三、大模型原理:图文解析MoE原理
2025年几乎所有领先的大型语言模型都采用了混合专家(Mixture of Experts,简称MOE)架构。
从GPT-4到DeepSeek V3,从Llama 4到Grock,这种稀疏激活的架构已经成为构建高性能AI系统的标准方法。
MOE(Mixture of Experts) 架构
MOE架构的主要组成部分
回顾下Transformer架构,我们会将token输入到Transformer中,Transformer架构是由N个编码器和N个解码器组成。编码器/解码器内部是由两部分组成:
- 注意力机制:残差+多头+LN
- 神经网络:残差+神经网络+LN
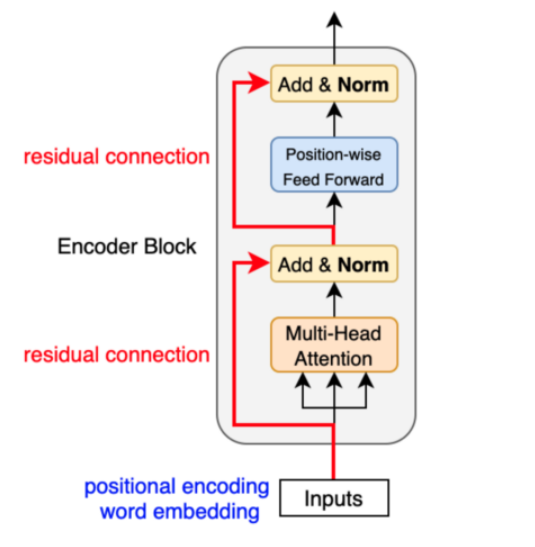
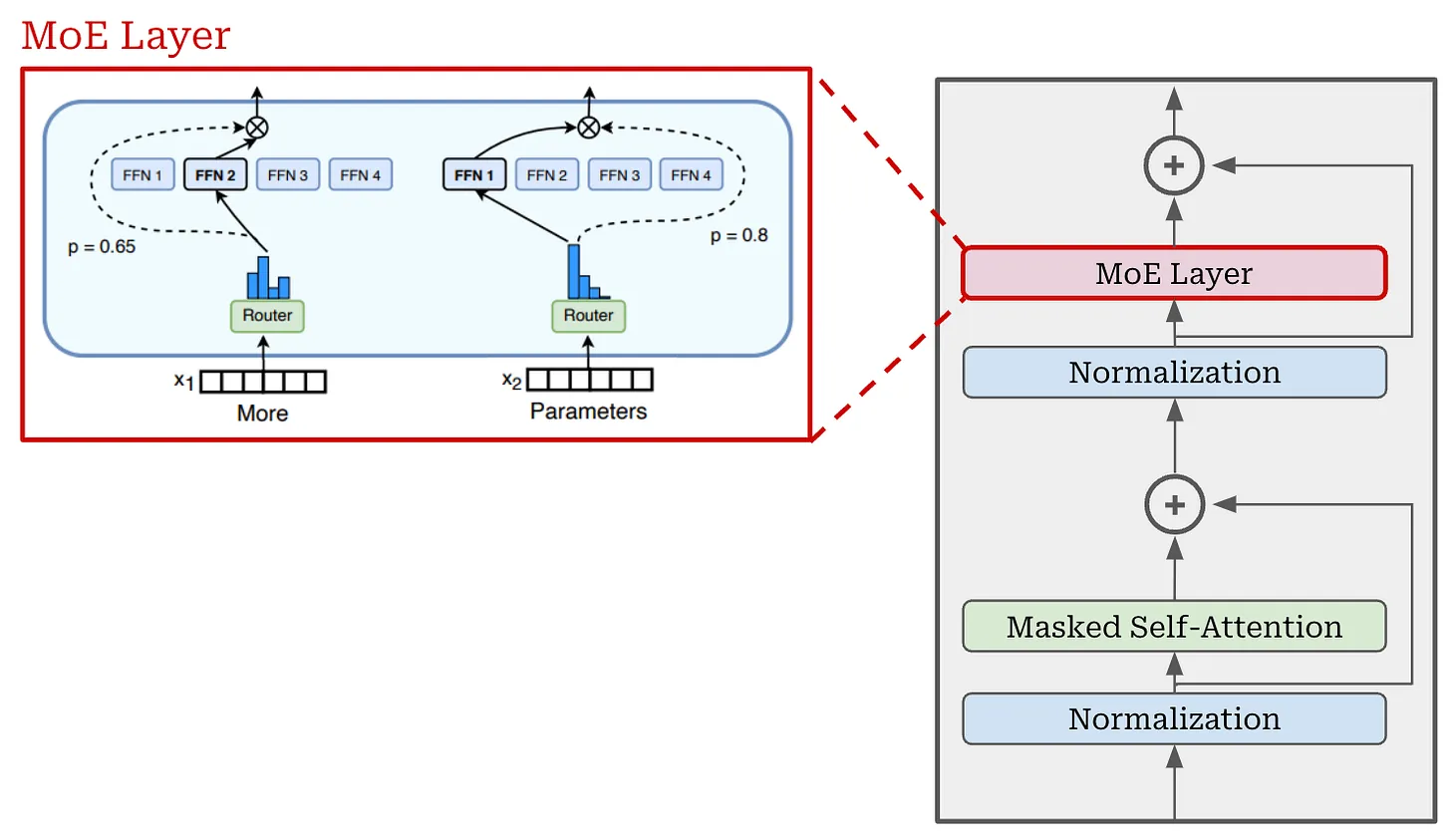
而MOE架构主要修改的是Transformer模型中的神经网络部分。由左图中可知MOE包含两部分:
- 稀疏 MoE 层: 这我们只需将 Transformer 的神经网络多拷贝几份(后文会将这一层称为专家层),在复杂运用中也可能是多个MoE层。
- 路由层: 这个部分用于决定哪些token被发送到哪个神经网络中。例如,在下图中,“More”这个令牌可能被发送到第二个神经网络,而“Parameters”这个令牌被发送到第一个神经网络。有时,一个令牌甚至可以被发送到多个神经网络。该路由方式是由预训练学习的参数所得到的
1. 专家层
我们无需在 Transformer 的每个前馈层都使用MOE层。即有的使用MOE有的保持神经网络。研究表明“交错”的 MoE 层可以在最终模型的性能和效率之间取得更好的平衡。
