Mongo3.4升级到mongo6性能降低9倍
time:2025/05/07
Author:skatexg
一、背景与目标
阿里云mongo3.0和3.4要停服下线,倒逼我们把mongo升级到高版本;和产线研发沟通后,决定把mongo升级到6.0版本;
原实例的基础信息如下:
mongo版本:3.4
实例规格配置:8核64G 3300G本地磁盘
说明:
1)其中一个大表2700G,集合默认压缩算法snappy;
- 程序连接mongo的url采用默认参数值(默认的w=1 and journal=0)
目标实例基础信息:
mongo版本:6.0
实例规格配置: 8核64G(独享型) 3300G ESSD AutoPL云盘
说明:
1) 默认压缩算法snappy;程序连接mongo的url采用默认参数值(w:=majority and journal=1)
二、升级过程遇到的问题
- 同样的数据量,6.0版本占用存储空间比3.4版本要多很多(如测试发现3.4版本的13G的数据在6.0版本占用20G存储空间)
- 6.0版本的写性能比3.4版本的写性能低9倍
三、解决方案
- mongo6.0版本存储空间占用比较多
原因分析:因为6.0版本的数据结构变化,导致和3.4版本比,在同样的表压缩算法下,相同的数据会占用更多的存储空间;
mongo6.0提供如下几个压缩算法(storage.wiredTiger.collectionConfig.blockCompressor)
- Snappy: 压缩简单明了,它追求极高的速度和合理的压缩
- Zlib: 压缩的工作方式略有不同,通常能获得更好的压缩率(与 snappy 和 zlib 之间的固有差异无关),这需要更多的 CPU 资源。
- Zstd 是一种较新的压缩算法,由 Facebook 开发,比 zlib 有了改进(压缩率更高、CPU 占用更少、性能更快)。
经过测试mongo6.0使用zstd压缩算法和mongo3.4使用snappy压缩算法的读写性能相似,如下图
