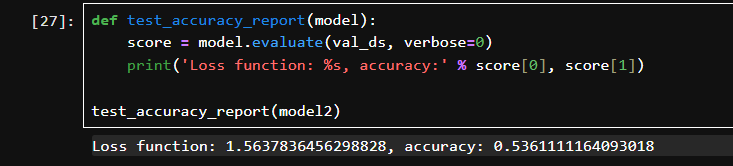
验证集 Loss大约为1.56。
验证集 Accuracy大约为53.6%。
对比 Adam 模型,波动更小、泛化更稳,是更优选择。