(Neurocomputing-2024)RoFormer: 增强型 Transformer 与旋转位置编码
RoFormer: 增强型 Transformer 与旋转位置编码
paper是追一科技发表在NeuroComputing 2024的工作
paper title:ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
Code:链接
ABSTRACT
位置编码在 Transformer 结构中已被证明是有效的。它能够为序列中不同位置的元素之间的依赖关系建模提供有价值的监督。在本文中,我们首先探讨了将位置信息整合到基于 Transformer 的语言模型学习过程中的各种方法。然后,我们提出了一种新方法,称为旋转位置编码(Rotary Position Embedding, RoPE),以有效利用位置信息。具体而言,所提出的 RoPE 通过旋转矩阵对绝对位置进行编码,同时在自注意力计算中显式地融入相对位置的依赖关系。值得注意的是,RoPE 具备多种优越特性,包括:序列长度的灵活性,可适应不同长度的输入序列;随相对距离增加而逐渐衰减的词间依赖性,更符合自然语言的特性;可用于线性自注意力计算的相对位置编码,提升计算效率。最后,我们在多个长文本分类基准数据集上评估了集成旋转位置编码的增强型 Transformer(即 RoFormer)。实验表明,该方法在各项任务中稳定超越现有的替代方案。此外,我们还提供了理论分析,用于解释部分实验结果。
关键词 预训练语言模型 · 位置信息编码 · 预训练 · 自然语言处理。
1 Introduction
单词的顺序对于自然语言理解具有重要价值。基于循环神经网络(RNNs)的模型通过在时间维度上递归计算隐藏状态来编码标记的顺序。基于卷积神经网络(CNNs)的模型(Gehring 等, 2017)通常被认为是对位置不敏感的,但最近的研究(Islam 等, 2020)表明,常用的填充(padding)操作可以隐式地学习位置信息。近年来,基于 Transformer 的预训练语言模型(PLMs)(Vaswani 等, 2017)在各种自然语言处理(NLP)任务中达到了最先进的性能,包括上下文表示学习(Devlin 等, 2019)、机器翻译(Vaswani 等, 2017)以及语言建模(Radford 等, 2019)等。与 RNN 和 CNNs 基础模型不同,PLMs 利用自注意力机制(self-attention)来语义捕捉语料的上下文表示。因此,与 RNNs 相比,PLMs 在并行化方面有了显著提升,同时也比 CNNs 更好地建模了更长的词内关系。
当前的预训练语言模型(PLMs)的自注意力架构已被证明是对位置不敏感的(Yun 等, 2020)。针对这一问题,已有多种方法被提出,以在学习过程中编码位置信息。一方面,绝对位置编码可以通过预定义函数(Vaswani 等, 2017)生成,并添加到上下文表示中;另一方面,也有可训练的绝对位置编码(Gehring 等, 2017;Devlin 等, 2019;Lan 等, 2020;Clark 等, 2020;Radford 等, 2019;Radford 和 Narasimhan, 2018)。另一方面,已有研究(Parikh 等, 2016;Shaw 等, 2018;Huang 等, 2018;Dai 等, 2019;Yang 等, 2019;Raffel 等, 2020;Ke 等, 2020;He 等, 2020;Huang 等, 2020)提出了相对位置编码,该方法通常在注意力机制中显式地编码相对位置信息。此外,Liu 等 (2020) 提出了从神经常微分方程(Neural ODE,Chen 等, 2018a)的角度建模位置编码依赖性,Wang 等 (2020) 研究了在复数空间中建模位置信息的方法。尽管这些方法有效,但它们通常将位置信息直接添加到上下文表示中,因此不适用于线性自注意力架构。
在本文中,我们提出了一种新方法——旋转位置编码(Rotary Position Embedding, RoPE),用于在 PLM 的学习过程中利用位置信息。具体而言,RoPE 通过旋转矩阵对绝对位置进行编码,同时在自注意力公式中显式地融入相对位置的依赖性。相较于现有方法,RoPE 具有多个优越特性,包括:
- 序列长度的灵活性,可适应不同长度的输入序列;
- 随相对距离增加而逐渐衰减的词间依赖性,更符合自然语言的特性;
- 支持线性自注意力的相对位置编码,提升计算效率。
实验结果表明,集成旋转位置编码的增强型 Transformer(即 RoFormer)在多个长文本分类基准数据集上优于现有方法,从而证明了 RoPE 的有效性。
我们的贡献包括以下三个方面:
- 相对位置编码方法分析:我们研究了现有的相对位置编码方法,并发现它们大多基于将位置信息直接添加到上下文表示中的思想。因此,我们提出了一种新方法——RoPE,其关键思想是利用旋转矩阵对相对位置进行编码,并提供了清晰的理论解释。
- RoPE 的特性研究:我们研究了 RoPE 的特性,并证明其随相对距离增加而衰减,这一特性非常适合自然语言编码。此外,我们认为,基于先前方法的相对位置编码并不适用于线性自注意力机制。
- RoFormer 模型评估:我们在多个长文本分类基准数据集上评估了 RoFormer,实验表明它在各项任务中始终优于现有方法。此外,一些基于预训练语言模型的实验已在 GitHub 公开:
https://github.com/ZhuiyiTechnology/roformer。
本文的结构如下:第 2 节 提出了位置编码问题的正式定义,并回顾了相关工作;第 3 节 详细描述了旋转位置编码(RoPE)及其特性;第 4 节 汇报实验结果;第 5 节 总结全文。
2 Background and Related Work
2.1 Preliminary
设 S N = { w i } i = 1 N S_N = \{ w_i \}_{i=1}^{N} SN={wi}i=1N 为一个包含 N N N 个输入标记的序列,其中 w i w_i wi 是第 i i i 个元素。对应的词嵌入表示为 E N = { x i } i = 1 N \mathbb{E}_N = \{ x_i \}_{i=1}^{N} EN={xi}i=1N,其中 x i ∈ R d x_i \in \mathbb{R}^{d} xi∈Rd 是标记 w i w_i wi 在没有位置信息时的 d d d 维词嵌入向量。自注意力机制首先将位置信息编码到词嵌入中,并将其转换为查询(query)、键(key)和值(value)表示:
q m = f q ( x m , m ) q_m = f_q(x_m, m) qm=fq(xm,m)
