【Redis】持久化与事务
文章目录
- 1. 持久化
- 1.1 RDB(定期)
- 1.1.1 触发方式
- 1.1.2 触发流程
- 1.2. AOF(实时)
- 1.2.1 设置AOF
- 1.2.2 刷新策略
- 1.2.3 重写机制
- 2. 事务
- 2.1 redis事务概念
- 2.2 事务操作

Mysql有几个特性:
- 原子性
- 一致性
- 隔离性,redis是串行的,自带隔离性
- 持久性,redis的持久化跟这个是一回事
1. 持久化
所以,要想办法将redis保存在内存上的的数据存在磁盘上;但是直接将数据存到磁盘上,是不是违反了redis快的特性了呢? - - 是的
为了达到快、持久的特性,redis会在内存、磁盘上均存储数据,并且两份数据理论上应该相同;将数据从内存写入到硬盘有不同的策略。
代价:消耗了更多的空间
Redis ⽀持RDB(redis database)和AOF(append only file)两种持久化机制,持久化功能有效地避免因进程退出造成数据丢失问题,当下次重启时利⽤之前持久化的⽂件即可实现数据恢复,当查询数据时,依旧是从内存中查找
1.1 RDB(定期)
1.1.1 触发方式
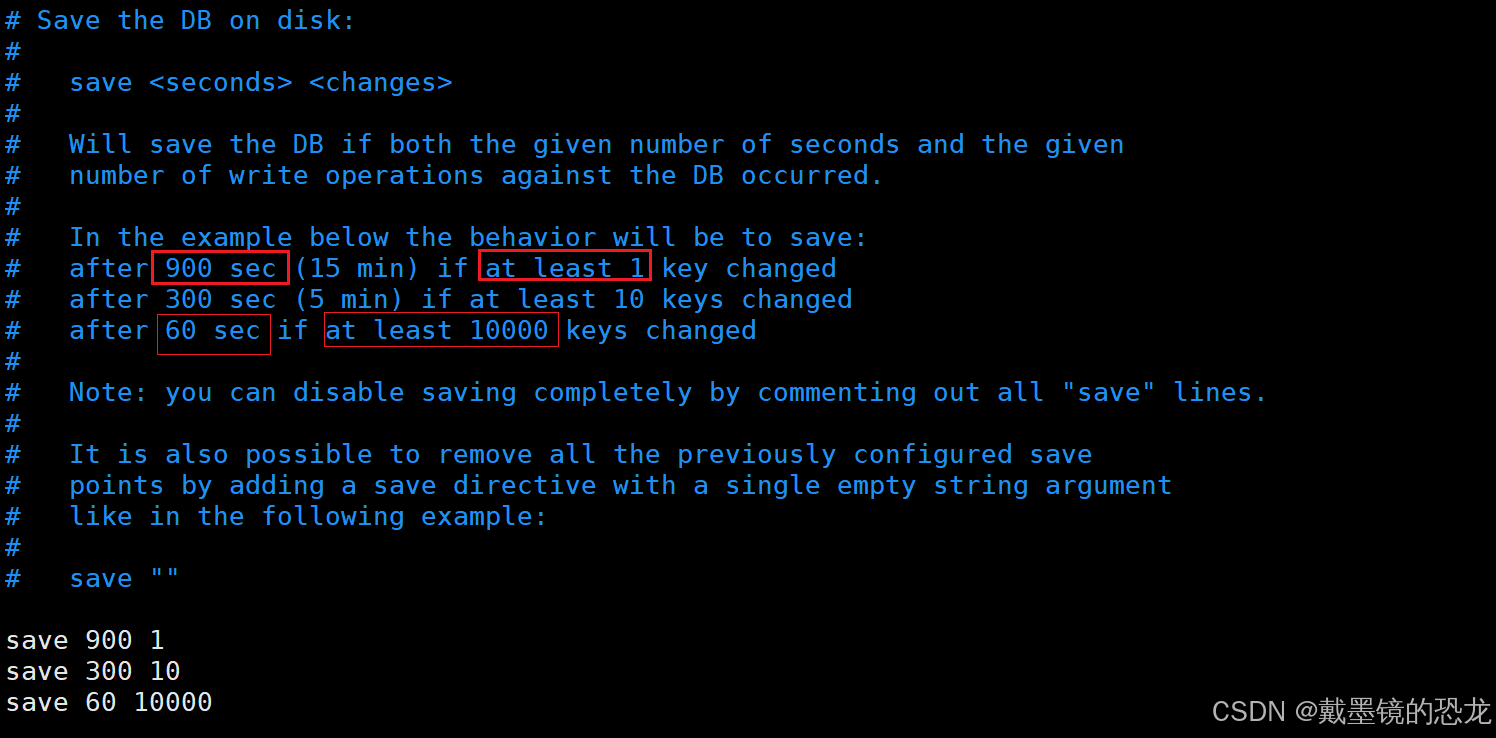
RDB策略定期的将redis内存中的数据,形成一个“快照”,写入到硬盘中。
- 手动触发
- save:会阻塞其它redis命令,不建议使用
- bgsave:后台运行(fork),子进程进行生成快照,写文件的工作
- 自动触发
配置文件中设置,修改配置文件后,一般需要重启服务器