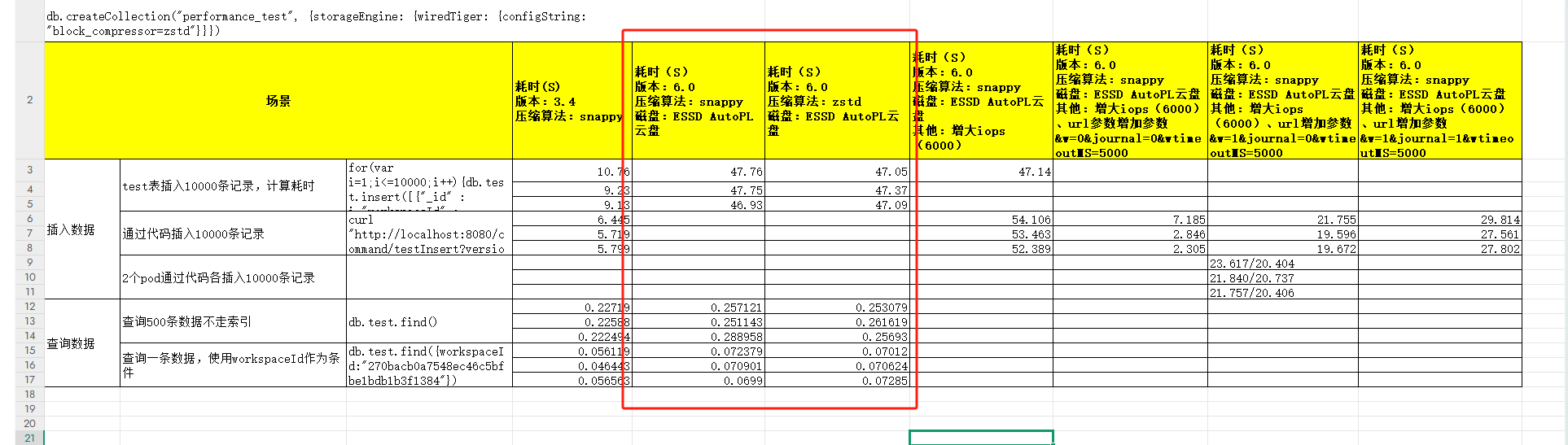
但是zstd占用存储空间对比snappy下少很多,如下图

结论:mongo6.0使用zstd压缩算法和mongo3.4使用snappy压缩算法下,读写性能没有损失,但是占用存储空间会少10%
2、mongo3.4版本的写性能比mongo6.0版本的写性能高9倍
原因分析:mongo3.4版本在客户端url没指定参数时,默认的w=1 and journal=0;从MongoDB 5.0 开始,隐式默认写关注为 w: majority,且journal=1
| mongo3.4版本 | mongo6版本 | |
|
|
写操作被复制多数节点后才确认提交成功 |
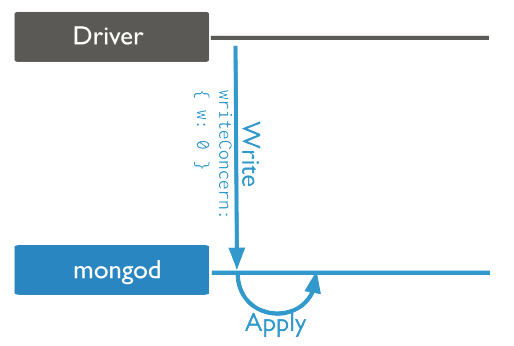
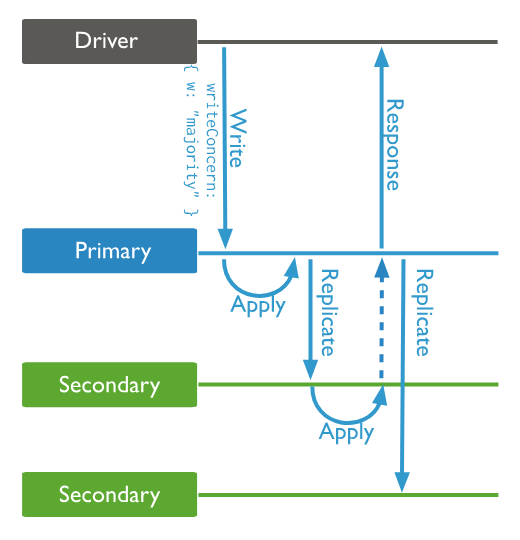
参数说明如下:
1)w参数说明:这个选项会通过确认写入操作已传播到指定数量的 mongod 实例才算提交成功。如果写关注缺少 w 字段,MongoDB 则会将 w 选项设为默认写关注
| w的参数值 | 说明 |
| majority | 等待写操作被复制到副本集中大多数节点上后才确认提交成功,数据不会被回滚;节点越多,变更性能影响越大 |
| 1 | 表示写(write)确认,为MongoDB 5.0版本以前的默认行为。确认写操作在内存中已完成,但由于还没有持久化,可能发生数据丢失;如果存储的是日志信息,可以设置W=1,确认返回更快,数据写入更快 |
| 0 | 要求不确认写入操作是否完成就返回提交成功;这个虽然写入更快,但是容易丢失数据 |
2)journal参数说明:这个选项会要求 MongoDB 确认写入操作已写入磁盘日志
| true | 表示日志(journal)确认。确认写操作已完成并刷到持久化存储的WAL中,写操作不会丢失。 |
| false | 表示日志(journal)确认。确认写操作已完成写入到内存中,写操作可能会丢失。 |