k n = f k ( x n , n ) k_n = f_k(x_n, n) kn=fk(xn,n)
v n = f v ( x n , n ) , ( 1 ) v_n = f_v(x_n, n), \quad (1) vn=fv(xn,n),(1)
其中, q m q_m qm、 k n k_n kn 和 v n v_n vn 通过 f q f_q fq、 f k f_k fk 和 f v f_v fv 分别整合了第 m m m 和第 n n n 个位置。查询(query)和键(key)值用于计算注意力权重,而输出则通过值(value)的加权和计算得出。
RoFormer
注意力计算公式如下:
a m , n = exp ( q m T k n d ) ∑ j = 1 N exp ( q m T k j d ) ( 2 ) a_{m,n} = \frac{\exp\left( \frac{q_m^T k_n}{\sqrt{d}} \right)} {\sum_{j=1}^{N} \exp\left( \frac{q_m^T k_j}{\sqrt{d}} \right)} \quad (2) am,n=∑j=1Nexp(dqmTkj)exp(dqmTkn)(2)
o m = ∑ n = 1 N a m , n v n o_m = \sum_{n=1}^{N} a_{m,n} v_n om=n=1∑Nam,nvn
现有的基于 Transformer 的位置编码方法主要集中在选择合适的函数来构造方程 (1)。
2.2 Absolute position embedding
方程 (1) 的一个典型选择是:
f
t
:
t
∈
{
q
,
k
,
v
}
(
x
i
,
i
)
:
=
W
t
:
t
∈
{
q
,
k
,
v
}
(
x
i
+
p
i
)
,
(
3
)
f_{t:t\in\{q,k,v\}}(x_i, i) := \mathbf{W}_{t:t\in\{q,k,v\}}(x_i + p_i), \quad (3)
ft:t∈{q,k,v}(xi,i):=Wt:t∈{q,k,v}(xi+pi),(3)
其中, p i ∈ R d p_i \in \mathbb{R}^d pi∈Rd 是一个依赖于标记 x i x_i xi 位置的 d d d 维向量。先前的研究(Devlin 等, 2019;Lan 等, 2020;Clark 等, 2020;Radford 等, 2019;Radford 和 Narasimhan, 2018)引入了一组可训练的向量 p i ∈ { p t } t = 1 L p_i \in \{ p_t \}_{t=1}^{L} pi∈{pt}t=1L,其中 L L L 是最大序列长度。Vaswani 等 (2017) 的研究提出使用正弦函数生成 p i p_i pi:
{ p i , 2 t = sin ( k / 1000 0 2 t / d ) p i , 2 t + 1 = cos ( k / 1000 0 2 t / d ) ( 4 ) \begin{cases} p_{i, 2t} = \sin(k / 10000^{2t/d}) \\ p_{i, 2t+1} = \cos(k / 10000^{2t/d}) \end{cases} \quad (4) {pi,2t=sin(k/100002t/d)pi,2t+1=cos(k/100002t/d)(4)
其中, p i , 2 t p_{i, 2t} pi,2t 是 d d d 维向量 p i p_i pi 的第 2 t 2t 2t 个元素。在下一节中,我们将展示所提出的 RoPE 与这种基于正弦函数的思想相关。然而,与直接将位置信息加到上下文表示不同,RoPE 通过与正弦函数相乘的方式来融合相对位置信息。
2.3 Relative position embedding
Shaw 等 (2018) 提出了不同的方程 (1) 设定方式如下:
f q ( x m ) : = W q x m f_q(x_m) := W_q x_m fq(xm):=Wqxm
f k ( x n , n ) : = W k ( x n + p ~ r k ) f_k(x_n, n) := W_k (x_n + \tilde{p}_r^k) fk(xn,n):=Wk(xn+p~rk)
f v ( x n , n ) : = W v ( x n + p ~ r v ) ( 5 ) f_v(x_n, n) := W_v (x_n + \tilde{p}_r^v) \quad (5) fv(xn,n):=Wv(xn+p~rv)(5)
其中, p ~ r k , p ~ r v ∈ R d \tilde{p}_r^k, \tilde{p}^v_r \in \mathbb{R}^d p~rk,p~rv∈Rd 是可训练的相对位置嵌入。需要注意的是, r = clip ( m − n , r min , r max ) r = \text{clip}(m - n, r_{\min}, r_{\max}) r=clip(m−n,rmin,rmax) 代表了位置 m m m 和 n n n 之间的相对距离。他们对相对距离进行了裁剪,并假设在超出某一阈值后,精确的相对位置信息并无实际作用。在保持方程 (3) 形式的基础上,Dai 等 (2019) 提出了对方程 (2) 的 q m T k n q_m^T k_n qmTkn 进行分解:
q m T k n = x m T W q T W k x n + x m T W q T W k p n + p m T W q T W k x n + p m T W q T W k p n ( 6 ) q_m^T k_n = x_m^T W_q^T W_k x_n + x_m^T W_q^T W_k p_n + p_m^T W_q^T W_k x_n + p_m^T W_q^T W_k p_n \quad (6) qmTkn=xmTWqTWkxn+xmTWqTWkpn+pmTWqTWkxn+pmTWqTWkpn(6)
其中的关键思想是,用正弦编码的相对位置嵌入 p ~ m − n \tilde{p}_{m-n} p~m−n 替换绝对位置嵌入 p n p_n pn,同时,将第三项和第四项的绝对位置 p m p_m pm 替换为两个独立于查询位置的可训练向量 u u u 和 v v v。此外,为了区分基于内容和基于位置的键向量 x n x_n xn 和 p n p_n pn, W k W_k Wk 被进一步区分为 W k W_k Wk 和 W k ^ \widehat{W_k} Wk ,从而得到:
q m T k n = x m T W q T W k x n + x m T W q T W k ^ p ~ m − n + u T W q T W k x n + v T W q T W k ^ p ~ m − n ( 7 ) q_m^T k_n = x_m^T W_q^T W_k x_n + x_m^T W_q^T \widehat{W_k} \tilde{p}_{m-n} + u^T W_q^T W_k x_n + v^T W_q^T \widehat{W_k} \tilde{p}_{m-n} \quad (7) qmTkn=xmTWqTWkxn+xmTWqTWk p~m−n+uTWqTWkxn+vTWqTWk p~m−n(7)
需要注意的是,在值(value)项中,位置信息被移除,即 f v ( x j ) : = W v x j f_v(x_j) := W_v x_j fv(xj):=Wvxj。后续的研究(Raffel 等, 2020;He 等, 2020;Ke 等, 2020;Huang 等, 2020)沿用了这一设定,仅在注意力权重中编码相对位置信息。然而,Raffel 等 (2020) 对方程 (6) 进行了改进:
q m T k n = x m T W q T W k x n + b i , j ( 8 ) q_m^T k_n = x_m^T W_q^T W_k x_n + b_{i,j} \quad (8) qmTkn=xmTWqTWkxn+bi,j(8)
其中, b i , j b_{i,j} bi,j 是可训练的偏置项。Ke 等 (2020) 研究了方程 (6) 的中间两项,并发现绝对位置与词之间的相关性较弱。Raffel 等 (2020) 进一步提出,使用不同的投影矩阵来建模词对或位置对:
q m T k n = x m T W q T W k x n + p m T U q T U k p n + b i , j ( 9 ) q_m^T k_n = x_m^T W_q^T W_k x_n + p_m^T U_q^T U_k p_n + b_{i,j} \quad (9) qmTkn=xmTWqTWkxn+pmTUqTUkpn+bi,j(9)
He 等 (2020) 认为,两个标记的相对位置只能通过方程 (6) 的中间两项完全建模。因此,他们直接用相对位置嵌入 p ~ m − n \tilde{p}_{m-n} p~m−n 替换了绝对位置嵌入 p m p_m pm 和 p n p_n pn:
q m T k n = x m T W q T W k x n + x m T W q T W k p ~ m − n + p ~ m − n T W q T W k x n ( 10 ) q_m^T k_n = x_m^T W_q^T W_k x_n + x_m^T W_q^T W_k \tilde{p}_{m-n} + \tilde{p}_{m-n}^T W_q^T W_k x_n \quad (10) qmTkn=xmTWqTWkxn+xmTWqTWkp~m−n+p~m−nTWqTWkxn(10)
Radford 和 Narasimhan (2018) 对四种不同的相对位置嵌入进行了比较,结果表明,与方程 (10) 形式相似的方法是四种方法中计算效率最高的。总体而言,这些方法都基于方程 (3) 的分解对方程 (6) 进行了修改,采用的自注意力机制设定来自方程 (2),而这一设定最早由 Vaswani 等 (2017) 提出。通常,这些方法的核心思路是直接将位置信息添加到上下文表示中。
与此不同,我们的方法的目标是在一定约束下从方程 (1) 中推导相对位置编码。接下来,我们将展示该方法如何通过旋转上下文表示来更直观地融入相对位置信息。
3 Proposed approach
在本节中,我们讨论所提出的旋转位置编码(Rotary Position Embedding, RoPE)。首先,在第 3.1 节中,我们对相对位置编码问题进行建模;接着,在第 3.2 节中,我们推导出 RoPE 的具体形式;最后,在第 3.3 节中,我们研究其性质。
3.1 Formulation
基于 Transformer 的语言建模通常通过自注意力机制利用单个标记的位置信息。如方程 (2) 所示, q m T k n q_m^T k_n qmTkn 通常能够在不同位置的标记之间传递知识。为了融入相对位置信息,我们要求查询 q m q_m qm 和键 k n k_n kn 的内积由某个函数 g g g 进行建模,该函数仅依赖于词嵌入 x m , x n x_m, x_n xm,xn 以及它们的相对位置 m − n m - n m−n 作为输入变量。换句话说,我们希望内积仅通过相对位置信息进行编码:
⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , m − n ) . ( 11 ) \langle f_q(x_m, m), f_k(x_n, n) \rangle = g(x_m, x_n, m - n). \quad (11) ⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n).(11)
最终目标是找到一个等效的编码机制,使得函数 f q ( x m , m ) f_q(x_m, m) fq(xm,m) 和 f k ( x n , n ) f_k(x_n, n) fk(xn,n) 满足上述关系。
3.2 Rotary position embedding
3.2.1 A 2D case
我们从一个二维情况(d = 2)出发。在这种设定下,我们利用向量在二维平面上的几何特性以及其复数表示来证明(详见第 3.4.1 节)方程 (11) 的解如下:
f q ( x m , m ) = ( W q x m ) e i m θ f_q(x_m, m) = (W_q x_m) e^{im\theta} fq(xm,m)=(Wqxm)eimθ
f k ( x n , n ) = ( W k x n ) e i n θ f_k(x_n, n) = (W_k x_n) e^{in\theta} fk(xn,n)=(Wkxn)einθ
g ( x m , x n , m − n ) = Re [ ( W q x m ) ( W k x n ) ∗ e i ( m − n ) θ ] ( 12 ) g(x_m, x_n, m - n) = \text{Re} \left[ (W_q x_m) (W_k x_n)^* e^{i(m-n)\theta} \right] \quad (12) g(xm,xn,m−n)=Re[(Wqxm)(Wkxn)∗ei(m−n)θ](12)
其中, Re [ ⋅ ] \text{Re}[\cdot] Re[⋅] 表示复数的实部, ( W k x n ) ∗ (W_k x_n)^* (Wkxn)∗ 表示 ( W k x n ) (W_k x_n) (Wkxn) 的共轭复数。 θ ∈ R \theta \in \mathbb{R} θ∈R 是一个预设的非零常数。