两个条件都满足,才执行
其中,save ""是关闭自动生成
1.1.2 触发流程
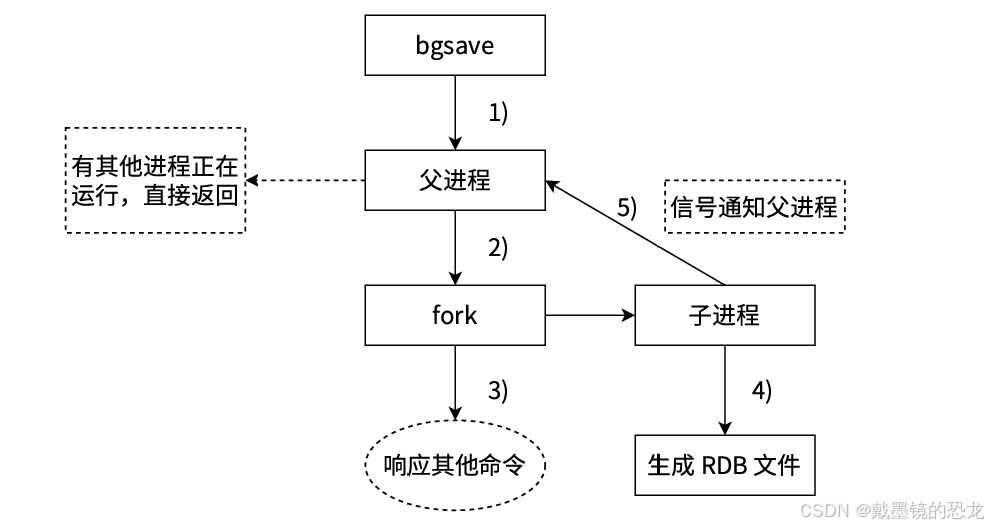
手动触发的执行流程:
RDB文件的位置:


保存:RDB⽂件保存再dir配置指定的⽬录(默认/var/lib/redis/)下,⽂件名通过dbfilename配置(默认dump.rdb)指定。
可以通过执⾏config setdir {newDir}和config setdbfilename {newFilename} 运⾏期间动态执⾏,当下次运⾏时RDB⽂件会保存到新⽬录。
至始至终,RDB文件只有一个
压缩:Redis默认采⽤LZF算法对⽣成的RDB⽂件做压缩处理,压缩后的⽂件远远⼩于内存大小,默认开启,可以通过参数config set rdbcompression{yes|no}动态修改。
校验:如果Redis启动时加载到损坏的RDB⽂件会拒绝启动。这时可以使⽤Redis提供的redis-check-dump⼯具检测RDB⽂件并获取对应的错误报告。

测试一下:
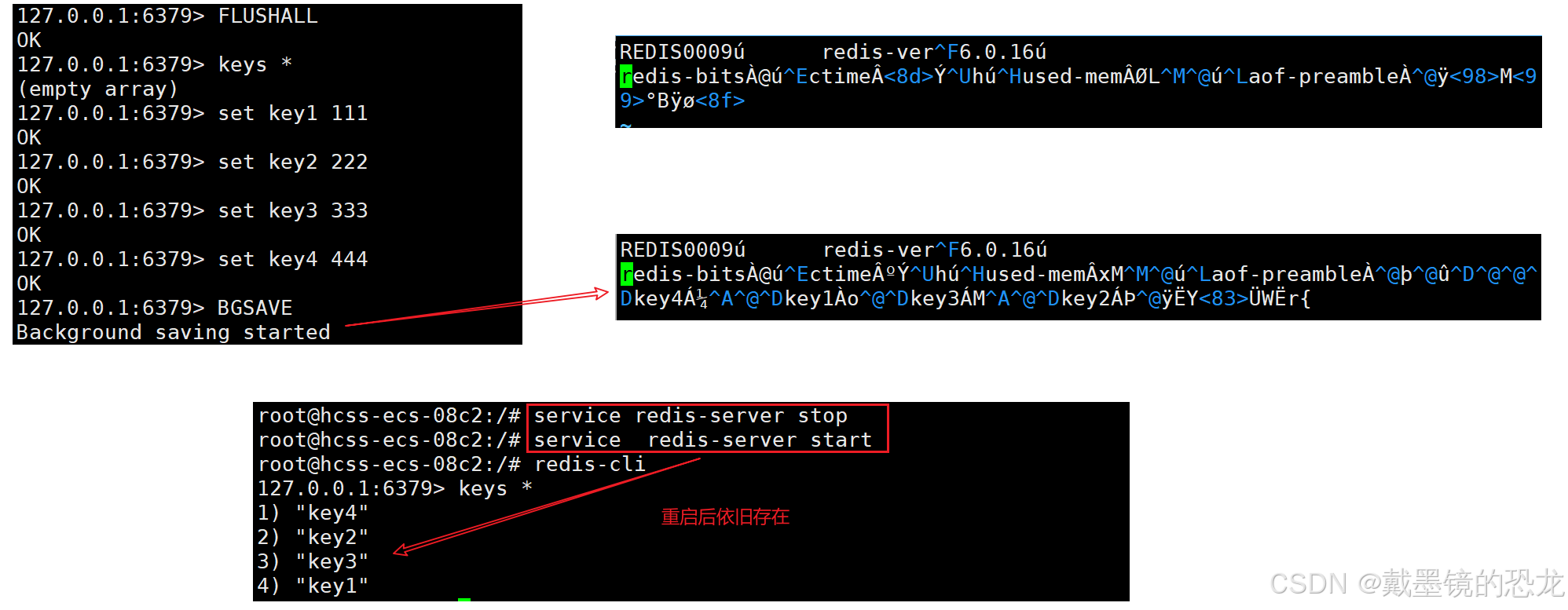
redis生成快照时,不仅仅是手动触发,也可以自动触发
- 配置文件中设置触发条件
- redis服务器正常关闭时,会触发
- 执行主从复制时,主节点也会自动生成rdb快照,然后把rdb快照文件内容传输给从节点(后面讲)
若异常退出(kill - 9 、断电),不会保存
bgsave 操作流程是创建子进程,子进程完成持久化操作,持久化速度太快了(数据少),难以观察到子进程.