基于 MoE 的 LLM 为模型架构引入了稀疏性,使我们能够显著增加模型规模,但不会增加推理成本。
2. 路由
这一层决定每个token将会激活哪些专家,由此很容易联想到用softmax来评估概率。如下为路由层架构
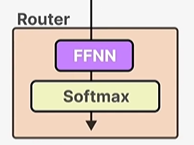
经过softmax会输出概率,把专家层和路由串联起来即得到MOE层。我们仅激活概率最高的Top-K个专家(通常K=1或2):
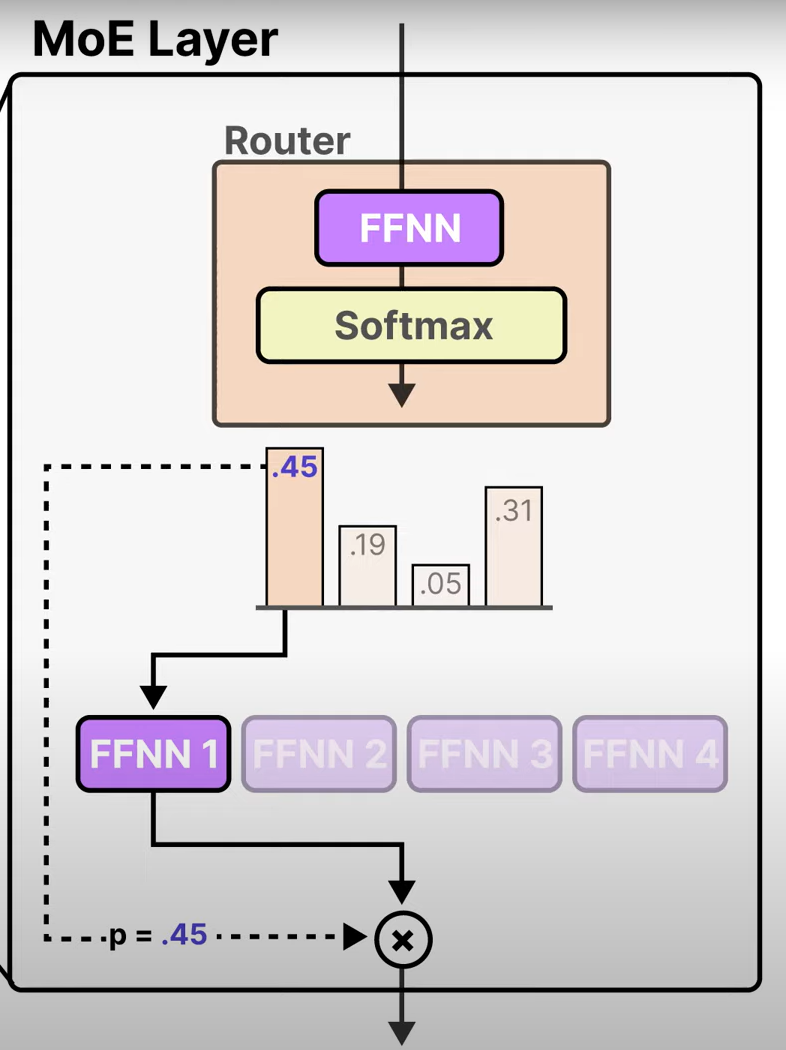
当K>1时我们MoE的输出时对其的概率加权和
负载均衡
防止有的专家太忙有的专家不干活。为了打破这种不平衡,MoE引入了两个计算去实现这个目标。
噪声注入技术
它会对那些被频繁选择的专家施加更大的抑制作用,降低它们的得分,从而给其他专家更多被选择的机会。噪声注入的具体实现方式如下:
在路由计算中加入高斯噪声:
H(X) = X·W + Noise
值得注意的是,这里添加的噪声并非完全随机,而是有选择性的。
辅助损失
仅有噪声注入和keepTopK机制还不足以完全解决专家不平衡问题。为此,MoE引入了辅助损失
辅助损失的核心思想是在模型的总损失函数中添加一个惩罚项,当专家选择分布不均衡时增加额外损失。它的计算步骤如下:
- 计算每个专家的重要性:对所有token的路由概率分布进行累加,得到每个专家的整体重要性分数
- 计算变异系数(Coefficient of Variation, CV):使用标准差除以均值,来衡量专家之间的使用不平衡程度