3)wtimeoutMS
此选项指定写关注的时间限制(以毫秒为单位),如果wtimeoutMS是0,写操作永远不会超时,如果写入操作不成功容易产生长阻塞
参数参考:
写关注 - MongoDB 手册 v8.0
事务与Read/Write Concern_云数据库 MongoDB 版(MongoDB)-阿里云帮助中心
测试结果如下:
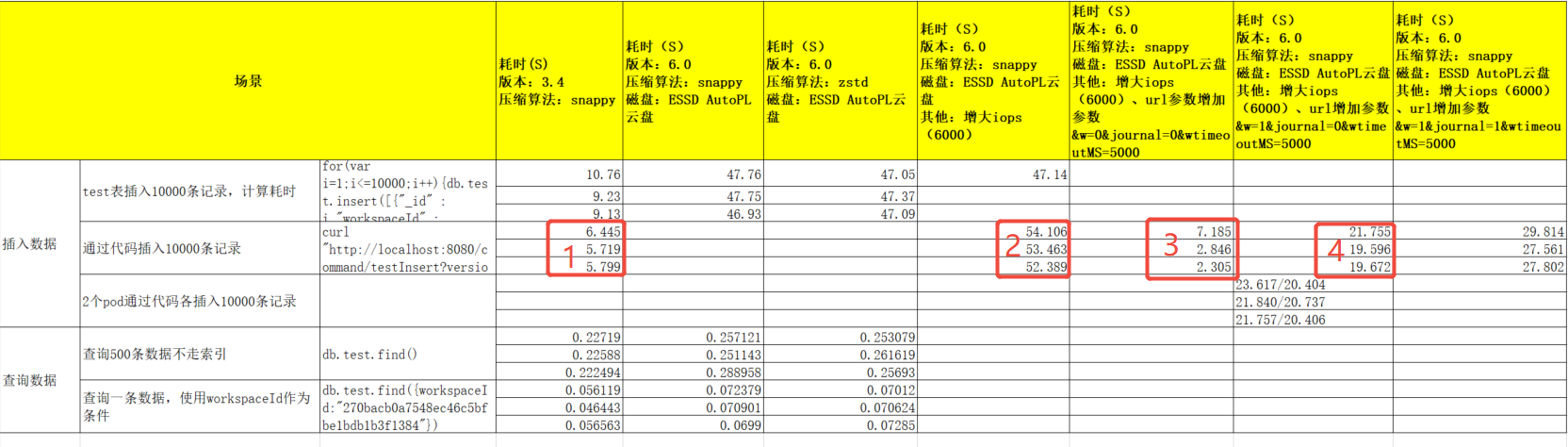
测试总结如下
| 测试条件(url参数) | 测试结果 | 说明 |
| mongo3.4 本地盘 ,w=1 and journal=0 | 红色框1:10000条记录的时间6秒 | 原始业务 |
| mongo6 Auto云盘 , w=majority and journal=1 and wtimeoutMS=5000 | 红色框2:10000条记录的时间54秒 | 不满足业务性能要求 |
| mongo6 Auto云盘 , w=0 and journal=0 and wtimeoutMS=5000 | 红色框3:10000条记录的时间7秒 | 不满足稳定性要求 |
| mongo6 Auto云盘 , w=1 and journal=0 and wtimeoutMS=5000 | 红色框4:10000条记录的时间20秒 | 平衡了性能和稳定性,可以满足业务 |
结论:
1、【mongo6 Auto云盘 , w=1 and journal=0 and wtimeoutMS=5000】的写入性能比 【mongo3.4 本地盘 ,w=1 and journal=0】慢3-4倍,但可以满足业务;这3-4倍的差距是因为本地盘(微秒级延迟)和云盘(2ms延迟)的性能差距
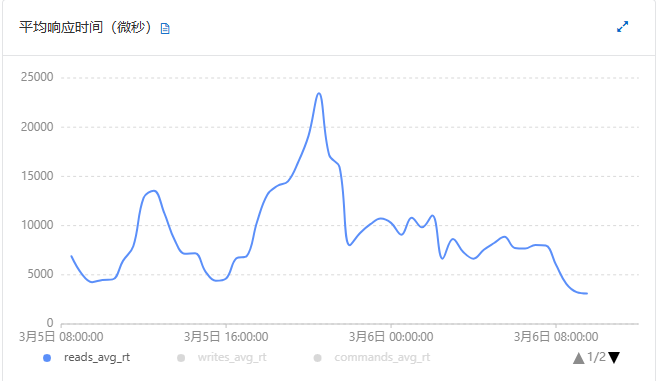
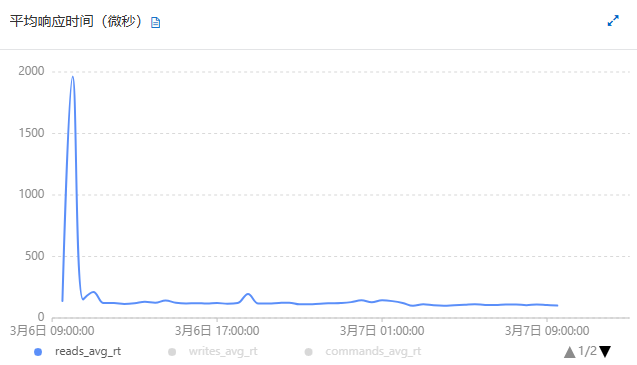
- 升级后实践效果