持久化会把数据写入到新的文件中,然后使用新的文件替换旧的文件,这个是容易观察到的;可以使用 linux 的 stat 命令,査看文件的 inode 编号
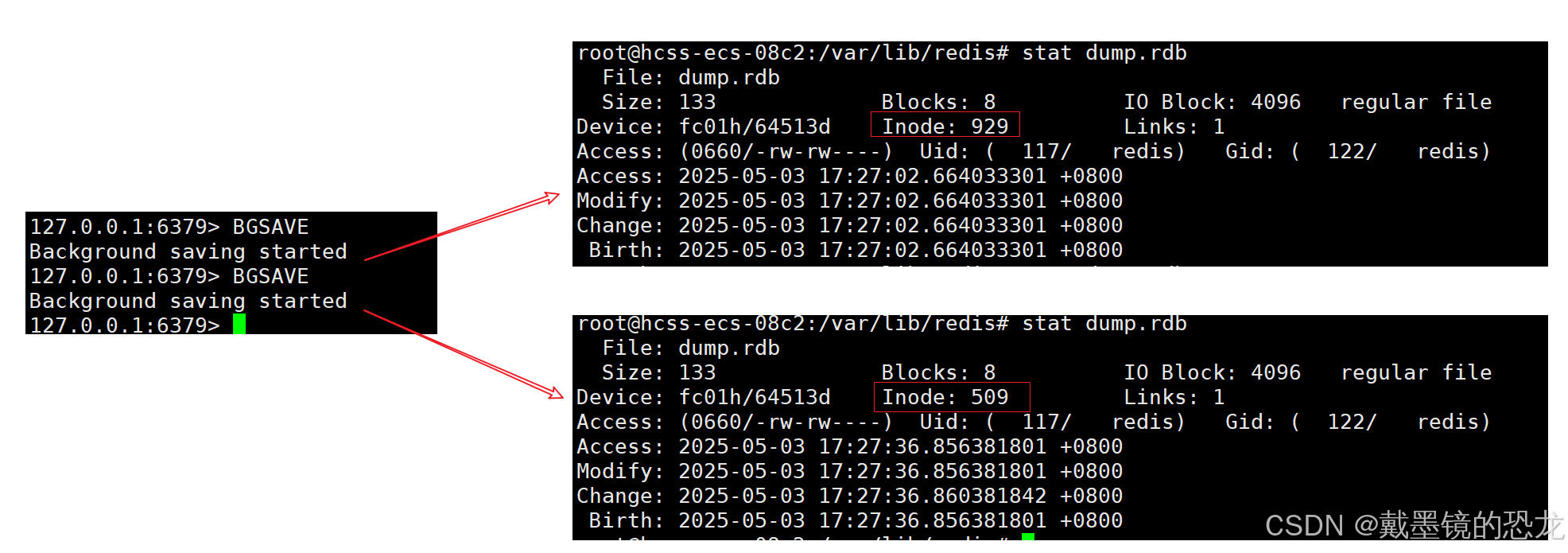
如果直接使用 save 命令,此时是不会触发子进程 & 文件替换逻辑;save 就直接在当前进程中,往同一个文件中写入数据了
RDB的优缺点
- RDB是⼀个紧凑压缩的⼆进制⽂件,代表Redis在某个时间点上的数据快照。⾮常适⽤于备份,全量复制等场景。
- ⽐如每6⼩时执⾏bgsave备份,并把RDB⽂件复制到远程机器或者⽂件系统中(如hdfs)⽤于灾备。
- Redis加载RDB恢复数据远远快于AOF的⽅式
- 因为其是使用二进制方式组织数据的
- RDB⽅式数据没办法做到实时持久化/秒级持久化。
- 因为bgsave每次运⾏都要执⾏fork创建⼦进程,属于重量级操作,频繁执⾏成本过⾼。
- RDB⽂件使⽤特定⼆进制格式保存,Redis版本演进过程中有多个RDB版本,兼容性可能有⻛险。
1.2. AOF(实时)
1.2.1 设置AOF
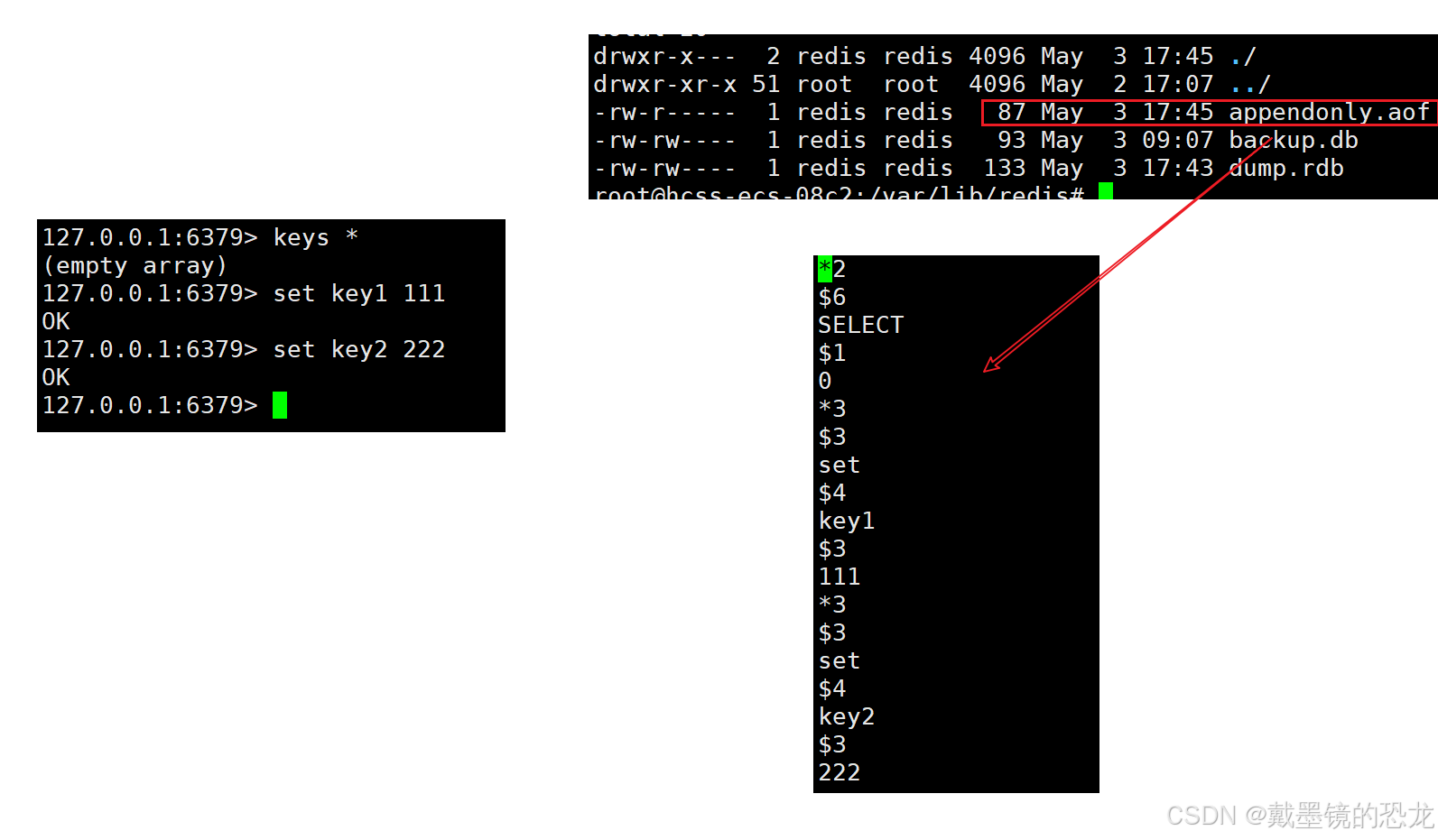