我们可以进一步将 f { q , k } f_{\{q,k\}} f{q,k} 写成矩阵乘法形式:
f { q , k } ( x m , m ) = ( cos m θ − sin m θ sin m θ cos m θ ) ( W { q , k } ( 11 ) W { q , k } ( 12 ) W { q , k } ( 21 ) W { q , k } ( 22 ) ) ( x m ( 1 ) x m ( 2 ) ) ( 13 ) f_{\{q,k\}}(x_m, m) = \begin{pmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{pmatrix} \begin{pmatrix} W_{\{q,k\}}^{(11)} & W_{\{q,k\}}^{(12)} \\ W_{\{q,k\}}^{(21)} & W_{\{q,k\}}^{(22)} \end{pmatrix} \begin{pmatrix} x_m^{(1)} \\ x_m^{(2)} \end{pmatrix} \quad (13) f{q,k}(xm,m)=(cosmθsinmθ−sinmθcosmθ)(W{q,k}(11)W{q,k}(21)W{q,k}(12)W{q,k}(22))(xm(1)xm(2))(13)
其中, ( x m ( 1 ) , x m ( 2 ) ) (x_m^{(1)}, x_m^{(2)}) (xm(1),xm(2)) 是在二维坐标系中表示的 x m x_m xm。同样地, g g g 也可以视为一个矩阵,这样便能够在二维情况下(详见第 3.1 节)推导出该问题的解。
具体而言,引入相对位置编码的过程非常直观:只需将仿射变换后的词嵌入向量按其位置索引的角度倍数进行旋转,这便是 Rotary Position Embedding 背后的核心直觉。
3.2.2 General form
为了将我们在二维情况的结果推广到任何偶数维 d d d 的向量 x i ∈ R d x_i \in \mathbb{R}^d xi∈Rd,我们将 d d d 维空间划分为 d / 2 d/2 d/2 个子空间,并利用内积的线性性质进行组合,从而将 f { q , k } f_{\{q,k\}} f{q,k} 转换为:
f { q , k } ( x m , m ) = R Θ , m d W { q , k } x m ( 14 ) f_{\{q,k\}}(x_m, m) = R_{\Theta, m}^d W_{\{q,k\}} x_m \quad (14) f{q,k}(xm,m)=RΘ,mdW{q,k}xm(14)
其中,旋转矩阵 R Θ , m d R_{\Theta,m}^d RΘ,md 由以下矩阵表示:
R Θ , m d = ( cos m θ 1 − sin m θ 1 0 0 … 0 0 sin m θ 1 cos m θ 1 0 0 … 0 0 0 0 cos m θ 2 − sin m θ 2 … 0 0 0 0 sin m θ 2 cos m θ 2 … 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 0 0 … cos m θ d / 2 − sin m θ d / 2 0 0 0 0 … sin m θ d / 2 cos m θ d / 2 ) ( 15 ) R_{\Theta,m}^d = \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \dots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \dots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \dots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \dots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \dots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \dots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{pmatrix} \quad (15) RΘ,md= cosmθ1sinmθ100⋮00−sinmθ1cosmθ100⋮0000cosmθ2sinmθ2⋮0000−sinmθ2cosmθ2⋮00…………⋱……0000⋮cosmθd/2sinmθd/20000⋮−sinmθd/2cosmθd/2 (15)
旋转矩阵的参数 Θ \Theta Θ 预定义为:
Θ = { θ i = 1000 0 − 2 ( i − 1 ) / d , i ∈ [ 1 , 2 , . . . , d / 2 ] } \Theta = \{\theta_i = 10000^{-2(i-1)/d}, i \in [1, 2, ..., d/2] \} Θ={θi=10000−2(i−1)/d,i∈[1,2,...,d/2]}
在图 (1) 中展示了 RoPE 的图形化示例。将 RoPE 应用于自注意力机制(Equation (2)),我们得到:
q m ⊤ k n = ( R Θ , m d W q x m ) ⊤ ( R Θ , n d W k x n ) = x m ⊤ W q ⊤ R Θ , n − m d W k x n ( 16 ) q_m^\top k_n = (R_{\Theta,m}^d W_q x_m)^\top (R_{\Theta,n}^d W_k x_n) = x_m^\top W_q^\top R_{\Theta, n-m}^d W_k x_n \quad (16) qm⊤kn=(RΘ,mdWqxm)⊤(RΘ,ndWkxn)=xm⊤Wq⊤RΘ,n−mdWkxn(16)
其中, R Θ , n − m d = ( R Θ , m d ) ⊤ R Θ , n d R_{\Theta, n-m}^d = (R_{\Theta,m}^d)^\top R_{\Theta,n}^d RΘ,n−md=(RΘ,md)⊤RΘ,nd。注意 R Θ d R_{\Theta}^d RΘd 是一个正交矩阵,确保了位置编码过程中的稳定性。此外,由于 R Θ d R_{\Theta}^d RΘd 是稀疏矩阵,直接执行矩阵乘法(如 Equation (16))在计算上并不高效,我们在理论分析部分提供了一种更优化的计算方式。