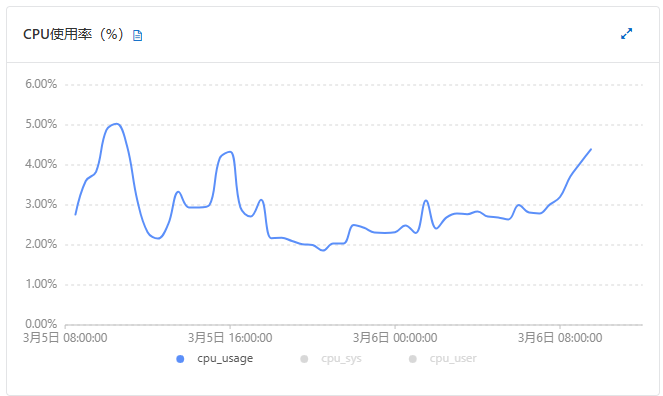
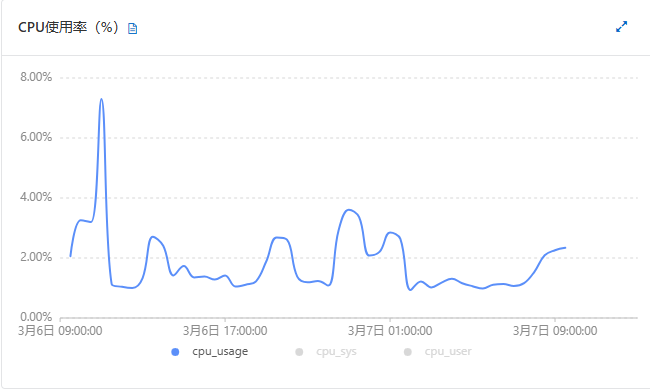
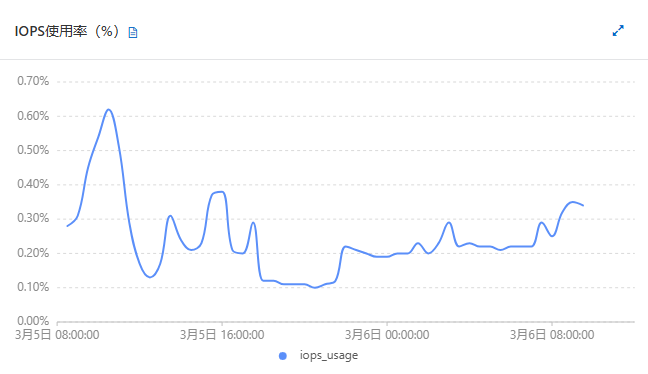
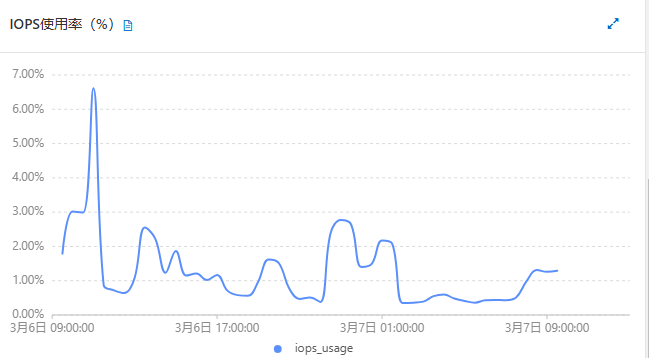
mongo升级前后,性能差不多,没有明显变化,如下图:
| 指标项 | 升级前(3.4)【w=1 and journal=0 】 | 升级后(6.0)【w=1 and journal=0 and wtimeoutMS=5000】 |
| cpu% |
|
|
| iops% |
|
|
| 平均响应时间(微秒) |
|
|
| 存储空间 | 2700G | 263G |
- 最佳实践场景
- 对数据可用性要求高的场景
{w=majority}: Write Concern可以确保副本集中大部分节点已经确认写入操作,即便此时发生节点故障或异常切换也不会产生数据丢失或者回滚的风险;在配合j=true,确认写操作已完成并刷到持久化存储的WAL中,数据可靠性更高
建议值
URL参数:{w=majority and journal=1 and wtimeoutMS=5000}
storage.wiredTiger.collectionConfig.blockCompressor=zstd
- 对写入性能要求高的场景
{w:1}: Write Concern通常能带来更好的写入性能,适合重写入的场景。
说明:
- 应合理关注监控中的从节点复制延迟,当延迟过大时可能会出现主节点异常rollback的问题。
- 当复制延迟超过了oplog的保留时长后,从节点将进入异常的recovering状态且无法自愈,降低实例可用性。
建议值
URL参数:{w=1 and journal=0 and wtimeoutMS=5000}
storage.wiredTiger.collectionConfig.blockCompressor=zstd
---end---