AOF持久化:以独⽴⽇志的⽅式记录每次写命令,重启时再重新执⾏AOF⽂件中的命令达到恢复数据的⽬的。
AOF的主要作⽤是解决了数据持久化的实时性,⽬前已经是Redis 持久化的主流⽅式。
当开启aof的时候,就会读取aof这个文件的内容,用来恢复数据(此时rdb就不生效了)
- 开启AOF功能需要设置配置:
appendonly yes,默认不开启。- AOF⽂件名通过appendfilename 配置(默认是appendonly.aof)设置。保存⽬录同RDB持久化⽅式⼀致,通过dir配置指定。
- AOF的⼯作流程操作:命令写⼊(append)、⽂件同步(sync)、⽂件重写(rewrite)、重启加载(load)

appendonly开启后,自动保存
AOF是一个文本文件,redis的每一次操作,都会被记录到文件中
1.2.2 刷新策略
引入AOF后,redis既要写内存,又要写磁盘,它的速度会不会受影响呢? - - 并没有
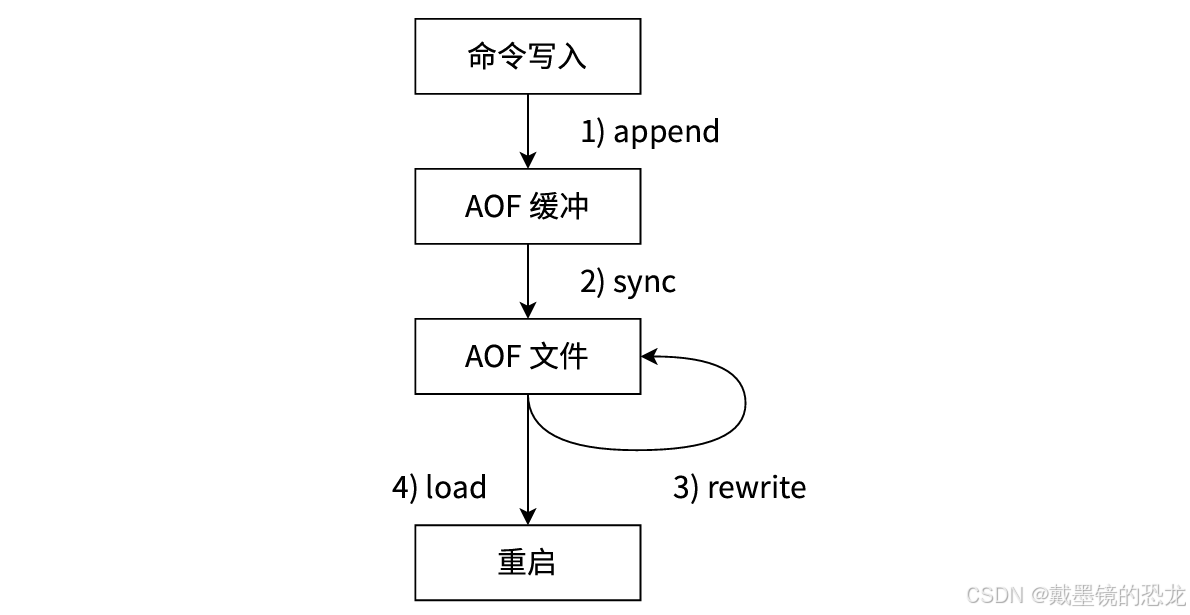
- 所有的写⼊命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF⽂件越来越⼤,需要定期对AOF⽂件进⾏重写,达到压缩的⽬的。