与之前工作(Equation (3) 至 (10))中采用的加性位置编码方法不同,我们的方法是乘法性的。此外,RoPE 通过旋转矩阵的乘法自然地融入了相对位置信息,而非在自注意力展开公式中直接修改位置项,这一点与加性位置编码方式存在显著区别。
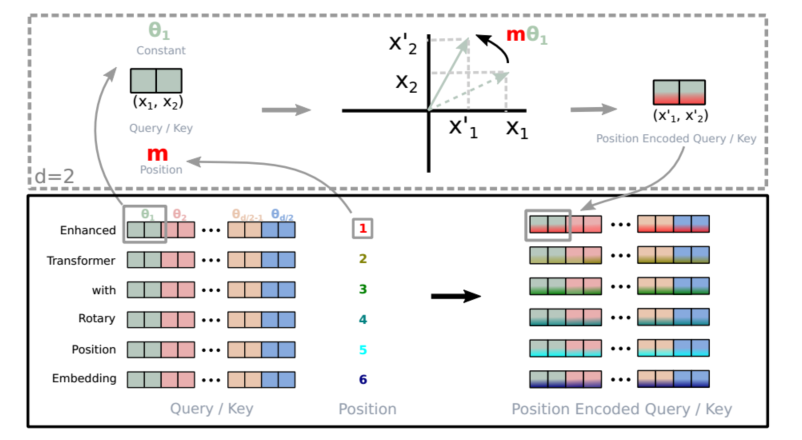
图1:旋转位置嵌入(RoPE)的实现。
3.3 Properties of RoPE
长距离衰减(Long-term decay):
遵循 Vaswani 等 (2017) 的设定,我们设定
θ
i
=
1000
0
−
2
i
/
d
\theta_i = 10000^{-2i/d}
θi=10000−2i/d。可以证明,这一设定提供了长距离衰减特性(详情见第 3.4.3 节)。也就是说,当相对位置增大时,内积值将会衰减。这一特性符合我们的直觉,即相对距离较远的两个标记之间的联系应当较弱。
RoPE 在线性注意力中的应用(RoPE with linear attention):
自注意力机制可以被重写为一个更加通用的形式。
原始自注意力机制计算如下:
Attention ( Q , K , V ) m = ∑ n = 1 N sim ( q m , k n ) v n ∑ n = 1 N sim ( q m , k n ) . ( 17 ) \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V})_m = \frac{\sum_{n=1}^{N} \text{sim}(q_m, k_n) v_n}{\sum_{n=1}^{N} \text{sim}(q_m, k_n)}. \quad (17) Attention(Q,K,V)m=∑n=1Nsim(qm,kn)∑n=1Nsim(qm,kn)vn.(17)
其中, sim ( q m , k n ) = exp ( q m T k n / d ) \text{sim}(q_m, k_n) = \exp(q_m^T k_n / \sqrt{d}) sim(qm,kn)=exp(qmTkn/d)。需要注意的是,原始自注意力需要计算每对查询和键的内积,其计算复杂度为 O ( N 2 ) \mathcal{O}(N^2) O(N2)。为了降低计算量,Katharopoulos 等 (2020) 提出了线性注意力,并将方程 (17) 重新表述为:
Attention ( Q , K , V ) m = ∑ n = 1 N ϕ ( q m ) T φ ( k n ) v n ∑ n = 1 N ϕ ( q m ) T φ ( k n ) . ( 18 ) \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V})_m = \frac{\sum_{n=1}^{N} \phi(q_m)^T \varphi(k_n) v_n}{\sum_{n=1}^{N} \phi(q_m)^T \varphi(k_n)}. \quad (18) Attention(Q,K,V)m=∑n=1Nϕ(qm)Tφ(kn)∑n=1Nϕ(qm)Tφ(kn)vn.(18)
其中, ϕ ( ⋅ ) , φ ( ⋅ ) \phi(\cdot), \varphi(\cdot) ϕ(⋅),φ(⋅) 通常是非负函数。Katharopoulos 等 (2020) 提出的非负函数如下:
ϕ ( x ) = φ ( x ) = elu ( x ) + 1 \phi(x) = \varphi(x) = \text{elu}(x) + 1 ϕ(x)=φ(x)=elu(x)+1
该方法首先利用矩阵乘法的结合律,先计算键和值之间的乘积,以降低计算量。此外,Shen 等 (2021) 采用Softmax 归一化来分别归一化查询和键,使其在内积计算前达到:
ϕ ( q i ) = softmax ( q i ) , ϕ ( k j ) = exp ( k j ) . \phi(q_i) = \text{softmax}(q_i), \quad \phi(k_j) = \exp(k_j). ϕ(qi)=softmax(qi),ϕ(kj)=exp(kj).
更多关于线性注意力的细节可参考相关论文。在本节中,我们重点讨论如何在线性注意力中引入 RoPE(旋转位置编码)。由于 RoPE 通过旋转矩阵注入位置信息,同时保持隐藏表示的范数不变,我们可以通过将旋转矩阵与非负函数的输出相乘,将 RoPE 与线性注意力结合:
Attention ( Q , K , V ) m = ∑ n = 1 N ( R Θ , m d ϕ ( q m ) ) T ( R Θ , n d φ ( k n ) ) v n ∑ n = 1 N ϕ ( q m ) T φ ( k n ) . ( 19 ) \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V})_m = \frac{\sum_{n=1}^{N} (R_{\Theta,m}^d \phi(q_m))^T (R_{\Theta,n}^d \varphi(k_n)) v_n}{\sum_{n=1}^{N} \phi(q_m)^T \varphi(k_n)}. \quad (19) Attention(Q,K,V)m=∑n=1Nϕ(qm)Tφ(kn)∑n=1N(RΘ,mdϕ(qm))T(RΘ,ndφ(kn))vn.(19)
需要注意的是:
- 我们保持分母不变,以避免除零风险。
- 分子中可能包含负值,即方程 (19) 并非严格概率归一化,但我们认为该计算仍然能够有效地建模值( v i v_i vi)的重要性。
3.4 Theoretical Explanation
3.4.1 Derivation of RoPE under 2D
在 d = 2 的情况下,我们考虑两个词嵌入向量 x q , x k x_q, x_k xq,xk,它们分别对应查询(query)和键(key),并具有位置索引 m m m 和 n n n。根据方程 (1),它们的位置编码版本如下:
q m = f q ( x q , m ) , q_m = f_q(x_q, m), qm=fq(xq,m),
k n = f k ( x k , n ) , ( 20 ) k_n = f_k(x_k, n), \quad (20) kn=fk(xk,n),(20)
其中, q m q_m qm 和 k n k_n kn 的下标表示已编码的位置信息。假设存在一个函数 g g g,用于定义 f { q , k } f_{\{q,k\}} f{q,k} 生成向量的内积关系:
q m T k n = ⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , n − m ) , ( 21 ) q_m^T k_n = \langle f_q(x_m, m), f_k(x_n, n) \rangle = g(x_m, x_n, n - m), \quad (21) qmTkn=⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,n−m),(21)
此外,我们需要满足以下初始条件:
q = f q ( x q , 0 ) , q = f_q(x_q, 0), q=fq(xq,0),
k = f k ( x k , 0 ) . ( 22 ) k = f_k(x_k, 0). \quad (22) k=fk(xk,0).(22)
这意味着, q q q 和 k k k 是不包含位置信息的初始向量。在此设定下,我们尝试找到 f q , f k f_q, f_k fq,fk 的解。首先,我们利用二维向量的几何意义及其复数表示,将方程 (20) 和 (21) 分解为:
f q ( x q , m ) = R q ( x q , m ) e i Θ q ( x q , m ) , f_q(x_q, m) = R_q(x_q, m)e^{i\Theta_q(x_q, m)}, fq(xq,m)=Rq(xq,m)eiΘq(xq,m),
f k ( x k , n ) = R k ( x k , n ) e i Θ k ( x k , n ) , f_k(x_k, n) = R_k(x_k, n)e^{i\Theta_k(x_k, n)}, fk(xk,n)=Rk(xk,n)eiΘk(xk,n),
g ( x q , x k , n − m ) = R g ( x q , x k , n − m ) e i Θ g ( x q , x k , n − m ) , ( 23 ) g(x_q, x_k, n - m) = R_g(x_q, x_k, n - m)e^{i\Theta_g(x_q, x_k, n-m)}, \quad (23) g(xq,xk,n−m)=Rg(xq,xk,n−m)eiΘg(xq,xk,n−m),(23)
其中, R f , R g R_f, R_g Rf,Rg 和 Θ f , Θ g \Theta_f, \Theta_g Θf,Θg 分别表示 f { q , k } f_{\{q,k\}} f{q,k} 和 g g g 的幅值(radical)与角度(angular)分量。将上述表达式代入方程 (21),得到如下关系:
R q ( x q , m ) R k ( x k , n ) = R g ( x q , x k , n − m ) , R_q(x_q, m) R_k(x_k, n) = R_g(x_q, x_k, n - m), Rq(xq,m)Rk(xk,n)=Rg(xq,xk,n−m),
Θ k ( x k , n ) − Θ q ( x q , m ) = Θ g ( x q , x k , n − m ) . ( 24 ) \Theta_k(x_k, n) - \Theta_q(x_q, m) = \Theta_g(x_q, x_k, n - m). \quad (24) Θk(xk,n)−Θq(xq,m)=Θg(xq,xk,n−m).(24)
对应的初始条件如下:
q = ∥ q ∥ e i θ q = R q ( x q , 0 ) e i Θ q ( x q , 0 ) , q = \|q\| e^{i\theta_q} = R_q(x_q,0)e^{i\Theta_q(x_q,0)}, q=∥q∥eiθq=Rq(xq,0)eiΘq(xq,0),
k = ∥ k ∥ e i θ k = R k ( x k , 0 ) e i Θ k ( x k , 0 ) , ( 25 ) k = \|k\| e^{i\theta_k} = R_k(x_k,0)e^{i\Theta_k(x_k,0)}, \quad (25) k=∥k∥eiθk=Rk(xk,0)eiΘk(xk,0),(25)
其中, ∥ q ∥ , ∥ k ∥ \|q\|, \|k\| ∥q∥,∥k∥ 和 θ q , θ k \theta_q, \theta_k θq,θk 分别是二维平面上 q q q 和 k k k 的幅值(radial part)和角度(angular part)。
接下来,我们设 m = n m = n m=n,并代入方程 (24),结合方程 (25) 的初始条件,得到:
R q ( x q , m ) R k ( x k , n ) = R q ( x q , 0 ) R k ( x k , 0 ) = R q ( x q , 0 ) R k ( x k , 0 ) = ∥ q ∥ ∥ k ∥ , ( 26 a ) R_q(x_q, m) R_k(x_k, n) = R_q(x_q, 0) R_k(x_k, 0) = R_q(x_q, 0) R_k(x_k, 0) = \|q\| \|k\|, \quad (26a) Rq(xq,m)Rk(xk,n)=Rq(xq,0)Rk(xk,0)=Rq(xq,0)Rk(xk,0)=∥q∥∥k∥,(26a)
Θ k ( x k , n ) − Θ q ( x q , m ) = Θ g ( x q , x k , 0 ) = Θ k ( x k , 0 ) − Θ q ( x q , 0 ) = θ k − θ q . ( 26 b ) \Theta_k(x_k, n) - \Theta_q(x_q, m) = \Theta_g(x_q, x_k, 0) = \Theta_k(x_k, 0) - \Theta_q(x_q, 0) = \theta_k - \theta_q. \quad (26b) Θk(xk,n)−Θq(xq,m)=Θg(xq,xk,0)=Θk(xk,0)−Θq(xq,0)=θk−θq.(26b)
从 (26a) 出发,我们可以得到 R f R_f Rf 的直接解:
R q ( x q , m ) = R q ( x q , 0 ) = ∥ q ∥ , R_q(x_q, m) = R_q(x_q, 0) = \|q\|, Rq(xq,m)=Rq(xq,0)=∥q∥,
R k ( x k , n ) = R k ( x k , 0 ) = ∥ k ∥ , ( 27 ) R_k(x_k, n) = R_k(x_k, 0) = \|k\|, \quad (27) Rk(xk,n)=Rk(xk,0)=∥k∥,(27)
R g ( x q , x k , n − m ) = R g ( x q , x k , 0 ) = ∥ q ∥ ∥ k ∥ . R_g(x_q, x_k, n - m) = R_g(x_q, x_k, 0) = \|q\| \|k\|. Rg(xq,xk,n−m)=Rg(xq,xk,0)=∥q∥∥k∥.