- 将CV作为惩罚项添加到模型的总损失中
例如,如果某些token总是倾向于选择专家1,而很少选择其他专家,那么专家1的重要性分数会显著高于其他专家。此时,高CV值会产生较大的惩罚损失,促使模型在训练过程中调整路由机制,更均衡地使用所有专家。
专家容量限制的实例解析
让我们通过一个具体例子来理解专家容量限制的工作方式。
假设我们有4个专家(FFN1-FFN4),一个批次中有多个token需要处理,专家容量上限C设为3。在应用专家容量限制前,token的分配情况可能是:
- FFN1:处理7个token
- FFN2:处理2个token
- FFN3:处理1个token
- FFN4:处理0个token
这种分配明显不均衡,FFN1过载而FFN4闲置。
应用专家容量限制后,分配变为:
- FFN1:处理3个token(达到容量上限)
- FFN2:处理2个token
- FFN3:处理1个token
- FFN4:处理4个token(接收了原本分配给FFN1的溢出token)
通过这种重新分配,所有专家都被适当激活,计算负载更加均衡。
MoE 模型的规模与参数
在评估 MoE 模型规模时,需要考虑多个维度:
- 总参数量: 模型中所有参数的数量
- 激活参数量: 处理每个输入时实际使用的参数数量
- 专家数量: 模型中专家的总数量
此外,还需要考虑隐藏层大小 (d_model)、FFN 中间层大小 (d_FFN)、专家层大小 (d_expert)、网络层数 (L)、注意力头数量 (H) 和注意力头维度 (d_head) 等参数。