- 当Redis服务器启动时,可以加载AOF⽂件进⾏数据恢复
AOF过程中为什么需要aof_buf这个缓冲区?Redis使⽤单线程响应命令,如果每次写AOF⽂件都直接同步硬盘,性能从内存的读写变成IO读写,必然会下降。先写⼊缓冲区可以有效减少IO次数,同时,Redis还可以提供多种缓冲区同步策略,让⽤⼾根据⾃⼰的需求做出合理的平衡。
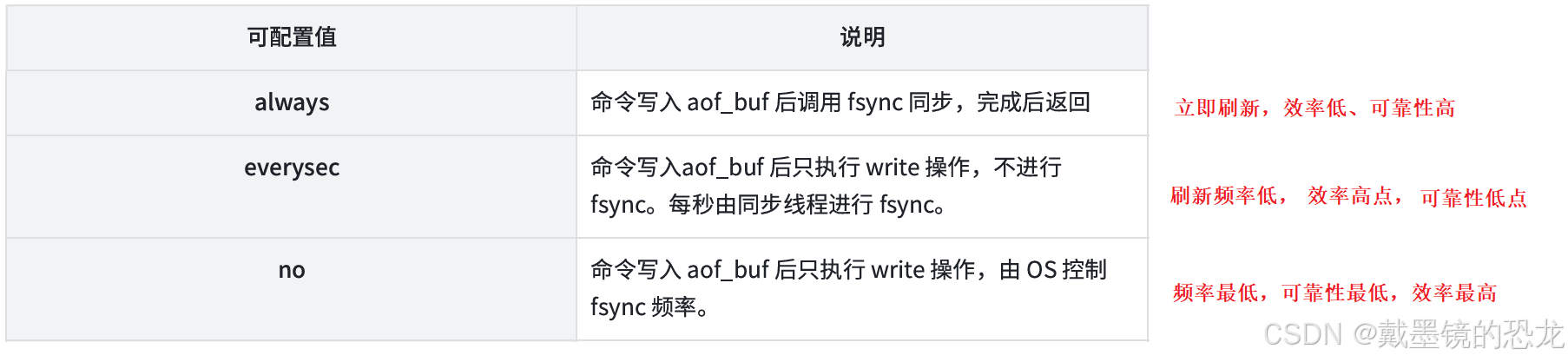
redis给出了一些缓冲区刷新的策略,根据不同的场景供我们选择
1.2.3 重写机制
随着命令不断写⼊AOF,⽂件会越来越⼤,为了解决这个问题,Redis引⼊AOF重写机制压缩⽂件体积。
AOF⽂件重写是把Redis进程内的数据转化为写命令同步到新的AOF⽂件(剔除、合并一些操作,从而达到“瘦身的目的”)
重写后的AOF为什么可以变⼩?有如下原因:
- 进程内已超时的数据不再写⼊⽂件。
- 旧的AOF中的⽆效命令,例如del、hdel、srem等重写后将会删除,只需要保留内存中数据的最终版本
- 多条写操作合并为⼀条,例如
lpush key a、lpush key b、lpush key c从可以合并为lpush key a b c。- 较⼩的AOF⽂件⼀⽅⾯降低了硬盘空间占⽤,⼀⽅⾯可以提升启动Redis时数据恢复的速度