这表明幅值 R q , R k R_q, R_k Rq,Rk 和 R g R_g Rg 不依赖于位置信息。另一方面,从 (26b) 可知, Θ g ( x q , x k , n − m ) = Θ k ( x k , m ) − Θ q ( x q , m ) − θ k \Theta_g(x_q, x_k, n - m) = \Theta_k(x_k, m) - \Theta_q(x_q, m) - \theta_k Θg(xq,xk,n−m)=Θk(xk,m)−Θq(xq,m)−θk,表示角度函数仅与位置索引 m m m 相关,而不依赖于词嵌入 x q , x k x_q, x_k xq,xk。因此,我们定义:
Θ f ( x q , k , m ) = ϕ ( m ) + θ { q , k } . ( 28 ) \Theta_f(x_q, k, m) = \phi(m) + \theta_{\{q,k\}}. \quad (28) Θf(xq,k,m)=ϕ(m)+θ{q,k}.(28)
进一步,将 n = m + 1 n = m + 1 n=m+1 代入方程 (24),并考虑上述方程,我们得到:
ϕ ( m + 1 ) − ϕ ( m ) = Θ g ( x q , x k , 1 ) + θ q − θ k . ( 29 ) \phi(m + 1) - \phi(m) = \Theta_g(x_q, x_k, 1) + \theta_q - \theta_k. \quad (29) ϕ(m+1)−ϕ(m)=Θg(xq,xk,1)+θq−θk.(29)
由于右侧是关于 m m m 的常数,因此** ϕ ( m ) \phi(m) ϕ(m) 形成算术级数**,从而得到:
ϕ ( m ) = m θ + γ , ( 30 ) \phi(m) = m\theta + \gamma, \quad (30) ϕ(m)=mθ+γ,(30)
其中 θ , γ ∈ R \theta, \gamma \in \mathbb{R} θ,γ∈R 为常数,且 θ \theta θ 非零。
最终解
综上所述,结合 (27) 至 (30) 的结果,我们得出:
f q ( x q , m ) = ∥ q ∥ e i θ q + m θ + γ = q e i ( m θ + γ ) , f_q(x_q, m) = \|q\| e^{i\theta_q + m\theta + \gamma} = q e^{i(m\theta + \gamma)}, fq(xq,m)=∥q∥eiθq+mθ+γ=qei(mθ+γ),
f k ( x k , n ) = ∥ k ∥ e i θ k + n θ + γ = k e i ( n θ + γ ) . ( 31 ) f_k(x_k, n) = \|k\| e^{i\theta_k + n\theta + \gamma} = k e^{i(n\theta + \gamma)}. \quad (31) fk(xk,n)=∥k∥eiθk+nθ+γ=kei(nθ+γ).(31)
需要注意的是,我们并未对 (22) 约束 f q ( x q , 0 ) f_q(x_q, 0) fq(xq,0) 和 f k ( x k , 0 ) f_k(x_k, 0) fk(xk,0),因此它们仍然是自由变量。为了使其与方程 (3) 形式一致,我们定义:
q = f q ( x q , 0 ) = W q x m , q = f_q(x_q, 0) = W_q x_m, q=fq(xq,0)=Wqxm,
k = f k ( x n , 0 ) = W k x n . ( 32 ) k = f_k(x_n, 0) = W_k x_n. \quad (32) k=fk(xn,0)=Wkxn.(32)
最终,设 γ = 0 \gamma = 0 γ=0,得到 RoPE 的最终表达式:
f q ( x m , m ) = ( W q x m ) e i m θ , f_q(x_m, m) = (W_q x_m) e^{im\theta}, fq(xm,m)=(Wqxm)eimθ,
f k ( x n , n ) = ( W k x n ) e i n θ . ( 33 ) f_k(x_n, n) = (W_k x_n) e^{in\theta}. \quad (33) fk(xn,n)=(Wkxn)einθ.(33)
3.4.2 Computational efficient realization of rotary matrix multiplication
利用方程 (15) 中 R Θ , m d R_{\Theta,m}^d RΘ,md 的稀疏性,我们可以得到一个计算更高效的 R Θ d R_{\Theta}^d RΘd 与 x ∈ R d x \in \mathbb{R}^d x∈Rd 的矩阵乘法实现:
R Θ , m d x = ( x 1 x 2 x 3 x 4 ⋮ x d − 1 x d ) ⊗ ( cos m θ 1 cos m θ 1 cos m θ 2 cos m θ 2 ⋮ cos m θ d / 2 cos m θ d / 2 ) + ( − x 2 x 1 − x 4 x 3 ⋮ − x d x d − 1 ) ⊗ ( sin m θ 1 sin m θ 1 sin m θ 2 sin m θ 2 ⋮ sin m θ d / 2 sin m θ d / 2 ) ( 34 ) R_{\Theta,m}^d x = \begin{pmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ \vdots \\ x_{d-1} \\ x_d \end{pmatrix} \otimes \begin{pmatrix} \cos m\theta_1 \\ \cos m\theta_1 \\ \cos m\theta_2 \\ \cos m\theta_2 \\ \vdots \\ \cos m\theta_{d/2} \\ \cos m\theta_{d/2} \end{pmatrix} + \begin{pmatrix} -x_2 \\ x_1 \\ -x_4 \\ x_3 \\ \vdots \\ -x_d \\ x_{d-1} \end{pmatrix} \otimes \begin{pmatrix} \sin m\theta_1 \\ \sin m\theta_1 \\ \sin m\theta_2 \\ \sin m\theta_2 \\ \vdots \\ \sin m\theta_{d/2} \\ \sin m\theta_{d/2} \end{pmatrix} \quad (34) RΘ,mdx= x1x2x3x4⋮xd−1xd ⊗ cosmθ1cosmθ1cosmθ2cosmθ2⋮cosmθd/2cosmθd/2 + −x2x1−x4x3⋮−xdxd−1 ⊗ sinmθ1sinmθ1sinmθ2sinmθ2⋮sinmθd/2sinmθd/2 (34)
这一实现方式充分利用了旋转矩阵的稀疏结构,仅需基本的元素级乘法和加法即可完成计算,从而大幅降低计算成本。
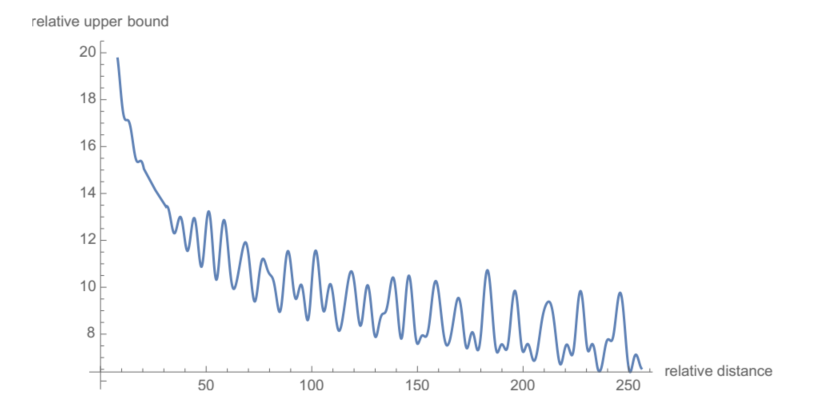
图2:RoPE的长期衰减。
3.4.3 Long-term decay of RoPE
我们可以将向量 q = W q x m q = W_q x_m q=Wqxm 和 k = W k x n k = W_k x_n k=Wkxn 的元素分组成成对形式,并将 RoPE 在方程 (16) 中的内积表示为复数乘法:
( R Θ , m d W q x m ) ⊤ ( R Θ , n d W k x n ) = Re [ ∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i ] . ( 35 ) (R_{\Theta,m}^d W_q x_m)^\top (R_{\Theta,n}^d W_k x_n) = \text{Re} \left[ \sum_{i=0}^{d/2 - 1} q_{[2i:2i+1]} k^*_{[2i:2i+1]} e^{i(m-n)\theta_i} \right]. \quad (35) (RΘ,mdWqxm)⊤(RΘ,ndWkxn)=Re i=0∑d/2−1q[2i:2i+1]k[2i:2i+1]∗ei(m−n)θi .(35)
其中, q [ 2 i : 2 i + 1 ] q_{[2i:2i+1]} q[2i:2i+1] 代表 q q q 的第 2 i 2i 2i 至 ( 2 i + 1 ) (2i+1) (2i+1) 个元素。
设:
h i = q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ , S j = ∑ i = 0 j − 1 e i ( m − n ) θ i , h_i = q_{[2i:2i+1]} k^*_{[2i:2i+1]}, \quad S_j = \sum_{i=0}^{j-1} e^{i(m-n)\theta_i}, hi=q[2i:2i+1]k[2i:2i+1]∗,Sj=i=0∑j−1ei(m−n)θi,
并定义 h d / 2 = 0 , S 0 = 0 h_{d/2} = 0, S_0 = 0 hd/2=0,S0=0。我们可以利用 Abel 变换(Abel transformation)对求和项进行重写:
∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i = ∑ i = 0 d / 2 − 1 h i ( S i + 1 − S i ) = − ∑ i = 0 d / 2 − 1 S i + 1 ( h i + 1 − h i ) . ( 36 ) \sum_{i=0}^{d/2 - 1} q_{[2i:2i+1]} k^*_{[2i:2i+1]} e^{i(m-n)\theta_i} = \sum_{i=0}^{d/2 - 1} h_i (S_{i+1} - S_i) = -\sum_{i=0}^{d/2 - 1} S_{i+1} (h_{i+1} - h_i). \quad (36) i=0∑d/2−1q[2i:2i+1]k[2i:2i+1]∗ei(m−n)θi=i=0∑d/2−1hi(Si+1−Si)=−i=0∑d/2−1Si+1(hi+1−hi).(36)
因此,我们得到:
∣ ∑ i = 0 d / 2 − 1 q [ 2 i : 2 i + 1 ] k [ 2 i : 2 i + 1 ] ∗ e i ( m − n ) θ i ∣ = ∣ ∑ i = 0 d / 2 − 1 S i + 1 ( h i + 1 − h i ) ∣ \left| \sum_{i=0}^{d/2 - 1} q_{[2i:2i+1]} k^*_{[2i:2i+1]} e^{i(m-n)\theta_i} \right| = \left| \sum_{i=0}^{d/2 - 1} S_{i+1} (h_{i+1} - h_i) \right| i=0∑d/2−1q[2i:2i+1]k[2i:2i+1]∗ei(m−n)θi = i=0∑d/2−1Si+1(hi+1−hi)
≤ ∑ i = 0 d / 2 − 1 ∣ S i + 1 ∣ ∣ ( h i + 1 − h i ) ∣ \leq \sum_{i=0}^{d/2 - 1} |S_{i+1}| |(h_{i+1} - h_i)| ≤i=0∑d/2−1∣Si+1∣∣(hi+1−hi)∣
≤ ( max i ∣ h i + 1 − h i ∣ ) ∑ i = 0 d / 2 − 1 ∣ S i + 1 ∣ . ( 37 ) \leq \left( \max_i |h_{i+1} - h_i| \right) \sum_{i=0}^{d/2 - 1} |S_{i+1}|. \quad (37) ≤(imax∣hi+1−hi∣)i=0∑d/2−1∣Si+1∣.(37)
重要结论:
随着相对距离
m
−
n
m-n
m−n 增加,
1
d
/
2
∑
i
=
1
d
/
2
∣
S
i
∣
\frac{1}{d/2} \sum_{i=1}^{d/2} |S_i|
d/21∑i=1d/2∣Si∣ 逐渐衰减,这可以通过设定
θ
i
=
1000
0
−
2
i
/
d
\theta_i = 10000^{-2i/d}
θi=10000−2i/d 来实现(见 Figure (2))。