AOF重写过程可以手动触发和⾃动触发:
- 手动触发:调⽤
bgrewriteaof命令。 - 自动触发:根据
auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定⾃动触发时机。- auto-aof-rewrite-min-size:表⽰触发重写时AOF的最小文件大小,默认为64MB。
- auto-aof-rewrite-percentage:代表当前AOF占用大小相⽐较上次重写时增加的⽐例
AOF重写流程
如果当前进程正在执⾏AOF重写,请求不执⾏;如果当前进程正在执⾏bgsave操作,重写命令延迟到bgsave完成之后再执⾏。
子进程只需要把内存中当前的数据获取出来,以 AOF 的格式写入到一个新的 AOF 文件中
(内存中的数据的状态,就已经相当于是把 AOF 文件结果整理后的模样了)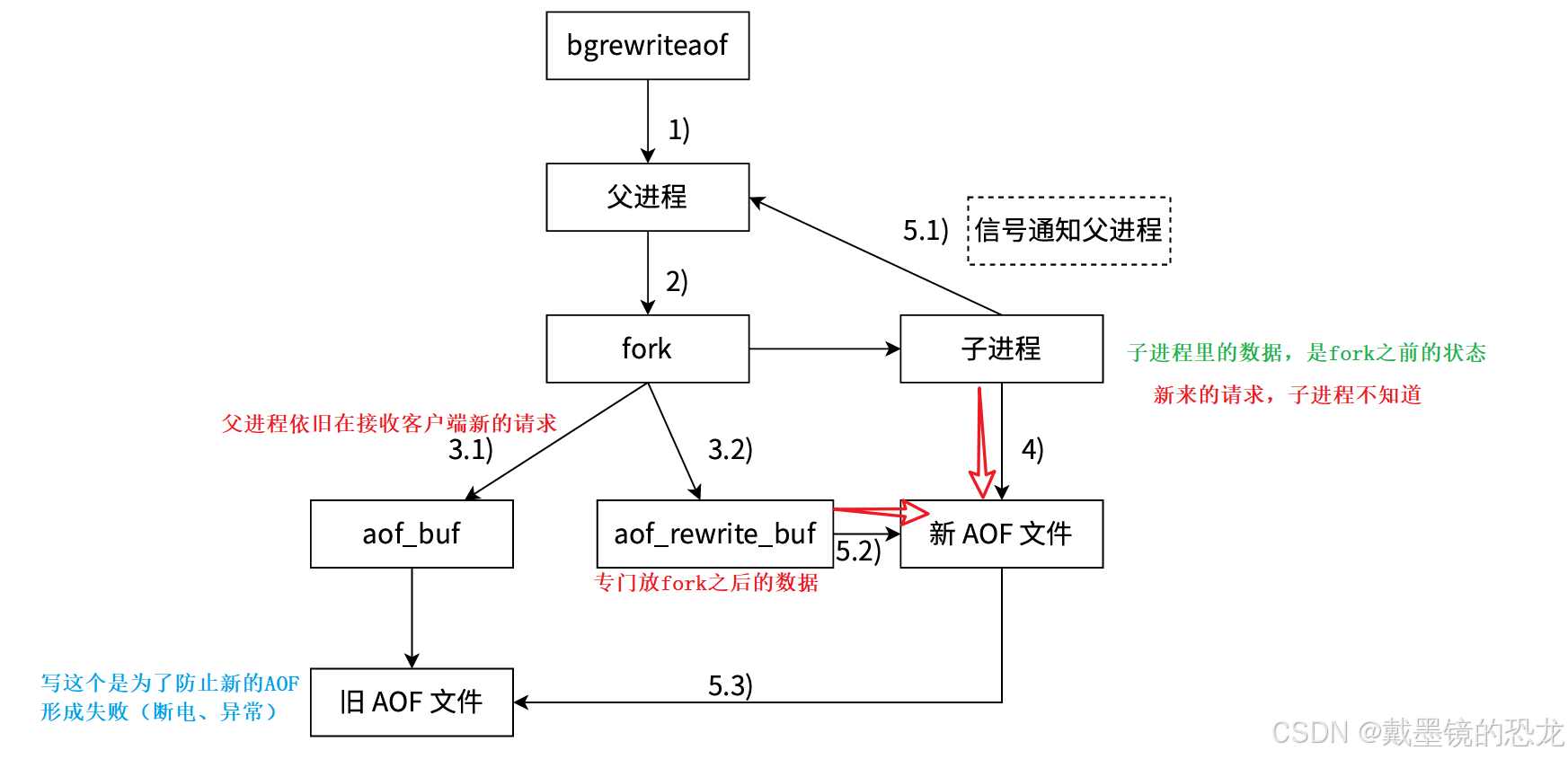
此处子进程写数据的过程,非常类似于 RDB 生成一个镜像快照
- 只不过 RDB 这里是按照二进制的方式来生成的,
- AOF 重写,则是按照 AOF 这里要求的文本格式来生成的,
- 二者都是为了把当前内存中的所有数据状态记录到文件中!!
启动时数据恢复
当Redis启动时,会根据RDB和AOF⽂件的内容,进⾏数据恢复
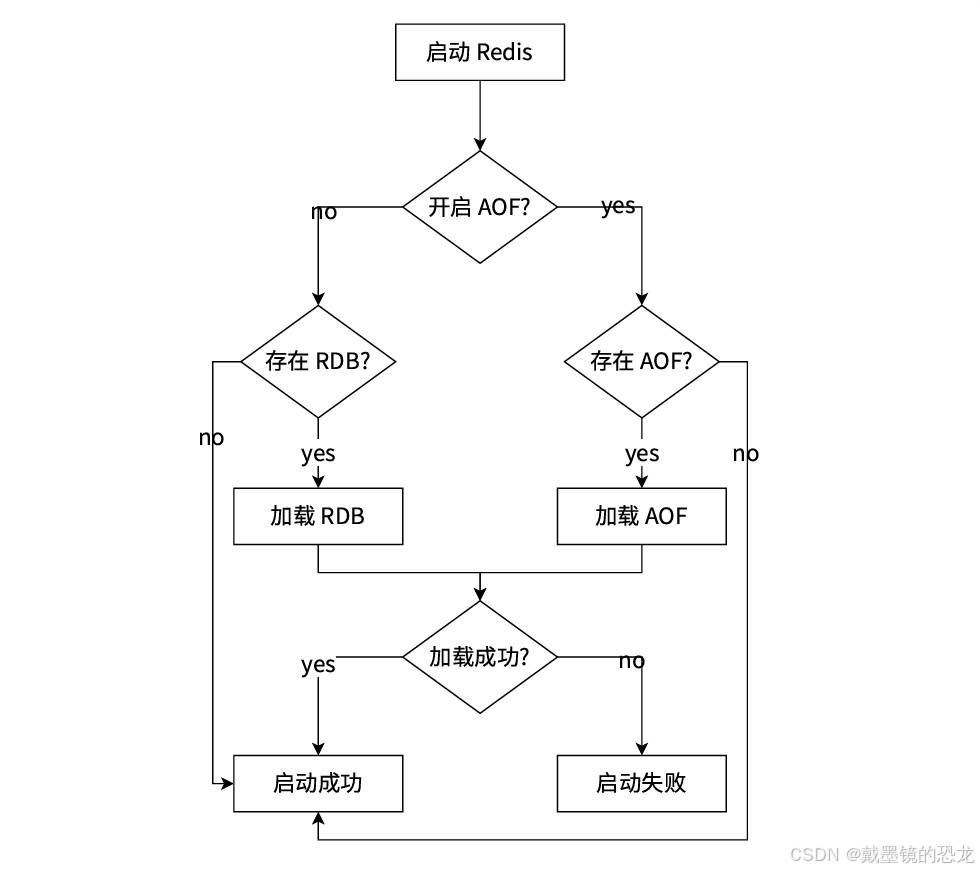
混合持久化模式:按照aof的方式,每一个请求/操作,都记录到文件中;在触发aof重写后,就会把当前的内存状态按照rdb二进制的格式写入到新的aof文件中,后续在进行操作,仍然是按照aof文本的方式追加在后面。

RDB与AOF的对比:
- RDB视为内存的快照,产⽣的内容更为紧凑,占⽤空间较小,恢复时速度更快。但产⽣RDB的开销较⼤,不适合进⾏实时持久化,⼀般⽤于冷备和主从复制。
- AOF视为对修改命令保存,在恢复时需要重放命令。并且有重写机制来定期压缩AOF⽂件。
- RDB和AOF都使⽤fork创建⼦进程,利⽤Linux⼦进程拥有⽗进程内存快照的特点进⾏持久化,尽可能不影响主进程继续处理后续命令。
可能出现的面试题:
- redis为什么持久化?有哪些方式?
- RDB与AOF的区别,各自有什么优势?
- RDB文件的生成流程,以及AOF重写的流程
2. 事务
2.1 redis事务概念
Redis的事务和MySQL事务的区别:
- 弱化的原⼦性:redis没有"回滚机制",只能做到这些操作"批量执行",不能做到"⼀个失败就恢复到初始状态"
- 不保证⼀致性:不涉及"约束",也没有回滚。
- MySQL的⼀致性体现的是运⾏事务前和运⾏后,结果都是合理有效的,不会出现中间⾮法状态
- 不需要隔离性:也没有隔离级别,因为不会并发执⾏事务(redis单线程处理请求).
- 不需要持久性:redis是保存在内存的,是否开启持久化,是redis-server⾃⼰的事情,和事务⽆关
Redis 事务本质上是在服务器上搞了⼀个"事务队列",每次客⼾端在事务中进⾏⼀个操作,都会把命令先发给服务器,放到"事务队列"中,但是并不会⽴即执⾏,⽽是会在真正收到EXEC命令之后才真正执⾏队列中的所有操作。
因此,Redis的事务的功能相⽐于MySQL来说,是弱化很多的,只能保证事务中的这⼏个操作是"连续的",不会被别的客⼾端"加塞",仅此⽽已。
redis为什么不像mysql一样呢? - - 所需空间、时间的代价太大
2.2 事务操作
MULTI
开启⼀个事务,执⾏成功返回OK
EXEC
真正执⾏事务
DISCARD
放弃当前事务,此时直接清空事务队列,之前的操作都不会真正执⾏到
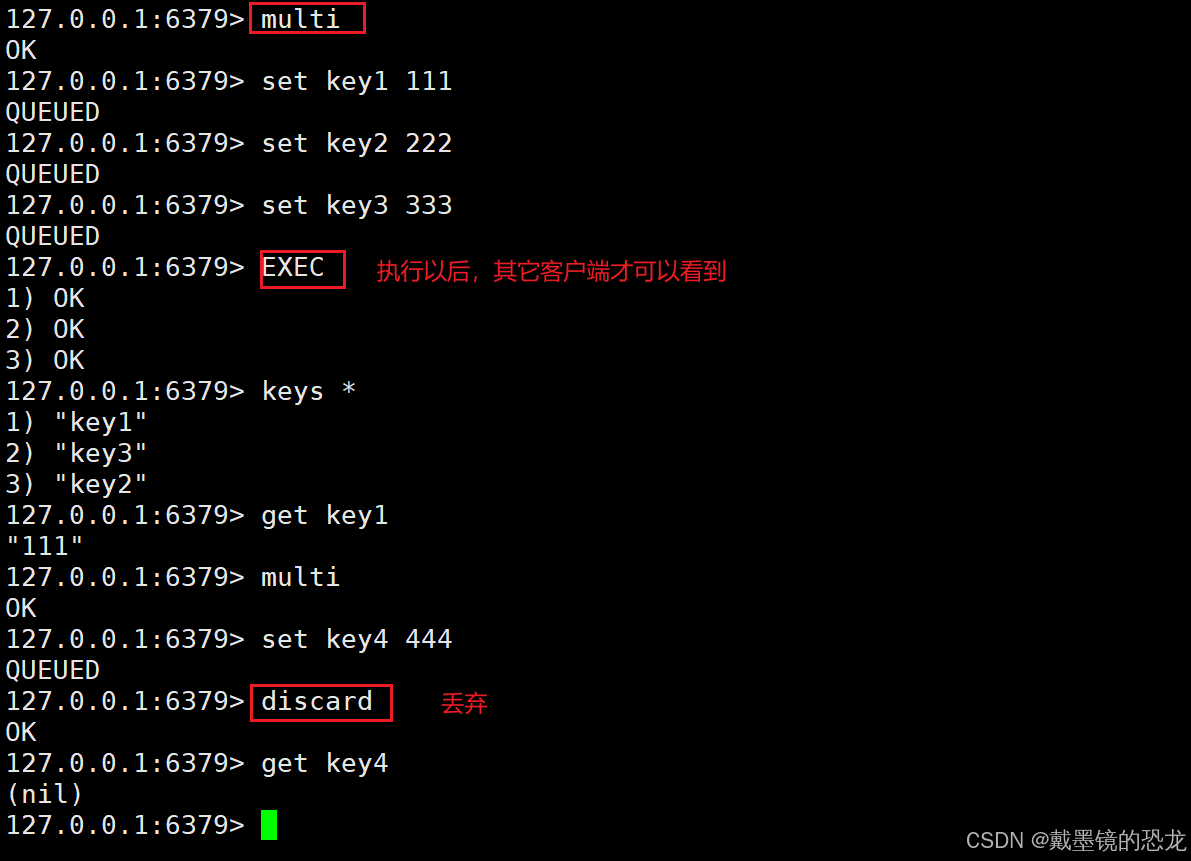
当开启事务,并发送多个命令后,此时服务区器重启了,此时的效果就等同于discard.
WATCH
在执⾏事务的时候,如果某个事务中修改的值,被别的客⼾端修改了,此时就容易出现数据不⼀致的问题
# 客⼾端1 先执⾏
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set key 100
QUEUED# 客⼾端2 再执⾏
127.0.0.1:6379> set key 200
OK# 客⼾端1 最后执⾏
127.0.0.1:6379> EXECOK
此时,key的值是多少呢??
从输⼊命令的时间看,是客⼾端1先执⾏的setkey100,客⼾端2后执⾏的setkey200,但是从实际的执⾏时间看,是客⼾端2先执⾏的,客⼾端1后执⾏的
127.0.0.1:6379> get key
"100"
这个时候就容易引起歧义,因此,即使不保证严格的隔离性,⾄少也要告诉⽤⼾,当前的操作可能存在⻛险, watch命令就是⽤来解决这个问题的,watch在该客⼾端上监控⼀组具体的key
- 当开启事务的时候,如果对watch的key进⾏修改,就会记录当前key的"版本号".(版本号是个简单的整数,每次修改都会使版本变⼤,服务器来维护每个key的版本号情况)
- 在真正提交事务的时候,如果发现当前服务器上的key的版本号已经超过了事务开始时的版本号,就会让事务执⾏失败。(事务中的所有操作都不执⾏).
客户端1先执行
127.0.0.1:6379> watch k1 # 开始监控k1
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set k1 100 #进⾏修改,从服务器获取k1的版本号是0.记录k1的版本号.(还没真修改呢, 版本号不变)
QUEUED
127.0.0.1:6379> set k2 1000
QUEUED
客⼾端2再执行
127.0.0.1:6379> set k1 200 # 修改成功, 使服务器端的k1 的版本号 0 -> 1
OK
客⼾端1再执行
127.0.0.1:6379> EXEC
# 真正执⾏修改操作, 此时对⽐版本发现, 客⼾端的 k1 的版本号是 0,
#服务器上的版本号是 1, 版本不⼀致! 说明有其他客⼾端在事务中间修改了 k1 !!!
(nil)
127.0.0.1:6379> get k1
"200"
127.0.0.1:6379> get k2
(nil)
此时说明事务已经被取消了,这次提交的所有命令都没有执行。
UNWATCH
取消对key的监控.
